Redis 作为一种非常流行的内存数据库,通过将数据保存在内存中,Redis 得以拥有极高的读写性能。但是一旦进程退出,Redis 的数据就会全部丢失。
为了解决这个问题,Redis 提供了 RDB 和 AOF 两种持久化方案,将内存中的数据保存到磁盘中,避免数据丢失。本文将重点讨论AOF持久化方案,以及其存在的一些问题,并探讨在Redis 7.0 (已发布RC1) 中Multi Part AOF(下文简称为MP-AOF,
本特性由阿里云数据库Tair团队贡献
)设计和实现细节。
一 AOF
AOF( append only file )持久化以独立日志文件的方式记录每条写命令,并在 Redis 启动时回放 AOF 文件中的命令以达到恢复数据的目的。
由于AOF会以追加的方式记录每一条redis的写命令,因此随着Redis处理的写命令增多,AOF文件也会变得越来越大,命令回放的时间也会增多,为了解决这个问题,Redis引入了AOF rewrite机制(下文称之为AOFRW)。AOFRW会移除AOF中冗余的写命令,以等效的方式重写、生成一个新的AOF文件,来达到减少AOF文件大小的目的。
二 AOFRW
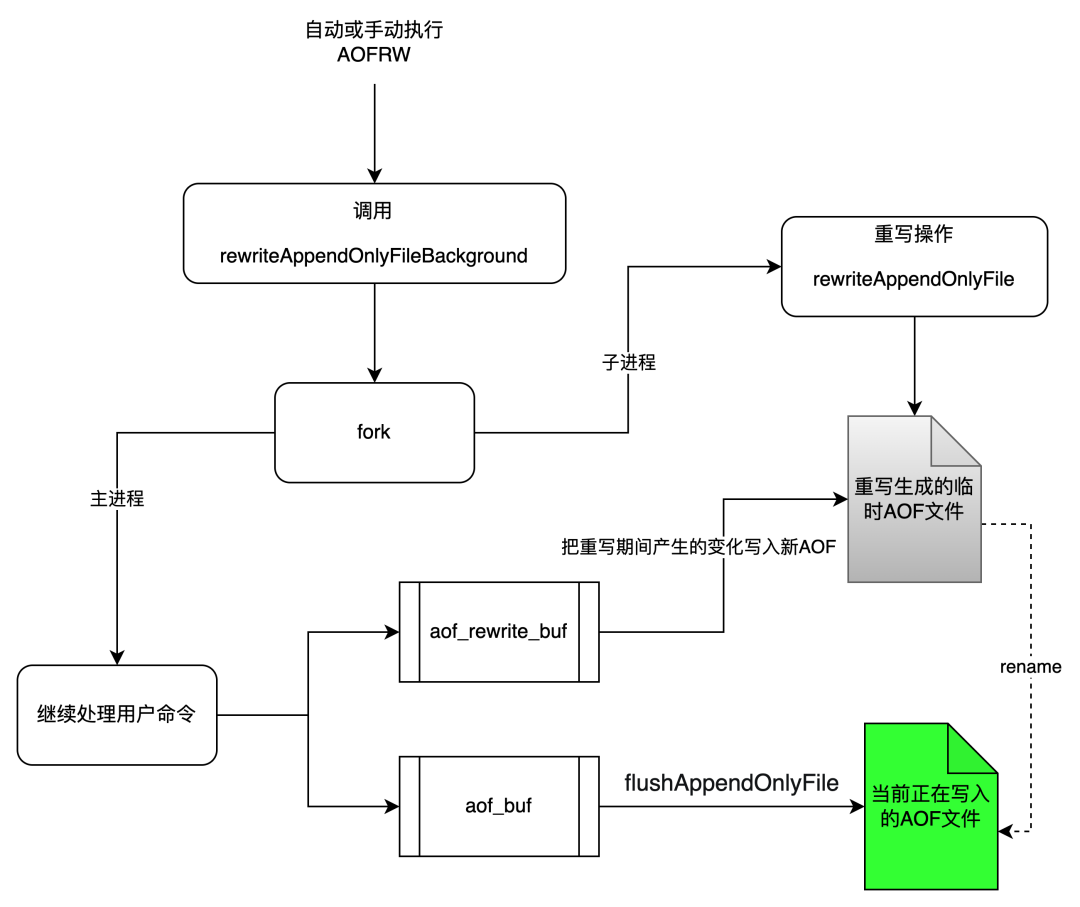
图1展示的是AOFRW的实现原理。当AOFRW被触发执行时,Redis首先会fork一个子进程进行后台重写操作,该操作会将执行fork那一刻Redis的数据快照全部重写到一个名为temp-rewriteaof-bg-pid.aof的临时AOF文件中。
由于重写操作为子进程后台执行,主进程在AOF重写期间依然可以正常响应用户命令。因此,为了让子进程最终也能获取重写期间主进程产生的增量变化,主进程除了会将执行的写命令写入aof_buf,还会写一份到aof_rewrite_buf中进行缓存。在子进程重写的后期阶段,主进程会将aof_rewrite_buf中累积的数据使用pipe发送给子进程,子进程会将这些数据追加到临时AOF文件中(详细原理可参考[1])。
当主进程承接了较大的写入流量时,aof_rewrite_buf中可能会堆积非常多的数据,导致在重写期间子进程无法将aof_rewrite_buf中的数据全部消费完。此时,aof_rewrite_buf剩余的数据将在重写结束时由主进程进行处理。
当子进程完成重写操作并退出后,主进程会在
backgroundRewriteDoneHandler
中处理后续的事情。首先,将重写期间aof_rewrite_buf中未消费完的数据追加到临时AOF文件中。其次,当一切准备就绪时,Redis会使用
rename
操作将临时AOF文件原子的重命名为server.aof_filename,此时原来的AOF文件会被覆盖。至此,整个AOFRW流程结束。
三 AOFRW存在的问题
1 内存开销
由图1可以看到,在AOFRW期间,主进程会将fork之后的数据变化写进aof_rewrite_buf中,aof_rewrite_buf和aof_buf中的内容绝大部分都是重复的,因此这将带来额外的内存冗余开销。
在Redis INFO中的aof_rewrite_buffer_length字段可以看到当前时刻aof_rewrite_buf占用的内存大小。如下面显示的,在高写入流量下aof_rewrite_buffer_length几乎和aof_buffer_length占用了同样大的内存空间,几乎浪费了一倍的内存。
aof_pending_rewrite:0aof_buffer_length:35500aof_rewrite_buffer_length:34000aof_pending_bio_fsync:0
当aof_rewrite_buf占用的内存大小超过一定阈值时,我们将在Redis日志中看到如下信息。可以看到,aof_rewrite_buf占用了100MB的内存空间且主进程和子进程之间传输了2135MB的数据(子进程在通过pipe读取这些数据时也会有内部读buffer的内存开销)。
