选自Psychology Today
作者:Cami Rosso
机器之心编译
编辑:陈萍、杜伟
在本文中,来自 MIT 的研究者探讨了关于深度学习中非常基础的问题,包括网络的近似能力、优化的动态规律和强泛化能力等。
人工智能(AI)的复苏很大程度上归功于深度学习在模式识别方面的快速发展。深度神经网络架构的构建一定程度上受到了生物大脑和神经科学的启发。就像生物大脑的内部运行机制一样,深度网络在很大程度上无法得到解释,没有一个统一的理论。对此,来自麻省理工学院(MIT)的研究者
提出了深度学习网络如何运行的新见解,有助于人们揭开人工智能机器学习的黑匣子
。
![]()
论文地址:https://cbmm.mit.edu/sites/default/files/publications/PNASlast.pdf
论文作者 Tomaso Poggio、Andrzej Banburski 和 Quianli Liao 来自 MIT 大脑、心智和机器中心(Center for Brains, Minds and Machines, CBMM),其中 Tomaso Poggio 是 MIT 计算神经学科「大家」,也是深度学习理论研究的先锋。他们创建了一种新的理论来解释深度网络的运行原因,并于 2020 年 6 月 9 日在 PNAS(美国国家科学院院刊)上发表了他们的研究成果。
![]()
值得强调的是,这篇论文的 editor 是 Stanford 理论大咖 David L. Donoho,他的研究方向主要包括谐波分析、信号处理、深度学习以及压缩感知。
研究者重点探究了深度网络对某些类型的多元函数的近似,这些函数避免了维数灾难现象,即维数准确率与参数量成指数关系。在应用机器学习中,数据往往是高维的。高维数据的示例包括面部识别、客户购买历史、病人健康档案以及金融市场分析等。
深度网络的深度是指计算的层数——计算层数越多,网络越深。为了阐明自己的理论,三位研究者
检验了深度学习的近似能力、动态优化以及样本外性能
。
对于一般的范例如下:为了确定一个网络的复杂性,使用函数 f (x ) 表示,理论上应当保证一个未知目标函数 g 的近似达到给定的准确率(> 0)。特别地,深度网络在近似函数方面比浅层网络具备更好的条件。这两种类型的网络都使用相同的操作集——点积、线性组合、单一变量的固定非线性函数、可能的卷积和池化。
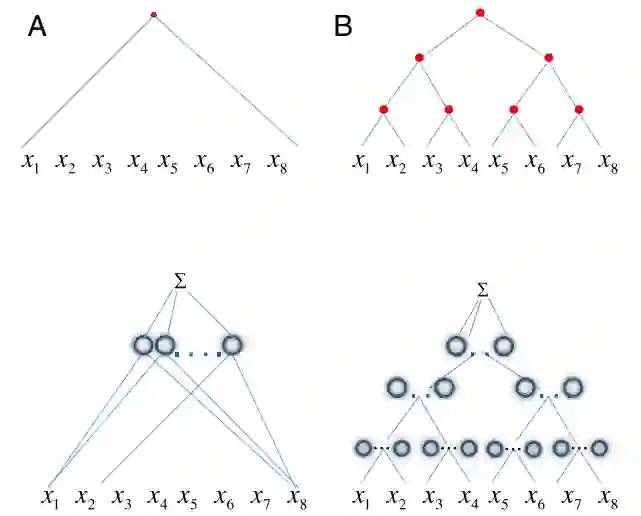
如下图 1 所示,网络中的每个节点对应于要近似的函数的图中的节点。结果发现,深度网络具有比浅层网络更好的近似能力。
![]()
研究者发现通过具有局部层级的深度卷积网络,指数成本消失,并再次变得更加线性。然后证明了对于特定类型的复合函数,卷积深度网络可以避免维数灾难。这意味着,对于具有局部层级问题,例如图像分类,浅层网络与深度网络之间的差距是指数级的。
「在近似理论中,无论是浅层网络还是深度网络,都在以指数代价近似连续函数,然而,我们证明了对于某些类型的组合函数,卷积型的深度网络(即使没有权重共享)可以避免维数灾难」,研究者表示。
