CIKM 2019 挑战杯冠军方案分享:「初筛-精排」两阶求解框架
 作者 | 杨鲤萍
作者 | 杨鲤萍


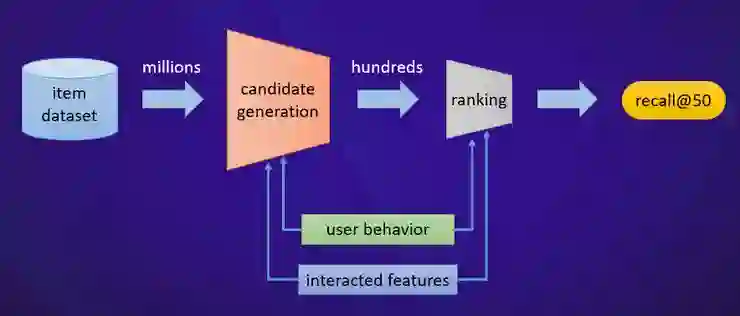
如果一名用户点击了某个商品,那么该用户对该商品所在类目的商品具有一定程度的偏好,如:iPhone,Mate 30->MI MIX Alpha(智能手机类目);
如果一名用户点击了某个商品,那么该用户对该商品所在主题的商品具有一定程度的偏好,如:沙滩裤,太阳眼镜->防晒霜(沙滩旅行主题)。
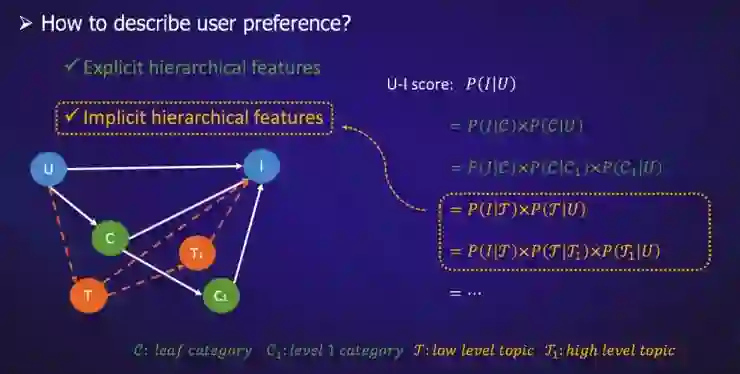
基于类目的层次偏好:iPhone,Mate 30->MI MIX Alpha(智能手机)->Canon EOS 相机(电子产品);
基于用户兴趣主题的层次偏好:沙滩裤,太阳眼镜->防晒霜(沙滩旅行)->运动鞋(户外旅行)。这里的沙滩旅行和户外旅行都是用户兴趣层面的表达。
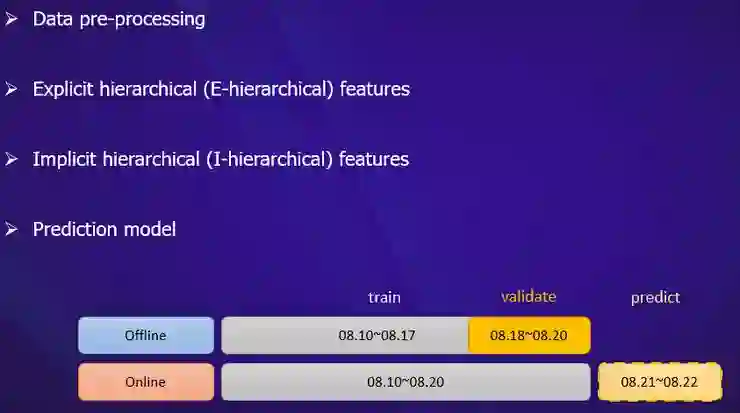