对于内存型数据库Redis而言,这是一笔不小的开销。
3351:M 25 Jan 2022 09:55:39.655 * Background append only file rewriting started by pid 68173351:M 25 Jan 2022 09:57:51.864 * AOF rewrite child asks to stop sending diffs.6817:C 25 Jan 2022 09:57:51.864 * Parent agreed to stop sending diffs. Finalizing AOF...6817:C 25 Jan 2022 09:57:51.864 * Concatenating 2135.60 MB of AOF diff received from parent.3351:M 25 Jan 2022 09:57:56.545 * Background AOF buffer size: 100 MB
AOFRW带来的内存开销有可能导致Redis内存突然达到maxmemory限制,从而影响正常命令的写入,甚至会触发操作系统限制被OOM Killer杀死,导致Redis不可服务。
2 CPU开销
-
在AOFRW期间,主进程需要花费CPU时间向aof_rewrite_buf写数据,并使用eventloop事件循环向子进程发送aof_rewrite_buf中的数据:
void aofRewriteBufferAppend(unsigned char *s, unsigned long len) {
if (!server.aof_stop_sending_diff && aeGetFileEvents(server.el,server.aof_pipe_write_data_to_child) == 0) { aeCreateFileEvent(server.el, server.aof_pipe_write_data_to_child, AE_WRITABLE, aofChildWriteDiffData, NULL); }
}
-
在子进程执行重写操作的后期,会循环读取pipe中主进程发送来的增量数据,然后追加写入到临时AOF文件:
int rewriteAppendOnlyFile(char *filename) {
int nodata = 0; mstime_t start = mstime(); while(mstime()-start < 1000 && nodata < 20) { if (aeWait(server.aof_pipe_read_data_from_parent, AE_READABLE, 1) <= 0) { nodata++; continue; } nodata = 0; aofReadDiffFromParent(); }
}
-
在子进程完成重写操作后,主进程会在
backgroundRewriteDoneHandler
中进行收尾工作。其中一个任务就是将在重写期间aof_rewrite_buf中没有消费完成的数据写入临时AOF文件。如果aof_rewrite_buf中遗留的数据很多,这里也将消耗CPU时间。
void backgroundRewriteDoneHandler(int exitcode, int bysignal) {
if (aofRewriteBufferWrite(newfd) == -1) { serverLog(LL_WARNING, "Error trying to flush the parent diff to the rewritten AOF: %s", strerror(errno)); close(newfd); goto cleanup; }
}
AOFRW带来的CPU开销可能会造成Redis在执行命令时出现RT上的抖动,甚至造成客户端超时的问题。
3 磁盘IO开销
