SIGIR 2019 eBay高精度召回任务挑战赛冠军团队DeepBlueAI技术分享

作者丨罗志鹏
单位丨深兰北京AI研发中心
近日,SIGIR 2019 eBay 数据挑战赛结果出炉,这次赛题是 eBay 搜索集团组织的高精度召回任务。由来自深兰科技北京 AI 研发中心的 DeepBlueAI 团队斩获冠军,本文带来该团队在竞赛中技术细节分享。
背景介绍
ACM SIGIR 是国际计算机学会主办的信息检索领域的最重要学术会议。SIGIR 专注于信息存储、检索和传播的各个方面,包括研究战略、输出方案和系统评估。今年, 第 42 届 SIGIR 会议于 2019 年 7 月 21 日至 25 日在法国巴黎举行。
团队成绩
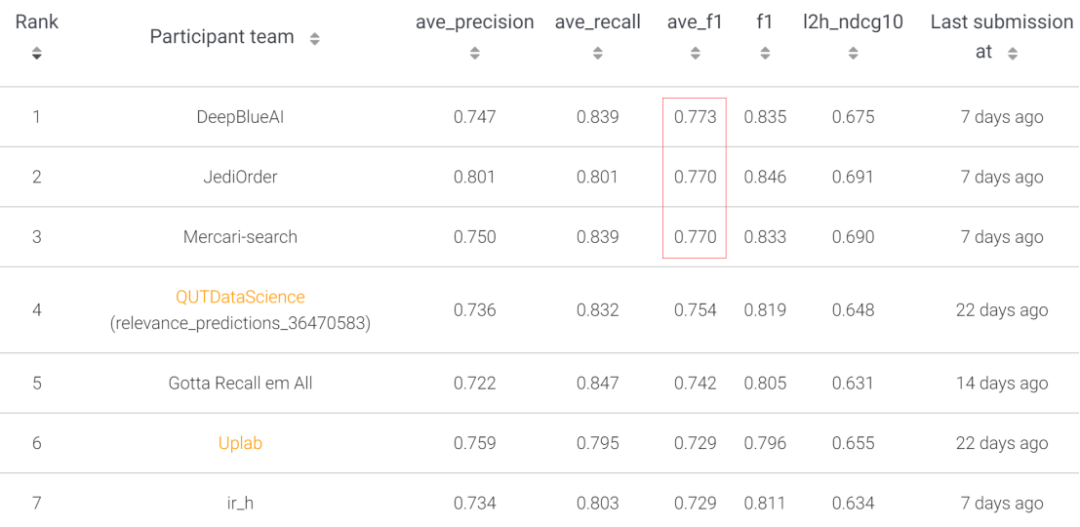
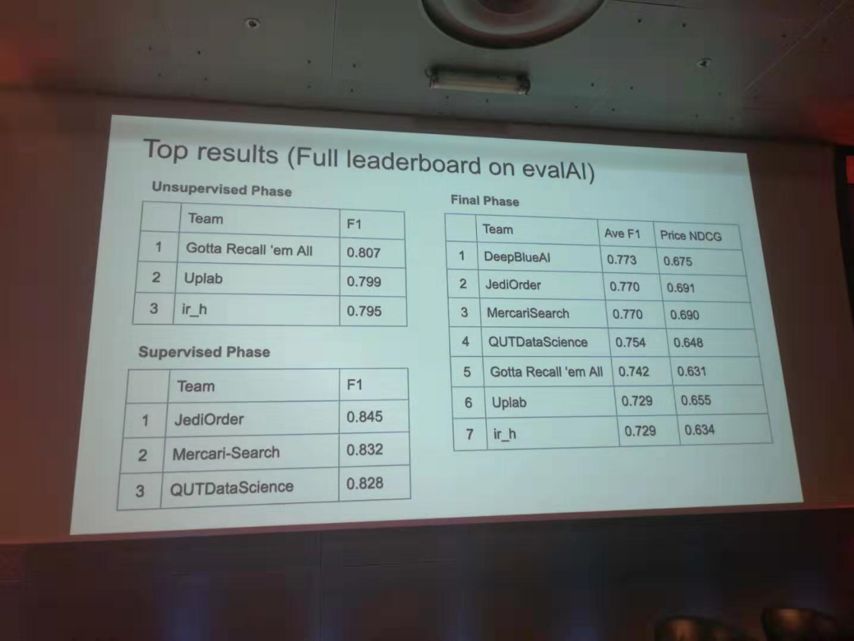
在 eBay SIGIR 2019 电子商务搜索挑战——高精度召回任务中,DeepBlueAI 团队荣获冠军,排名如下:

赛题介绍
本次比赛是由 eBay 搜索组组织的高精度召回任务。本次挑战针对的是电子商务搜索中的常见问题:展示非相关性排序时要显示的项目。用户通常按非相关性的维度进行排序,例如流行度、评论得分、价格等。
本次比赛的重点在于:使用非相关性排序时找到应该召回的内容。比赛数据集包括大约 90 万条来自 eBay 收藏类别中的特定字段,以及与收藏类别相关的 150 个热门搜索查询短语。每条数据带有商品标题,价格,分类目录和相应图像网址的 URL。参赛选手要合理运用数据集材料,来判断查询短语和文档是否相关。
评测指标
使用 150 个查询短语的平均 F1-score 作为本次竞赛的主要性能指标。得分越高代表模型性能越好。
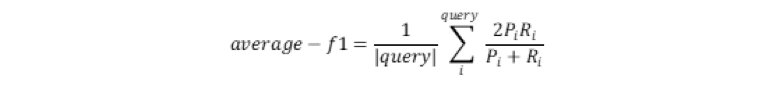
题目特点
在这次比赛中,主要有以下难点:
1. 数据量大
原始数据集共约 90 万字段,150 个查询短语,两两组合即要预测约 1 亿 3 千万个 (document, query) 对是否相关。
