在
上一篇文章中,前苹果工程师、普林斯顿大学博士 Adi Fuchs 聚焦 AI 加速器的秘密基石:指令集架构 ISA、可重构处理器等。在这篇文章中,我们将跟着作者的思路回顾一下相关 AI 硬件公司,看看都有哪些公司在这一领域发力。
这是本系列博客的第四篇,主要介绍了 AI 加速器相关公司。全球科技行业最热门的领域之一是 AI 硬件, 本文回顾了 AI 硬件行业现状,并概述相关公司在寻找解决 AI 硬件加速问题的最佳方法时所做的不同赌注。
对于许多 AI 硬件公司来说,最近几年似乎是 AI 硬件发展的黄金时代;过去三年英伟达股价暴涨约 + 500%,超越英特尔成为全球市值最高的芯片公司。其他创业公司似乎同样火爆,在过去几年中,他们已花费数十亿美元资助 AI 硬件初创公司,以挑战英伟达的 AI 领导地位。
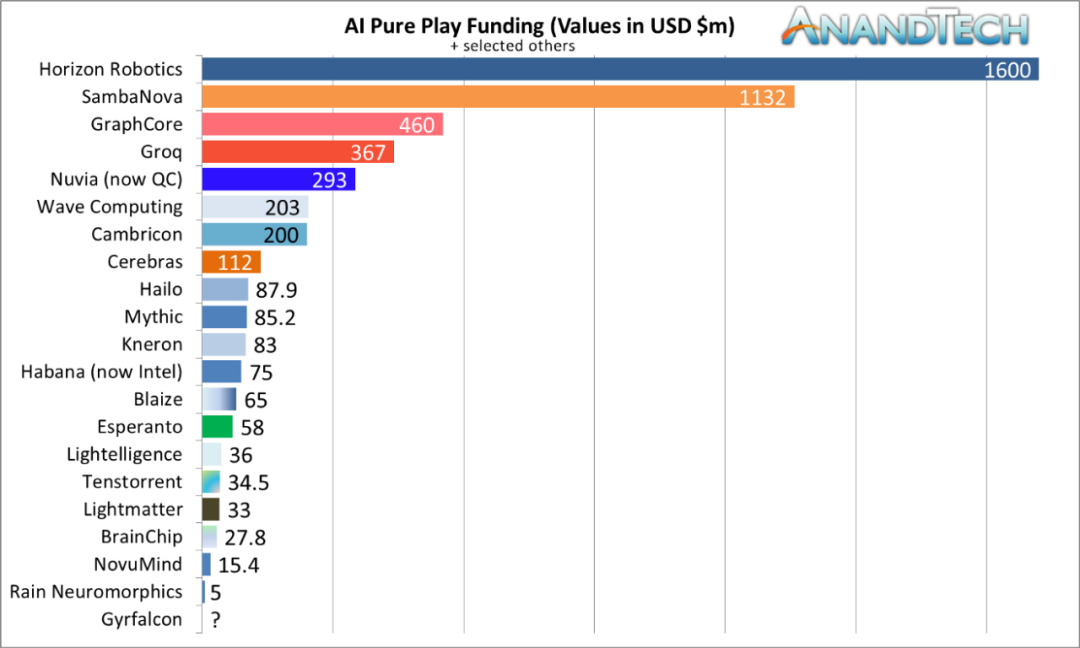
![]()
AI 硬件初创公司 - 截至 2021 年 4 月的总融资。图源:AnandTech
此外,还有一些有趣的收购故事。2016 年,英特尔以 3.5 亿美元收购了 Nervana,2019 年底又收购了另一家名为 Habana 的人工智能初创公司,该公司取代了 Nervana 提供的解决方案。非常有意思的是,英特尔为收购 Habana 支付了 20 亿美元的巨款,比收购 Nervana 多好几倍。
AI 芯片领域,或者更准确地说,AI 加速器领域(到目前为止,它已经不仅仅是芯片)包含了无数的解决方案和方法,所以让我们回顾这些方法的主要原则。
如果你在耕地,你更愿意使用哪个?两只壮牛还是 1024 只鸡?(西摩・克雷)
