VIPKID实时计算技术实践


文章作者:甄国有@VIPKID
内容来源:Flink中文社区
VIPKID 介绍
核心业务场景
技术实现
-
总结
VIPKID 介绍
核心业务场景
主要场景介绍
当前业务痛点
问题处理不及时,用户容易等待,阻断上课,带给用户体验差;
人工处理效率低,课量增加以及大规模突发情况下,导致 FM 团队规模增加,需要更多人力;
有些用户出了问题,没有联系监课人员的话,问题被隐藏;
技术实现
数据体系建设:介绍用于支撑整个实时计算的 Vlink 数据平台、当前场景下相关业务数据采集和业务标签数据计算,是业务实现的支撑
自动化业务系统:介绍如何应用实时数据流来解决当前业务痛点
问题与优化:介绍实现过程中碰到的业务和技术问题以及解决方案
收益效果:介绍最终获得的收益成果
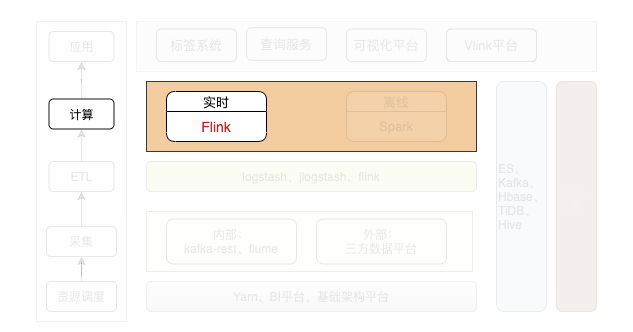
数据体系建设
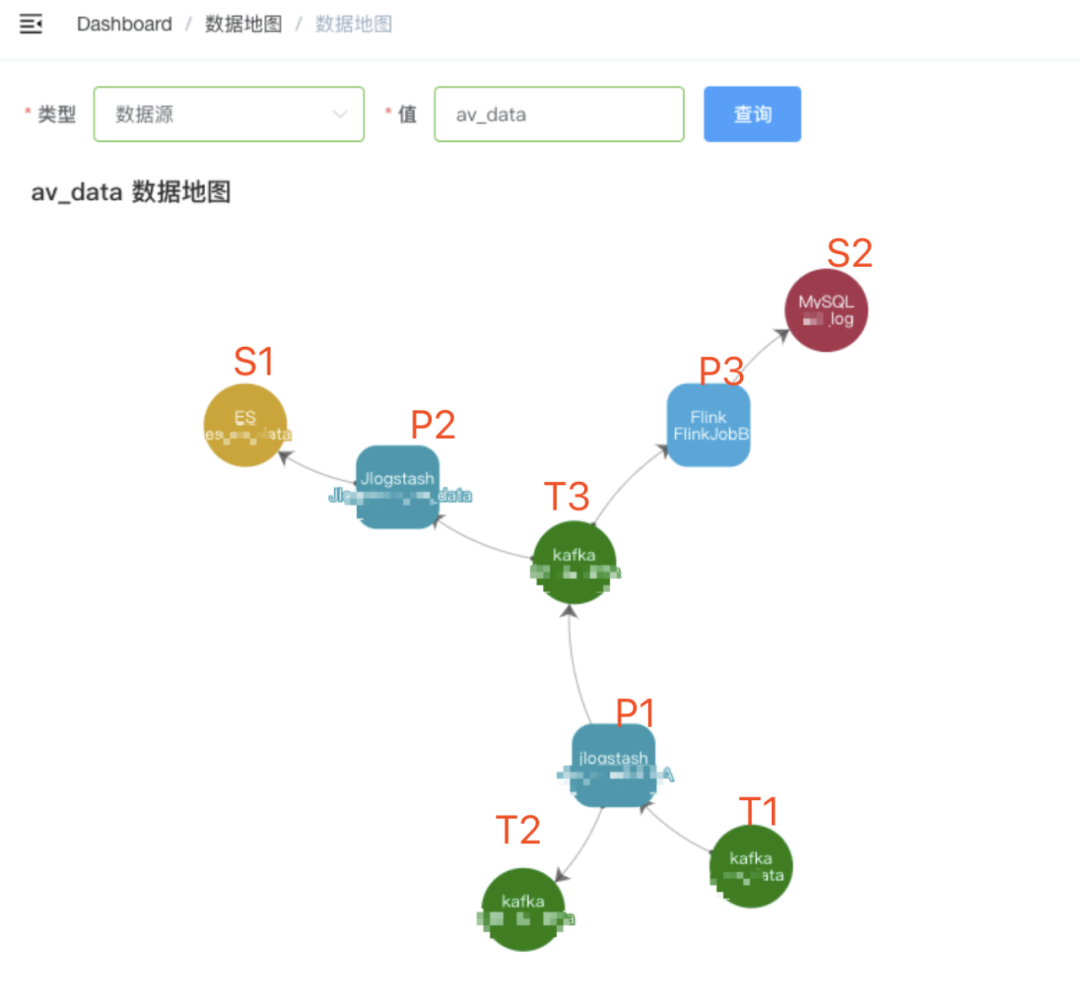
Vlink 数据平台:介绍一站式数据平台,提供数据接入明细:
a.数据来源;
b.数据的业务含义;
c.数据打点规律,提高开发接入效率,解决上下游不明确问题;
业务数据采集:介绍当前场景下的业务数据采集;
业务数据计算:介绍如何应用Flink来计算复杂逻辑的业务数据;
■ Vlink 数据平台
主要功能点
1. 交互式运行作业
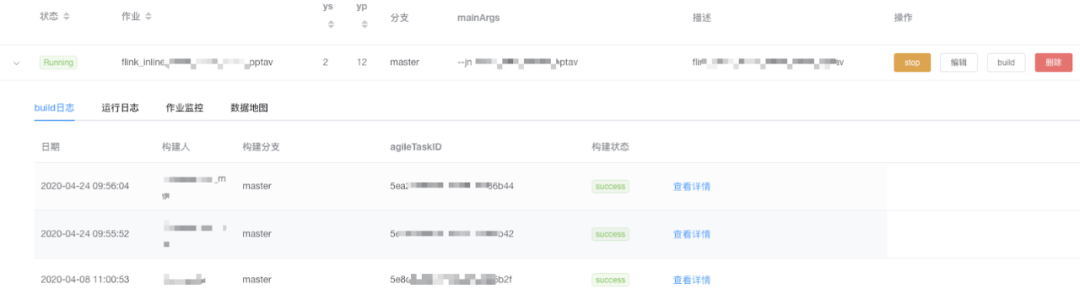
2. 批量执行操作:
某一类作业逻辑更新;
三方依赖库的升级更新;
集群升级;
版本控制;
支持交互式开发 Flink SQL Job(仅支持 Kafka)。
数据 Schema 查询
开发约束
private[garlic] trait AbstractJobModel extends Serializable {def tm: Long // event time 事件时间def ingestion: Long // ingestion time 摄入到到Flink系统时间def f: Boolean // for filter data that is useless 不符合条件要被过滤的数据def unNatural: Boolean // filter future data “超自然”数据}
