WWWJ | 基于多视图表示学习的专利分类
1. 引言
在当今社会,专利是企业保护自身核心知识产权的重要工具。根据世界知识产权与专利局所发布的数据,2020 年全年的专利申请量已经超过 300 万个,相比于 2019 年增加 5%。并且这一数字在持续增加中。在通常情况下,专利审查员会根据其具有的领域知识手工将每个专利手动分为多个类别。然而,随着专利申请迅速增长,传统的手动操作费力费时,几乎无法满足需求。因此,迫切需要自动专利分类工具来支持相关服务。专利的自动分类对于提高大规模专利管理和服务的效率具有重要意义。
目前关于专利自动分类的相关研究大致可以分为两个方面:挖掘有效的特征与设计专用的分类器。专利文档中含有大量的元特征以及文本信息,通过从中挖掘有效的特征对专利进行分类。另一方面,特定的分类器如SVM,CNN,GRU,BERT等方法也被引入来解决专利自动分类问题。例如,DeepPatent建立了深度卷积神经网络模型,并结合词嵌入对专利文件进行分类, PatentBert利用了功能强大的预训练语言模型 Bert,然后对其进行微调以处理多标签专利分类问题。目前与深度学习相关的研究很少有从多视图的角度来关注此任务,同时现有方法缺乏可解释性,即将其分类为特定类别的原因解释。
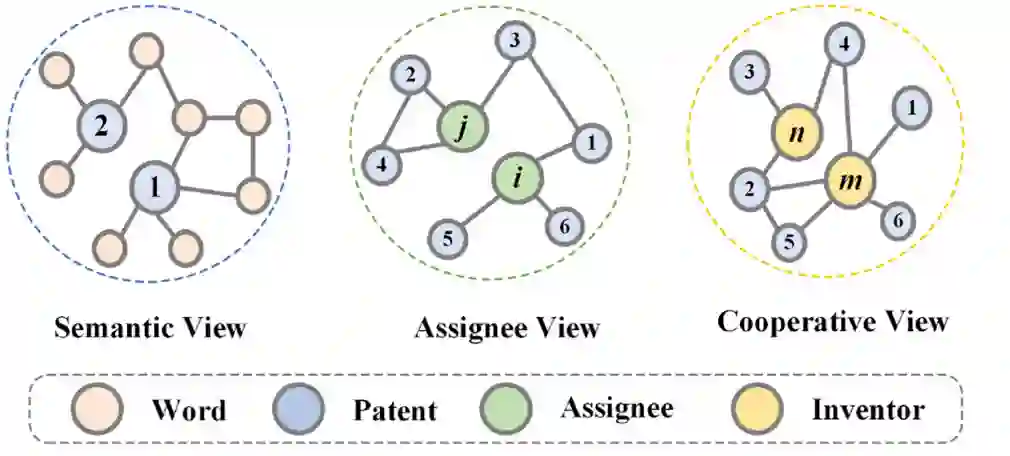
图1 专利多视图网络示例