英伟达成立于 1993 年,是最早研究加速计算的大公司之一。英伟达一直是 GPU 行业的先驱,后来为游戏机、工作站和笔记本电脑等提供各种 GPU 产品线,已然成为世界领导者。正如在之前的文章中所讨论的,GPU 使用数千个简单的内核。相比来说,CPU 使用较少的内核。
最初 GPU 主要用于图形,但在 2000 年代中后期左右,它们被广泛用于分子动力学、天气预报和物理模拟等科学应用。新的应用程序以及 CUDA 和 OpenCL 等软件框架的引入,为将新领域移植到 GPU 铺平了道路,因此 GPU 逐渐成为通用 GPU (General-Purpose GPU),简称 GPGPU。
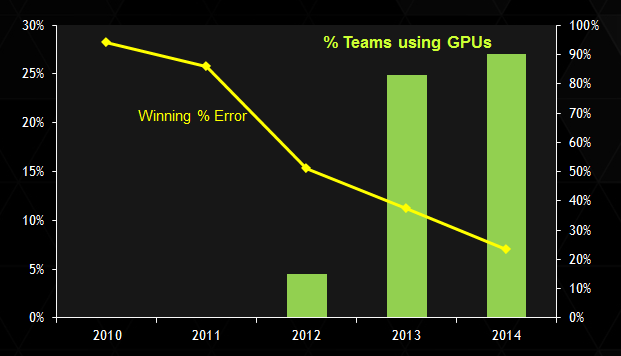
![]()
ImageNet 挑战赛:使用 GPU 的获胜误差和百分比。图源:英伟达
从历史上看,人们可能会说英伟达是幸运的,因为当 CUDA 流行和成熟时,现代 AI 就开始了。或者有人可能会争辩说,正是 GPU 和 CUDA 的成熟和普及使研究人员能够方便高效地开发 AI 应用程序。无论哪种方式,历史都是由赢家书写的 —— 事实上,最有影响力的 AI 研究,如 AlexNet、ResNet 和 Transformer 都是在 GPU 上实现和评估的,而当 AI 寒武纪爆发时,英伟达处于领先地位。
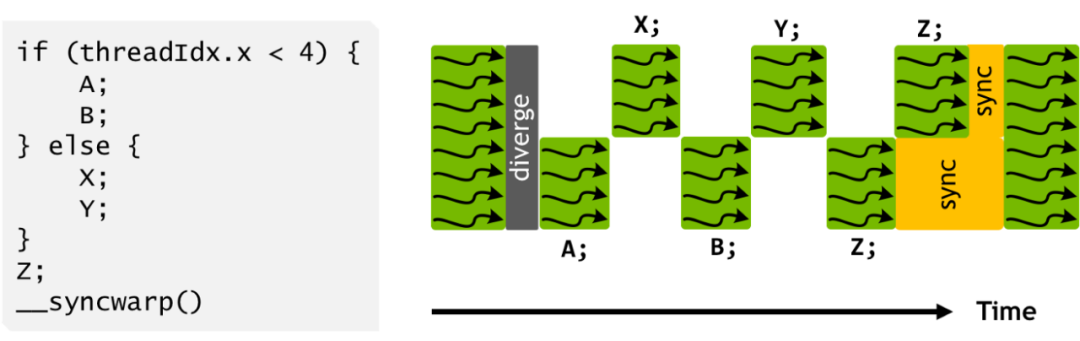
![]()
GPU 遵循单指令多线程 (SIMT) 的编程模型,其中相同的指令在不同的内核 / 线程上并发执行,每条指令都按照其分配的线程 ID 来执行数据部分。所有内核都以帧同步(lock-step)方式运行线程,这极大地简化了控制流。另一方面,SIMT 在概念上仍然是一个多线程类 c 的编程模型,它被重新用于 AI,但它并不是专门为 AI 设计的。由于神经网络应用程序和硬件处理都可以被描述为计算图,因此拥有一个捕获图语义的编程框架会更自然、更有效。
