解读Been There, Done That: Meta-Learning with Episodic Recall
最近在研究的线路就是: metal learning + episodic memory.
我觉得agent 需要能学习各种任务,也需要有记忆把学到的抽象的东西保存下来,这样可以1.通过搜索,联想,推理,在遇到新任务时,看似不相同也能从经验中快速学到规律,这样可以减少漫无边际的游荡在搜索空间的时间。2.重复出现的任务,就可以直接从记忆调取拿来用了。
这篇论文要解决或因面临什么样的现状而产生的?
1 当面临结构相近可是不同而新颖的任务时该怎么加快学习速度?
2 之前遇到过得任务确定会重复发生,你该怎么办,每次都重新学习?
即:confronting learners with (1) an open-ended series of related yet novel tasks, within which (2) preciously encountered tasks identifiably reoccur (for related observations, see Anderson, 1990; O’Donnell et al., 2009). In the present work, we formal-ize this dual learning problem, and propose an architecture which deals with both parts of it.
前提要点:
1 参考点:情景记忆是去保存曾经遇到过得场景和策略,避免每次遇到此类都需要反向传播式的增量更新。
2 对比: 对比当前场景的内部表示和过去场景的内部表示,选择出与当前相似的过去场景(策略动作)
3 快与慢的依赖关系:情景记忆依赖缓慢地增量式更新
4 学习者知道该采用什么样的归纳偏置
(对于标准的深度学习,学习者没有这些偏置信息,也就是会有较高的方差,所以会考虑很大范围的假设,从而希望找到那一个带有偏置的最优假设。)
5 学习如何学习: 能够加速强化学习,这一通用观点可通过多种方式实现,那篇(我上次介绍的前额皮质的论文)提出一种与神经科学和心理学特别相关的一种方法。
论文架构:
一个标准的LSTM + differentiable neural dictionary(DND)
即:This architecture melds the standard LSTM working memory with a differentiable neural episodic memory.
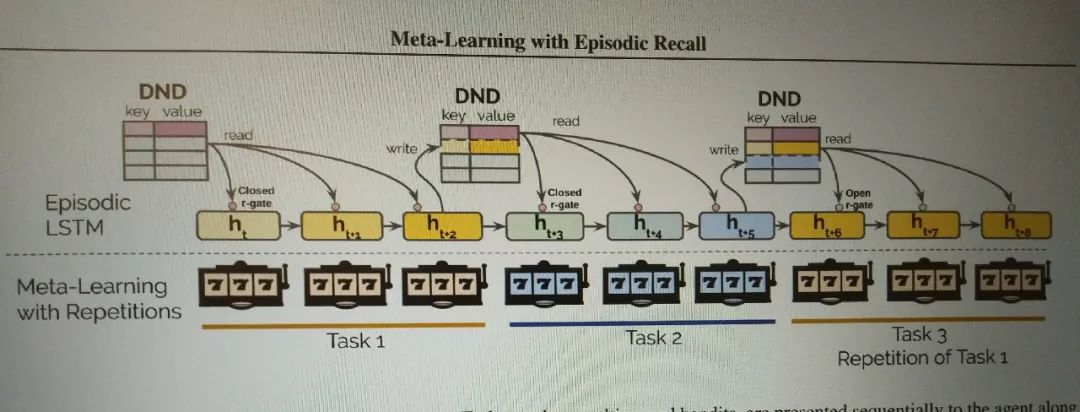
下面开始看图说话:
1.任务有3个,如图按序列的喂给LSTM网络
2.每个任务都有一个cue,这是标志任务开始了,所以要从DND中去搜索与当前cue最接近的一个key,找到对应value,传回给隐变量们,注意隐变量们不一定能得到这个值,这取决于有一个r-gate.
3.一开始r-gate是关着的,因为开始的训练是不需要从DND获得啥的,所以它关着,随着训练越来越接近尾声倾于稳定,这个门逐渐打开,使DND中存储的记忆能够回到对应的当前的隐变量中。这个过程称之为:读。
4. 在一个任务的结束时,会将这个任务的隐变量们和对应cue存储到DND中,又或者cue在DND中已经存在,那么就是去更新它。这个过程称之为:写。
5,具体r-gate是什么,下节见。
differentiable neural dictionary(DND)是什么?

如公式,r-gate就是图中rt,就是在LSTM中加一个门,它能让网络自己去调用和把握,自己去优化出最好的开放和关闭节奏,而不是规定死了每次都要用DND的内容完全决定决策。
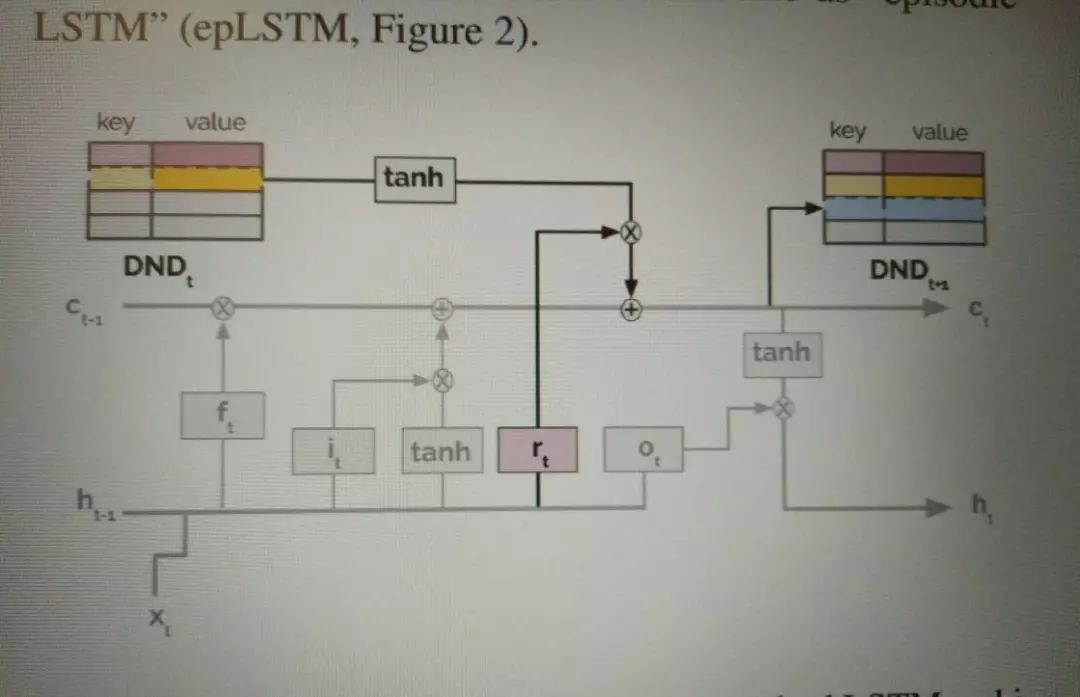
如上图,公式的另一种呈现。灰色部分是普通的LSTM结构,黑色线是应DND结构而生的门。
最后,github上有个自己实现的对应代码(pytorch):
https://github.com/qihongl/dnd-lstm/
我看了,他的memory(DND)就是由list来存储的,寻找相似记忆就是通过similarity函数实现的,metric(相似度衡量标准)可选,有L2距离,L1距离和余弦。
不过觉得它的实现,尤其是读和写的内容不符合我上面讲的理论,逻辑上我推理出它不能实现它预期的task based 的情景记忆任务。暂时没有时间去跑代码和深究。
若你看完也发现问题,或觉得没问题,欢迎交流:
wechat: Leslie27ch




