概率语法图模型发力,小样本学习的突破 | 焦点评论
2017年10月26日,科学期刊《Science》上刊发了知名人工智能创业公司Vicarious的一项最新研究[1] --- “A generative vision model that trains with high data efficiency and breaks text-based CAPTCHAs”。CAPTCHA是Completely Automated Public Turing Test To Tell Computers and Humans Apart的缩写,指基于网络文本验证创建的全自动区分计算机和人类的图灵测试。该项研究通过提出一种新型生成式组成模型(generative compositional model):Recursive Cortical Network (RCN),使用小样本学习,在CAPTCHA上获得突破性的成果。RCN的成功表明,在推动人工智能发展的道路上,生成式组成模型,特别是上下文相关概率语法图模型和自底向上(bottom-up)/自顶向下(top-down)联合推理算法,取得了一个重要的阶段性成果。为什么这么认为?我们从以下几个方面作个简要的介绍和分析。
RCN的实验结果、与深度学习的比较和结论
在CAPTCHA中(图1),对英文字母进行遮挡、变形等处理之后,人类往往仍然能够准确地识别,但这个任务却对当今流行的机器学习算法带来了巨大挑战。在CAPTCHA中,机器的识别正确率超过1%即被认为突破。而RCN在多个CAPTCHA数据库中,获得了极佳的成绩(reCAPTCHA:66.6%, BotDetect 64.4%, Yahoo: 57.4%, PayPal: 57.1%),整体上以300倍的数据有效性(data efficiency)击败了深度学习的卷积网络模型。其中,在reCAPTCHA上,对于每个字母,RCN仅使用5个训练样本,而深度学习卷积网络模型达到相似的成绩使用了二百三十万个训练样本。此外,RCN在多个任务(如单样本和小样本识别、手写数字生成等)中,均取得了优异的结果。
对于与深度学习模型比较,Vicarious的博客[2]提到:“deep learning has demonstrated many narrow super-human abilities on recognizing photos and playing games. It is important not to conflate the success of deep learning in creating a diversity of narrow intelligences as progress on the path toward general intelligences.” 深度学习在识别图像和游戏AI上显示了过人却狭隘的能力。但重要的是,不要把深度学习在狭隘智能上的成功,和通往通用智能之路上的进展混为一体。

图1.人类在字母形式上感知的灵活性。(A)人类擅长解析不熟悉的字体。(B) 相同的字母可以有很多的表现形式,人类可以从上图中识别出“A”。(C) 常识和上下文信息会影响人类对字体的感知:(i)“m”还是“u”或“n”; (ii) 同样的线条中,不同位置上的遮挡会影响对其理解为“N”还是“S”; (iii) 对形状的感知会帮助识别图中的“b,i,s,o,n”和“b,i,k,e”。(摘自[1])
RCN工作的意义之一: 组成模型与小数据学习
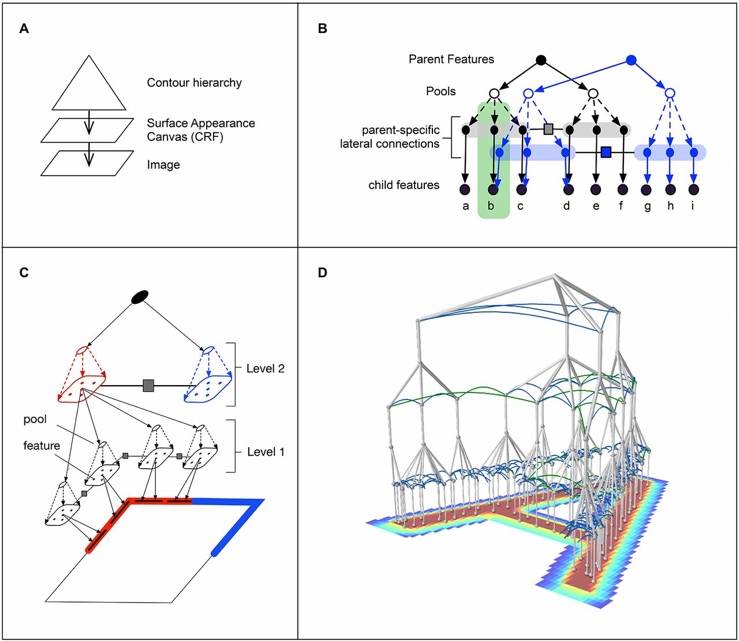
