Merlin:基于深度学习的推荐系统框架


分享嘉宾:赵元青 NVIDIA 深度学习架构师
编辑整理:光光
出品平台:DataFunTalk、AI启蒙者
Merlin框架总览
NVTabular
HugeCTR
Deep Learning Example
首先与大家介绍Merlin的框架总览,常见的推荐系统流水线,以及各个部分遇到的挑战和要重点解决的问题。
1. Merlin框架总览
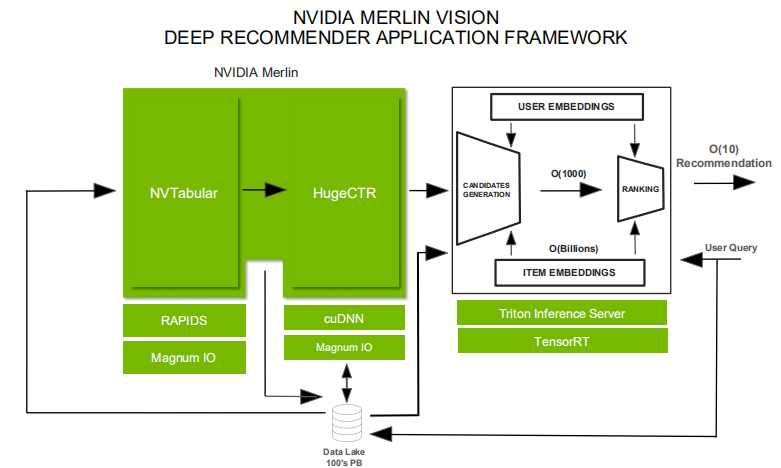
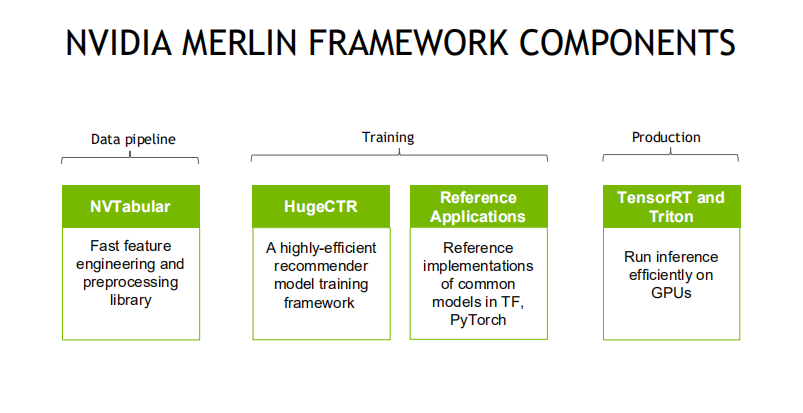
Merlin 框架主要包含三个组件NVTabular、HugeCTR和Triton。NVTabular是用来解决推荐系统特征工程、数据前处理的问题,HugeCTR是CTR模型训练框架,而Triton则是推理服务器框架。
2. 推荐系统的常见流水线
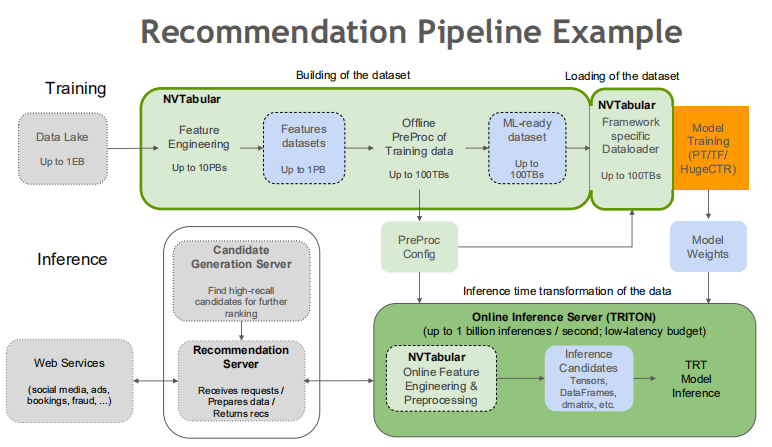
在离线模型训练流程中,NVTabular能够读取和解析原始数据集,进行特征工程和前处理,并通过对应的Dataloader将数据加载到CTR模型训练框架之中;而对于线上推荐系统模型推理,NVTabular则可以将离线ETL过程中收集到的统计信息输出到TRITON,这可以解决推荐系统Training与Inference阶段中数据一致性的问题,防止特征穿越。
3. 工业界落地推荐系统的常见挑战

