记忆驱动的媒体学习与创意

1 引 言
经过百万年演化而成的人脑或许是世界上最复杂最精密的机器,它承载了人类所有智能活动(注意、学习、记忆、直觉、顿悟和决策等)。人脑的核心结构由百亿级神经元及百万亿神经突触构成。每个神经元通过神经突触“接收”从其他神经元传递过来的信息,再将加工处理后的信息通过神经突触传递给其它神经元。这样,外界感官信息(视觉、听觉、嗅觉、味觉、触觉)以复杂方式在大脑中被分析与处理,形成感知和认知。
“工欲善其事,必先利其器”。为了仿真大脑对外界信息的处理机制,首先要观测信息在大脑神经元和神经突触之间的“传递”。目前,光、电、磁和声等观测与调控技术为大脑观测提供了有效手段,打开了理解大脑、模拟大脑和连接大脑的大门。当前较为成熟的大脑观测方式有CT(电脑断层扫描)、MRI(磁共振成像)、PET(正电子发射计算机断层扫描)和fMRI(功能性磁共振成像)等。
记忆是大脑智能的基础。神经科学研究发现[1],人类有瞬时记忆、工作记忆和长期记忆三种形式的记忆体,三种记忆体及其联系如图1所示。瞬时记忆用来感知外界信息,如我们“眼观六路、耳听八方”,从外界环境中不断感知信息。瞬时记忆所感知得到的信息如果没有引起注意,则这些信息就成为了“耳边风”。只有那些引起注意力的信息被送入工作记忆体,直觉、顿悟和推理等智能活动就基于这些数据展开。在工作记忆区域中,当前输入(通过各种感官感知)信息(即当前数据)以及非当前输入信息(已存储的历史信息,如已有知识和过往经验)一起发生作用。也就是说,人脑在进行感知和认知时,不仅要对当前数据进行处理,还需要调动大脑中存储的相关信息。因此,注意力与记忆在人的认知理解过程中扮演了重要的角色,特别是对于文本、语音与视频等序列数据的知识获取与理解过程至关重要。古语常言“弦外之音、画外之意”,这就是人脑在认知理解中不仅仅依赖当前数据,通过从长期记忆中唤醒了类似信息,而对当前信息做出的加工和处理。可见,如果能对上述三种记忆体之间的交互和融合进行算法建模,我们就可以建立起一种“类脑计算”模式,完成智能处理任务。
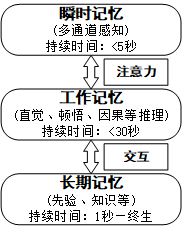
图1 瞬时记忆、工作记忆和长期记忆三种记忆体及其联系
《记忆碎片》这部影片描述了一位短期记忆缺失的人物。在生活中,这个人物有一个原型,该原型人物失去了记住半个小时前发生的事情的能力。科学家们一直认为,短期记忆是在大脑的海马体中形成与储存,长期记忆在大脑皮层长期储存。学习与记忆被认为由如下三部分组成:将事件编码进入神经网络、将编码好的信息储存起来、将来回忆的时候重新调出使用。这个过程如图2所示。
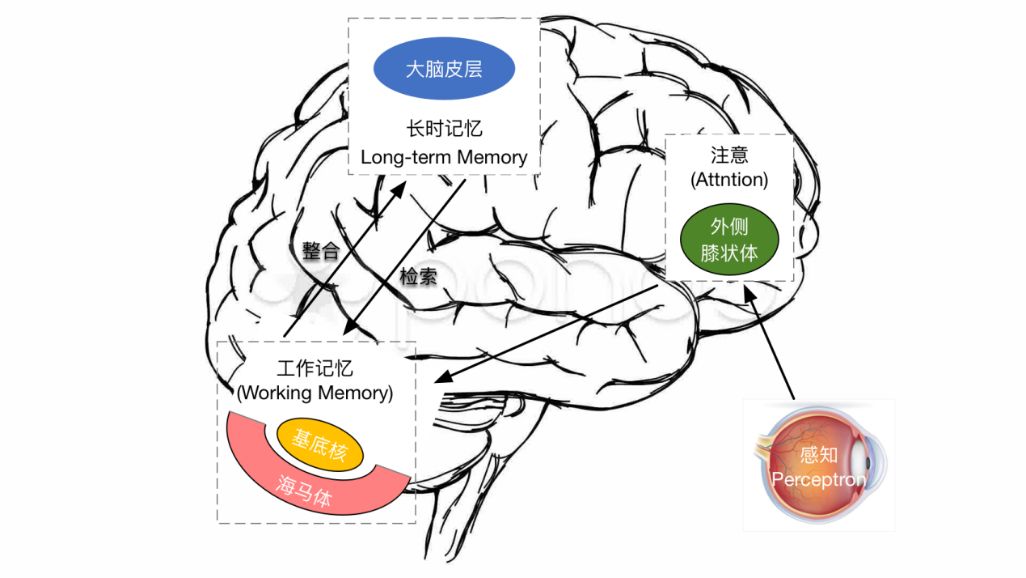
图2 大脑皮层中长时记忆和海马体中工作记忆的示意图
由于“端到端”深度学习在识别分类等任务中表现了优异性能,因此如何在深度学习模型中引入注意力机制和外在记忆结构,以挖掘数据中感兴趣的信息和有效利用外来信息,是当前人工智能研究的热点。这一方面的代表性工作是针对序列数据学习的反馈神经网络(Recurrent Neural Network, RNN[2])。理论上,RNN的当前状态依赖于所有前序输入与状态,也就是说RNN每个时刻可“记忆”过往全部信息,但在实际使用中由于梯度消失使得RNN在很短的序列中就表现出“遗忘”的特性,即多步之前的状态对当前状态输出几乎没有影响。