论文浅尝 - EMNLP2020 | 图结构对于多跳问答而言必要吗?
研究方向 | 知识图谱,图神经网络,多模态

背景提要
抽取式阅读理解,指的是要求机器在阅读一段文本后,来回答一个问题。而回答这个问题的答案来自原文中的一段连续的序列(也就是连续的几个词)。
其中的多跳推理,近年来引起了关注。ACL2019的一篇论文提出用图的方法解该问题,使用动态图网络建模实体之间的联系。

具体思路如下:
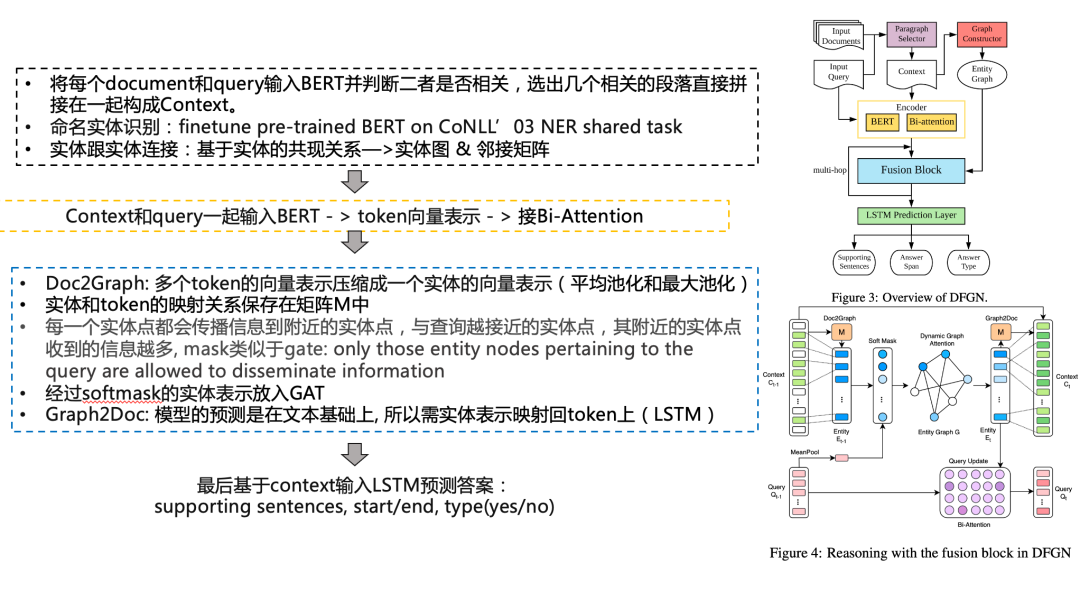
其中的共现关系按如下表示:
对与同一个句子中同时出现的实体间建立边的连接。
对于同样的实体在Context中出现多次,则他们直接有边的连接。eg. 如“美利坚合众国”这个实体可能在文章中被多次提及,每次出现则图中会新建一个节点,这些节点直接都是互相连接的。
文章标题中出现的实体与其对应正文中的所有实体都有连接
本文思路
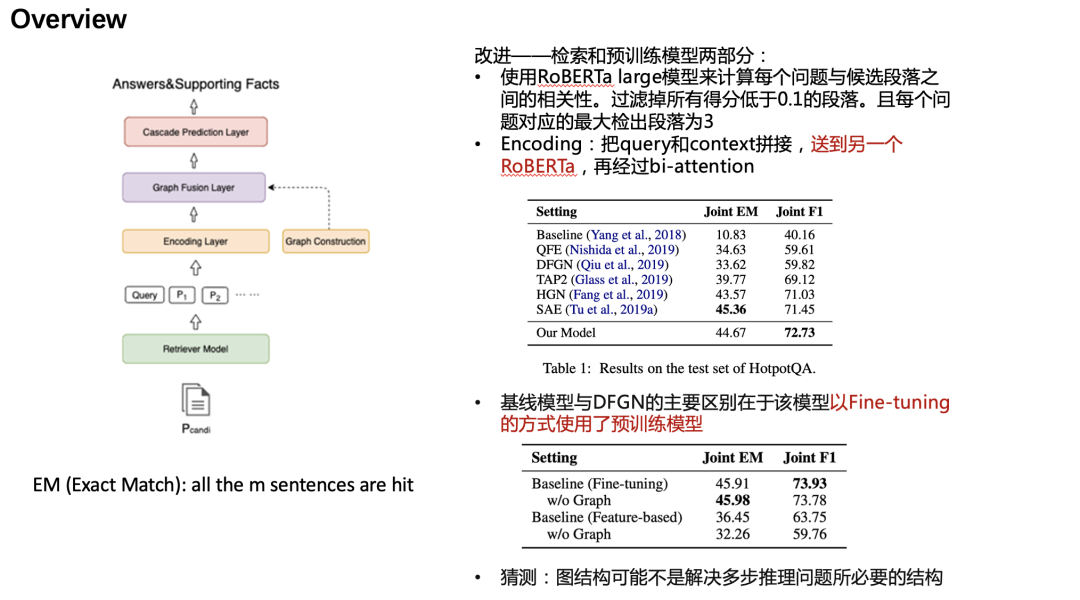
本文的改进主要在于检索和预训练模型两部分:
使用RoBERTa large模型来计算每个问题与候选段落之间的相关性。过滤掉所有得分低于0.1的段落。且每个问题对应的最大检出段落为3