图2. RCN模型示意图。(a)物体边缘和表面分离建模。层级结构生成对象轮廓,条件随机场(Conditional Random Field, CRF)生成表观模型。(b)与节点AND node(实心)表示视觉概念的组成成分,或节点OR node(虚心)表示同一语义的不同变化。(c)使用3层RCN对矩形轮廓建模。第二层的AND node用来表示矩形的角,每个角表示为第一层中线条的交汇。(d)使用4层RCN表示字母“A”。(摘自[1])
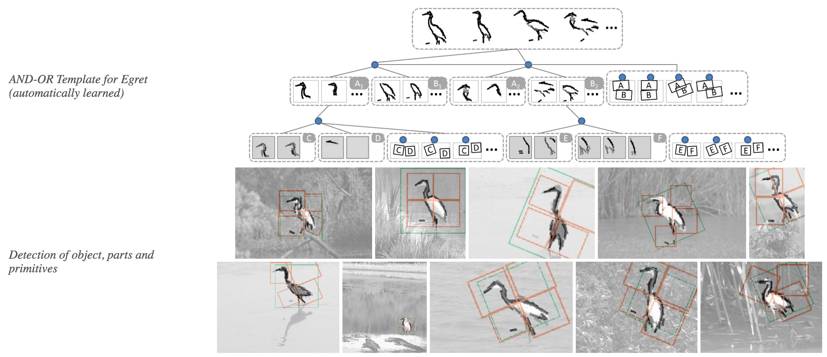
图3. AOT模型示意图。利用与或图 (And-Or Graph) 模型对物体进行层次化建模。(摘自[4])
人类智能的一个重要特性是,人类具有从小样本中进行学习的能力,并且具有极强的泛化性,即所谓举一反三,融会贯通。RCN的实验结果显示了较强的基于小样本的学习和泛化的能力。基于小样本学习的能力通常需要显式的多层次组成模型(Hierarchical and Compositional Models)的支持。RCN模型实质上属于上下文相关概率语法图模型(Context-Sensitive Probabilistic Grammar Models),更具体是属于概率与或图模型(Probabilistic And-Or Graph Models)[3,4,5],并且RCN进一步融合了系统神经科学(systems neuroscience)研究的启发,特别是视皮层中的侧连接(lateral connections in the visual cortex)。RCN文章中也具体说明了这点:“The seminal work on AND-OR templates and tree-structured compositional models has the advantage of simplified inference, but is lacking in selectivity owing to the absence of lateral constraints.” 如图2所示,RCN利用hierarchical graph把物体表示为边缘和面的组合。在RCN中有两种节点,即Feature node(即与节点AND node)和Pool node(即或节点OR node)。这里,与节点And node表示某个视觉概念的组成成分,比如可以用线段的组合去表示角,用四个角的组合去表示一个矩形;可以用多个小面去组合表示一个大面。这样我们就得到了一个层次化的语义结构(线段、角、形状等等)。或节点OR node表示同一语义的不同变化,比如一个边缘形状的内部形变和视角变换,一个面语义在不同纹理和尺度下的变换等等。同时,RCN还通过侧向连接来让不同高层语义之间去分享中低层的语义表达,比如“角”作为一个基本概念单元,可以被不同的物体边缘轮廓所共有。作为比较,图3给出一个通过小样本弱监督学习的AOT(And-Or Template)与或模板在物体检查中应用的示例图。
实际上,如图4所示,概率上下文相关语法模型[3]同样强调对侧连接进行建模和计算,只是在AOT工作[3]中使用条件独立的假设,从而可以使用动态规划进行推理。RCN层次化、产生式的建模方式使模型获得了在小样本上的学习能力,通过对物体边缘和平面的分离建模,以及对物体纹理、尺度等复杂变化的层次化建模,使得整个模型获得了极强的泛化能力和对表观特征变化的鲁棒性。基于小样本学习的研究方向上,另一个重量级的工作是2015年发表在科学期刊的Bayesian program learner[10],其模型原理上也可以认为属于上下文相关的概率语法图模型。另外两个相关工作包括(1)compositional boosting用于多层次图像结构的检测[6];(2)基于与或图(And-Or Graph)的在线物体跟踪[7],其中后者在实验中性能也超过两种基于深度学习的算法。