为了克服这个问题,长短时记忆(Long Short Term Memory, LSTM[3])、门控循环单元(Gated Recurrent Unit, GRU[4])等模型引入了“短时记忆”的概念,即当前时刻状态的输出受到其过往若干时刻状态的影响。在“短时记忆”基础上,LSTM进一步学习序列数据中若干输入单元与某一输出之间的影响权重,使得LSTM具备了“注意力”机制,在机器翻译、语音识别和图文生成等领域取得了巨大成功,这一学习输入序列数据和输出序列数据之中若干单元之间相互影响的注意力机制也被称为“内在记忆(internal memory)”。
如前所述,人脑在理解当前场景和环境时,有效利用了与当前输入数据相关的信息,这些信息存储在外部记忆体(External Memory)中。神经图灵机(Neural Turing Machine, NTM[5])就是通过一个控制器(LSTM实现)来对一个外部记忆库(相当于图灵机中的纸带)中知识进行读/写操作,以有效利用已有知识和先验信息,这被称为是一种深度神经推理(DeepNeural Reasoning)的方法。类似的工作还有记忆网络(Memory Networks[6]) 、自适应计算时间(Adaptive Computation Time)、神经随机访问机器(Neural Random Access Machines)以及通过强化学习来训练NTM、堆栈和队列等形式的“外在记忆体”随机访问方法。
在端到端深度学习中引入注意力机制和记忆结构,可有效利用当前数据以外的数据和知识,克服了仅依赖于输入数据进行驱动学习的不足,在零样本学习等方面表现出一定的优势。为此,基于记忆驱动的手段和方法在媒体学习和创意中成为了当前的热点。
本文余下部分组织如下,第一节将介绍记忆网络的三个经典工作:神经图灵机、记忆神经网络和可微分神经计算机。第二节将会介绍国际关于记忆网络的研究与应用。第三节将会比较记忆网络的国内外研究进展。第四节将会展望基于记忆驱动的媒体学习和创意。
2 国内研究进展
本节主要介绍国内关于记忆网络的三个应用,分别是记忆驱动的自动问答、记忆驱动的电影视频问答和记忆驱动的创意(文本生成图像)。
2.1 外在记忆驱动下的自动问答
问答系统是一个允许用户发布问题和解决问题的平台。问答系统的好处已在文献[29][30]中得到充分认可。一些问答网站在现实世界中变得越来越流行,并且随着时间的推移已经积累了大量的问题与答案。凭借大量的问答数据,问答系统已成为一个活跃的研究领域,并在信息检索和自然语言处理(NLP)领域引起了广泛关注[31]。在各种问答研究中,仿真问答(FQA)是最广泛研究的任务之一[32]。
给定一段描述性语句,仿真型问答旨在提取实体答案。单句问题[33][34]是FQA中最常见的形式。例如:“世界上最大的大陆是什么?”。另一方面,还有另一种形式的FQA,其问题是描述某个实体的描述性段落。这种FQA的一个典型例子叫做QuizBowl[35][36]。Quiz Bowl问题由一系列有序句子组成,这些句子从不同角度描述了答案的方方面面。它有一个名为“金字塔”的属性,意味着先前描述问题的句子包含更隐蔽的线索,而之后的句子会给出较为具体的信息。图7展示了一个Quiz Bowl问题及其相应答案的示例。具有相同颜色的单词与答案具有相同的指示性提示(例如,Notre Dame du Haut和Villa Savoye是Le Corbusier使用钢筋混凝土框架设计的两座建筑。)。这个问题包含六个有序句子。前面的句子包含答案信息较少,后面的句子提供了更有用的线索来揭示答案。