/*** 指定消费时间戳初始化方法*/def initSourceWithTm[T](deserializer: AbstractDeserializationSchema[T], topics: Array[String], tm: Long): SourceFunction[T]/*** 指定消费时间戳和Kafka Server初始化方法*/def initSourceWithServerAndTm[T](deserializer: AbstractDeserializationSchema[T], topics: Array[String], servers: String, tm: Long): SourceFunction[T]/*** 通用初始化方法*/def initSource[T](implicit deserializer: AbstractDeserializationSchema[T], topics: Array[String], servers: String, tm: Long = 0L): SourceFunction[T]
sinkFilteredDataToKafka:不符合规则或异常被过滤。
sinkUnnaturalDataToKafka:超自然数据。
sinkLateDataToKafka:乱序数据应延迟而被 Window Function 丢弃。
sinkDataInAndProcessToKafka:每条数据的摄入时间和处理时间。
Kafka
Hbase
ES
JDBC
■ 业务数据采集

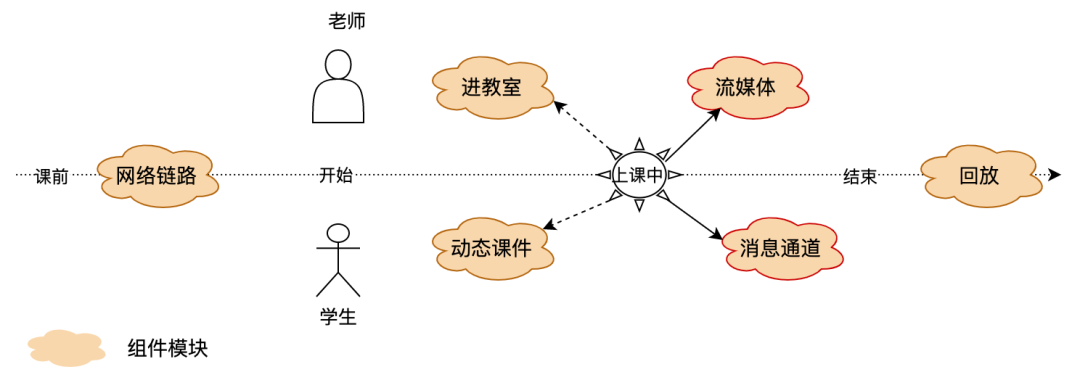