虽然从 CPU 转向 GPU 架构是朝着正确方向迈出的一大步,但这还不够。GPU 仍然是传统架构,采用与 CPU 相同的计算模型。CPU 受其架构限制,在科学应用等领域逐渐被 GPU 取代。因此,通过联合设计专门针对 AI 的计算模型和硬件,才有希望在 AI 应用市场占有一席之地。
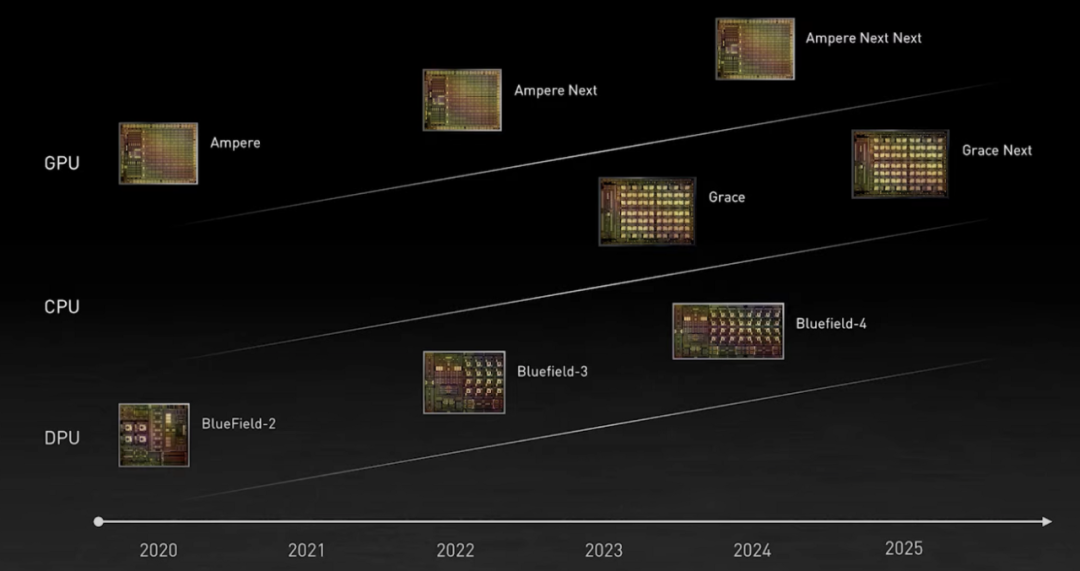
![]()
英伟达的 GPU、CPU 和 DPU 路线图。图源:英伟达
英伟达主要从两个角度发展 AI:(i) 引入 Tensor Core;(ii) 通过收购公司。比如以数十亿美元收购 Mellanox ,以及即将对 ARM 的收购。
ARM-NVIDIA 首次合作了一款名为「Grace」的数据中心 CPU,以美国海军少将、计算机编程先驱 Grace Hopper 的名字命名。作为一款高度专用型处理器,Grace 主要面向大型数据密集型 HPC 和 AI 应用。新一代自然语言处理模型的训练会有超过一万亿的参数。基于 Grace 的系统与 NVIDIA GPU 紧密结合,性能比目前最先进的 NVIDIA DGX 系统(在 x86 CPU 上运行)高出 10 倍。
Grace 获得 NVIDIA HPC 软件开发套件以及全套 CUDA 和 CUDA-X 库的支持,可以对 2000 多个 GPU 应用程序加速。
Cerebras 成立于 2016 年。随着 AI 模型变得越来越复杂,训练时需要使用更多的内存、通信和计算能力。因此,Cerebras 设计了一个晶圆级引擎 (WSE),它是一个比萨盒大小的芯片。