图7 Quiz Bowl中的一个的例子
现有方法倾向于将Quiz Bowl问题视为文本分类任务。文献[35]在词袋模型的基础上,使用Naive-Bayes模型进行答案识别。为了完全理解每个句子的语义,文献[36]使用依赖树递归神经网络(DT-RNN)来利用句子编码中的依赖信息。文献[37]引入了堆叠卷积神经网络(CNN),以学习原始文本的句子表示和段落表示,并将这些特征映射到相应的答案。在文献[38]中,作者提出了一个深度平均网络(DAN)来学习描述段落与其答案之间的相关性。
上述方法仅侧重于利用单个句子与其对应答案之间的语义相关性,通过构建更好的语义空间以完成Quiz Bowl数据的语义分类。然而,社会学和生物学的研究表明[39][40],决策的形成通常受到信息流中不同时间节点下不同信息的综合影响。在QuizBowl竞赛中,当给出一系列有序的句子时,答案的线索逐渐给出。因此,最好利用句子的时序相关性来识别答案。除此之外,人类在阅读时,会联想到有相关性的辅助信息。在大多数情况下,我们在接收到问题后,都会通过检索自身已有知识,给出正确答案[41][42]。因此,文献[43]推测问题语句之间的时序相关性和外部知识是有助于提升Quiz Bowl回答准确率的两个因素,而利用这两个因素提升问答效果对本任务也是极具意义的。
基于以上的假设,文献[48]致力于如何有效地利用有序句子中的时序相关性和外部辅助知识提高QuizBowl的回答表现。具体来说,文献[48]设计了一种名为时序增强知识存储网络(Temporality Enhanced Knowledge Memory Network,TE-KMN)的新型网络架构。这种端到端的架构引入了一种基于注意力的时序模型,它是门控循环单元(GRU[4])的扩展,用于捕获有序语句的时序相关性。同时,利用每个描述句之外的辅助知识,增强对每句话的理解。
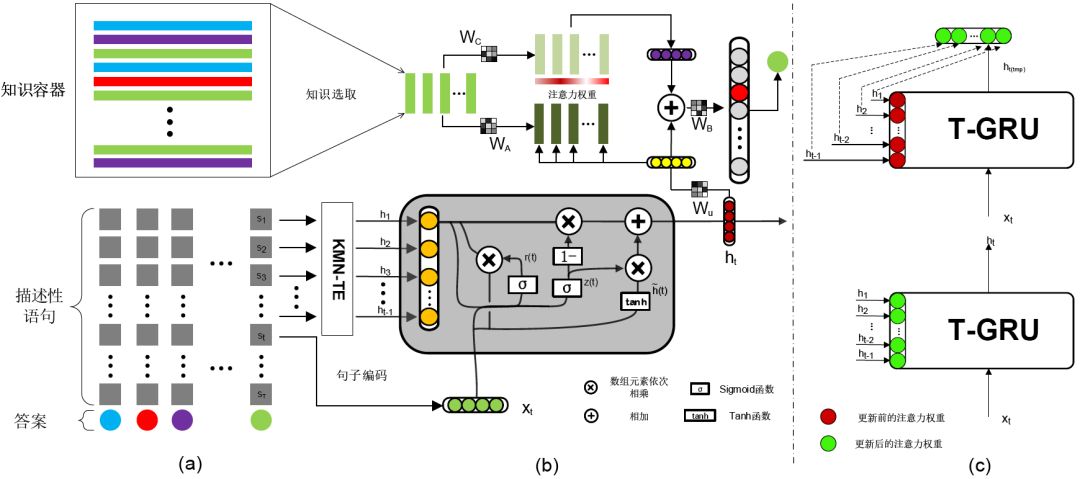
图8 时序增强知识存储网络结构图
图8是文献[43]提出的时序增强知识存储网络(TE-KMN)结构图,其中,(a)左下角是训练数据。对于每个答案,有几个有序的描述性句子从不同方面逐渐揭示一个答案。靠前的句子包含较少与答案相关的线索,而后序语句则包含较多线索。左上角是一个知识存储器,由外部辅助知识组成,这里的知识主要来自维基百科。(b)给出答案,假设总共有T个有序句子从不同方面描述答案(即 S1,S2……ST)。每个句子Si都被编码为向量Xi。每个句子ht的隐向量hi(1≤𝑖≤𝑡−1)将影响隐向量ht的学习。隐向量ht之后被传送到知识存储网络,并与句子st相关的外部辅助知识做进一步推理。(c)更新T-GRU的注意力机制。右上角是更新前的T-GRU。右下角是同一个T-GRU,h1, h2 ,..., ht-1是读取前面句子的T-GRU的隐藏输出。红色和绿色实心圆圈分别代表更新前后的α值。
2.2 基于层叠记忆网络的电影视频问答
建立视觉理解和人机交互之间的联系是人工智能领域一项具有挑战的任务。尽管视觉自动描述[44][45][46][47]在建立视觉内容与自然语言连接上取得一定进展,但它通常描述视觉内容的粗略语义信息,缺少对不同视觉线索之间的建模以及推理的能力。而视觉问题回答(VQA)[48][49][50]能够依赖全面的场景理解,对不同层次的视觉内容进行推理找到正确的答案。