2. 匹配难度大
给定的 query 长度短,一般为 2-3 个专业性英文单词,最长的不超过 6 个词,匹配难度较大,对建模挑战较大。
3. 训练集小,调优难
在约 1 亿 3 千万条 (document, query) 中只有 6 万余条数据作为训练集,其余部分全部需要给出预测结果。此外,150 个 query 中每个 query 的训练集数据量差异很大,需要对 average-f1 指标进行优化处理。
特征工程
我们通过 LightGBM 模型来验证特征效果。特征分三部分构成,第一部分是对 query 做基础属性特征;第二部分是对商品做基础属性特征;第三部分就是对 query 与商品做组合特征。
在所有的特征当中,query 与 title 的句向量以及在句向量的基础上再做的特征对效果影响较大。我们针对这点尝试了不同的文本,单词处理方法与不同的词向量训练方法去生成 query 与 title 的句向量。
query基础属性特征
query 单词的个数,query 数字的个数;
query 的形容词占比与名词占比;
query 的语义向量。
商品基础属性特征
title 单词的个数,title 数字的个数;
title 的形容词占比与名词占比;
商品类别的 hash 值(5 列),商品类别是逐级递减的,最多 5 级,下一个类别是上一个的子集;
最后一列商品类别的 hash 值;
最后一列商品类别的 value_counts;
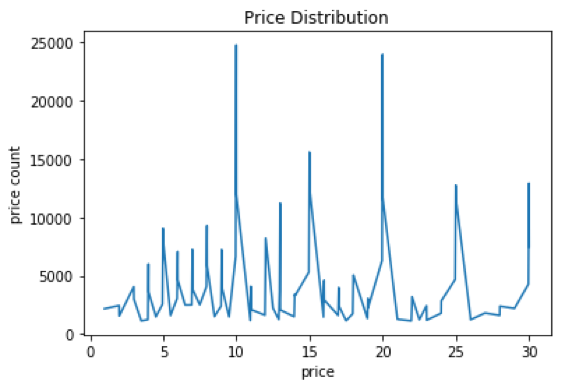
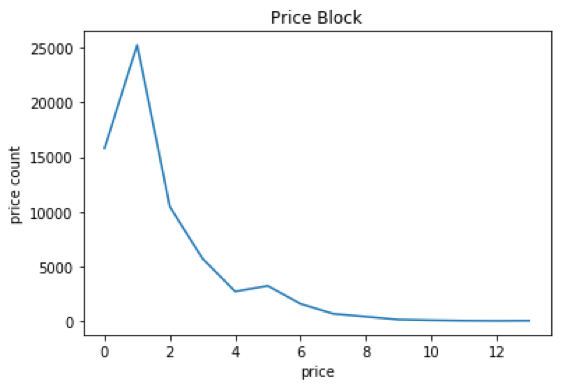
价格分箱,一个查询可能搜索出价格差异较大的两个商品,价格分箱能体现出这两个商品的差异;相比直接把价格做特征,价格分箱能把两个价格相近的商品归为一类。下图是商品的价格分布,可以看出价格分布差异较大,而做完价格分箱后,能弱化这种差异,价格分布都很集中。
查询关键词与商品组合特征
title 句向量与 query 句向量的差值与点积;