总结起来,业界落地推荐系统的常见挑战有:
Feature Exploration:特征探索,每次对特征进行一次重新组合或者是加入新的特征都要将所有的数据重新处理一遍,增加训练成本。
Dataloading:数据加载,如果没有一个合适的数据加载方案,那么即便数据已经处理好了,将数据加载到训练框架的效率也是比较低的。
Training Embedding Tables:为了推荐系统支持训练更大规模的Embedding layers,从而提升更好的推荐效果,工业界在这方面做了很多的尝试。在这个过程中最常见的问题就是单张GPU显存容量不够;而将训练拓展到多张GPU、多个节点则会遇到许多协同上的问题。
High Accuracy:高准确率,在实际模型优化过程中,单次模型迭代速度太慢,没有充分的调优时间来让模型达到最优准确率。
Deployment:部署,通常线上服务要求在一定latency内能承载比较高的QPS,而为了更好的推荐效果,我们期望能在单次请求中能对更多的候选集结果进行排序,从而达到更好的推荐效果,在满足线上推理性能的条件下这势必会引入更多的硬件成本。
4. Merlin推荐系统框架的优势

先来看下Merlin推荐系统框架的优势:
NVTabular:为特征工程、前处理提供了更快的迭代速度,同时利用异步批量加载的方法有效提高了GPU的利用率,提供更快的加载速率。
HugeCTR:在Embedding lookup上做了很多优化,可以轻易的通过数据和模型并行的方式将模型扩展到TB级别,在大规模参数的背景下,这给挖掘模型能力提供了更多的想象力。同时更快的训练速度也让算法工程师能够尝试更多的网络结构,挖掘最适合所研究问题的模型。
Triton:Triton本身是面向高吞吐低延时的生产环境的框架,本次分享不会重点展开。

1. NVTabular的主要优势

NVTabular的主要优势有:
Scale:数据集大小不受显存或主存限制。
Speed:相比于纯CPU的方案有约10倍的提升。
Usability:更好的易用性,对于开发者而言能够用更少的API调用便能实现与Pandas、Numpy一样的处理流程。
Interoperability:能够与PyTorch、TensorFlow、HugeCTR兼容。
2. NVTabular给算法工程师带来的改变
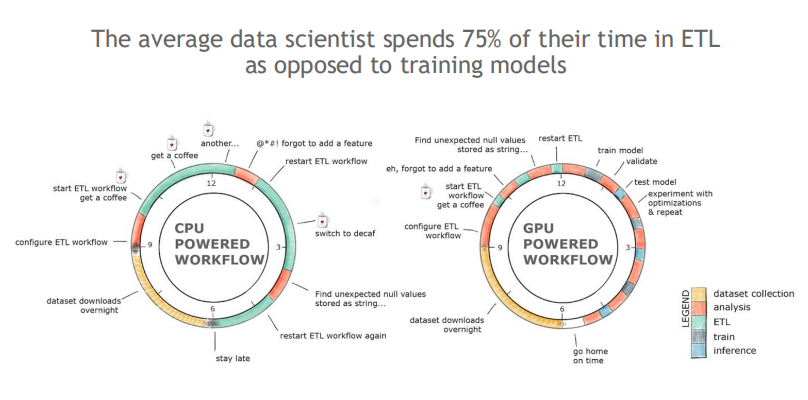
NVTabular可以提供更快的ETL执行速度,给算法工程师更多的时间对暴露出的问题进行解决,也能够预留更充分的时间对模型特征进行更多的组合、优化,提高工作效率。
3. NVTabular与其它开发工具的比较

数据大小:NVTabular不受限于CPU主存与GPU显存,而cuDF与Panda则受限于GPU显存与CPU主存。
模型复杂度:NVTabular提供了面向推荐系统的更为上层的API,而cuDF、Pandas则属于比较基础的开发工具,所以应用起来的复杂度会更高。
IO开销:cuDF与Pandas的操作是所见即所得,NVTabular更加关注于整体流水线最终的执行结果。NVTabular在基于cuDF的封装过程中做了很多的优化,使得其IO开销只是一个常数。
线上推理:NVTabular是针对推荐系统开发的数据处理工具,支持线上推理;而cuDF与Pandas在这一方面是缺失的。
4. 案例与实例代码
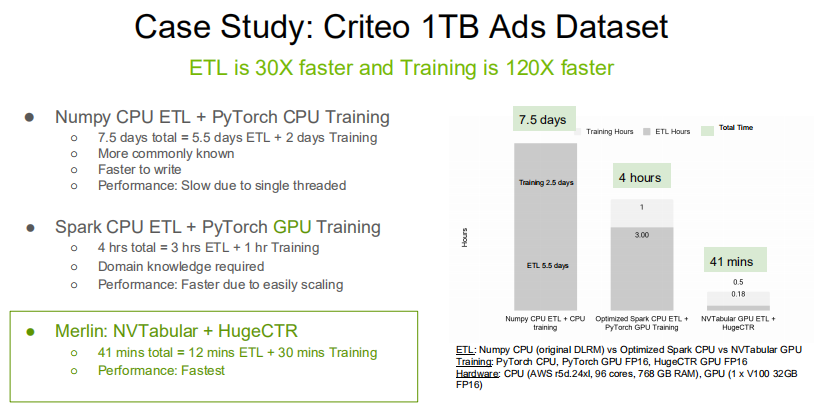


