近九千人齐聚 NeurIPS 2018,四篇最佳论文,十大研究领域,1010 篇论文被接收

AI 科技评论消息:NeurIPS 2018 于 12 月 3 日—12 月 8 日在加拿大蒙特利尔会展中心(Palais des Congrès de Montréal)举办,今年共计有 9 场 Tutorial 、7 场主题 Talk 和 41 场 Workshop,相较去年来说,不管是主题活动,还是投稿论文,亦或是参会人数,都上了一层新的台阶。
在大会第一天的下午的开幕式环节,最佳论文奖、时间检验奖等诸多奖项一并揭晓,大会主席也向在场观众透露了今年论文的热点分布,会议新的亮点以及一系列数据。

随着会议的影响和规模越来越大,今年创造性地开设了展览日,吸引了将近 32 家公司,设立了 15 场演讲和圆桌,17 篇 demo 展示和 10 场 workshop。
今年共有 9 场 tutorial,其中有 5 场由组委会邀请。组委会共接收 36 个 tutorial 举办申请,最后通过 4 场。workshop 申请上,共收到 118 份报名,最终通过 39 份。竞赛申请上,共收到 21 份申请,最终通过 8 个。
组委会今年特别提及了到四场 workshop,分别是 WiML,Black in AI,LatinX in AI,Queer in AI,宣扬反对歧视和偏见。

组委会表示,我们需要意识到人是复杂的动物,要能看到其他人的观点,切身体会到被当做局外人的感受,要多听、多做研究、多学习,不断努力,表明自己的观点和态度。

为了将会议办好,组委会在今年也做出了很多努力,如设立 advisory board, inclusion survey ,邀请 D&I 讲者,在 Twitter 上提供小贴士等。