如前文所述,在AOFRW期间,主进程除了会将执行过的写命令写到aof_buf之外,还会写一份到aof_rewrite_buf中。aof_buf中的数据最终会被写入到当前使用的旧AOF文件中,产生磁盘IO。同时,aof_rewrite_buf中的数据也会被写入重写生成的新AOF文件中,产生磁盘IO。因此,同一份数据会产生两次磁盘IO。
4 代码复杂度
Redis使用下面所示的六个pipe进行主进程和子进程之间的数据传输和控制交互,这使得整个AOFRW逻辑变得更为复杂和难以理解。
int aof_pipe_write_data_to_child; int aof_pipe_read_data_from_parent; int aof_pipe_write_ack_to_parent; int aof_pipe_read_ack_from_child; int aof_pipe_write_ack_to_child; int aof_pipe_read_ack_from_parent;
四 MP-AOF实现
1 方案概述
顾名思义,MP-AOF就是将原来的单个AOF文件拆分成多个AOF文件。在MP-AOF中,我们将AOF分为三种类型,分别为:
-
BASE:表示基础AOF,它一般由子进程通过重写产生,该文件最多只有一个。
-
INCR:表示增量AOF,它一般会在AOFRW开始执行时被创建,该文件可能存在多个。
-
HISTORY:表示历史AOF,它由BASE和INCR AOF变化而来,每次AOFRW成功完成时,本次AOFRW之前对应的BASE和INCR AOF都将变为HISTORY,HISTORY类型的AOF会被Redis自动删除。
为了管理这些AOF文件,我们引入了一个manifest(清单)文件来跟踪、管理这些AOF。同时,为了便于AOF备份和拷贝,我们将所有的AOF文件和manifest文件放入一个单独的文件目录中,目录名由appenddirname配置(Redis 7.0新增配置项)决定。
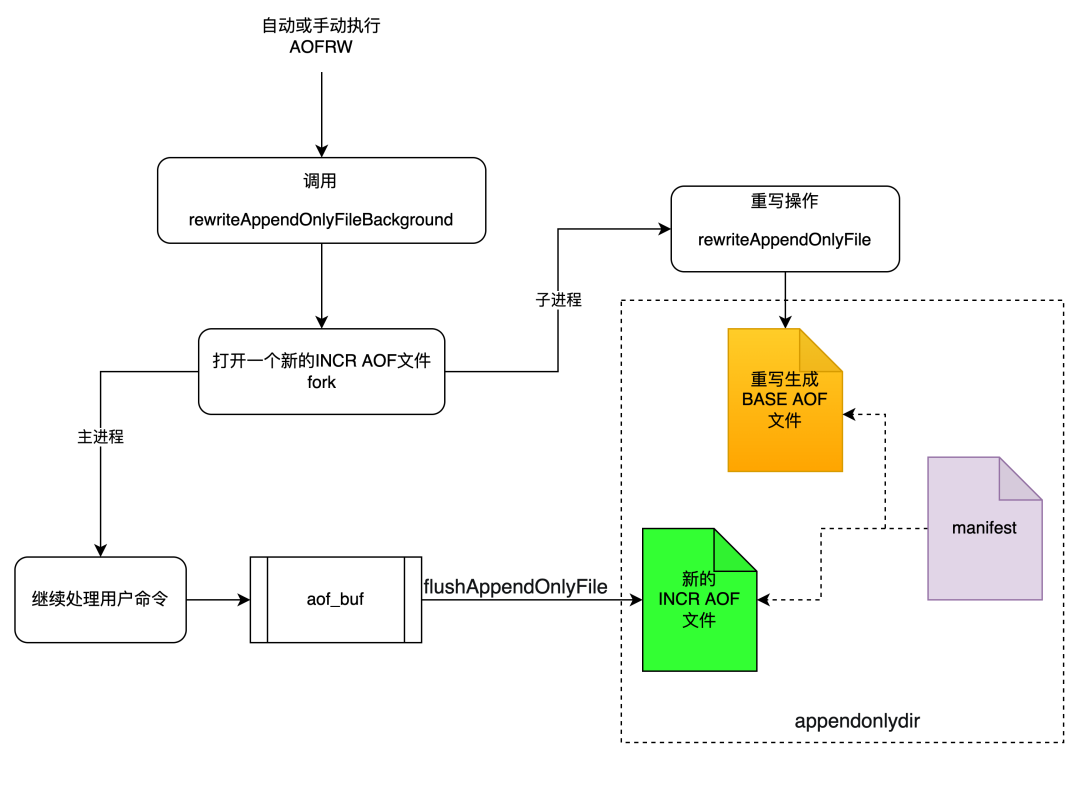
图2展示的是在MP-AOF中执行一次AOFRW的大致流程。在开始时我们依然会fork一个子进程进行重写操作,在主进程中,我们会同时打开一个新的INCR类型的AOF文件,在子进程重写操作期间,所有的数据变化都会被写入到这个新打开的INCR AOF中。子进程的重写操作完全是独立的,重写期间不会与主进程进行任何的数据和控制交互,最终重写操作会产生一个BASE AOF。新生成的BASE AOF和新打开的INCR AOF就代表了当前时刻Redis的全部数据。AOFRW结束时,主进程会负责更新manifest文件,将新生成的BASE AOF和INCR AOF信息加入进去,并将之前的BASE AOF和INCR AOF标记为HISTORY(这些HISTORY AOF会被Redis异步删除)。一旦manifest文件更新完毕,就标志整个AOFRW流程结束。
由图2可以看到,我们在AOFRW期间不再需要aof_rewrite_buf,因此去掉了对应的内存消耗。同时,主进程和子进程之间也不再有数据传输和控制交互,因此对应的CPU开销也全部去掉。对应的,前文提及的六个pipe及其对应的代码也全部删除,使得AOFRW逻辑更加简单清晰。
2 关键实现
Manifest
1)在内存中的表示
MP-AOF强依赖manifest文件,manifest在内存中表示为如下结构体,其中:
-
aofInfo:表示一个AOF文件信息,当前仅包括文件名、文件序号和文件类型
-
base_aof_info:表示BASE AOF信息,当不存在BASE AOF时,该字段为NULL
-
incr_aof_list:用于存放所有INCR AOF文件的信息,所有的INCR AOF都会按照文件打开顺序排放
-
history_aof_list:用于存放HISTORY AOF信息,history_aof_list中的元素都是从base_aof_info和incr_aof_list中move过来的