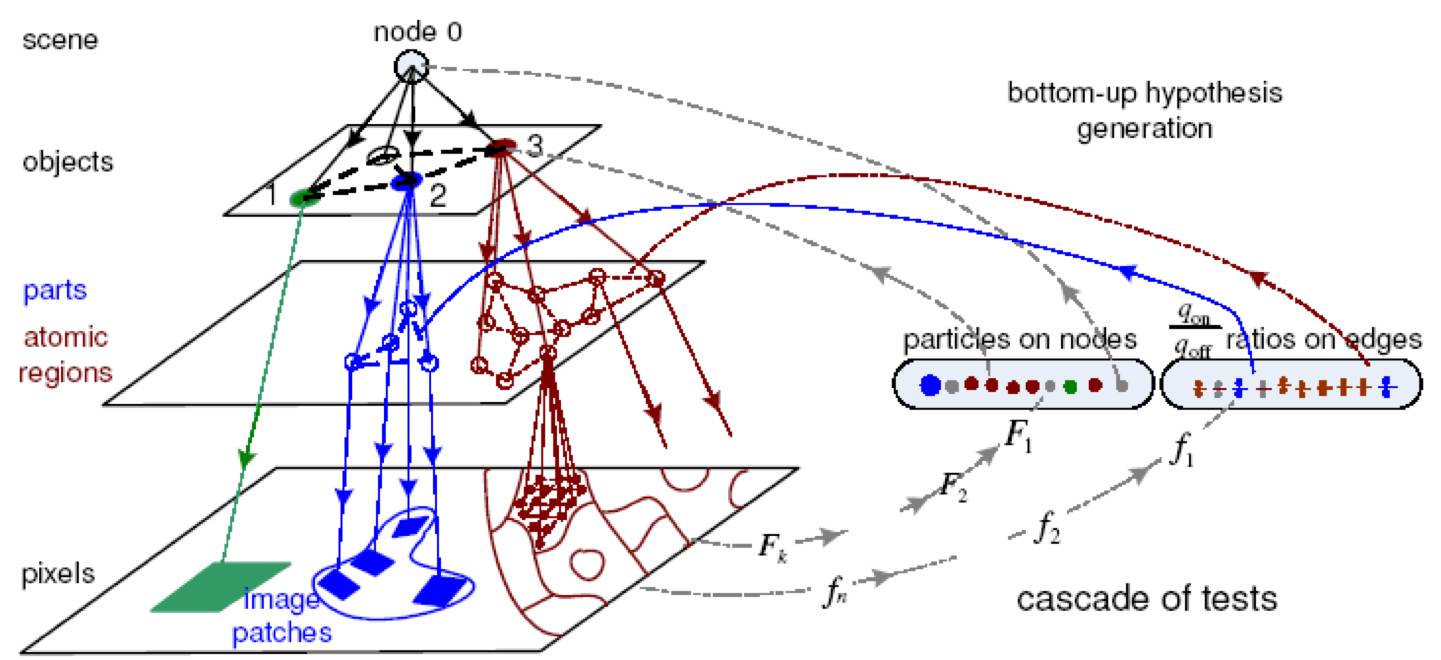
图4. 基于与或图的推理算法示例图。自顶向下产生式模型和自底向上判别式模型统一示意图,两者结合计算产生解译图。自底向上判别式模型主要进行两种测试,一是对分层结构中的每层中的节点本身进行测试,如图中Particles on nodes,二是多测试所得的节点之间的关系进行测试,如图中Ratios on edges,两种测试都是在多层上同时进行。测试所得结果作为“提议(Proposal)”驱动自顶向下的马尔可夫链跳转或扩散,或在一些简化的假设下,直接进行(近似)动态规划推理。(摘自[9])
RCN工作的意义之二:自底向上/自顶向下计算
显式的多层次组成模型,特别是与或图 (And-Or Graph) 模型,使得自底向上/自顶向下联合推理算法得以鲁棒的实现,从而能在最大化贝叶斯后验的框架下(MAP)统一基于判别式模型的数据驱动和基于高层语义的任务驱动,并且很容易通过局部上下文无关和条件独立假设来根据需要简化推理过程,比如使用动态规划。图5所示为RCN的基于Message-Passing的推理算法示意图,与图4所示算法原理相通。
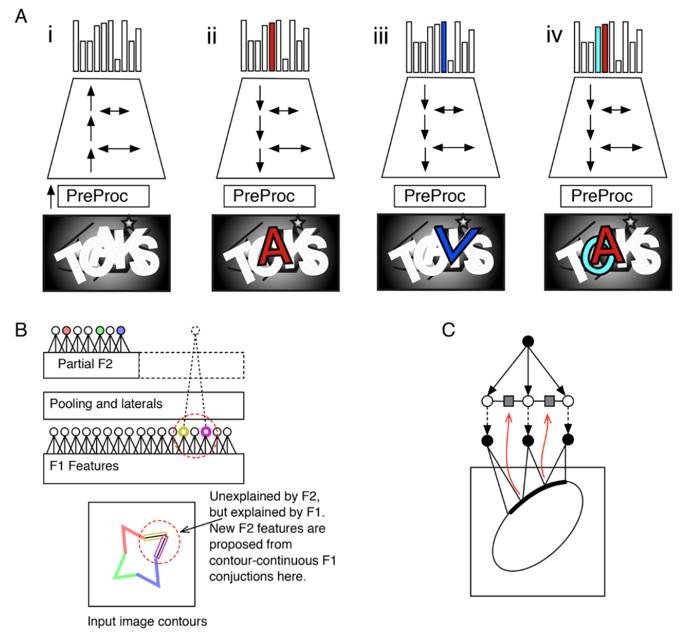
图5. RCN的推理算法。(A) (i) 通过前向传递,包括侧连接传递,生成字符假设。这里PreProc是一类Gabor算子,生成像素上的边界概率。(ii) 反向传递和侧连接传递从之前的假设中选取了“A”。(iii)“A”和“K”之间产生了一个错误的假设“K”,可以通过上下文解析消除错误假设。(iv)多个假设联合解释了图中的字母,包括对分离、遮挡的推理。(B)第二层上的特征学习。着色圆圈代表激活的特征,虚线圆圈代表最终选取的特征。(C)从边缘的相邻结构中学习侧连接。(摘自[1])
RCN工作的意义之三:模型可解释性
上下文相关概率图语法模型和自底向上/自顶向下联合推理算法一个比较直接的优势是模型本身和算法推理过程都是可解释的。特别是,根据任务,图语法模型中的每个节点不仅有语法结构功能,也同时具备语义解释功能;由于结构上显示多层次和组成,推理算法计算过程中非常清楚每一步,自底向上数据驱动的贡献和自顶向下结构以及空间和语义关系的贡献各是多少;并且,如果模型预测和推理结果出错时,能相对容易找出哪些中间步骤有错。在建立通用人工智能框架的方向上,DARPA对概率上下文相关语法模型框架也表示了重视[8],如图6所示。
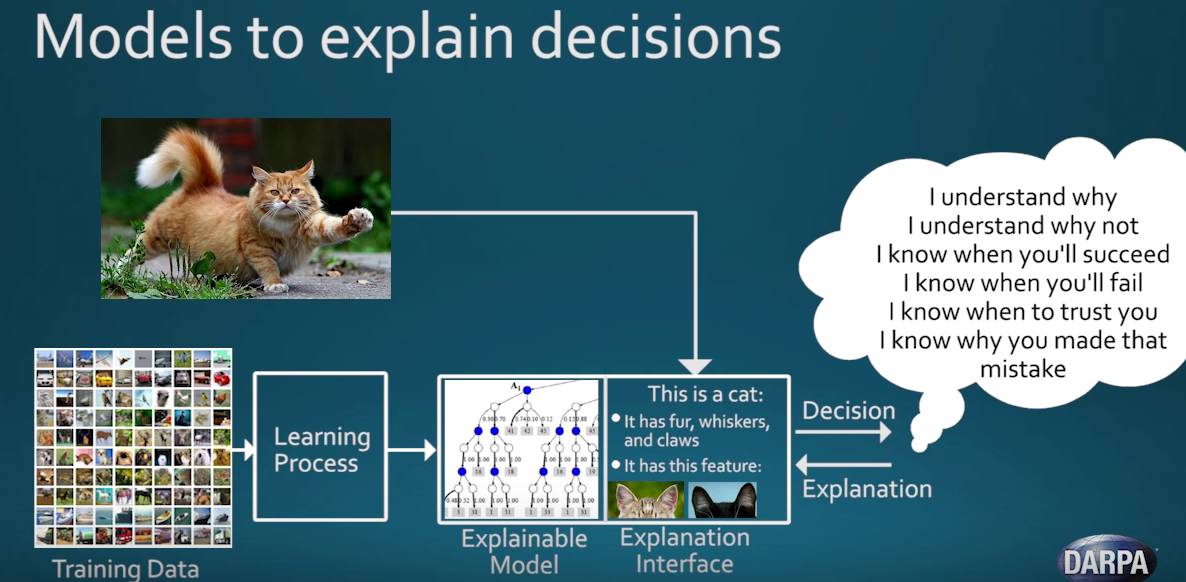
图6. DARPA 在可解释人工智能(eXplainable AI, XAI)项目中,极为重视概率上下文相关语法模型。图中猫的模型示例是基于AOT工作[4]。(视频截屏自[8])
RCN背后学术流派与历史:概率图语法与组成模型
RCN的成功是得益于概率上下文相关语法模型和自底向上/自顶向下联合推理算法。从更广的角度来看,RCN的成功或许能促使我们继续在概率上下文相关语法模型和自底向上/自顶向下联合推理算法的框架下,来思考视觉知识的统一表达模型和学习算法,包括场景上下文语义建模、复杂物体层次化构造(Hierarchical Composition)法和基于人类感知和认知机理的小样本机器学习理论,从而能进一步实现小数据大任务(small-data-big-tasks)。这与当前流行的深度学习模型所擅长大数据小任务(big-data-small-tasks)截然不同。而在通往通用人工智能的方向上,这一点尤其重要。为此,我们下面对RCN背后学术流派与历史作一些简要回顾;笔者试图提供一个总体的解读,因此部分表述不完全拘泥于严谨的理论。