为此,我们基于很少人关注的元数据信息,包括发明人和受让人公司,通过多视图专利网络分析的方法构建了名为 Patent2vec 的新颖框架。具体来说,我们首先根据专利数据的特性,将专利网络划分为三个视图,分别是语义视图、合作视图、受让人视图,如图1所示。进而,我们在单视图网络上根据其网络结构使用了不同的图表示学习方法来获得单视图的专利表示。之后,我们设计了一个包含多视图增强与多视图融合的多视图学习模块,其可以将多种视图的表示融合成单独的专利表示并且可以利用不同视图的相关性来增强专利的表示。最后,我们使用专利的表示来预测专利的类别。
相关成果已被中国计算机学会推荐B类国际期刊World Wide Web录用,论文信息如下:
论文标题:
Patent2Vec: Multi-view representation learning on patent-graphs for patent classification
论文作者:
Lintao Fang,Le Zhang,Han Wu,Tong Xu,Ding Zhou,Enhong Chen
2. 技术细节
2.1 问题描述
对于给定多视图专利网络
2.2 模型整体框架
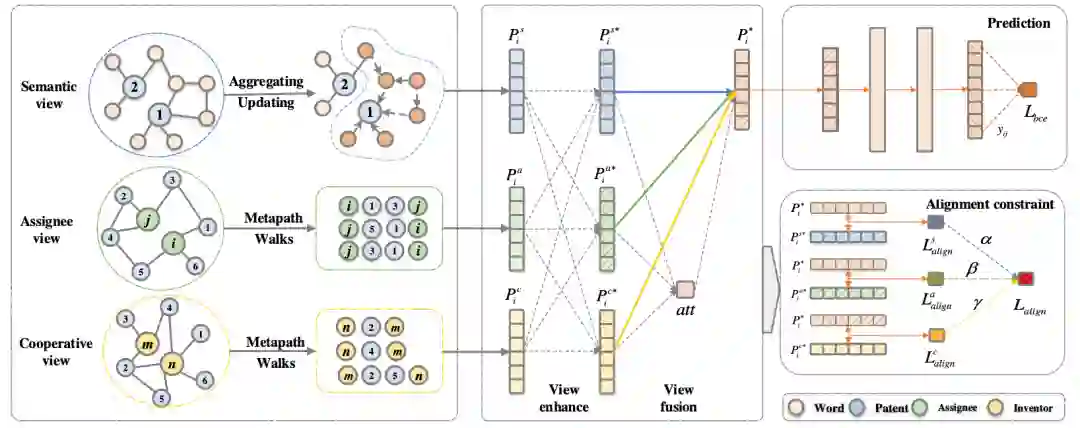
图2 模型整体框架
其中,模型输入是多视图网络的网络结构信息,输出的是每个专利节点的低维向量表示。考虑到专利数据的独特特性,我们首先构建了多视图专利图, 并进一步设计了一个多视图学习模块。我们的模型可以同时生成专利表征并针对特定的下游任务进行优化,以下内容将详细介绍技术方案的每个部分的细节。
2.3 单视图网络表征