typedef struct { sds file_name; long long file_seq; aof_file_type file_type; } aofInfo;
typedef struct { aofInfo *base_aof_info; list *incr_aof_list; list *history_aof_list; long long curr_base_file_seq; long long curr_incr_file_seq; int dirty; } aofManifest;
为了便于原子性修改和回滚操作,我们在redisServer结构中使用指针的方式引用aofManifest。
struct redisServer {
aofManifest *aof_manifest;
}
2)在磁盘上的表示
Manifest本质就是一个包含多行记录的文本文件,每一行记录对应一个AOF文件信息,这些信息通过key/value对的方式展示,便于Redis处理、易于阅读和修改。下面是一个可能的manifest文件内容:
file appendonly.aof.1.base.rdb seq 1 type bfile appendonly.aof.1.incr.aof seq 1 type ifile appendonly.aof.2.incr.aof seq 2 type i
Manifest格式本身需要具有一定的扩展性,以便将来添加或支持其他的功能。比如可以方便的支持新增key/value和注解(类似AOF中的注解),这样可以保证较好的forward compatibility。
file appendonly.aof.1.base.rdb seq 1 type b newkey newvaluefile appendonly.aof.1.incr.aof type i seq 1 # this is annotationsseq 2 type i file appendonly.aof.2.incr.aof
文件命名规则
在MP-AOF之前,AOF的文件名为appendfilename参数的设置值(默认为appendonly.aof)。
在MP-AOF中,我们使用basename.suffix的方式命名多个AOF文件。其中,appendfilename配置内容将作为basename部分,suffix则由三个部分组成,格式为seq.type.format ,其中:
-
seq为文件的序号,由1开始单调递增,BASE和INCR拥有独立的文件序号
-
type为AOF的类型,表示这个AOF文件是BASE还是INCR
-
format用来表示这个AOF内部的编码方式,由于Redis支持RDB preamble机制,因此BASE AOF可能是RDB格式编码也可能是AOF格式编码:
#define BASE_FILE_SUFFIX ".base"#define INCR_FILE_SUFFIX ".incr"#define RDB_FORMAT_SUFFIX ".rdb"#define AOF_FORMAT_SUFFIX ".aof"#define MANIFEST_NAME_SUFFIX ".manifest"
因此,当使用appendfilename默认配置时,BASE、INCR和manifest文件的可能命名如下:
appendonly.aof.1.base.rdb appendonly.aof.1.base.aof appendonly.aof.1.incr.aofappendonly.aof.2.incr.aof
兼容老版本升级
由于MP-AOF强依赖manifest文件,Redis启动时会严格按照manifest的指示加载对应的AOF文件。但是在从老版本Redis(指Redis 7.0之前的版本)升级到Redis 7.0时,由于此时并无manifest文件,因此如何让Redis正确识别这是一个升级过程并正确、安全的加载旧AOF是一个必须支持的能力。