![]()
Andrew Feldman。图源:IEEE spectrum
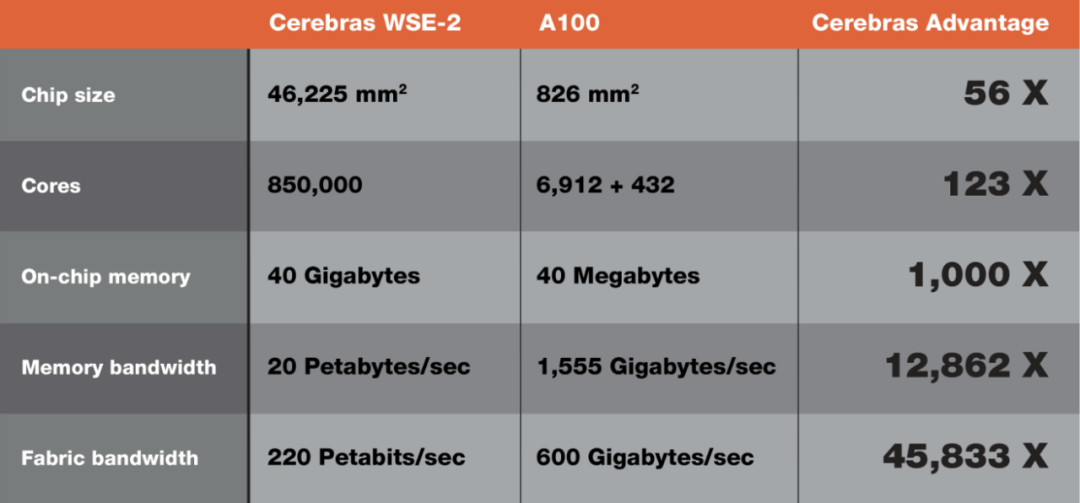
典型的处理芯片是在一块称为晶圆的硅片上制造的。作为制造过程的一部分,晶圆被分解成称为芯片的小块,这就是我们所说的处理器芯片。一个典型的晶圆可容纳数百甚至数千个这样的芯片,每个芯片的尺寸通常在 10 平方毫米到 830 平方毫米左右。NVIDIA 的 A100 GPU 被认为是最大的芯片,尺寸 826 平方毫米,可以封装 542 亿个晶体管,为大约 7000 个处理核心提供动力。
Cerebras WSE-2 与 NVIDIA A100 规格比较。图注:BusinessWire
Cerebras 不仅在单个大芯片上提供超级计算机功能,而且通过与学术机构和美国国家实验室的合作,他们还提供了软件堆栈和编译器工具链。其软件框架基于 LAIR(Linear-Algebra Intermediate Representation )和 c++ 扩展库,初级程序员可以使用它来编写内核(类似于 NVIDIA 的 CUDA),还可用于无缝降低来自 PyTorch 或 TensorFlow 等框架的高级 Python 代码。
总而言之,Cerebras 的非传统方法吸引了许多业内人士。但是更大的芯片意味着内核和处理器因缺陷而导致失败的可能性更高,那么如何控制制造缺陷、如何冷却近百万个核心、如何同步它们、如何对它们进行编程等等都需要逐个解决,但有一点是肯定的,Cerebras 引起了很多人的注意。