针对不同的视图,我们采用不同的方法来得到单视图的表征。首先,对于语义视图表征,我们在构建的语义视图网络上使用GraphSAGE模型来学习节点的嵌入表示:
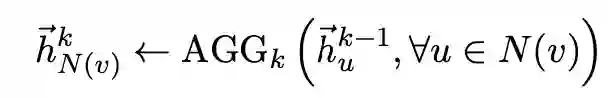
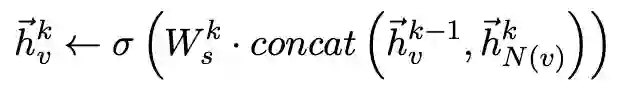
其次,对于受让人视图,我们使用了基于元路径的随机游走来学习节点嵌入,我们定义了一个元路径模式
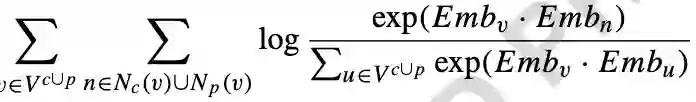
最后,对于合作视图,我们同样采用基于元路径随机游走的网络嵌入方法学习节点表示,类似地,其目标函数为:
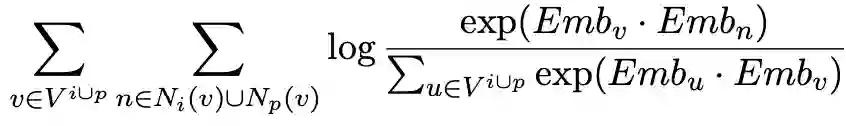
2.4 多视图学习模块
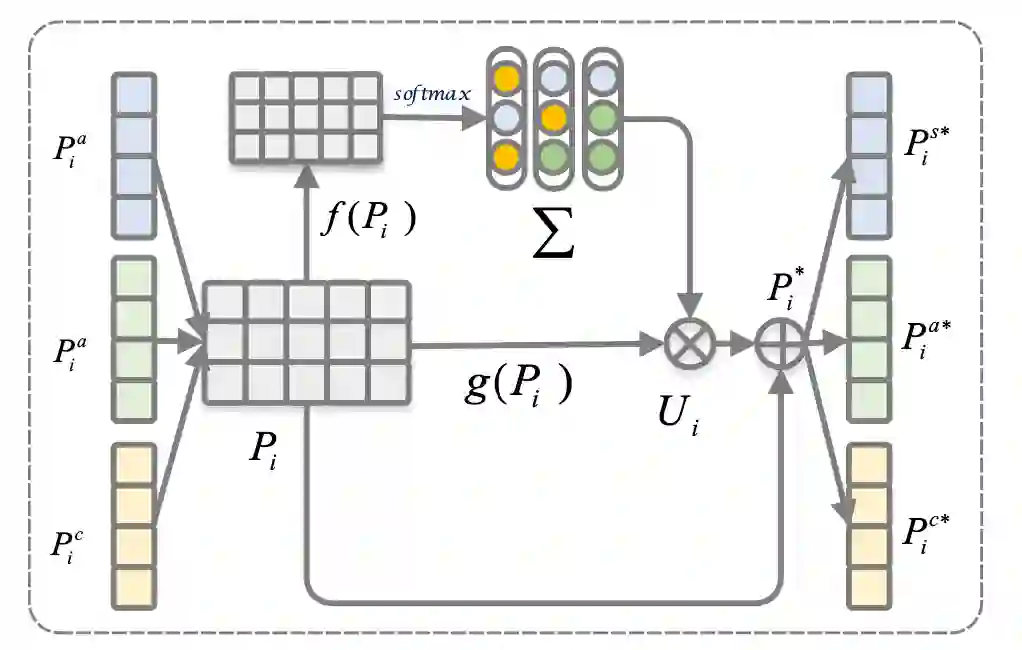
图3 表示增强模块的示意图
考虑到不同视图之间的相关性的知识,我们设计了一个视图增强模块,它通过从其他视图的表示来增强单视图表示,可以获得更好的单视图表示。其计算流程如上图3所示。
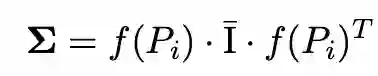
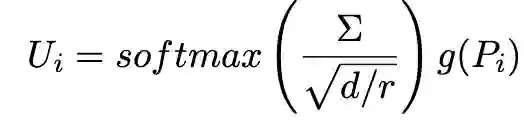
具体而言,我们使用基于注意力机制的多视图融合模块,将来自多个视图的表示融合提炼为单个表示:
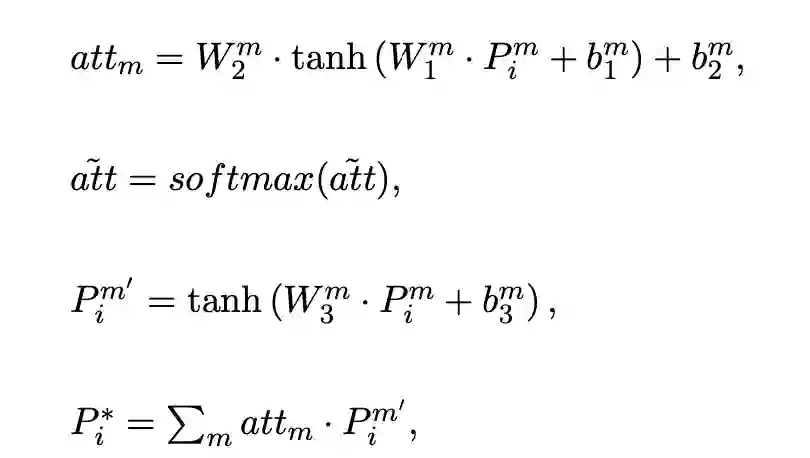