识别能力是这一重要过程的首要环节,在真正加载AOF文件之前,我们会检查Redis工作目录下是否存在名为server.aof_filename的AOF文件。如果存在,那说明我们可能在从一个老版本Redis执行升级,接下来,我们会继续判断,当满足下面三种情况之一时我们会认为这是一个升级启动:
-
-
或者appenddirname目录存在,但是目录中没有对应的manifest清单文件
-
如果appenddirname目录存在且目录中存在manifest清单文件,且清单文件中只有BASE AOF相关信息,且这个BASE AOF的名字和server.aof_filename相同,且appenddirname目录中不存在名为server.aof_filename的文件
int loadAppendOnlyFiles(aofManifest *am) {
if (fileExist(server.aof_filename)) { if (!dirExists(server.aof_dirname) || (am->base_aof_info == NULL && listLength(am->incr_aof_list) == 0) || (am->base_aof_info != NULL && listLength(am->incr_aof_list) == 0 && !strcmp(am->base_aof_info->file_name, server.aof_filename) && !aofFileExist(server.aof_filename))) { aofUpgradePrepare(am); } }
}
一旦被识别为这是一个升级启动,我们会使用
aofUpgradePrepare
函数进行升级前的准备工作。
-
使用server.aof_filename作为文件名来构造一个BASE AOF信息
-
将该BASE AOF信息持久化到manifest文件
-
使用
rename
将旧AOF文件移动到appenddirname目录中
void aofUpgradePrepare(aofManifest *am) {
if (am->base_aof_info) aofInfoFree(am->base_aof_info); aofInfo *ai = aofInfoCreate(); ai->file_name = sdsnew(server.aof_filename); ai->file_seq = 1; ai->file_type = AOF_FILE_TYPE_BASE; am->base_aof_info = ai; am->curr_base_file_seq = 1; am->dirty = 1;
if (persistAofManifest(am) != C_OK) { exit(1); }
sds aof_filepath = makePath(server.aof_dirname, server.aof_filename); if (rename(server.aof_filename, aof_filepath) == -1) { sdsfree(aof_filepath); exit(1);; }
}
升级准备操作是Crash Safety的,以上三步中任何一步发生Crash我们都能在下一次的启动中正确的识别并重试整个升级操作。
多文件加载及进度计算
Redis在加载AOF时会记录加载的进度,并通过Redis INFO的loading_loaded_perc字段展示出来。在MP-AOF中,
loadAppendOnlyFiles
函数会根据传入的aofManifest进行AOF文件加载。在进行加载之前,我们需要提前计算所有待加载的AOF文件的总大小,并传给
startLoading
函数,然后在
loadSingleAppendOnlyFile
中不断的上报加载进度。
接下来,
loadAppendOnlyFiles
会根据aofManifest依次加载BASE AOF和INCR AOF。当前加载完所有的AOF文件,会使用
stopLoading
结束加载状态。