用户发起进教室流程:加载 SDK 后,请求服务和网关,然后初始化服务组件流媒体、消息通道和动态课件,当所有组件都没有异常时才表示进教室成功了,否则继续重试逻辑直到进教室失败或成功;
进教室成功后,课程在正常进行中时,服务组件持续提供服务并实时上报数据。
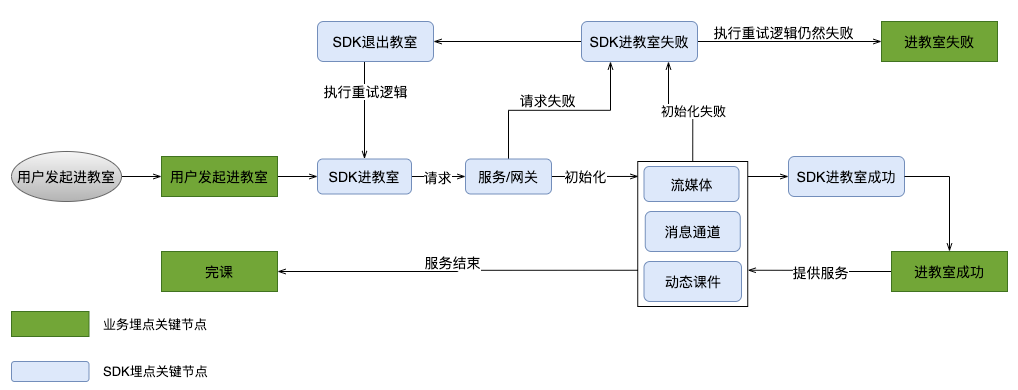
进教室标签,用户有0到多次进教室记录,因某一组件初始化失败而进不了教室和进教室过长,以及进教室成功。
流媒体标签,主要有音视频卡顿、听不见彼此和看不见彼此以及音视频正常数据,数据打点百毫秒级别。
动态课件标签,主要有课件加载失败、课件动作不同步和无法划线拖动。
■ 业务数据计算
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)val stream = env.addSource(singleSource).name("signal").union(env.addSource(avSource).name("av")).union(env.addSource(dbySource).name("dby")).union(env.addSource(enterSource).name("enter")).filter(_.f).filter(_.unNature).assignTimestampsAndWatermarks(new DummyEventTimePunctuWaterMarks[InlineInputEventForm](6 * 1000)).filter(m => *** ).name("***")val ***Streaam = stream.filter(f => *** ).keyBy(key => *** ).window(TumblingEventTimeWindows.of(Time.milliseconds(30 * 