全新水下目标检测算法SWIPENet+IMA框架(已开源)
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:AI算法修炼营 | 论文已上传,文末附下载方式

论文地址:https://arxiv.org/abs/2005.11552.pdf
代码地址:https://github.com/LongChenCV/SWIPENet
近年来,基于深度学习的方法在标准的目标检测中取得了可喜的性能。水下目标检测仍具有以下几点挑战:(1)水下场景的实际应用中目标通常很小,含有大量的小目标;(2)水下数据集和实际应用中的图像通常是模糊的,图像中具有异构的噪声。
为了解决小目标检测和噪声这两个问题,本文首先提出了一种新颖的神经网络架构,即用于小物体检测的样本加权混合网络(SWIPENet)。SWIPENet由高分辨率和语义丰富的超特征图组成,可以显著提高小物体检测的准确性。此外,提出了一种新的样本加权损失函数,该函数可以为SWIPENet建模样本权重,它使用一种新颖的样本重新加权(Sample re-weighting)算法,即Invert Multi-Class Invert Adaboost(IMA),以减少噪声对提出的SWIPENet的影响。
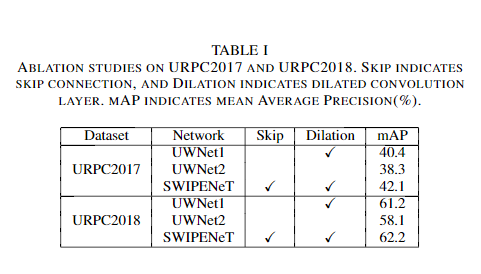
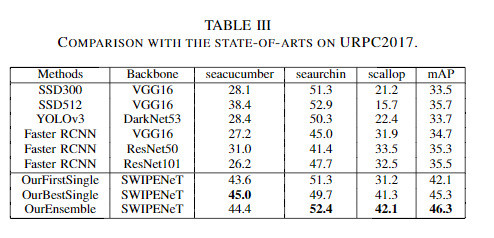
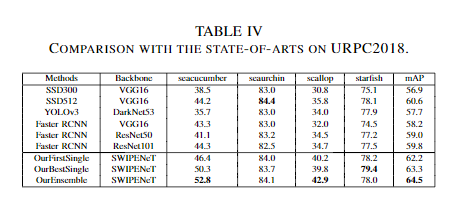
在两个水下机器人拾取竞赛数据集URPC2017和URPC2018进行的实验表明,与几种最先进的目标检测方法相比,本文提出的SWIPENet+IMA框架在检测精度上取得了较好的性能。
水下目标检测旨在对水下场景中的物体进行定位和识别。这项研究由于在海洋学、水下导航等领域的广泛应用而引起了持续的关注。但是,由于复杂的水下环境和光照条件,这仍然是一项艰巨的任务。
基于深度学习的物体检测系统已在各种应用中表现出较好的性能,但在处理水下目标检测方面仍然感到不足,主要有原因是:可用的水下目标检测数据集稀少,实际应用中的水下场景的图像杂乱无章,并且水下环境中的目标物体通常很小,而当前基于深度学习的目标检测器通常无法有效地检测小物体,或者对小目标物体的检测性能较差。同时,在水下场景中,与波长有关的吸收和散射问题大大降低了水下图像的质量,从而导致了可见度损失,弱对比度和颜色变化等问题。