title 句向量与 query 句向量的的相似度,相似度计算包括 cosine, cityblock, canberra;
query 单词与 cate 单词相同的个数;query 单词与 title 单词相同的个数;
使用 fuzzywuzzy 计算字符的编辑距离;使用 fuzzywuzzy 计算单词的编辑距离;
title 单词数与 query 单词数的差值与比值;
价格分箱针对 query,与直接用价格分箱相比,对每个 query 分别做分箱,能使每个 query 的价格分箱互不干扰;
BM25 计算 query 与 title 的相关性分数。BM25 算法通常用来作搜索相关性评分。其主要思想为:对 query 进行语素解析,生成语素 qi;然后,对于每个商品 title D,计算每个语素 qi 与 D 的相关性得分,最后,将 qi 相对于 D 的相关性得分进行加权求和,从而得到 Query 与 D 的相关性得分。
BM25 算法的一般性公式如下:
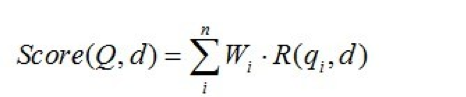
不同的单词文本预处理方法
把句子里的标点与分隔符去掉,并转成小写;
把句子里的标点与分隔符去掉,提取词干并转成小写;
不去特殊字符,直接用空格分隔,转成小写。
句向量的生成
用预处理好的 title 与 query 训练使用 word2vec 来生成词向量,然后生成句向量,虽然总语料库数据量小,但是使用它们训练得出的词向量更能体现出该数据的特性,同时也能覆盖到更多的词;
用 google 已经预训练好的词向量来生成句向量。
实验模型
在本次比赛中,我们实验了几种经典的文本相似度匹配、自然语言推理模型,包括 CNN, BiGRU,decomposable attention, ESIM 等,其中效果最好的是 ESIM。
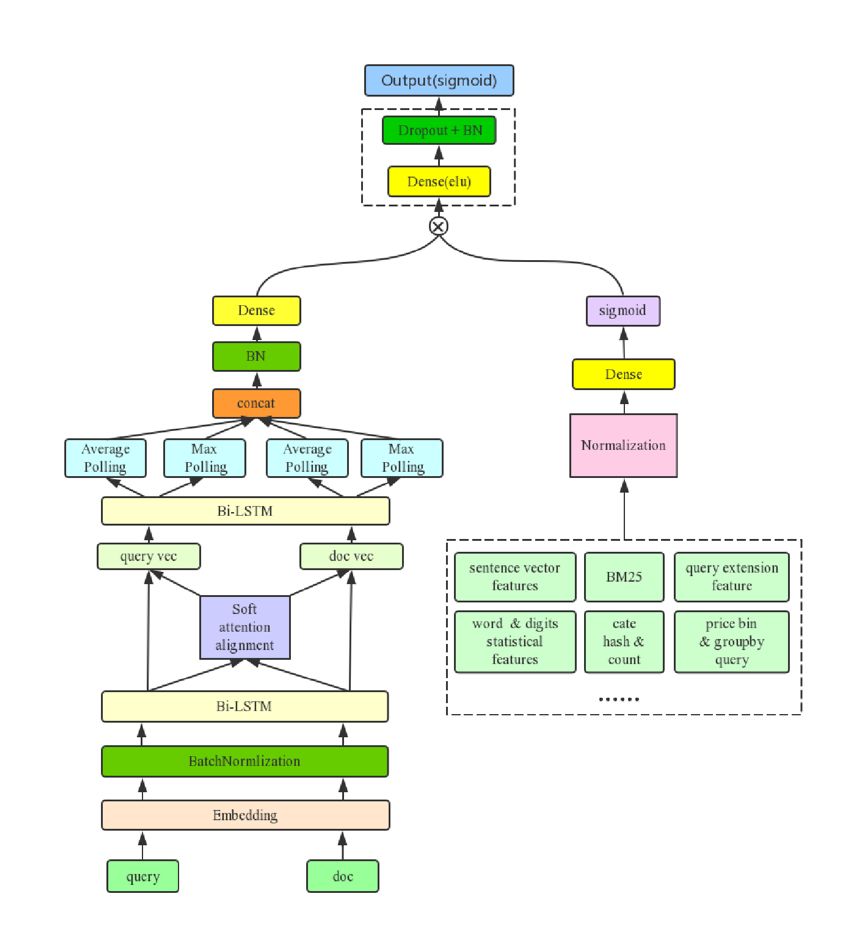
我们最好的单模型是在 ESIM 中引入我们构造的特征,这部分特征我们称做 dense feature。