会议上,也特别提到签证问题,此次有超过一半的参会黑人签证被拒。他们表示,接下来将会早一点发出邀请函,未来在会议主办地的选择上也会注意。
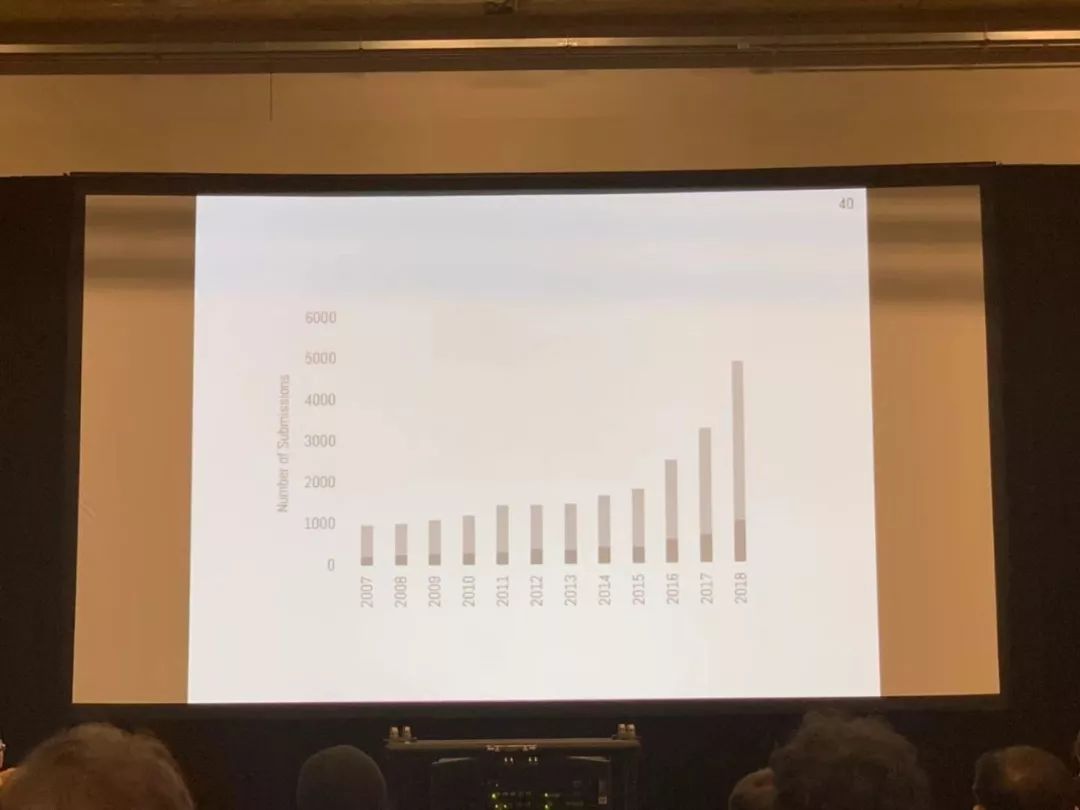
今年组委会共审阅 4854 篇论文,接收论文 1010 篇,接收率与去年一致,均为 21%。可以看到,从 2015 年开始,NeurIPS 的投稿论文迎来爆发式增长。
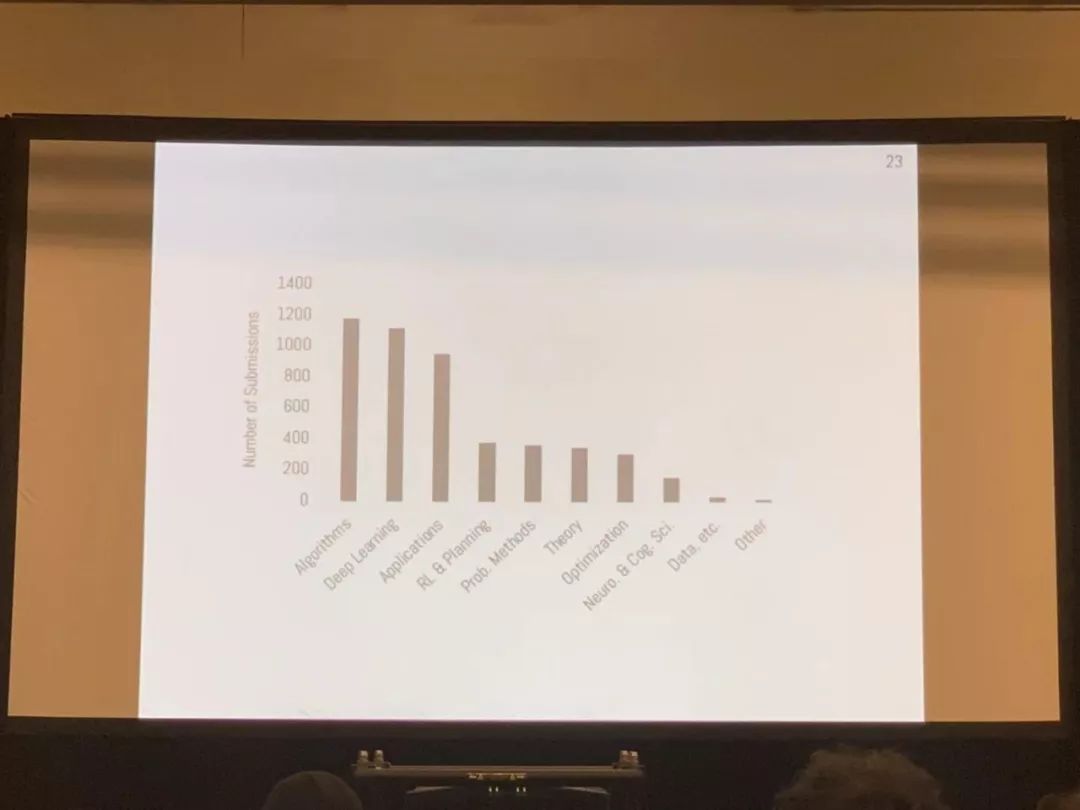
组委会今年统计出十大热点领域,分别是:
Algorithms
Deep Learning
Applications
RL&Planning