整体上,概率语法图和组成模型的演变和发展主要包括,著名华人人工智能专家傅京生(K.S. Fu)在上个世纪70年代提出的句法模式识别(Syntactic pattern recognition)、U. Grenander的模式理论(Pattern theory)、S. Geman提出的视觉中compositionality和reusable parts的概念和模型。这些学派思想在UCLA得到进一步拓广和长足的发展,主要包括朱松纯(S.-C. Zhu)和D. Mumford在2006年提出的与或图(And-Or Graph)模型,以及他们的长期合作者A. Yuille在与或图模型发展方向上的一系列工作,包括朱珑在UCLA期间的工作,以及后来与深度学习结合的相关工作。
视觉知识通常可以分为两类,一类是表达性知识(Representational Knowledge),包括各个层次上的视觉字典和各种关系;另一类是计算性知识(Computational Knowledge),包括各种特征的计算和自底向上与自顶向下的排序(Ordering) 。在上个世纪80年代后期和90年代初,研究人员逐渐认识到视觉问题在本质上是一个病态问题(ill-posed problem),必须在贝叶斯框架下通过融入关于客观世界的先验知识进行推理计算来求解问题,通过显式的建立各类视觉模式的模型来表达各种视觉知识。Grenander(1976)、Cooper(1979)和傅京生(1982)最早提出对各类视觉模式建立统计模型。S. Geman进一步提出了组成性(compositionality)和可重用部件(reusable parts)的概念和模型。在早期的模型中,通常只是作一些简单的假设,如物体表面和图像区域的平滑性(Smoothness)等。这些模型包括:各类物理模型(Physically-based Model)、正则化理论(RegularizationTheory)和能量函数模型(Energy Functional)等等。在随后的研究中,这些早期模型都被统一到统计建模的范畴内,但这种建模方法的计算量很大,为此研究者开始通过引入隐含变量(HiddenV ariables)来解释图像中的各种相关性(Dependency)从而进行降维,建立视觉模型中的产生式模型(Generative Model),减少计算量。产生式模型必须要建立一些视觉字典作为隐含变量。隐含变量的引入一方面进行降维,同时进行解相关(Decoupling),如稀疏编码(Sparse Coding)以及后来的Active basis模型,通过从自然图像中学习到一个超完备(Over-complete)基来建立图像的加性模型(Additive Model),只需要使用少量的基(基的数量远小于象素点的个数,即稀疏性)就可以表示图像。
视觉模式,特别是类间结构变化大的物体,如钟、椅子和衣服等,需要用构造(Composition)式方法来建模,对其语法(Grammar)进行描述。从构造方式上来说,这类物体的结构分解是有规则的,如钟可分解为:外框、表盘、指针、表示时间的数字,但是其中的每一个子部件(Part)都有千变万换的表现形式,如外框可以是方形、圆形或椭圆形等,表示时间的数字可以是罗马数字或阿拉伯数字等。对其建模,一方面要能对这种构造方式进行表示,同时对子部件之间的关系进行描述,而子部件本身也可能进一步通过构造式模型来描述。通过这种构造式方法对大量视觉模式建模,最终处于分解最低层的一些子部件就可以抽象形成视觉字典(Visual Vocabulary),它们反过来逐级向上构造出大量的视觉模式及其各种表现形式,从而可以处理类间结构的变化。