人脑在应对和VQA类似的认知任务时,不仅需要对当前接收到的信息进行处理,还需要根据接收到的信息对大脑中存储的知识进行检索和推理。因此注意力机制和记忆在认知理解的过程中有很重要的作用。目前VQA任务中常见的方法是通过卷积神经网络(CNN)和递归神经网络(RNN)[48]在同一特征空间下学习图像和问题特征组合的表示。为了准确地关联特定的语言信息与特定的视觉内容,同时根据问题对已有的视觉内容进行推理,文献[49][50]分别提出利用动态记忆和注意力机制来提高VQA的性能。
视频可以看作是图片在时间和空间上的拓展,因此视频理解任务,需要模型不仅能够编码每一帧的信息,而且需要编码连续视频帧之间的时序性依赖关系。和一般视频相比,大多数电影具有特定的背景(例如动作电影和战争电影)以及拍摄风格。因此,仅通过视觉内容来理解电影的故事是一项具有挑战性的任务。另一方面,电影通常包含由演员之间对话组成的字幕信息,这部分信息能够为更好的理解电影内容提供帮助。针对视频理解等认知任务,虽然LSTM能够编码具有时序依赖性的时序信息且同时具有一定的记忆能力,但是LSTM的记忆能力有限并且不具备推理能力。为了提高模型的记忆能力并体现推理过程,NTM[50]通过一个控制器(LSTM)来对一个外部记忆库(相当于图灵机中的纸带)中知识进行读/写操作,以有效利用已有知识和先验信息,类似的工作还有Memory Networks [6]。
文献[51]探究了如何利用电影片段的视觉信息以及电影字幕进行电影问题回答任务。提出的层叠记忆网络(LMN)分别通过静态单词记忆模块和动态字幕记忆模块来存储单词和电影字幕信息,同时通过这两个模块学习电影视觉内容的分层表示,即帧级和片段级。静态单词模块包含MovieQA数据集[52]中的所有单词信息,而动态字幕记忆模块包含所有字幕信息。方法框架如图9所示,通过用静态单词模块中存储的单词信息表示每个电影视觉帧的区域特征并得到帧级表示。其次,生成的帧级表示输入到动态字幕记忆模块并得到最终的电影片段级表示。因此,分级形成的电影表示不仅对每一帧内视觉内容和单词之间的对应关系进行编码,而且还对电影片段内的字幕和帧之间的时间对应关系进行编码。
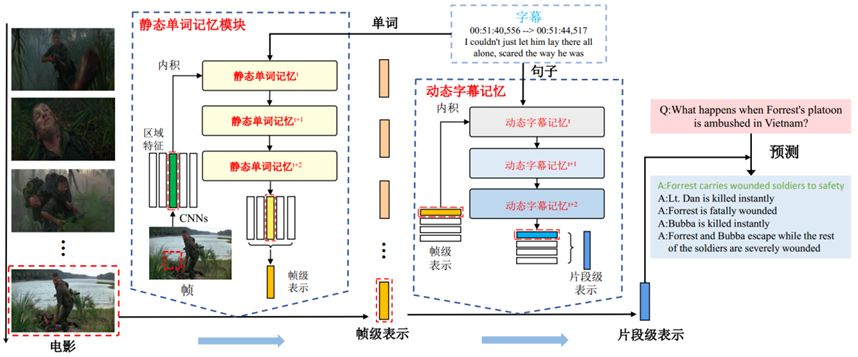
图9 LMN模型的框架
层叠记忆网络(LMN)能够同时利用视觉内容以及字幕内容进行电影问答任务。LMN的输入是逐帧特征图序列{I1,I2,...,IT},输出是LMN预测的正确答案。后续小节将绍LMN如何通过静态单词记忆和动态字幕记忆表示帧级和片段级的视觉内容。
2.2.1 用静态单词记忆模块表示电影视频帧
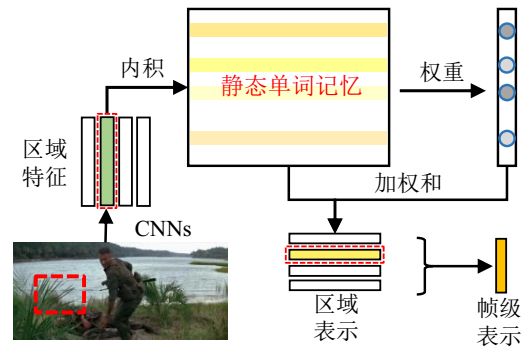
图10 词记忆模块的框架图
该模块的主要目标是通过静态单词记忆模块得到电影片段帧中特定区域的语义表示。如图10所示,该模块有一个静态单词记忆模块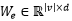
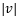
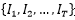
因此能够得到𝐻×𝑊大小的区域特征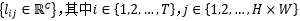
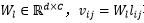
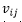