之后该团队解释了
为什么参数过多的深度网络在样本外数据上表现良好
。该研究证明对于分类问题,给定一个用梯度下降算法训练的标准深度网络,那么重要的是参数空间的方向,而不是权重的范数或大小。
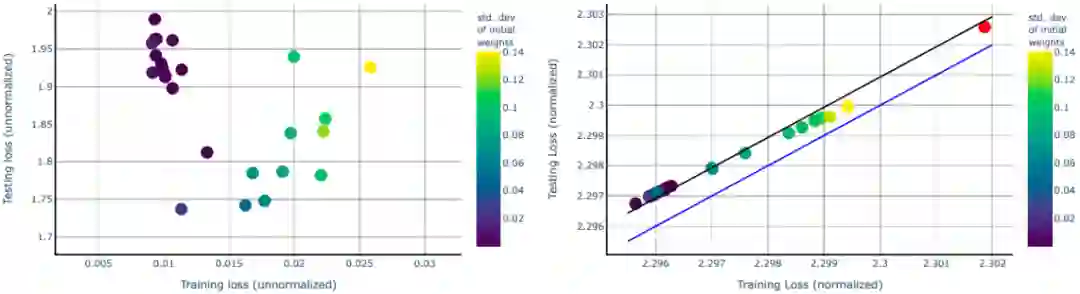
参考文献 27 的最新结果说明了在二元分类线性网络的特殊情况下过拟合的明显缺失。他们证明了最小化损失函数,如 logistic 函数、交叉熵和指数损失函数等会使线性可分离数据集的最大边值解渐近收敛,不受初始条件的影响,也不需要显式正则化。这里该研究讨论了非线性多层深度神经网络(DNN)在指数型损失下的情况,如下图 2 所示:
![]()
左图显示了在数据集(CIFAR-10)相同、初始化不同的网络上,测试与训练交叉熵损失的对比,结果显示在训练集上产生的分类误差为零,但测试误差不同;右图显示了在相同的数据、相同的网络上测试与训练损失的对比。
研究者这样描述:「在描述经验指数损失最小化的特征时,我们考虑的是权重方向的梯度流,而不是权重本身,因为分类的相关函数对应于归一化网络。动态归一化权值与单位范数约束下最小化损失的约束问题等价。特别地,典型动态梯度下降与约束问题具有相同的临界点。」
这意味着深度网络上的动态梯度下降与那些对参数的范数和大小都有明确约束的网络等价——梯度下降收敛于最大边值解。研究者发现了线性模型的相似性,在这种模型中,向量机收敛到伪逆解,目的是最小化解的数量。
事实上,研究者
假定训练深度网络的行为是为了提供隐式正则化和范数控制(norm control)
。科学家们把深度网络的这种能力归因为泛化,而无需对正则化项或权重范数进行明确的控制,而对于数学计算问题,则表明不管在梯度下降中是否存在强制约束,单位向量(从梯度下降的解中计算)保持不变。换言之,深度网络选择最小范数解,因此具有指数型损失的深度网络的梯度流具有局部最小化期望误差。
「我们认为,这项研究结果特别有趣,因为它可能解释了深度学习领域出现的最大谜团之一,即
卷积深度网络在一些感知问题上的不合理有效性
」,研究者写道。
随着应用数学、统计学、工程学、认知科学以及计算机科学跨学科的交融,研究者开发了一种关于为什么深度学习有效的理论,它可能会促进新的机器学习技术的发展,并在未来加速人工智能的突破。
原文链接:https://www.psychologytoday.com/us/blog/the-future-brain/202008/new-ai-study-may-explain-why-deep-learning-works
12月22日20:00,百度自然语言处理部资深研发工程师硕环老师将在第二期直播《NLP开发利器解析:中文超大规模预训练模型精讲》中介绍:
-
基于预训练的语义理解技术
文心(ERNIE)技术原理详解
文心最新技术解读
文心语义理解技术应用
扫码进群听课,还有机会赢取100元京东卡、《智能经济》实体书、限量百度鼠标垫多重好奖!
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com