并发场景下的幂等问题——分布式锁详解

写在前面:本文讨论的幂等问题,均为并发场景下的幂等问题。即系统本存在幂等设计,但是在并发场景下失效了。
一 摘要
二 问题
1 问题现象

2 问题原因
幂等(idempotent、idempotence)是一个数学与计算机学概念,常见于抽象代数中。
在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。
--来自百度百科
1)用户选择实人认证后会在服务端初始化一条记录;
2)用户在钉钉移动端按照指示完成人脸比对;
3)比对完成后访问服务端修改数据库状态。
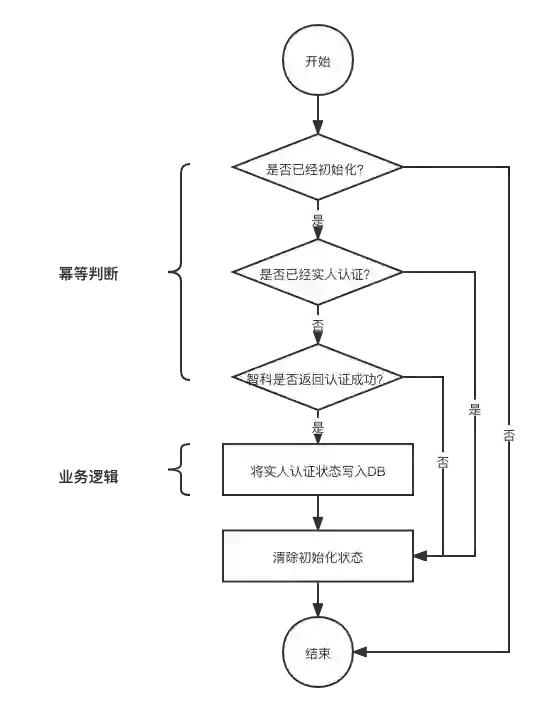
三 解决方案
-
与数据源交互,例如数据库状态变更等; -
与其他业务系统交互,例如调用下游服务或发送消息等;
四 分布式锁
In computer science, locks are mechanisms in a multithreaded environment to prevent different threads from operating on the same resource. When using locking, a resource is "locked" for access by a specific thread, and can only be accessed by a different thread once the resource has been released. Locks have several benefits: they stop two threads from doing the same work, and they prevent errors and data corruption when two threads try to use the same resource simultaneously.
Distributed locks in Java are locks that can work with not only multiple threads running on the same machine, but also threads running on clients on different machines in a distributed system. The threads on these separate machines must communicate and coordinate to make sure that none of them try to access a resource that has been locked up by another.
方案一
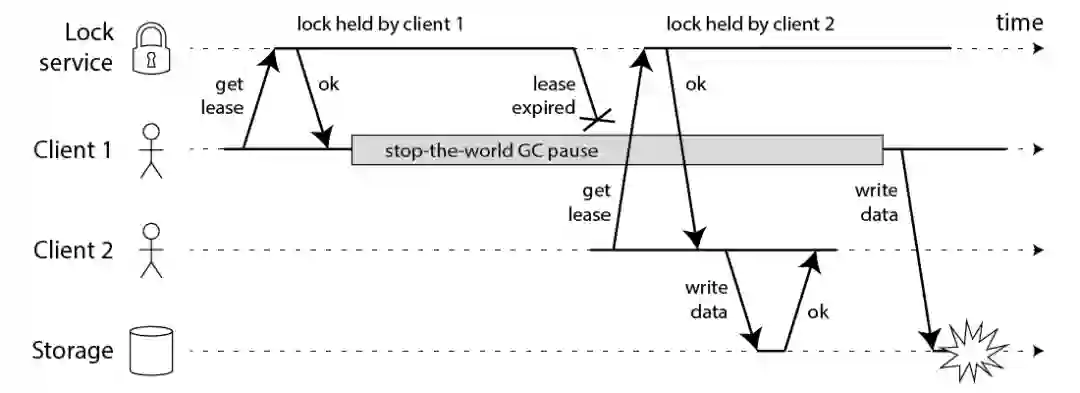
1)单点故障问题,即当持有锁的应用发生单点故障时,锁将被长期无效占有;
2)网络超时问题,即当客户端发生网络超时但实际上锁成功时,我们无法再次正确的
● 初始化分布式锁的工厂
● 利用工厂生成一个分布式锁实例
● 使用该分布式实例上锁和解锁操作
@Testpublic void testTryLock() {
//初始化工厂 MdbDistributeLockFactory mdbDistributeLockFactory = new MdbDistributeLockFactory(); mdbDistributeLockFactory.setNamespace(603); mdbDistributeLockFactory.setMtairManager(new MultiClusterTairManager());
//获得锁 DistributeLock lock = mdbDistributeLockFactory.getLock("TestLock");
//上锁解锁操作 boolean locked = lock.tryLock(); if (!locked) { return; } try { //do something } finally { lock.unlock(); }}
方案二
SET resource_name my_random_value NX PX 30000
if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1])else return 0end
方案三
1)一方面它很好的解决了持有锁的客户端单点故障的问题
2)另一方面,如果锁提前释放,就会出现锁的错误持有状态
private void renewExpiration() {ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());if (ee == null) {return;}Timeout task = commandExecutor.getConnectionManager().newTimeout(timeout -> {ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName());if (ent == null) {return;}Long threadId = ent.getFirstThreadId();if (threadId == null) {return;}RFuture<Boolean> future = renewExpirationAsync(threadId);future.onComplete((res, e) -> {if (e != null) {log.error("Can't update lock " + getRawName() + " expiration", e);EXPIRATION_RENEWAL_MAP.remove(getEntryName());return;}if (res) {// reschedule itselfrenewExpiration();} else {cancelExpirationRenewal(null);}});}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);ee.setTimeout(task);}
protected RFuture<Boolean> renewExpirationAsync(long threadId) {return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return 1; " +"end; " +"return 0;",Collections.singletonList(getRawName()),internalLockLeaseTime, getLockName(threadId));}
方案四
参考资料