考虑到不同的视图表示处于不同的向量空间中,融合后的表征可能会引入额外的噪声,我们受到多模态表示学习的启发,提出了一个多视图对齐模块。其通过将不同视图的表示投影到一个共同的表示空间中,然后使得不同视图之间表示相近,其损失函数为:
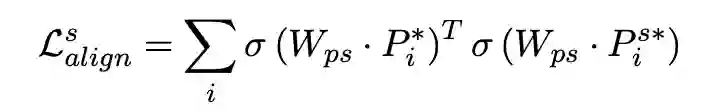
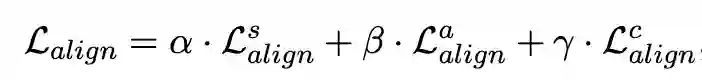
2.5 使用专利表示进行专利分类
在表示层之后,可以根据不同的任务接入不同的损失函数。在这里,我们的任务是专利分类,因此我们将融合的专利表示输入至两层全连接层预测专利的分类预测概率:
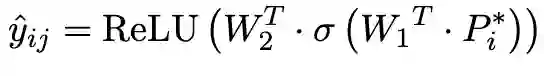
因为专利分类是多标签分类,在此使用BCE损失函数
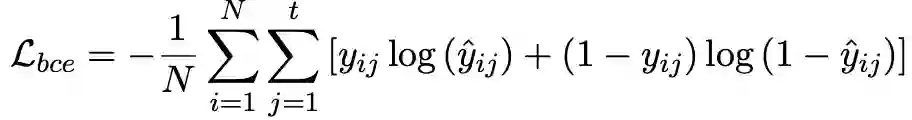
最终损失函数为分类损失和对齐约束损失的联合:
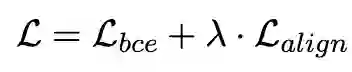
3. 实验
3.1 数据集
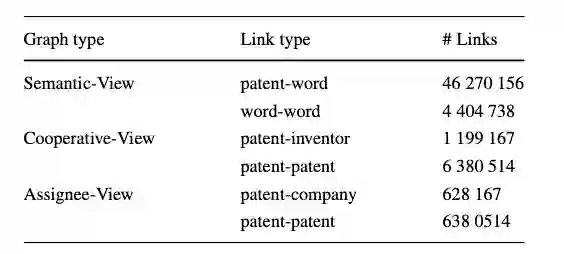
在数据方面,我们使用美国专利商标局(USPTO)的专利数据库,其中包含约600万条专利数据。不失一般性,我们从中抽取了约60万条专利数据。并据此构建了专利网络,关于该数据的具体信息见下表:
3.2 实验结果
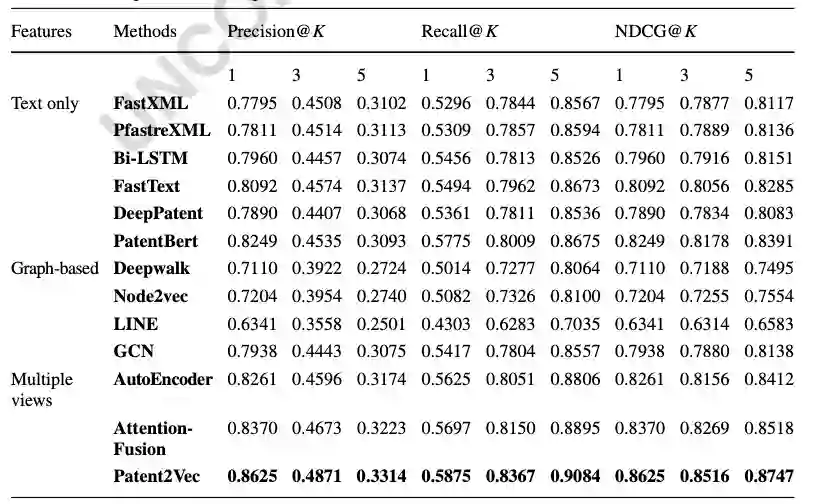