其中Wk表示静态单词记忆We中的第k行向量。Vij和Wk都先进行了归一化操作,因此αijk等价于cosine相似度。接下来区域特征Vij可以用记忆当中所有单词向量的加权和表示,如公式(15)所示。

其中|v|代表静态单词记忆的大小。符号:=表示“更新”操作。因此帧级的表示可以通过公式(16)计算。

因为每个区域特征是所有单词向量的加权和,Vi可以看做是第i个电影帧的语义表示。这个过程和图片区域上的注意力机制相似。但是该模型是建立记忆中的单词与每一个区域特征之间的联系。
文献[51]提出的静态单词记忆有两个特点:(1)静态单词记忆可以看做是一个单词嵌入矩阵,我们可以利用记忆将单词映射为连续向量;(2)静态单词记忆可以用于表示电影帧中的区域特征。
2.2.2 用动态字幕记忆模块表示电影片段
该模块的主要目的是通过动态字幕记忆得到电影片段中特定帧的语义表示。因为电影不仅包含视觉内容还包含字幕信息,因此,文献[51]提出了动态字幕记忆模块来表示带有电影字幕的电影片段,其框架如图11所示。
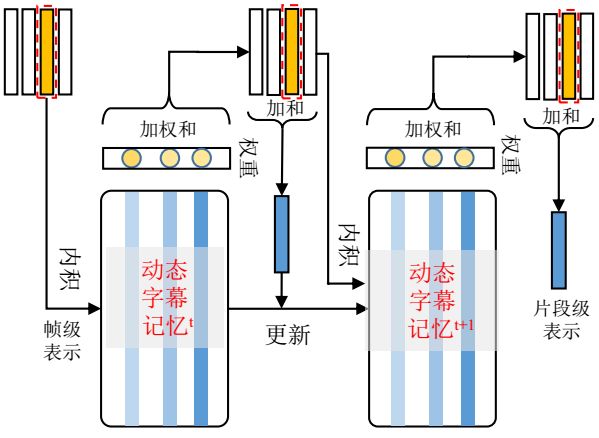
图11 动态字幕记忆模块的框架图
Fig.11 The framework of Dynamic Subtitle Memory module.
假设电影视频帧已被表示为公式(16)所示的输出Vi。然后,通过静态单词记忆得到字幕的表示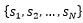