对语法建模的思想一开始出现在对自然语言建模的研究中,研究者通过随机上下文无关语法(Stochastic Context Free Grammar,SCFG)来对自然语言的词法、句法等建模。在图像中,对语法建模更为重要,是建模的一个核心问题。自然语言中字与字之间,词与词之间等存在显式的左右顺序(Left-to-Right)关系,但在图像中不存在,这给图像语法建模带来了很大的困难:SCFG并不直接适用,传统的研究中还没有合适的模型。
描述式模型适合对高熵模式进行建模,如各种纹理, 数学形式上属于隐式函数,即这类高熵模式通常处于图像空间种的隐式流形(Implicit Manifold)上;产生式模型适合对低熵模式进行建模,如各种卡通画,通过建立一组超完备基,图像就表示为在这组基下的坐标系数,数学形式上属于显式函数,即这类低熵模式处于图像空间中的显式流形(Explicit Manifold)上。但在实际自然场景中,由于尺度的原因,一幅图像中通常都是既有低熵模式也有高熵模式。为此必须将描述式和产生式模型进行统一,进一步这种统一必须表现在视觉的各个层次上,同时对不同层次之间的构造(Composition)关系进行描述 。
朱松纯(S.-C. Zhu)等人在研究概率上下文相关语法模型过程中,指出描述式和产生式模型是在图像空间不同熵区的表现,将其统一其实就是David Marr(计算机视觉的奠基人)在七十年代末提出原始简约图模型(Primal Sketch)的理论模型。进一步,基于原始简约图模型,通过感知尺度空间理论(Perceptual Scale Space Theory)来研究视觉模式的统计描述和模型随着尺度变化而变化的规律,为描述式和产生式模型转化提供了理论基础。随之,与或图(And-Or Graph) 表示在2006年由朱松纯(S.-C.Zhu)团队首次提出,并进一步与D. Mumford合作进行了框架的完善,融入随机上下文相关语法(Stochastic Context Sensitive Grammar),能对复杂物体的多层次构造特性(Hierarchical Compositionality)建模,完全表示图像语法(Image Grammar)。与或图表示突破了传统单一模板(Template)的表示方法,对每类物体用多个图结构表示,该结构可以通过语法(Grammar)、产生规则(Production Rule)进行动态调制,从而可以用相对小的视觉字典(Visual Vocabulary),表达大量类间结构变化很大的物体的图像表现形式(Configuration)。建立小样本学习理论的一个关键问题是要研究产生式模型如何指导判别式模型,这点在RCN模型中得到了非常好的体现。
视觉推理计算的目的是在贝叶斯框架下,给定输入图像,求客观世界表达的最优后验概率分布。主要两类计算模型,一类是自底向上的判别式模型,另一类是自顶向下的产生式模型。判别式模型通过计算图像的局部特征来逼近后验概率 (Posterior Probability)或后验概率比(Ratios of Posterior Probability),产生式模型通过使用马尔可夫链蒙特卡罗方法(Markov Chain Monte Carlo, MCMC)或基于简化模型的(近似)动态规划按贝叶斯规则来自顶向下推理后验概率。视觉计算的任务根据所求的客观世界表达的不同而不同,解译(Parsing)图像是其最主要的目标。 