int loadAppendOnlyFiles(aofManifest *am) {
total_size = getBaseAndIncrAppendOnlyFilesSize(am); startLoading(total_size, RDBFLAGS_AOF_PREAMBLE, 0);
if (am->base_aof_info) { aof_name = (char*)am->base_aof_info->file_name; updateLoadingFileName(aof_name); loadSingleAppendOnlyFile(aof_name); }
if (listLength(am->incr_aof_list)) { listNode *ln; listIter li;
listRewind(am->incr_aof_list, &li); while ((ln = listNext(&li)) != NULL) { aofInfo *ai = (aofInfo*)ln->value; aof_name = (char*)ai->file_name; updateLoadingFileName(aof_name); loadSingleAppendOnlyFile(aof_name); } }
server.aof_current_size = total_size; server.aof_rewrite_base_size = server.aof_current_size; server.aof_fsync_offset = server.aof_current_size;
stopLoading();
}
AOFRW Crash Safety
当子进程完成重写操作,子进程会创建一个名为temp-rewriteaof-bg-pid.aof的临时AOF文件,此时这个文件对Redis而言还是不可见的,因为它还没有被加入到manifest文件中。要想使得它能被Redis识别并在Redis启动时正确加载,我们还需要将它按照前文提到的命名规则进行
rename
操作,并将其信息加入到manifest文件中。
AOF文件
rename
和manifest文件修改虽然是两个独立操作,但我们必须保证这两个操作的原子性,这样才能让Redis在启动时能正确的加载对应的AOF。MP-AOF使用两个设计来解决这个问题:
-
BASE AOF的名字中包含文件序号,保证每次创建的BASE AOF不会和之前的BASE AOF冲突;
-
先执行AOF的
rename
操作,再修改manifest文件;
为了便于说明,我们假设在AOFRW开始之前,manifest文件内容如下:
file appendonly.aof.1.base.rdb seq 1 type bfile appendonly.aof.1.incr.aof seq 1 type i
则在AOFRW开始执行后manifest文件内容如下:
file appendonly.aof.1.base.rdb seq 1 type bfile appendonly.aof.1.incr.aof seq 1 type ifile appendonly.aof.2.incr.aof seq 2 type i
子进程重写结束后,在主进程中,我们会将temp-rewriteaof-bg-pid.aof重命名为appendonly.aof.2.base.rdb,并将其加入manifest中,同时会将之前的BASE和INCR AOF标记为HISTORY。此时manifest文件内容如下:
file appendonly.aof.2.base.rdb seq 2 type bfile appendonly.aof.1.base.rdb seq 1 type hfile appendonly.aof.1.incr.aof seq 1 type hfile appendonly.aof.2.incr.aof seq 2 type i
