从零开始:教你如何训练神经网络丨数据工匠简报
点击上方
Datartisan数据工匠
可以订阅哦!
1
从零开始:教你如何训练神经网络

作者从神经网络简单的数学定义开始,沿着损失函数、激活函数和反向传播等方法进一步描述基本的优化算法。在理解这些基础后,本文详细描述了动量法等当前十分流行的学习算法。此外,本系列将在后面介绍 Adam 和遗传算法等其它重要的神经网络训练方法。
本文是作者关于如何「训练」神经网络的一部分经验与见解,处理神经网络的基础概念外,这篇文章还描述了梯度下降(GD)及其部分变体。此外,该系列文章将在在后面一部分介绍了当前比较流行的学习算法,例如:
动量随机梯度下降法(SGD)
RMSprop 算法
Adam 算法(自适应矩估计)
遗传算法
作者在第一部分以非常简单的神经网络介绍开始,简单到仅仅足够让人理解我们所谈论的概念。作者会解释什么是损失函数,以及「训练」神经网络或者任何其他的机器学习模型到底意味着什么。作者的解释并不是一个关于神经网络全面而深度的介绍,事实上,作者希望我们读者已经对这些相关的概念早已了然于心。如果读者想更好地理解神经网络具体是如何运行的,读者可以阅读《深度学习》等相关书籍,或参阅文末提供的相关学习资源列表。
本文作者以几年前在 kaggle 上进行的猫狗鉴别竞赛(https://www.kaggle.com/c/dogs-vs-cats)为例来解释所有的东西。在这个比赛中我们面临的任务是,给定一张图片,判断图中的动物是猫还是狗。
扫码阅读原文

page
2
向开发者砸钱,百度要构建自己的AI生态护城河

进入年底,百度牟足劲希望在人工智能战略上再造一波声势。
日前百度在北京办了场AI开发者实战营,这是今年继深圳、成都、杭州、上海、广州之后的第五站。百度在会上宣布了“百度AI加速器”开营,这是个孵化器性质的机构,通过技术输入和资源倾斜,百度希望以资本的方式构建自己的生态护城河。
加速器第一期招募了包括光珀智能、鲲云科技、至真互联在内22个创业团队,涉及智能家居、智慧农业、智慧医疗、智慧司法、智能客服、AI芯片、汽车服务等多个领域。
在抢开发者这件事上,百度最近一年的动作很多,这家AI巨头最大的筹码是技术。具体而言,百度开放的重点是语音、图像、人脸、UNIT、AR、PaddlePaddle。今年早些时候,百度曾先后推出“机器人视觉解决方案”、“人脸硬件合作伙伴计划”、“人脸识别接口新计费模式”,并宣布“语音技术全系列接口永久免费开放”。
在免费开放技术接口这件事上,百度是动了真格的,目前一共开放了超过80项跟AI相关的技能。
扫码阅读原文

page
3
分布式TensorFlow入坑指南:从实例到代码带你玩转多机器深度学习
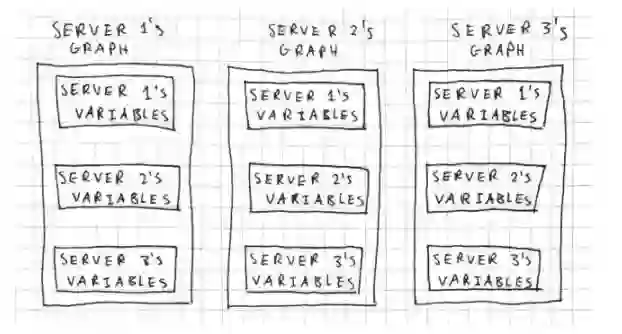
通过多 GPU 并行的方式可以有很好的加速效果,然而一台机器上所支持的 GPU 是有限的,因此本文介绍了分布式 TensorFlow。分布式 TensorFlow 允许我们在多台机器上运行一个模型,所以训练速度或加速效果能显著地提升。本文简要概述了分布式 TensorFlow 的原理与实践,希望能为准备入坑分布式训练的读者提供一些介绍。
不幸的是,关于分布式 TensorFlow 的官方文档过于简略。我们需要一个稍微易懂的介绍,即通过 Jupyter 运行一些基本例子。
如果你想交互式地使用 Jupyter,可以在 GitHub 上找到源代码。此外,本文的一些解释是作者自己对实证结果或 TensorFlow 文档的解释,因此可能会有一些小误差。
GitHub 地址:https://github.com/mrahtz/distributed_tensorflow_a_gentle_introduction
扫码阅读原文


更多课程和文章尽在微信号
「datartisan数据工匠」