Encoding:把query和context拼接,送到另一个RoBERTa,再经过bi-attention
基线模型与DFGN的主要区别在于该模型以Fine-tuning的方式使用了预训练模型,最后发现简单的Fine-tuning可以把模型效果提高到另一个程度。并且在finetune的前提下图结构添加与否没有那么必要(效果提升有限)
所以猜测:图结构可能不是解决多步推理问题所必要的结构
为了进一步理解图结构,作者猜测:自注意力或者Transformer可能更加擅长处理多步推理问答任务,为此做了如下测试,同时提出如下观点:
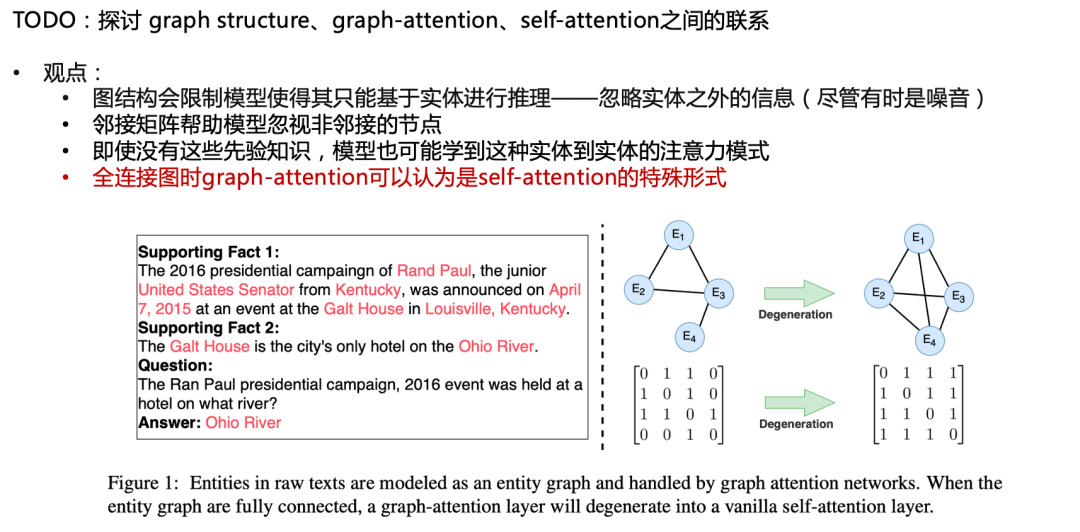
图结构会限制模型使得其只能基于实体进行推理——忽略实体之外的信息(尽管有时是噪音)
邻接矩阵帮助模型忽视非邻接的节点
即使没有这些先验知识,模型也可能学到这种实体到实体的注意力模式
全连接图时graph-attention可以认为是self-attention的特殊形式
实验
预训练模型使用Feature-based的方法
graph-attention
自注意力使用了与图注意力相同的形式,唯一的不同在于自注意力将所有的节点视作全连接的