GraphCore 是首批推出商业 AI 加速器的初创公司之一,这种加速器被称为 IPU(Intelligent Processing Unit)。他们已经与微软、戴尔以及其他商业和学术机构展开多项合作。
目前,GraphCore 已经开发了第二代 IPU,其解决方案基于一个名为 Poplar 的内部软件堆栈。Poplar 可以将基于 Pytorch、Tensorflow 或 ONNX 的模型转换为命令式、可以兼容 C++ 的代码,支持公司提倡的顶点编程(vertex programming)。与 NVIDIA 的 CUDA 一样,Poplar 还支持低级 C++ 编程以实现更好的潜在性能。
![]()
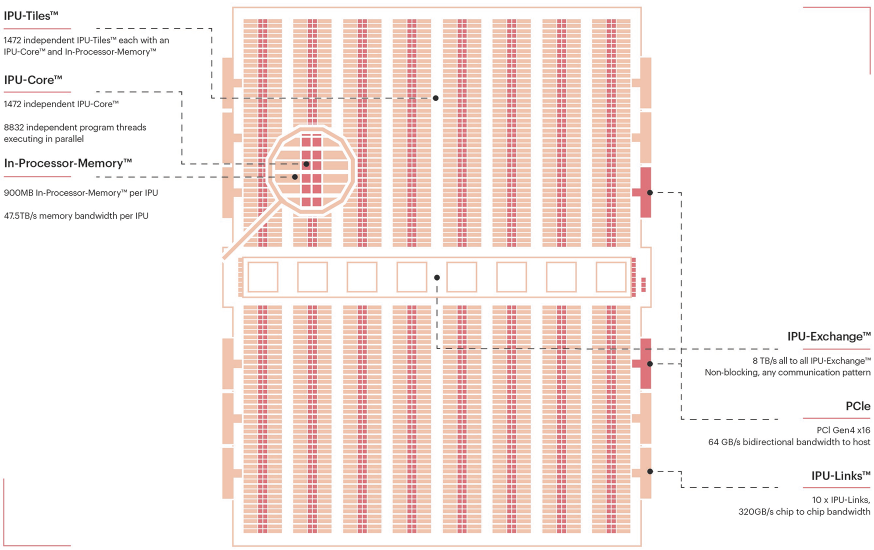
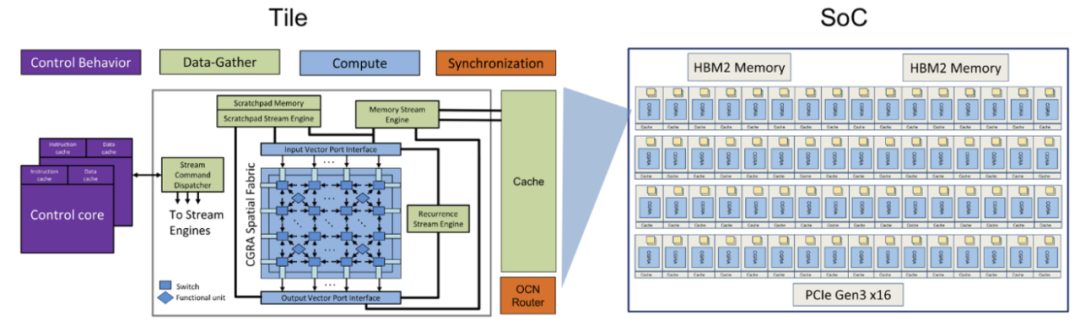
IPU 由 tiled 多核设计组成,tiled 架构由 MIT 于 2000 年代初研发,该设计描述了复制结构的 2D 网格,每个网格都结合了网络交换机、小型本地内存和处理核心。第一代 IPU 有 1216 个 tile,目前第二代 IPU 有 1472 个 tile。每个 IPU 内核最多可以执行 6 个线程,这些线程是包含其专有指令集架构 (ISA) 的代码流。
IPU 采用的是大规模并行同构众核架构。其最基本的硬件处理单元是 IPU-Core,它是一个 SMT 多线程处理器,可以同时跑 6 个线程,更接近多线程 CPU,而非 GPU 的 SIMD/SIMT 架构。IPU-Tiles 由 IPU-Core 和本地的存储器(256KB SRAM)组成,共有 1216 个。因此,一颗 IPU 芯片大约有 300MB 的片上存储器,且无外部 DRAM 接口。