图像解译通常可分为两个子部分:一是所谓的“什么跟什么在一起(What goes with what)?”问题,即图划分(Graph Partition)问题,其解空间为图划分空间(Graph Partition Space);二是所谓的“什么是什么(What is what)?”问题,即给定一个划分状态,为其每个子图选择模型,并匹配模型的参数。其解空间为模型空间(Model Space)。图像解译必须在两者的联合空间中求最优解,而传统的视觉计算通常只在其中一个空间上求解。在图划分空间上求解的算法包括:图的谱分析(Graph Spectral Analysis)方法,Minimum-cut和Graph-cut,和 基于图的通用信任传递(Generalized Belief Propagation on Graph) 。这类算法由于只集中在图划分空间上进行,而且能处理的能量函数类型也有限,所以不能作通用的视觉计算。在模型空间上求解的有如均值漂移(Mean-shift)算法等。传统的MCMC方法,如Gibbs采样,通过每次调整一个点的状态进行计算,所以它们的计算量特别大,不适合大型系统。后来Swendsen-Wang(SW)算法通过每次调整一组点的状态来进行计算,大大的加速了Gibbs采样,但是SW算法只能处理Potts模型,所以也无法进行通用的视觉计算。进行通用而高效的视觉计算的关键是在贝叶斯框架下,算法不依赖于初始状态,在图划分和模型的联合空间达到最优,要将自底向上的判别式模型与自顶向下的产生式模型进行统一,并有效调度,这点在相对小的任务上有很好的表现[9],但有待进一步研究能推广到small-data-big-tasks。
编辑评论
我们也邀请了《视觉求索》的部分编辑们对这篇文章作了评论。
“CAPTCHA是认证用户是真人而不是机器程序的一个有效手段。
--- by 华刚
“如今大数据时代的人工智能是‘高大上’的代表,但背后却藏着个‘暴力美学’。大量的数据样本用来描述数据间的匹配关系,深度学习以此训练深度神经网络的海量参数。以最通俗的语言来说,深度神经网络其实是以无与伦比的暴力记忆能力、以海量参数生硬地记住了数据间的匹配关系,再以无可匹敌的计算能力重现了此关系。最近甚至有ICLR文章记载,深度神经网络可以被训练成记住一大堆随机生成的噪声信号!所以,这样的智能其实是靠人工标注的数据堆砌出来的。正所谓,‘有多少人工,就有多少智能。’
《科学》杂志的这篇文章正是要突破‘大数据’的瓶颈,把人工智能真正建立在小数据的基础。从小数据中萃取的智能才可能是真正的大智能!”
--- by 周少华
总结
我们非常高兴的看到RCN的成功,但同时更希望看到,也相信很快能看到,更多的对其模型背后框架的思考和进一步研究。这里,我们引用Vicarious的博客文章的结束语来共勉之:“Miles Brundage said it well: Progress so farhas largely been toward demonstrating general approaches for building narrow systems rather than general approaches for building general systems. Progress toward the former does not entail substantial progress toward the latter. General systems are hard to evaluate and harder to build than their narrow counterparts, but we must confront this difficulty directly if we ever hope to achieve human level intelligence with qualities like common sense.”