1. HugeCTR的特点
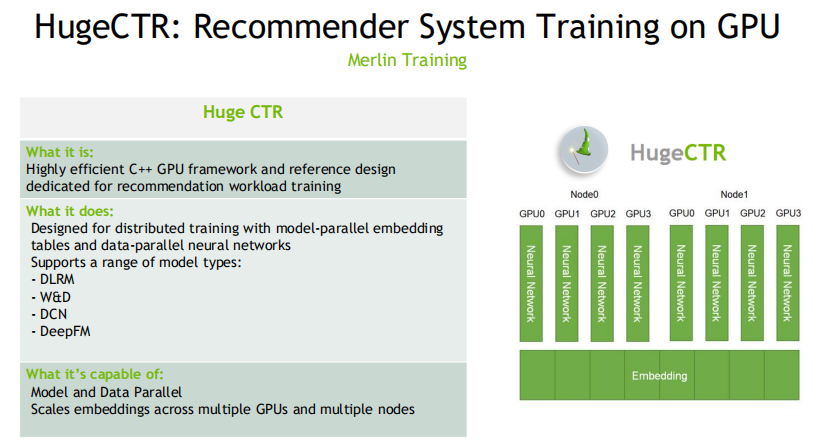
NVIDIA结合企业优势,使得HugeCTR在GPU这一方面做了许多深层次的优化,提高并行能力。
HugeCTR是用C++开发,并由json来定义模型,支持模型并行与数据并行这个两种模式。
HugeCTR内置许多常见模型实现,例如DLRM,DCN,DeepFM。
HugeCTR对大型Embedding layer是支持多GPU与多节点的。
2. HugeCTR的主要优势