卷积神经网络的下采样的使用能够带来强大的语义信息,从而导致许多分类任务的成功。然而,下采样操作对于目标检测任务来说是不够的,目标检测任务不仅需要识别物体的类别,而且还需要在空间上定位其位置。在应用了几次下采样操作之后会导致特征图的空间分辨率太粗糙,从而无法处理小物体的检测。
在本文中,提出了SWIPENet网络结构,该网络充分利用了受DSSD启发的几种高分辨率和语义丰富的Hyper 特征图。
先来介绍一下DSSD网络。
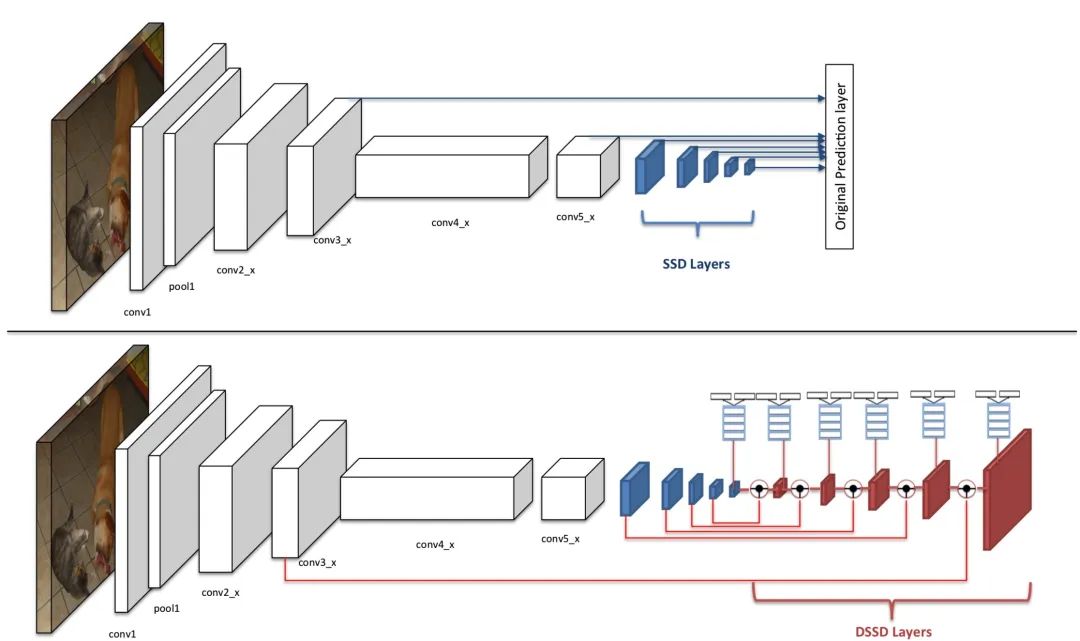
SSD利用了感受野与分辨率不同的6个特征图进行后续分类与回归网络的计算,DSSD保留了这6个特征图,但对这6个特征图进一步进行了融合处理,然后将融合后的结果送入后续分类与回归网络,如下图所示。具体做法是,将最深层的特征图直接用作分类与回归,接着,该特征经过一个反卷积模块,并与更浅一层的特征进行逐元素相乘,将输出的特征用于分类与回归计算。类似地,继续将该特征与浅层特征进行反卷积与融合,共计输出6个融合后的特征图,形成一个沙漏式的结构,最后给分类与回归网络做预测。
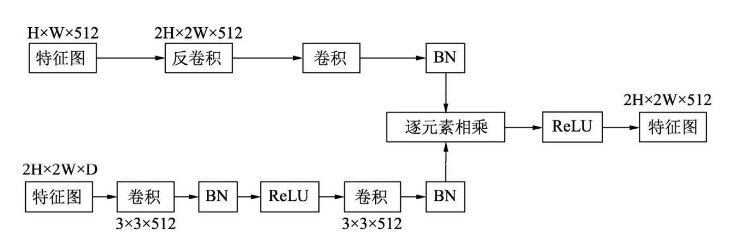
DSSD具体的反卷积模块如下图所示。这里深特征图的大小是H×W×512,浅特征图的大小为2H×2W×D。深特征图经过反卷积后尺寸与浅特征图相同,再经过一些卷积、ReLU与BN操作后,两者进行逐元素的相乘,最后经过一个ReLU模块,得到最终需要的特征图。
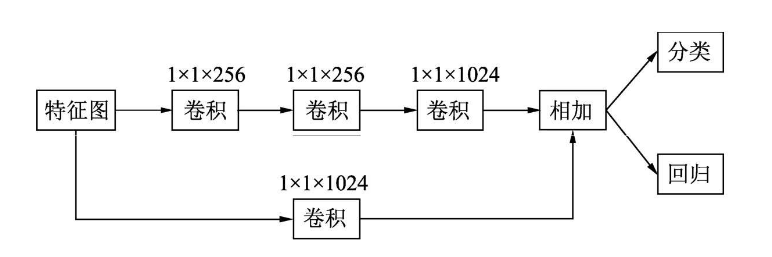
在得到特征图后,DSSD也改进了分类与回归的预测模块。SSD的预测模块是直接使用3×3卷积,而DSSD则对比了多种方法,最终选择了下图所示的计算方式,包含了一个残差单元,主路和旁路进行逐元素相加,然后再接到分类与回归的预测模块中。
可以看出,DSSD通过多个上采样反卷积层增强了SSD目标检测框架,以提高特征图的分辨率。在DSSD体系结构中,首先,构造多个下采样卷积层以提取有利于对象分类的高语义特征图。经过几次下采样操作后,特征图太粗糙而无法提供足够的信息来进行精确的小对象定位,因此,添加了多个上采样反卷积层和skip connection来恢复特征图的高分辨率。但是,即使恢复了分辨率,下采样操作丢失的详细信息也无法完全恢复。