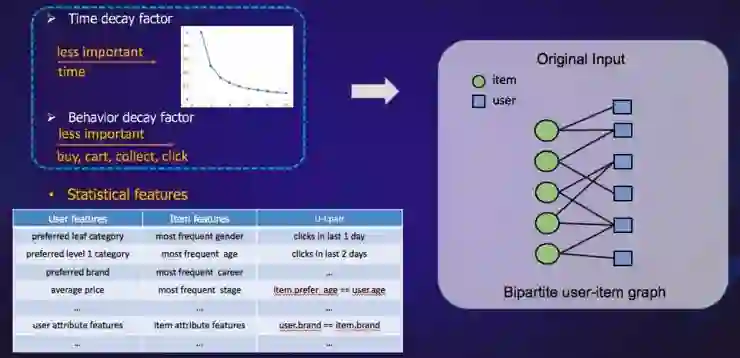
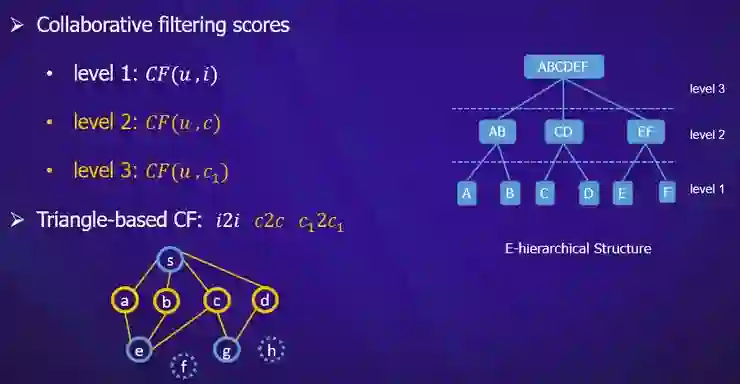
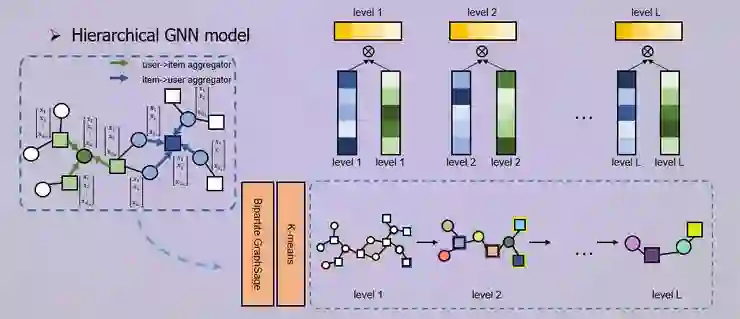
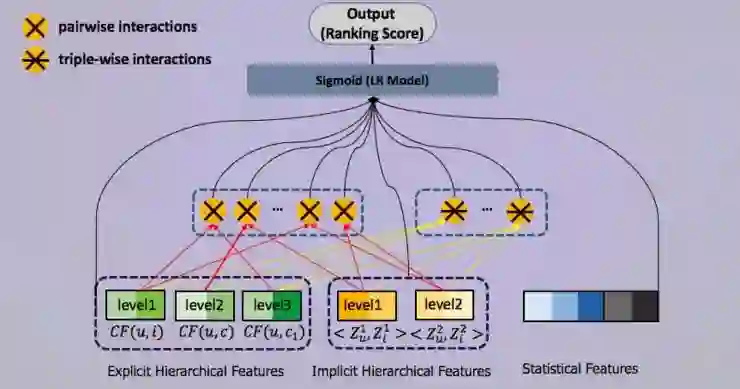
version1 基于协同过滤+统计特征
version2 基于显性层次特征+统计特征
version3 基于显性/隐形层次特征+统计特征
version4 基于二阶结构特征交叉+统计特征
version5 基于三阶结构特征交叉+统计特征





登录查看更多
相关内容

专知会员服务
44+阅读 · 2019年11月20日
Arxiv
4+阅读 · 2018年9月6日




相关VIP内容
专知会员服务
44+阅读 · 2019年11月20日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年9月6日