ACL 2020 | 多跳问答的基于对齐的无监督迭代解释检索方法




-
监督方法,要求训练时标注解释。然而,标签数据不总是可用的,并且标签当中可能含有噪音。 -
潜在方法,根据答案质量抽取解释,不需要显式的训练数据。例如强化学习和 PageRank 的思路。这类方法通常需要更多的问题-答案对数据。 无监督方法,使用无监督算法来抽取解释。

如图是一个需要多跳推理的样例问题。AIR 检索到的两个平行的解释链条提供了不完美的,但是与给定问题相关的解释。

该文所提出的 QA 方法包含两个组件:
-
无监督的迭代组件:在给定查询时,检索解释链。 答案分类组件:给定原问题和已检索到的解释,将候选答案分类为正确或错误。
下面分别对这两个组件进行简介。
2.1 迭代的解释检索
-
它使用对齐 -IR 方法 [1] 检索给定当前查询的最突出的解释句子。解释句子来自于数据集特定的知识库。 它调整查询以关注于缺失的信息,即当前解释链条没有覆盖的关键词。
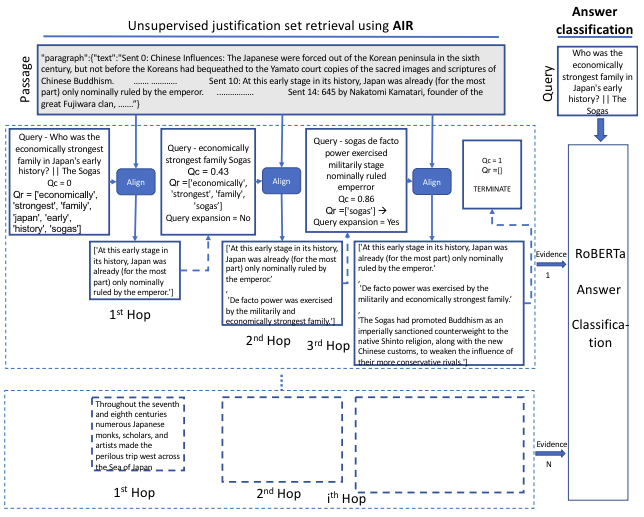
如图展示了 AIR 在 MultiRC 上迭代检索解释句子的情况。
对齐方法计算查询中的每个 token 和给定知识库句子中的每个 token 的词嵌入之间的余弦相似度,得到一个余弦相似度分数矩阵。对于每个查询 token,算法通过最大池化选择解释文本中最类似的 token。
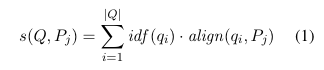
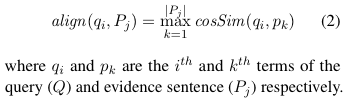
2.1.2 剩余项
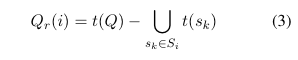

2.1.4 AIR 检索过程

停止条件:AIR 在满足以下两个条件中的任一条件时停止迭代地检索解释。
-
上一次解释检索的迭代中,没有发现新的查询项,即 -
所有查询项都被解释覆盖,即
2.2 答案分类
AIR 的解释链可以输入到任何监督的答案分类方法中,作者在实验中使用 RoBERTa。
以 MultiRC 为例,作者将查询(问题和候选答案文本组合而成)和解释文本拼接,并在两段文本中使用 [SEP]。然后对 [CLS] 标签使用 sigmoid 函数执行二分类任务(正确答案与否)。
在依赖大知识库的 QA 任务中,可能会出现:存在多个支持正确答案的解释链。为了利用这种答案分类的冗余性,作者扩展 AIR 以提取平行的解释链条。

实验与分析
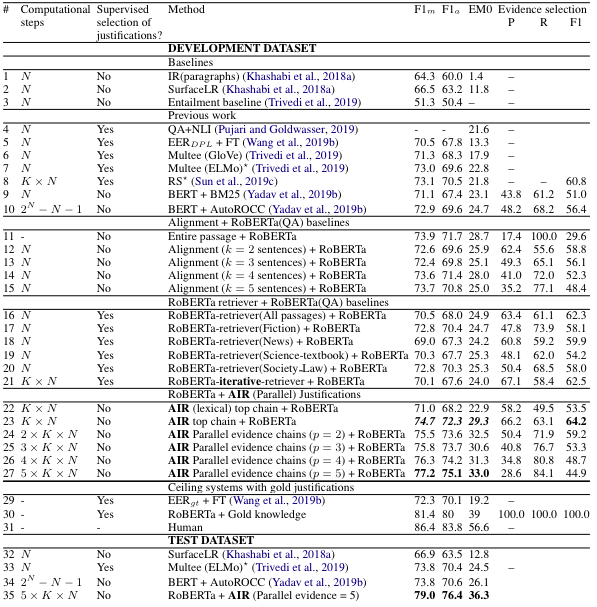
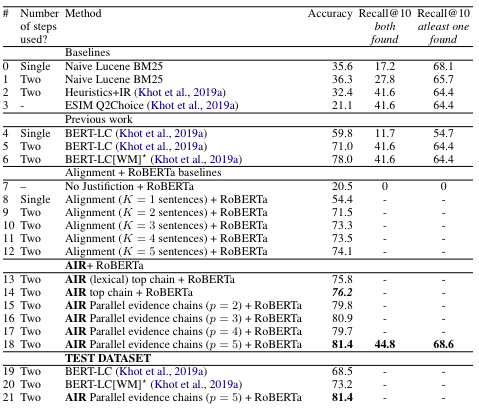
在之前介绍的算法外,作者还引入了一些基线算法。
MultiRC 上的 3 个基线算法:
将所有的段落文本馈送给 RoBERTa 分类器
使用对齐方法 [5] 检索得到 top-k 句子,该方法用于比较 AIR 的查询重构造
-
使用监督的 RoBERTa 分类器进行训练,为每个查询选择正确的解释
-
不包含任何解释 -
使用对齐方法检索得到 top-k 句子

小结
作者介绍了一种简单的、无监督的问答解释检索方法。该方法结合了三个想法:(a) 一种无监督的对齐方法,利用 GloVe 嵌入将问题和答案与解释句子进行软对齐;(b) 一个迭代过程,该迭代过程将重点放在现有解释未覆盖的查询剩余项上;(c) 一个简单的停止条件,当给定问题和候选答案中的所有项都被检索到的解释句子集合覆盖时,该迭代过程结束。

参考文献
[1] Vikas Yadav, Steven Bethard, and Mihai Surdeanu. 2019a. Alignment over heterogeneous embeddings for question answering. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, (Long Papers), Minneapolis, USA. Association for Computational Linguistics.
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