Prob. Methods
Theory
Optimization
Neuro.&Cog.Sci.
Data, etc
Other
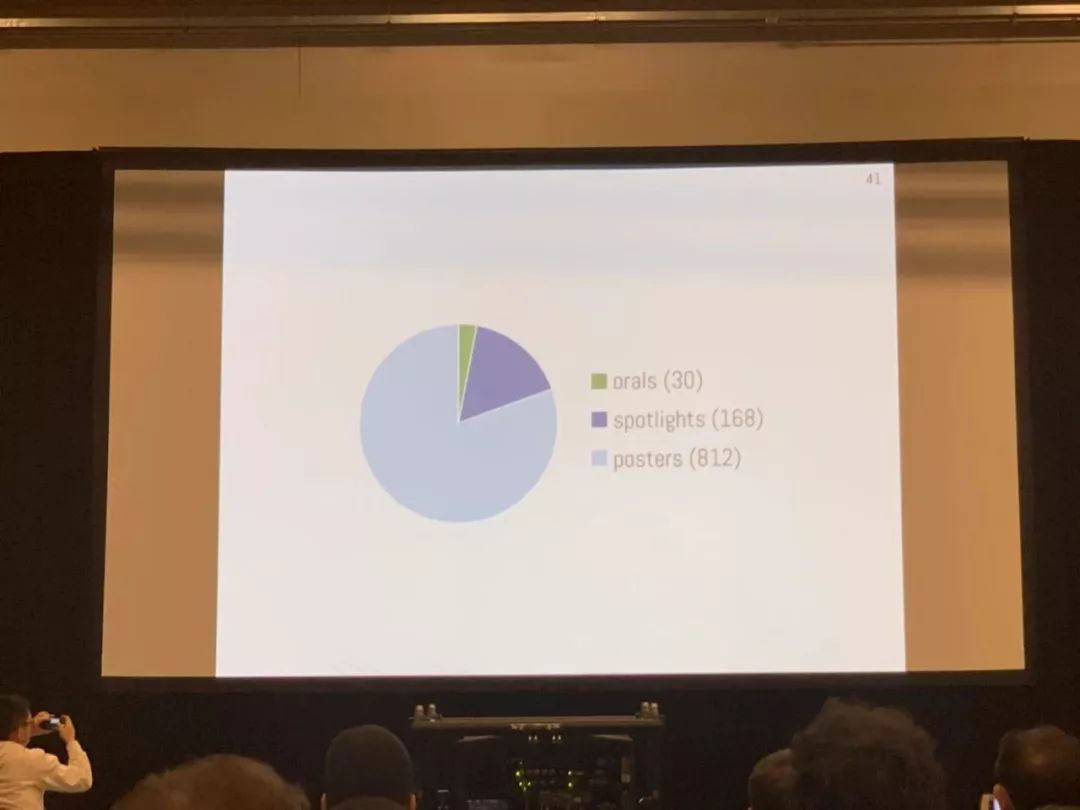
在论文分布上,共接收 30 篇 oral 论文,168 篇 spotlight 论文,812 篇 poster 论文。其中,有 44% 的接收论文提供了代码或数据,有 56% 的论文已经在网上公布。
今年共有四篇最佳论文奖,一篇时间检验奖,值得一提的是,曾获得KDD CUP 2012 Track 1 第一名,并开发了 SVDFeature,XGBoost,cxxnet 等著名机器学习工具陈天奇榜上有名。
最佳论文奖