连接 IPU-Tiles 的互联机制称作 IPU-Exchange,可以实现无阻塞的 all-to-all 通信,共有大约 8TB 的带宽。最后,IPU-Links 实现多芯片互联,PCIe 实现和 Host CPU 的连接。
Wave Computing、SambaNova 和 SimpleMachines 是三家推出加速器芯片的初创公司。其中 Wave Computing 成立于 2008 年,其使命是「通过可扩展的实时 AI 解决方案,从边缘到数据中心革新深度学习」,该公司由 Dado Banatao 和 Pete Foley 创立。一段时间以来,它一直处于隐身模式,从各种来源获得资金。
Wave Computing 的核心产品是数据流处理器单元(DPU),采用非冯诺依曼架构的软件可动态重构处理器 CGRA(Coarse grain reconfigurable array/accelerator)技术,适用于大规模异步并行计算问题。2019 年前后,Wave Computing 针对边缘计算市场的算力需求,将 MIPS 技术与 Wave 旗下 WaveFlow 和 WaveTensor 技术相结合,推出 TritonAI 64 IP 平台。但不幸的是,它在 2020 年申请了破产保护。
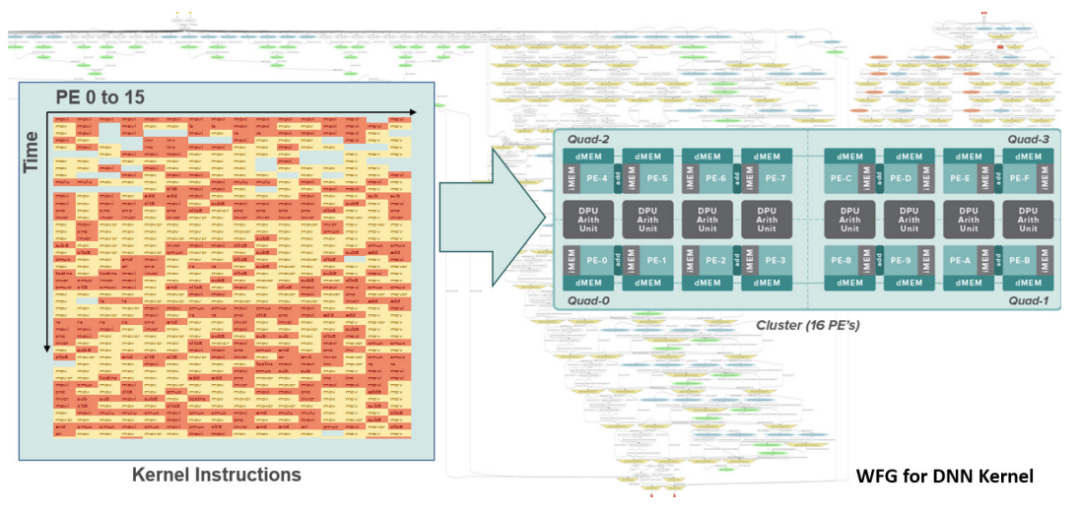
![]()
基于时间的 DPU 核映射。图源:Wave Computing
SambaNova 成立于 2017 年底,自那以来,该公司获得了由 Google Ventures,Intel Capital 和 Blackrock 领导的三轮融资以及在美国能源部的 Laurence Livermore 和 Los Alamos 的部署。他们现在已经可以为一些客户提供新产品。