我们根据专利的预测结果正确与否来评估模型性能,采用了Precision@K,Recall@K以及NDCG@K指标进行对比。实验基准模型采用了基于文本分类的FastXML,Bi-LSTM,DeepPatent等模型和基于图的Deepwalk,node2vec,GCN等。整体的实验结果如下表所示:
3.3 消融实验
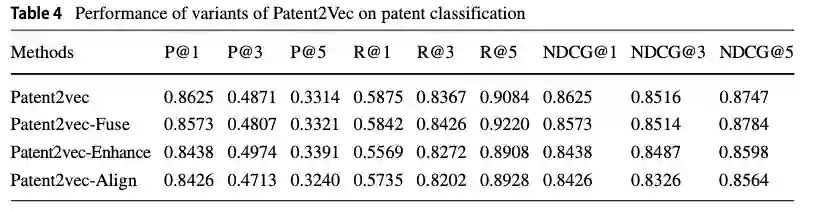
为了进一步验证提出的多视图表示学习模块对于学习专利表示的有效性,我们移除相应的模块,实现了几种变体Paten2vec-Fuse,Patent2vec-Enhance,Patent2vec-Alig等,实验结果如下表所示:
为了验证不同视图的重要性,在不改变其他模块的情况下,我们使用不同的视图信息组合进行实验,得到的结果如下:
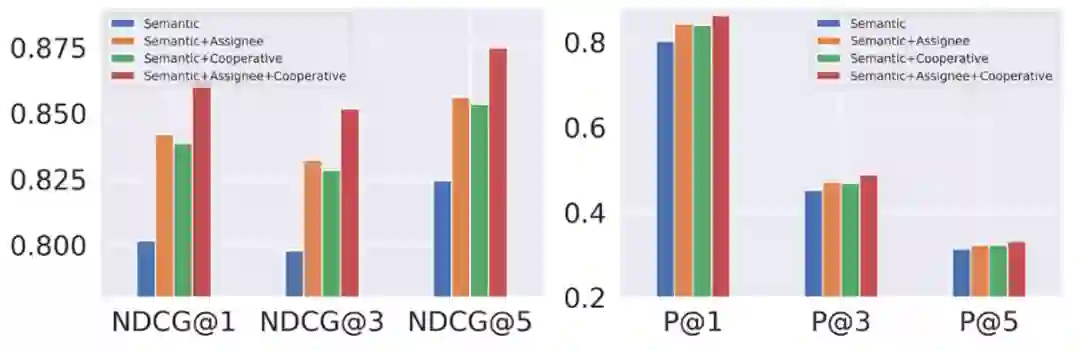
整体而言,实验结果证实了语义信息、受让人和合作信息对于专利分类的价值,并验证了我们所提出的多视图表示学习模块的有效性。
3.4 可视化
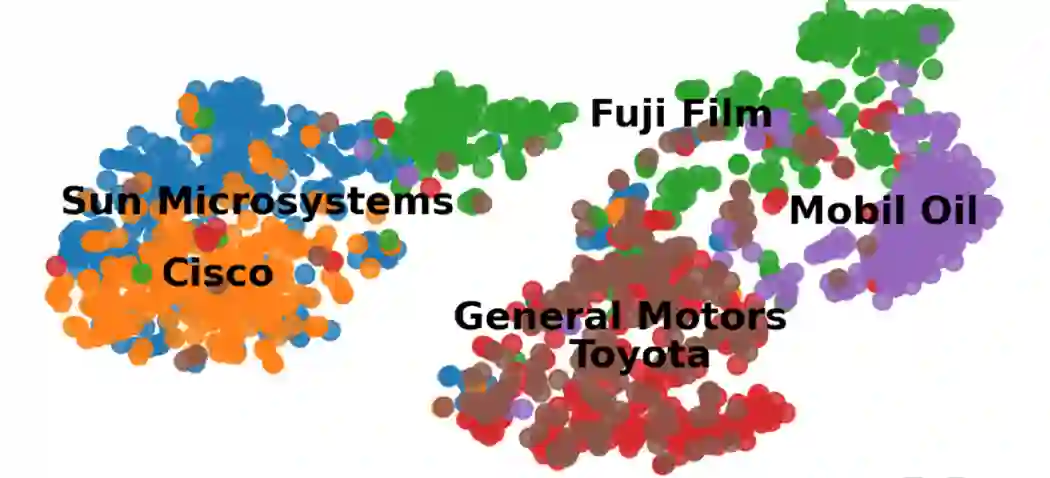
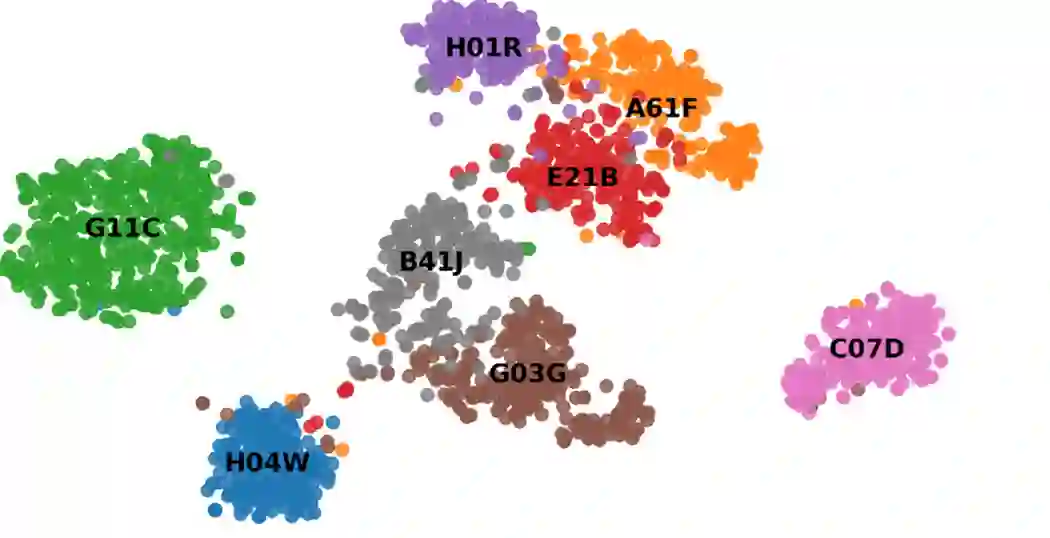
我们选取了若干类别,并使用TSNE将专利的表示可视化,其结果如下图所示,可以看到,我们学习得到的表征是有较好的区分性的。
同时,我们选取将不同公司的专利的表示进行了可视化,我们从信息技术和汽车等领域选择了几家公司并对它们进行可视化,我们可以发现具有相似经营业务的公司具有较大的覆盖而不同行业的具有较大的距离。从这两幅可视化的图中可以看出我们提出的多视图表示学习模型是有效的。