此时,本次AOFRW的结果对Redis可见,HISTORY AOF会被Redis异步清理。
backgroundRewriteDoneHandler
函数通过七个步骤实现了上述逻辑:
-
在修改内存中的server.aof_manifest前,先dup一份临时的manifest结构,接下来的修改都将针对这个临时的manifest进行。这样做的好处是,一旦后面的步骤出现失败,我们可以简单的销毁临时manifest从而回滚整个操作,避免污染server.aof_manifest全局数据结构;
-
从临时manifest中获取新的BASE AOF文件名(记为new_base_filename),并将之前(如果有)的BASE AOF标记为HISTORY;
-
将子进程产生的temp-rewriteaof-bg-pid.aof临时文件重命名为new_base_filename;
-
将临时manifest结构中上一次的INCR AOF全部标记为HISTORY类型;
-
将临时manifest对应的信息持久化到磁盘(persistAofManifest内部会保证manifest本身修改的原子性);
-
如果上述步骤都成功了,我们可以放心的将内存中的server.aof_manifest指针指向临时的manifest结构(并释放之前的manifest结构),至此整个修改对Redis可见;
-
清理HISTORY类型的AOF,该步骤允许失败,因为它不会导致数据一致性问题。
void backgroundRewriteDoneHandler(int exitcode, int bysignal) { snprintf(tmpfile, 256, "temp-rewriteaof-bg-%d.aof", (int)server.child_pid);
temp_am = aofManifestDup(server.aof_manifest);
new_base_filename = getNewBaseFileNameAndMarkPreAsHistory(temp_am);
if (rename(tmpfile, new_base_filename) == -1) { aofManifestFree(temp_am); goto cleanup; }
markRewrittenIncrAofAsHistory(temp_am);
if (persistAofManifest(temp_am) == C_ERR) { bg_unlink(new_base_filename); aofManifestFree(temp_am); goto cleanup; }
aofManifestFreeAndUpdate(temp_am);
aofDelHistoryFiles();}
支持AOF truncate
在进程出现Crash时AOF文件很可能出现写入不完整的问题,如一条事务里只写了MULTI,但是还没写EXEC时Redis就Crash。默认情况下,Redis无法加载这种不完整的AOF,但是Redis支持AOF truncate功能(通过
aof-load-truncated
配置打开)。其原理是使用server.aof_current_size跟踪AOF最后一个正确的文件偏移,然后使用
ftruncate
函数将该偏移之后的文件内容全部删除,这样虽然可能会丢失部分数据,但可以保证AOF的完整性。
在MP-AOF中,server.aof_current_size已经不再表示单个AOF文件的大小而是所有AOF文件的总大小。因为只有最后一个INCR AOF才有可能出现不完整写入的问题,因此我们引入了一个单独的字段server.aof_last_incr_size用于跟踪最后一个INCR AOF文件的大小。当最后一个INCR AOF出现不完整写入时,我们只需要将server.aof_last_incr_size之后的文件内容删除即可。
if (ftruncate(server.aof_fd, server.aof_last_incr_size) == -1) { }