1000L))).sideOutputLateData(***lateOutputTag).apply( ***WindowFunction)sink***ToKafka(***Streaam, ***name, recordFilter60s, ***kafkaSink, recordTmKafkaSink)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)***省略部分逻辑代码***val ppt***JoinStream = ***Stream.coGroup(***Stream).where(lb => ***).equalTo(lb => ***).window(SlidingEventTimeWindows.of(Time.milliseconds(30000), Time.milliseconds(15000)))//.sideOutputLateData(***LateOutputTag).apply(ppt***CoGroupWindowFunction)sink***StreamToKafka(ppt***JoinStream, ***name, recordFilter60s, ***kafkaSink, recordTmKafkaSink)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)AsyncDataStream.unorderedWait(stream,syncGet***Function(),500L,TimeUnit.MICROSECONDS)
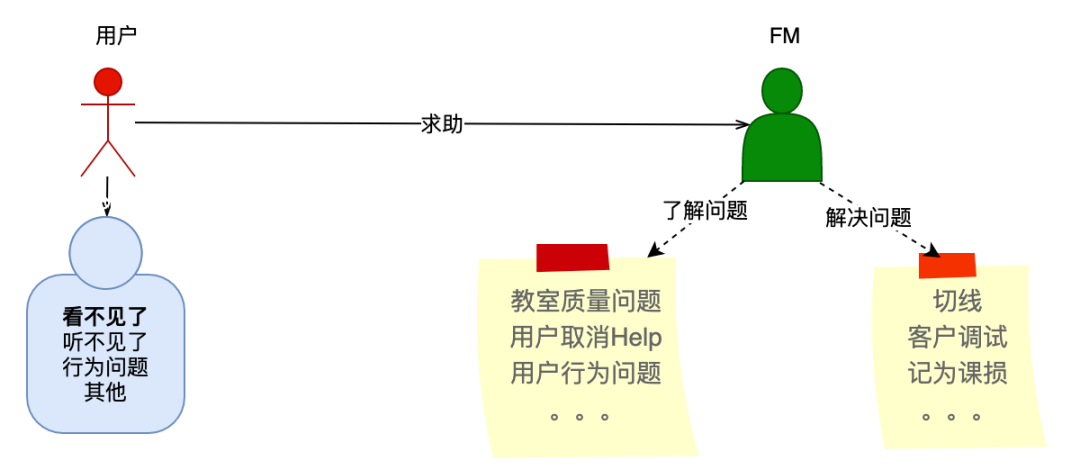
自动化业务系统
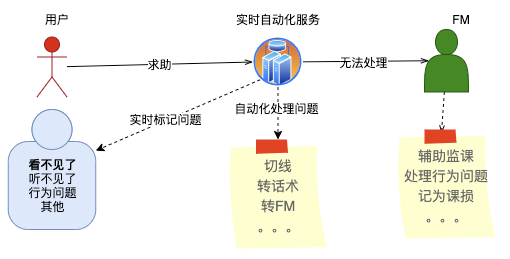
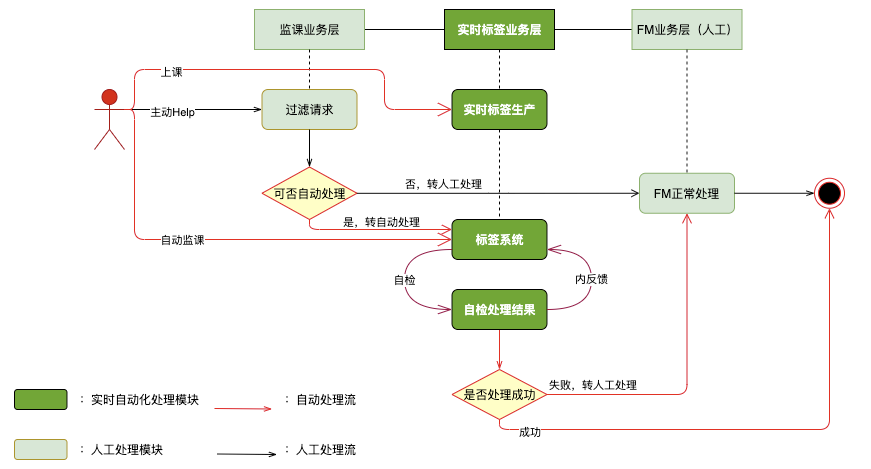
被动等用户发起 Help
主动探测问题标签流
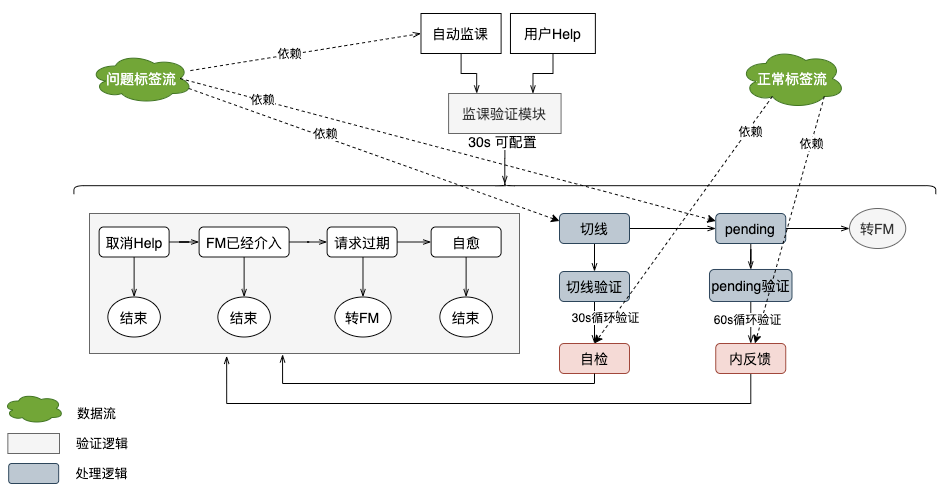
问题与优化
数据质量良莠不齐,指标不一致:整个数据埋点涉及 3 个部门跨 11 个团队,没有统一口径。通过 Vlink 数据平台按业务层级统一管理数据指标、端版本控制和验证流程;