其中,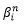
当在电影问答任务中只使用视频信息而不使用字幕信息时公式(19)中的帧级的表示{Vi}是公式(16)的输出。这样片段级的表示从单词空间转换到字幕句子空间,然后用文献[12]中提到的方法进行电影问答任务,如公式(20)所示。

其中u表示问题向量,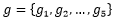
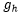
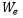
总的来说,层叠记忆网络[51]具有以下优点:(1)分别用静态单词记忆和动态字幕记忆得到区域特征和帧级特征,而不是学习联合嵌入矩阵。分层的帧级和片段级表示包含更丰富的语义信息,并在电影问答中获得良好的性能。(2)通过利用准确的单词和字幕信息表示每一个区域和帧级特征,在回答问题的过程中该模型能够支持精确的推理。
2.3 外在记忆驱动下的创意:文本生成图像
根据自然语言描述生成真实图像(text-to-image)是一项活跃的研究任务。该技术适用于许多实际应用,如图像编辑、原型和游戏设计。基于生成对抗网络(Generative Adversarial Network, GAN[54])的模型已经在CUB和Oxford Flower[55]等单类别单物体数据集上取得了非常有前景的结果。然而,现有的方法在像MSCOCO[56]这样的复杂数据集上取得的效果非常有限,在这些数据中,通常一个图像会包含不同的对象,并且对象很少处于图像正中[57][58]。为了生成复杂的场景,现有的方法试图利用词级注意力细粒度模型[59],建立层次化的文本到图像的映射[60],以及通过额外的对话增强文本描述[61]。然而,使用辅助视觉知识进行的工作还很少。根据人的作画过程,现实世界的场景或一些参考可以帮助作画者快速学习并提高作画质量。也就是说,一位成熟的作画者通常会在他/她的绘画中找到和使用额外的相关视觉线索。
因此,文献[62]使用图像子块作为视觉提示来增强文本到图像的生成。具体来说,文献[62]使用候选区域网络(Region Proposal Network, RPN[63])提取的候选块(proposal)作为存储在外部视觉知识存储器中的视觉线索。候选块特征向量可以被视为有意义的图像子块的视觉概要,尤其是那些包含实际物体概率最高的图像子块。RPN提取的候选块(即视觉线索)具有许多视觉细节,例如纹理,形状,颜色,物体大小等,它们可以被文本激活,并和文本描述一起合成最终的图像。
在文献[62]中,给定一个文本句子和外部视觉记忆,其首先利用多模态编码器将文本句子编码成多模态隐藏向量。多模态编码器类似于文献[24]提出的记忆网络模型。然而,文献[62]使用词嵌入而不是词袋表示。
2.3.1 视觉线索抽取
Region Proposal Network由文献[63]提出,通过对锚点区域框进行排名和优化,以生成最有可能包含对象的候选块。在RPN之后,ROI池化(Region of Interest Pooling)用于将不同大小的CNN特征图标准化为相同大小。ROI池化的输出将作为视觉线索。
文献[62]从MSCOCO训练数据集图像中提取了大约320000个候选块以构建知识库。候选块的选取过程如图12所示。每个候选块都是1024维的语义向量。当一个图像中有超过5个候选块时,只保留最有可能是物体的前5个候选块。
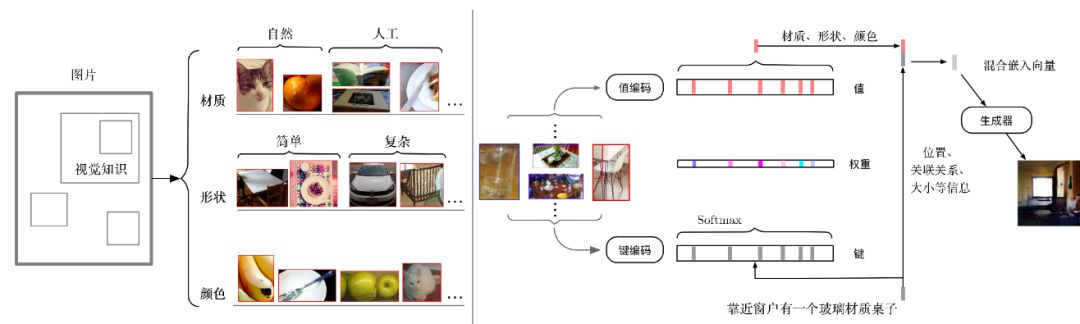
图12 视觉记忆候选块的抽取
2.3.2 多媒体编码
基于记忆网络,文献[62]的多模式编码器使用两个编码器和注意机制来编码Proposal(即视觉线索)和文本描述。
首先使用预先训练的文本编码器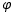
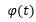
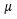
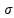
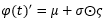
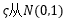