AOFRW限流
Redis在AOF大小超过一定阈值时支持自动执行AOFRW,当出现磁盘故障或者触发了代码bug导致AOFRW失败时,Redis将不停的重复执行AOFRW直到成功为止。在MP-AOF出现之前,这看似没有什么大问题(顶多就是消耗一些CPU时间和fork开销)。但是在MP-AOF中,因为每次AOFRW都会打开一个INCR AOF,并且只有在AOFRW成功时才会将上一个INCR和BASE转为HISTORY并删除。因此,连续的AOFRW失败势必会导致多个INCR AOF并存的问题。极端情况下,如果AOFRW重试频率很高我们将会看到成百上千个INCR AOF文件。
为此,我们引入了AOFRW限流机制。即当AOFRW已经连续失败三次时,下一次的AOFRW会被强行延迟1分钟执行,如果下一次AOFRW依然失败,则会延迟2分钟,依次类推延迟4、8、16...,当前最大延迟时间为1小时。
在AOFRW限流期间,我们依然可以使用bgrewriteaof命令立即执行一次AOFRW。
if (server.aof_state == AOF_ON && !hasActiveChildProcess() && server.aof_rewrite_perc && server.aof_current_size > server.aof_rewrite_min_size && !aofRewriteLimited()){ long long base = server.aof_rewrite_base_size ? server.aof_rewrite_base_size : 1; long long growth = (server.aof_current_size*100/base) - 100; if (growth >= server.aof_rewrite_perc) { rewriteAppendOnlyFileBackground(); }}
AOFRW限流机制的引入,还可以有效的避免AOFRW高频重试带来的CPU和fork开销。Redis中很多的RT抖动都和fork有关系。
五 总结
MP-AOF的引入,成功的解决了之前AOFRW存在的内存和CPU开销对Redis实例甚至业务访问带来的不利影响。同时,在解决这些问题的过程中,我们也遇到了很多未曾预料的挑战,这些挑战主要来自于Redis庞大的使用群体、多样化的使用场景,因此我们必须考虑用户在各种场景下使用MP-AOF可能遇到的问题。如兼容性、易用性以及对Redis代码尽可能的减少侵入性等。这都是Redis社区功能演进的重中之重。
同时,MP-AOF的引入也为Redis的数据持久化带来了更多的想象空间。如在开启aof-use-rdb-preamble时,BASE AOF本质是一个RDB文件,因此我们在进行全量备份的时候无需在单独执行一次BGSAVE操作。直接备份BASE AOF即可。MP-AOF支持关闭自动清理HISTORY AOF的能力,因此那些历史的AOF有机会得以保留,并且目前Redis已经支持在AOF中加入timestamp annotation,因此基于这些我们甚至可以实现一个简单的PITR能力( point-in-time recovery)。
MP-AOF的设计原型来自于Tair for redis企业版[2]的binlog实现,这是一套在阿里云Tair服务上久经验证的核心功能,在这个核心功能上阿里云Tair成功构建了全球多活、PITR等企业级能力,使用户的更多业务场景需求得到满足。今天我们将这个核心能力贡献给Redis社区,希望社区用户也能享受这些企业级特性,并通过这些企业级特性更好的优化,创造自己的业务代码。有关MP-AOF的更多细节,请移步参考相关PR(#9788),那里有更多的原始设计和完整代码。
[1]http://mysql.taobao.org/monthly/2018/12/06/
[2]https://help.aliyun.com/document_detail/145956.html
搜索与推荐技术实战训练营