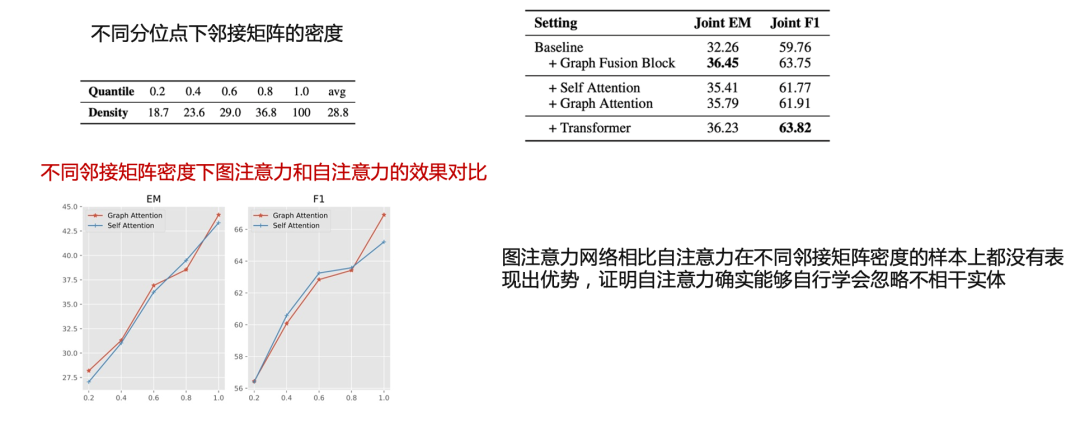
最后发现哪怕不使用图结构,transformer也可以达到和self-attention,graph-attetion相同的效果。并且随着图的密度增大,这一过程中graph attention也没有显示出和self attention很大的差距
最后作者探讨了,预训练与transformer的方法定位预训练模型中包含基于实体的注意力的头(attention head)的可能性:
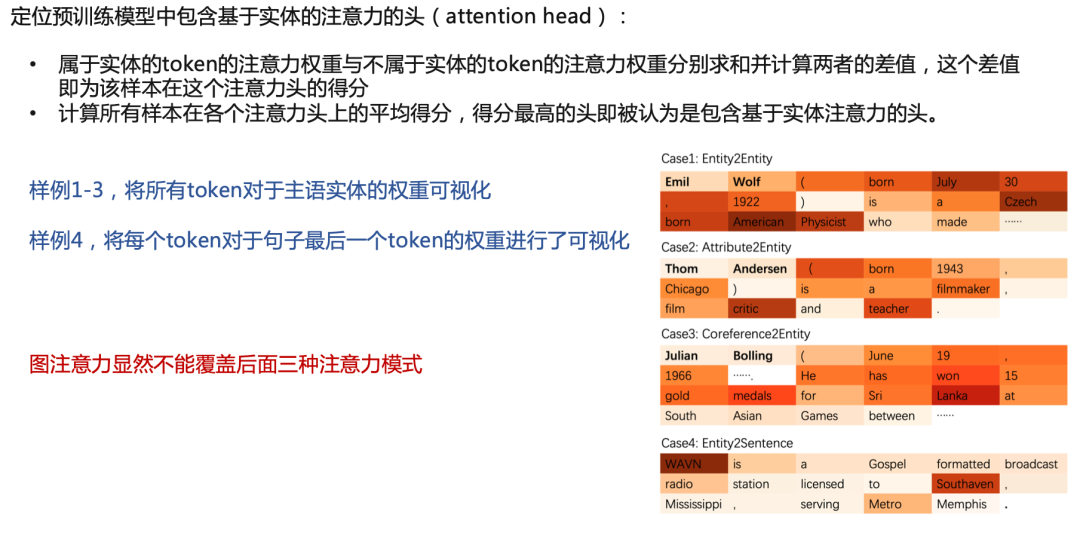
最后发现,该方法可以很好地捕捉和识别出相对于特定实体的其他概念注意力(四种情况,而后三种情况是graph方法所做不到的)
总结
适当使用预训练的模型,多跳推理某些情况下可能不需要图结构
图结构在某些情况下也是对于任务的一种制约/限制
邻接矩阵和图结构可以看作是某种与任务相关的先验知识
一些情况下graph attention和graph structure都可以被self-attention所代替
图上的mask可以控制信息在图上传播的路径
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 网站。