为了改进DSSD,本文所提出的SWIPENet网络使用空洞卷积层来获得强语义信息,而不会丢失支持对象定位的详细信息。图2说明了提出的SWIPENet的基本结构,它由多个基本卷积块(红色),空洞卷积块(绿色),反卷积块(蓝色)和新的样本加权损失(灰色)组成。
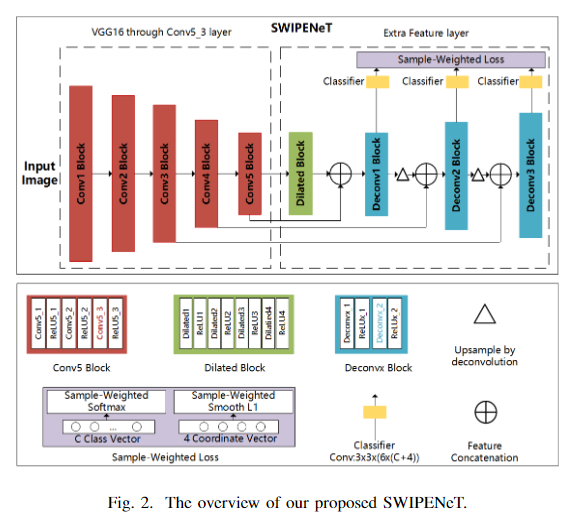
SWIPENet的主干网络采用的标准VGG16模型(在Conv53layer上被截断)。与DSSD不同的是,在网络上添加了四个具有ReLU激活的空洞卷积层,可以在不牺牲特征图分辨率的情况下获得较大的感受野(较大的感受野会带来强语义信息)。同时,skip connection将低层的精细细节传递给高层特征图。最后,在反卷积层上构造了多个Hyper Feature Map。SWIPENet的分类和回归预测模块上部署了三个不同的反卷积层,即Deconv12,Deconv22和Deconv32(在图2中表示为Deconvx2),它们的大小逐渐增加并预测多个尺度的对象。在三个反卷积层中定义了6个默认框和相对于原始默认框形状的4个坐标偏移,并使用3×3卷积产生C + 1类别的分数(C表示类别的数量,1指示背景类)。
Sample-weighting loss
本文提出了一种新颖的样本加权损失函数,可以在SWIPENeT中对样本权重进行建模。样本加权损失使SWIPENet可以专注于学习高权重样本,而忽略低权重样本。它能够与新颖的样本加权算法Invert Multi-Class Invert Adaboost配合使用,通过减少权重来减少可能的噪声对SWIPENet的影响。
样本加权损失L由用于边界框分类的损失Lcls和用于边界框回归的损失Lreg组成,Lcls使用softmax损失函数而Lreg使用L1平滑损失实现。
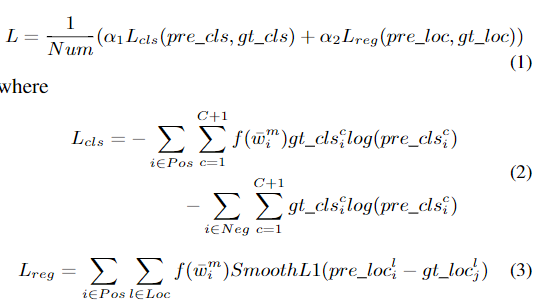
样本权重通过调整反向传播中使用的参数的梯度来影响SWIPENet的特征学习。
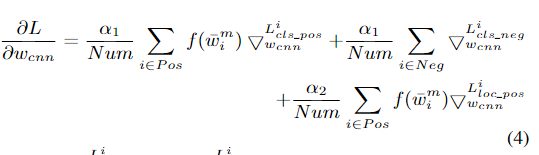
通过使用样本权重损失,使得SWIPENeT的特征学习主要由高权重样本决定,而低权重样本的特征学习则被忽略。
样本重加权可用于解决嘈杂的数据问题。它通常为每个样本分配一个权重,然后优化样本加权的训练损失。