https://redisson.org/glossary/java-distributed-lock.html
https://github.com/redisson/redisson/wiki/8.-distributed-locks-and-synchronizers
https://redis.io/topics/distlock?spm=ata.21736010.0.0.31f77e3aFs96rz
附录
分布式锁
public class MdbDistributeLock implements DistributeLock {/*** 锁的命名空间*/private final int namespace;/*** 锁对应的缓存key*/private final String lockName;/*** 锁的唯一标识,保证可重入,以应对put成功,但是返回超时的情况*/private final String lockId;/*** 是否持有锁。true:是*/private boolean locked;/*** 缓存实例*/private final TairManager tairManager;public MdbDistributeLock(TairManager tairManager, int namespace, String lockCacheKey) {this.tairManager = tairManager;this.namespace = namespace;this.lockName = lockCacheKey;this.lockId = UUID.randomUUID().toString();}@Overridepublic boolean tryLock() {try {//获取锁状态Result<DataEntry> getResult = null;ResultCode getResultCode = null;for (int cnt = 0; cnt < DEFAULT_RETRY_TIMES; cnt++) {getResult = tairManager.get(namespace, lockName);getResultCode = getResult == null ? null : getResult.getRc();if (noNeedRetry(getResultCode)) {break;}}//重入,已持有锁,返回成功if (ResultCode.SUCCESS.equals(getResultCode)&& getResult.getValue() != null && lockId.equals(getResult.getValue().getValue())) {locked = true;return true;}//不可获取锁,返回失败if (!ResultCode.DATANOTEXSITS.equals(getResultCode)) {log.error("tryLock fail code={} lock={} traceId={}", getResultCode, this, EagleEye.getTraceId());return false;}//尝试获取锁ResultCode putResultCode = null;for (int cnt = 0; cnt < DEFAULT_RETRY_TIMES; cnt++) {putResultCode = tairManager.put(namespace, lockName, lockId, MDB_CACHE_VERSION,DEFAULT_EXPIRE_TIME_SEC);if (noNeedRetry(putResultCode)) {break;}}if (!ResultCode.SUCCESS.equals(putResultCode)) {log.error("tryLock fail code={} lock={} traceId={}", getResultCode, this, EagleEye.getTraceId());return false;}locked = true;return true;} catch (Exception e) {log.error("DistributedLock.tryLock fail lock={}", this, e);}return false;}@Overridepublic void unlock() {if (!locked) {return;}ResultCode resultCode = tairManager.invalid(namespace, lockName);if (!resultCode.isSuccess()) {log.error("DistributedLock.unlock fail lock={} resultCode={} traceId={}", this, resultCode,EagleEye.getTraceId());}locked = false;}/*** 判断是否需要重试** @param resultCode 缓存的返回码* @return true:不用重试*/private boolean noNeedRetry(ResultCode resultCode) {return resultCode != null && !ResultCode.CONNERROR.equals(resultCode) && !ResultCode.TIMEOUT.equals(resultCode) && !ResultCode.UNKNOW.equals(resultCode);}}
分布式锁工厂
public class MdbDistributeLockFactory implements DistributeLockFactory {/*** 缓存的命名空间*/@Setterprivate int namespace;@Setterprivate MultiClusterTairManager mtairManager;@Overridepublic DistributeLock getLock(String lockName) {return new MdbDistributeLock(mtairManager, namespace, lockName);}}
数据库安全
登录查看更多
相关内容

数据库(
Database )或数据库管理系统(
Database management systems )是按照数据结构来组织、存储和管理数据的仓库。目前数据管理不再仅仅是存储和管理数据,而转变成用户所需要的各种数据管理的方式。
专知会员服务
148+阅读 · 2019年12月28日
Arxiv
0+阅读 · 2022年4月15日




相关VIP内容
专知会员服务
148+阅读 · 2019年12月28日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月15日