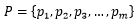

其中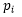
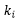
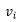
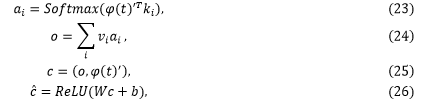
其中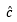
2.3.3 图像迭代生成
得到多模态隐向量后,将其输入给生成器,作为生成器的条件,约束生成器的生成结果,在我们的实验中有两个生成器,前者生成64*64的图像,并输出给下一个生成器,第二个生成器则会输出256*256的最终图像。两个生成器都使用生成对抗模型的框架进行训练。相应的,每个生成器都对应一个判别器,判别器用于指导生成器的生成。具体框架如图13所示。在生成的第一阶段,增强文本嵌入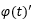
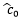
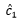
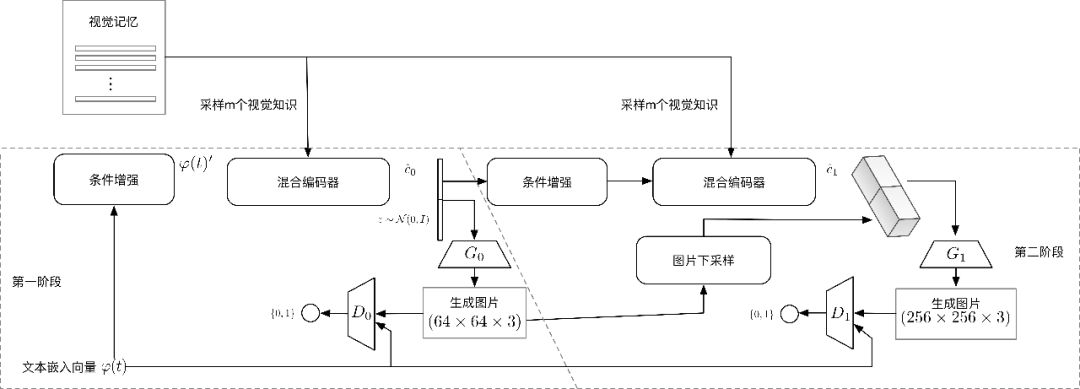
图13 vmCAN的框架图
3 国内外研究进展比较
关于国内外记忆网络的研究进展,对近五年(2014-2018)发表在机器学习与人工智能相关的国际顶级会议(ICML、NIPS、ICLR、AAAI、IJCAI、CVPR)上的论文进行调研,统计分析了题目包含“memory”的论文,统计结果如表1所示。
表1 2014-2018年国际顶级会议上关于记忆网络的论文数量统计
Table 1 Statistics of the number of the paper published on the top conference (2014-2018).
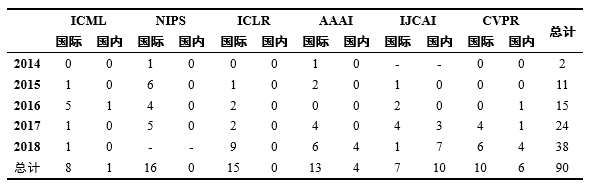
近五年来,国内外总共有90篇关于记忆网络的文章发表在上述的关于机器学习和人工智能的6大国际顶级会议中,统计调查以后,有以下发现:
(1)总体来讲,国际上关于记忆网络的研究领先于国内。在已发表的90篇文章中,其中69篇来自于国际,21篇来自于国内。且在认可度相对更高的ICML和NIPS上的文章数量,国际远多于国内。
(2)关于记忆网络的研究呈现快速增长趋势,且增长速度越来越快。2014年只有2篇关于记忆网络的研究,但随后以每年10篇左右的增长趋势增长,2018年关于记忆网络的研究已经达到38篇,这其中还不包括NIPS 2018的文章。可以预见,之后两年关于记忆网络的研究会越来越多。