在实验中发现把 dense feature 和 nn 模型某一层直接 concat 的效果并不好,我们参考了 product neural network 概念以及 LSTM 中的 Gate 设计,我们把 dense feature 做为 gate 来使用,使用中我们把 dense feature 经过全连接层得到和子模型维度一样的表示向量,然后加上 sigmoid 激活函数,再进行 element-wise-multiplication,这样 dense feature 就可以控制子模型的信息流通,通过实验发现这样的结构在各个子模型上都能够得到较大提升。
优化后的 Gate-ESIM 模型结构如下:
效果优化
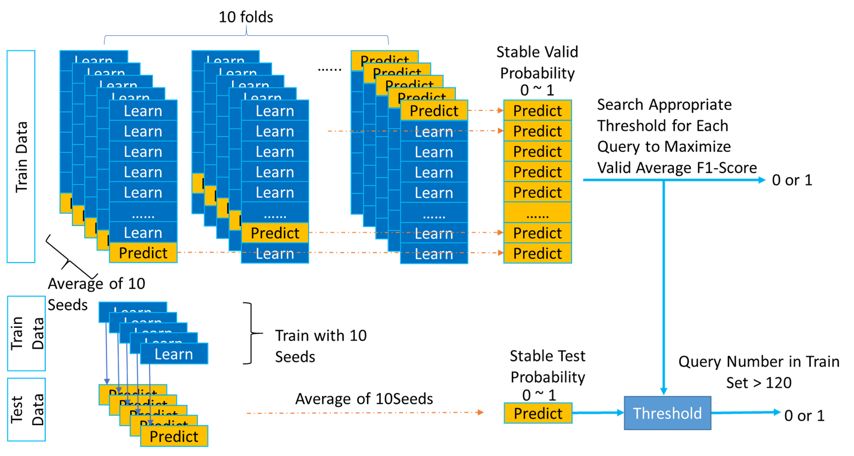
考虑到不同的 query 的训练数据量和分布都有些不同,并不一定都使用 0.5 作为正负例的划分阈值。所以我们可以调整每个 query 预测出来概率的正负例划分阈值,来优化 Average F1-Score。
相对于测试集,训练集的数量较少,为了让调整阈值后的结果更稳定,我们选择对训练集进行 10 折交叉验证,每折用 10 个不同的种子分别训练得到 10 个模型,然后把预测结果取平均。同样,对测试集预测时,用全量训练集用 10 个不同的种子分别训练得到 10 个模型,然后预测结果取平均。
在搜索阈值时,我们以优化 10 折交叉验证结果上的得分为目标。之后将 10 折交叉验证上搜到的阈值用于测试集。并且考虑到训练集中有些 query 数量较少,二分类的阈值微调后对验证集的分数会影响很大,所以我们选择只对训练集中样例数大于 120 的 query 调整阈值,数量约为整体的 81.3%。
这种优化方法虽然会在本地数据集上出现轻微的过拟合,但线上测试集也得到的较大提升,对我们后期的提分也是至关重要的。
实验结果
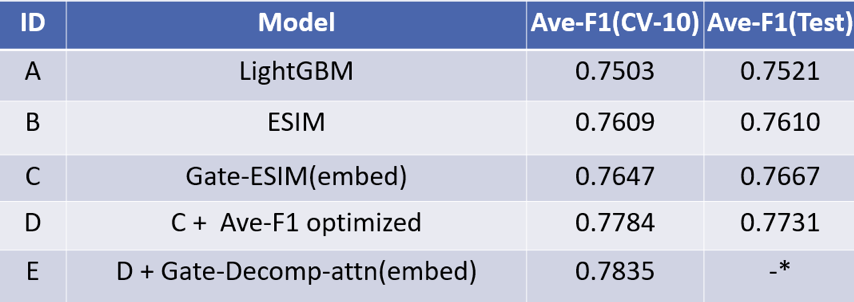
▲ 注: local最好的结果E没有来得及提交
从实验结果来看基于我们构造的特征的 LightGBM 模型在 Ave-F1 指标上也取得了 0.7521 的成绩,也能在榜单中排名前列,证明我们在特征工程上做了很多有效的特征。