实时计算下获取维度信息造成对 DB 库压力:a、在业务允许的前提下,通过小窗口聚合数据,减少查询次数;b、根据数据时效性增加缓存;
无课程数据时“造数据”导致数据量翻倍:在串行逻辑下,前置多窗口且窗口大小与核心逻辑窗口大小保持一致,指定与 TaskManager*2 的分片数,预处理获取课程维度信息“造数据”再 shuffle 给下游核心窗口逻辑处理。
收益效果
近 60% 求助能自动化处理,同时监课人员减少近 40%
用户求助后能在 20 秒内处理完毕,处理速度比人工更快,处理成功率高
用户满意度高,投诉率降低了 2/3
总结
相关引用
[1]: https://www.donews.com/news/detail/4/2978938.html
[2]: https://blog.scottlogic.com/2018/07/06/comparing-streaming-frameworks-pt1.html
[3]: https://issues.apache.org/jira/browse/FLINK-13148
[4]: https://github.com/google/guava/wiki/CachesExplained
甄国有,VIPKID 在线教室技术研发中心高级数据工程师,负责在线教室实时计算体系的落地和场景化,专注于数据体系建设和架构。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个三连击呗~~
DataFun会员计划重磅发布!多重权益加持,为你筑就数据科学家之路!扫码了解更多:

文章推荐:
关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近600位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,8万+精准粉丝。

🧐分享、点赞、在看,给个三连击呗!👇