分布式的Embedding layer有利于对模型进行拓展。
Json数据结构能够比较灵活的定义模型的网络结构。
提供了对常见输入数据错误的检测和处理机制。
提供动态哈希表插入功能,使得线上学习过程中遇到的新特征可以动态生成hash值,映射到现有embedding layer之中,从而低成本捕获了新特征学习带来的收益。
3. 实例
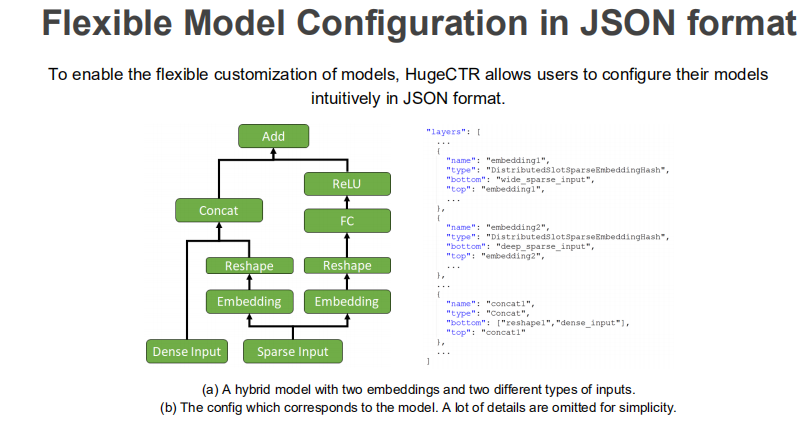
① json定义模型
只需描述清楚每个节点的名字与类别以及与其它节点的连接情况。
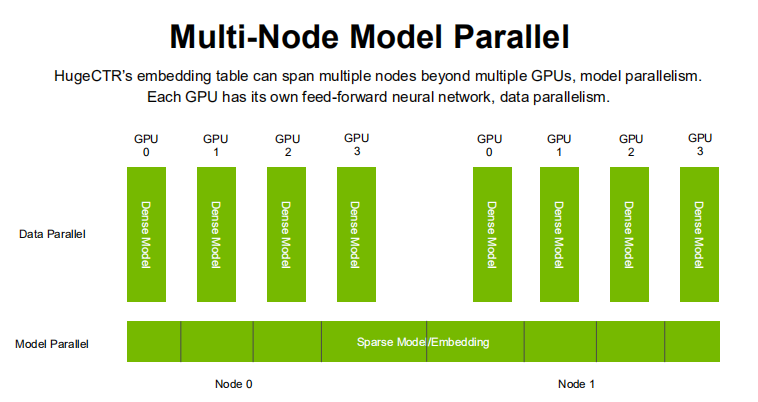
② 多节点模型并行示意图
DenseLayer重复分布在每一个GPU上,而SparseEmbeddingLayer则分块分布在多个GPU上。
4. HugeCTR的加速性能
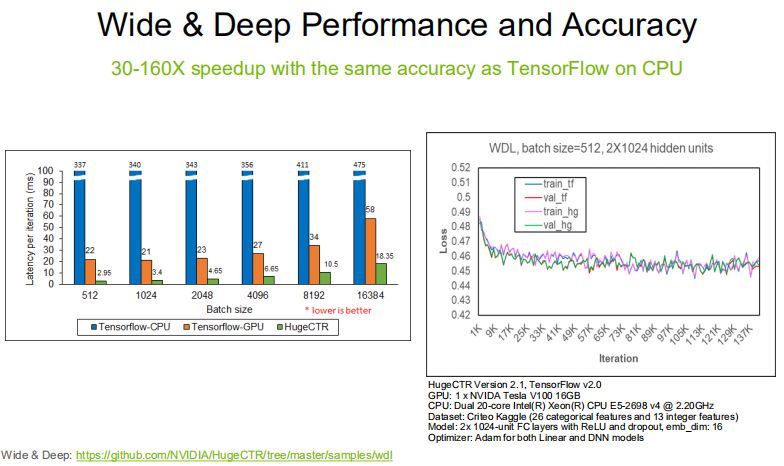
速度:不论是TensorFlow的GPU方案还是CPU方案,HugeCTR在训练速度上都明显快于TensorFlow。
效果:在相同的数据量下,HugeCTR能够达到与TensorFlow基本一致的训练效果。