经过参数调优的 ESIM [1] 模型在 Ave-F1 指标上也取得了非常好的效果,同时我们通过初始化预训练词向量和采用门限机制的 Gate-ESIM 的效果得到进一步提升。我们使用多种子 10 折交叉验证的方法在 local 搜索阈值对 Ave-F1 进行调优,经过这一步优化后的结果线上成绩达到 0.7731,提升非常明显。
最后我们对 Decomposable AttentionModel [2] 模型也进行了优化,最后和优化后的 Gate-ESIM 模型进行融合,在 local 效果上再次提升了千分之 5 左右,因结束时间理解有误未能提交到线上。
Poster

工作总结
提出了一种用 dense feature 做 gate 的网络结构,使得原有的模型得到较大提升;
对正负例划分阈值进行优化来提升评测指标效果。我们采用在 local 结果上进行阈值搜索的方式来优化评测指标,为了使得搜索到的阈值更稳定可靠,我们采用 10 折交叉验证并结合多 seed 的方式获取 local 预测结果,并且只在那些有不低于 120 个样本的 query 下进行阈值搜索;
构造丰富的基于 query,商品以及 query-商品对的特征;
使用不同的预处理方法构造特征,加强了特征表达。
进一步工作
尝试利用商品的图像信息;
对 query 和 doc 进行数据增强,增加更多训练样本;
对 query 进行扩展;
使用 BERT 进行 Fine-tune。
参考文献
[1] Chen, Qian, et al. "Enhanced LSTM for Natural Language Inference." ACL. 2017.
[2] Parikh, Ankur, et al. "A DecomposableAttention Model for Natural Language Inference." EMNLP. 2016.

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐