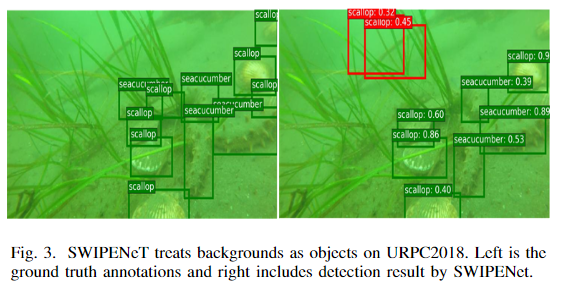
SWIPENet可能会丢失或错误地检测到训练集中的某些对象,这些目标对象可能被视为噪声数据。这是因为含有噪声的数据非常模糊,并且与背景相似,因此容易被忽略或检测为背景。如果我们使用这些嘈杂的数据训练SWIPENet,则性能可能会受到影响, SWIPENet无法将背景与物体区分开来。图3显示了示例测试图像及其通过SWIPENet的不正确检测。
为了解决这个问题,受文章《Inverse boosting pruning trees for depression detection on Twitter》(https://arxiv.org/abs/1906.00398)的启发提出一种IMA算法,以减少不确定对象的权重,以提高SWIPENet的检测精度。
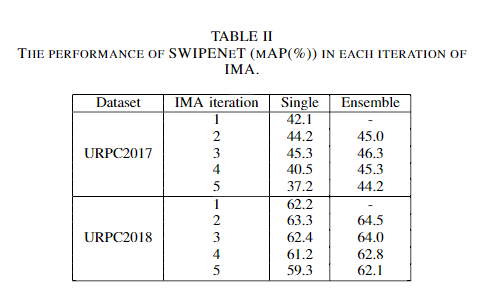
IMA算法首先顺序训练多个基本分类器,并根据其错误率Em分配权重值α。然后,将由前面的分类器分类错误的样本分配较高的权重,从而使后面的分类器专注于学习这些样本。最后,将所有弱基础分类器组合在一起,形成具有相应权重的整体分类器。IMA还训练了M次SWIPENet,然后将它们整合为一个统一模型。不同的是,在每次训练迭代中,IMA都会减少丢失对象的权重,以减少这些“干扰”样本的影响。

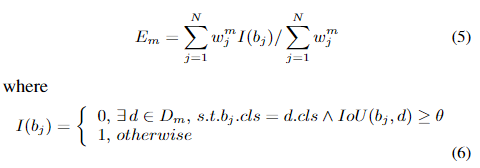
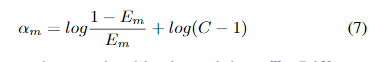
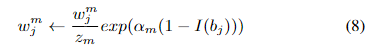

IMA算法同时定义了一个线性映射函数将IMA权重映射到样本加权损失中使用的权重。
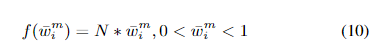
更多细节可以参考论文原文
论文下载
在CVer公众号后台回复:检测0601,即可下载本论文
CVer-目标检测 交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集4000人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加群
![]()
▲长按关注我们
请给CVer一个在看!![]()