1. 丰富的模型实现
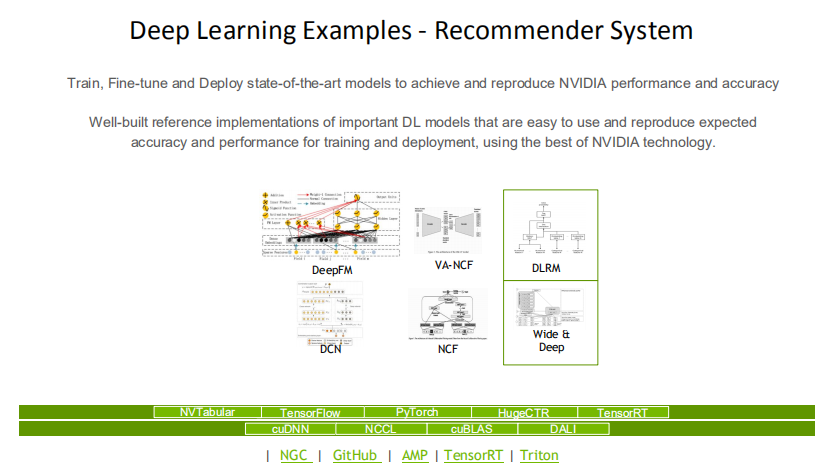
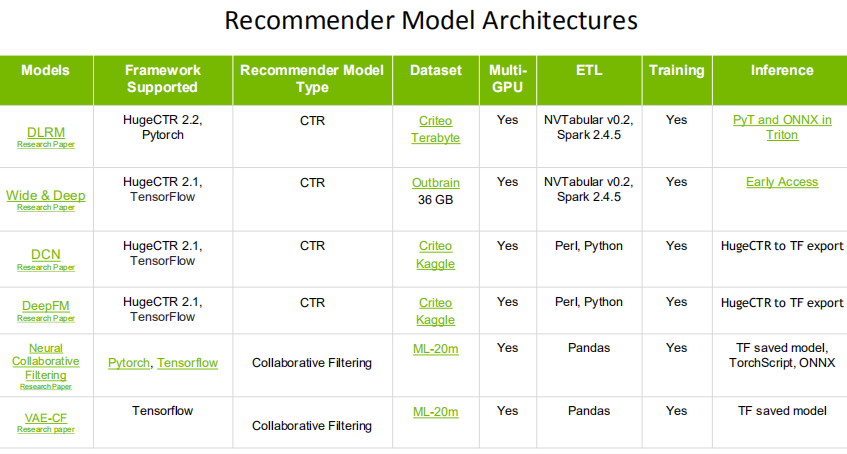
Merlin DeepLearningExamples对DeepFM,VA-NCF,DLRM,DCN,NCF等主流推荐系统都提供了NVIDIA版本实现,下面的表格给出了不同模型的实现细节。
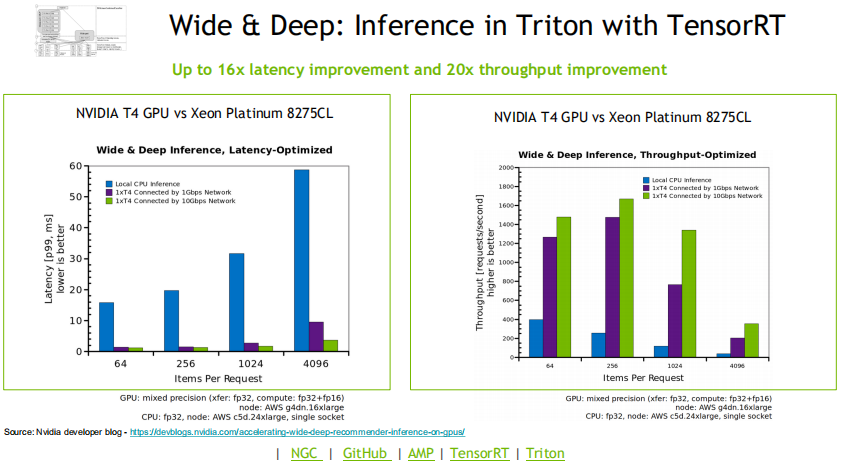
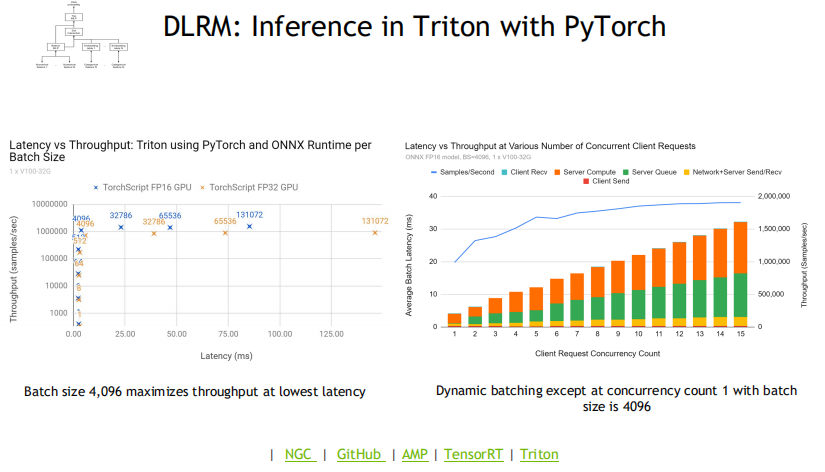
2. 高性能的推理能力
Merlin在Inference阶段的两个重要的结构是TensorRT与Triton。TensorRT是一个针对推理场景对模型进行优化的SDK,支持包括PyTorch,TensorFlow,ONNX在内的许多模型。
通过Triton做线上推理,将TensorRT作为执行后端,能够有效降低Latency,并最大化地利用GPU资源。相比于一个纯CPU的方案,两者的结合使用能够使Latency达到原先的1/18,数据吞吐量达到原先的17.6倍。下面两张图展示了一个纯CPU方案与TensorRT和Triton在Latency与Throughput上的对比。

1. 总结
Merlin推荐系统框架主要包括:数据流水处理,模型训练,推理三个部分。
NVTabular能够进行高效的特征工程、前处理和数据在库;HugeCTR是一个高效的推荐系统模型训练家,不但能够支持大规模的Embedding Layer训练,还能够动态加入线上学习过程中新出现的特征。TensorRT与Triton则能够提高GPU使用效率,提高模型推理速度。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~

赵元青,2013年本科毕业于北京信息科技大学,曾就职于阿里大文娱优酷事业群、知乎和 OPPO。曾经在知乎负责过个性化推送算法侧和首页排序/重排序模块,在推荐系统领域有较深的钻研。目前在 NVIDIA 负责推荐系统领域的深度学习解决方案架构。

文章推荐:
社群推荐:

关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近600位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,9万+精准粉丝。

🧐分享、点赞、在看,给个3连击呗!👇