(3)上述的各大机器学习与人工智能的会议既包含了理论又包含了应用,但每年关于记忆网络研究的论文数量分布都较为均匀,体现了记忆网络的通用性,也从侧面说明了记忆网络研究的重要性。
4 发展趋势与展望
随着近几年记忆网络的发展,利用外部存储形式的机器学习方法(即记忆网络)已经成为新一代人工智能发展中不可或缺的一个方向。目前来看,记忆驱动的研究有以下发展趋势:
(1)关于记忆网络的研究越来越多。如前所述,国内外关于记忆网络的研究正在蓬勃发展,每年发表在机器学习与人工智能相关的各大顶级会议上的论文数量正在逐年攀升。
(2)关于记忆网络的研究越来越热。如前所述,不仅每年发表在各大顶级会议上的论文数量越来越多,且每年的增长趋势并没有放缓。如表1所示,2015年增长了9篇,2016年增长了4篇,2017年增长了9篇,2018年增长了14篇。
(3)关于记忆网络的应用研究也越来越广泛。得益于记忆网络的通用性,记忆网络已经成功地运用于自动问答、视觉问答、物体检测、强化学习、文本生成图像等各个领域。
回顾机器学习与人工智能的发展历史,可以发现机器学习与人工智能正在朝着深度学习和神经网络的方向发展。如表2所示,从语言模型到神经语言模型,从贝叶斯学习到贝叶斯深度学习,从图灵机到神经图灵机,从强化学习到深度强化学习。可以预见,若有一种被称为“X”的方法,那将来很有可能出现一种“深度/神经+X”的方法。
表2 一些机器学习的发展趋势
Table 2 Trends of some machine learning methods

我们认为下一代的人工智能应该是从数据、经验并能自动推理的永不停息(never-ending)的学习[65]。数据驱动的机器学习方法已经成功运用于自然语言、多媒体、计算机视觉、语音和跨媒体等领域,后续应通过例如注意力机制、记忆网络、迁移学习、强化学习等方式与人类知识进行有机结合,从而实现从浅层计算到深度推理、从单纯的数据驱动到数据驱动与逻辑规则相结合、从垂直领域的智能到更通用的人工智能。
作者简介
吴 飞

吴飞,男,浙江大学计算机学院教授,主要研究方向为人工智能、跨媒体计算、多媒体分析与检索和统计学习理论。Email: wufei@zju.edu.cn.

韩亚洪

韩亚洪,男,天津大学计算机学院教授,主要研究方向为多媒体分析与检索、计算机视觉和机器学习。Email: yahong@tju.edu.cn.
廖彬兵

廖彬兵,男,浙江大学计算机学院博士生,主要研究方向为人工智能和数据挖掘。Email: bbliao@zju.edu.cn.
于俊清

于俊清,男,华中科技大学计算机科学与技术学院教授,主要研究方向为基于内容的视频分析、索引与检索、多核计算与流编译、视频情感计算、网络安全与大数据处理。Email: yjqing@hsut.edu.cn
中国计算机学会

长按识别二维码关注我们
CCF推荐
【精品文章】
点击“阅读原文”,下载和浏览报告。