Nearly tight sample complexity bounds for learning mixtures of Gaussians via sample compression schemes
利用样本压缩方案学习高斯混合的近似紧样本复杂度界
作者:Hassan Ashtiani,Shai Ben-David,Nicholas Harvey,Christopher Liaw,Abbas Mehrabian,Yaniv Plan
我们证明了 (k d^2/ε^2) 样本对于学习 R^d 中 k 个高斯的混合,直至总变差距离中的误差 ε 来说,是充分必要条件。这改善了已知的上界和下界这一问题。对于轴对准高斯混合,我们证明了 O(k d/ε^2) 样本匹配一个已知的下界是足够的。上限是基于样本压缩概念的分布学习新技术。任何允许这种样本压缩方案的分布类都可以用很少的样本来学习。此外,如果一类分布具有这样的压缩方案,那么这些产品和混合物的类也是如此。我们主要结果的核心是证明了 R^d 中的高斯类能有效的进行样本压缩。

Optimal Algorithms for Non-Smooth Distributed Optimization in Networks
网络中非光滑分布优化的优化算法
作者:Kevin Scaman, Francis Bach, Sébastien Bubeck, Yin Tat Lee, Laurent Massoulié
在本文中,我们考虑使用计算单元网络的非光滑凸函数的分布式优化。我们在两个正则性假设下研究这个问题:(1)全局目标函数的 Lipschitz 连续性,(2)局部个体函数的 Lipschitz 连续性。在局部正则性假设下,本文给出了称为多步原对偶(MSPD)的一阶最优分散算法及其相应的最优收敛速度。这个结果的一个显著特点是,对于非光滑函数,当误差的主要项在 O(1/t) 中时,通信网络的结构仅影响 O(1/t) 中的二阶项,其中 t 是时间。换言之,即使在非强凸目标函数的情况下,由于通信资源的限制而导致的误差也以快速率减小。在全局正则性假设下,基于目标函数的局部平滑,给出了一种简单而有效的分布式随机平滑(DRS)算法,并证明了 DRS 在最优收敛速度的 d1/4 乘因子内,其中 d 为底层。

Neural Ordinary Differential Equations
神经常微分方程
作者:Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, David Duvenaud
我们引入了一种新的深度神经网络模型。我们使用神经网络参数化隐藏状态的导数,来代替指定隐藏层的离散序列。网络的输出是使用黑箱微分方程求解器计算的。这些连续深度模型具有恒定的存储器成本,使它们的评估策略适应于每个输入,并且可以显式地以数值精度换取速度。我们在连续深度残差网络和连续时间潜变量模型中证明了这些性质。我们还构造了连续归一化流,这是一种生成模型,可以通过最大似然度进行训练,而不需要对数据维度进行划分或排序。对于训练,我们将展示如何通过任何 ODE 求解器可扩展地反向传播,而无需访问其内部操作。这允许较大模型中的 ODES 进行端到端的训练。

Non-delusional Q-learning and value-iteration
「Non-delusional」Q 学习和价值迭代
作者:Tyler Lu,Dale Schuurmans,Craig Boutilier
我们用函数逼近法确定了 Q-学习和其他形式的动态规划中误差的根本来源。当近似结构限制了可表达的贪婪策略的类别时,就会产生偏差。由于标准 Q-updates 对可表达的策略类做出了全局不协调的动作选择,因此可能导致不一致甚至冲突的 Q 值估计,从而导致病态行为,例如过度/低估、不稳定甚至发散。为了解决这个问题,我们引入了策略一致性的新概念,并定义了一个本地备份流程,通过使用信息集,也就是记录与备份 Q 值一致的策略约束集,来确保全局一致性。我们证明了使用这种备份的基于模型和无模型的算法都能消除妄想偏差,从而产生第一种已知算法,保证在一般条件下的最优结果。此外,这些算法只需要多项式的一些信息集(的潜在指数支持)。最后,我们建议使用其他实用的启发式价值迭代和 Q 学习方法去尝试减少妄想偏差。
时间检验奖

The Tradeoffs of Large Scale Learning
权衡大规模学习
作者:Léon Bottou,Olivier Bousquet
这篇文章建立了一个理论框架,在学习算法中考虑了近似优化的影响。分析表明,对于小规模和大规模学习问题来说,近似最优化算法的 tradeoff 是不相同的。小规模的学习问题服从于常规的近似估计。大规模学习系统还受限于底层优化算法的非平凡方式的计算复杂性。
会议重头戏就此结束,接下来,将是一系列有意思的 workshop 和对所有论文的展示,雷锋网 AI 科技评论也将为大家持续带来相关报导。
特此感谢第四范式涂威威供图。

点击阅读原文,查看说好不改名的 NIPS,改成 NeurlPS 了