参考文献
[1] D. George, W. Lehrach, K. Kansky, M. Lázaro-Gredilla, C. Laan, B. Marthi, X.Lou, Z. Meng, Y. Liu, H. Wang, A. Lavin, and D. S. Phoenix, “A generative vision model that trains with high data efficiency and breaks text-based CAPTCHAs”, Science, 2017.
[2] https://www.vicarious.com/2017/10/26/common-sense-cortex-and-captcha/
[3] S.-C. Zhu(朱松纯), D. Mumford, “Astochastic grammar of images,” Foundations and Trends in Computer Graphics and Vision, 2007.
[4] Z. Si(司长长), S.-C. Zhu(朱松纯), “Learning AND-OR templates for object recognition anddetection,” PAMI, 2013.
[5] A. L. Yuille, “Towards a theory of compositional learning and encoding ofobjects,” ICCV Workshops, 2011.
[6] T. F. Wu(吴田富), G.-S. Xia, S.- C. Zhu(朱松纯),“Compositional Boosting for Computing Hierarchical Image Structures,” CVPR,2007. https://v.qq.com/x/page/
[7] T. F. Wu(吴田富), Y. Lu(吕洋),S.-C. Zhu(朱松纯), “Online ObjectTracking, Learning and Parsing with And-Or Graphs,” TPAMI, 2016. https://v.qq.com/x/page/
[8] A DARPA Perspective on AI, https://www.youtube.com/watch?v=-O01G3tSYpU&t=3s or https://v.qq.com/
[9] Z. Tu(屠卓文),X. Chen, A. L. Yuille, S.-C. Zhu(朱松纯), “Image parsing:Unifying segmentation, detection, and recognition,” IJCV, 2005.
[10] B. M. Lake, R. Salakhutdinov, J. B. Tenenbaum, “Human-level concept learningthrough probabilistic program induction,” Science, 2015.

版权声明:本原创文章版权属于《视觉求索》公众号。任何单位或个人未经本公众号的授权,不得擅自转载。联系授权转载请通过订阅公众号后发消息或电邮visionseekereditors@gmail.com。