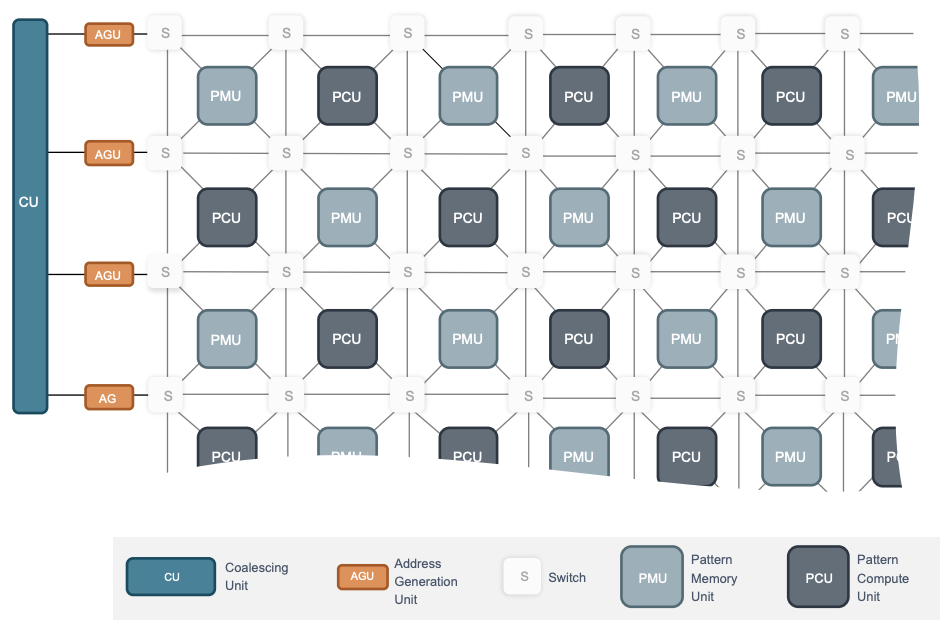
![]()
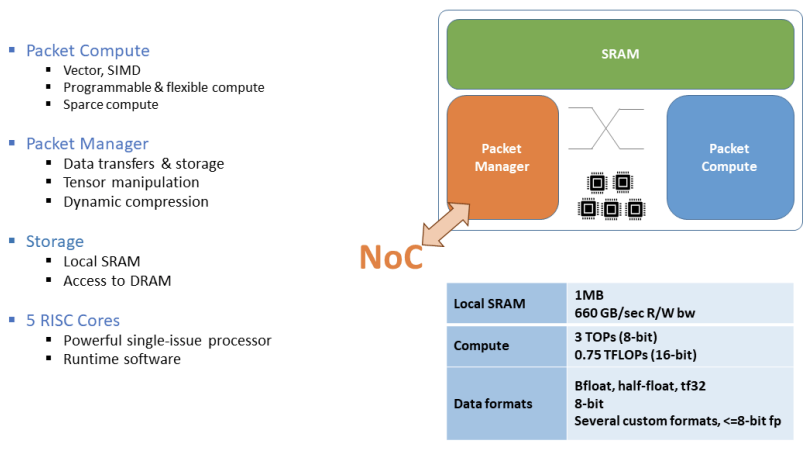
SambaNova 正在为数据中心构建芯片和软件栈,目标是用 AI 进行推理和训练。其架构的核心是可重构数据流单元(RDU,reconfigurable dataflow unit)。RDU 芯片包含一组计算单元(称为 PCU)和暂存器存储单元(称为 PMU),它们以 2D 网格结构组织起来,并与 NoC 交换机连接。RDU 通过一组称为 AGU 和 CU 的单元结构访问芯片外存储器。
![]()
SambaNova 的关键用例。图源:HPCWire
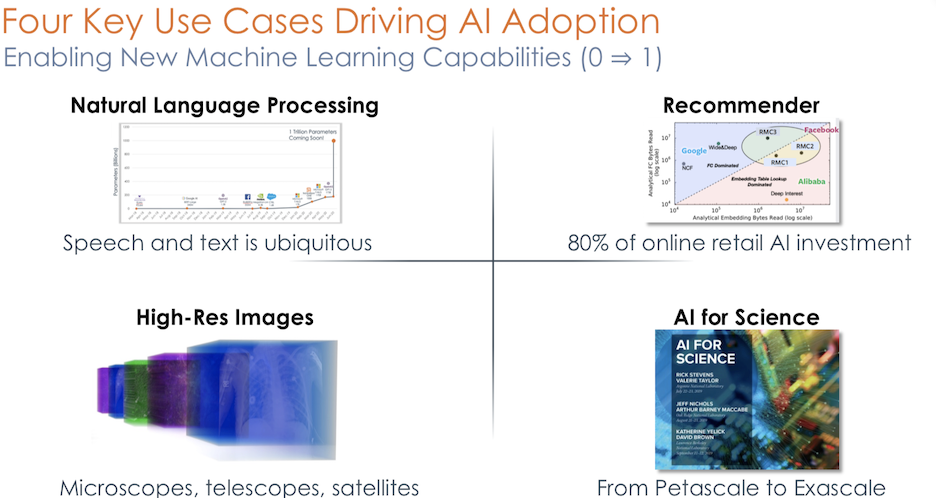
SambaNova 的软件堆栈(称为 Sambaflow)采用高级 Python 应用程序(例如 PyTorch、TensorFlow )并将它们降低为可以在编译时对芯片 PCU、PMU、AGU 和 CU 进行编程的表示。SambaNova 展示了 RDU 架构可以运行复杂的 NLP 模型、推荐模型和高分辨率视觉模型。
SimpleMachines 由威斯康星大学的一群学术研究人员于 2017 年创立。该研究小组一直在探索依赖于结合冯诺依曼(逐条指令)和非冯诺依曼(即数据流)执行的异构数据路径的可重构架构。
该公司提供的数据均参考了在顶级学术会议和期刊发表的原创研究论文。指导架构原则有点类似于 SambaNova 正在做的事情,即开发一个可重新配置的架构,以支持非常规编程模型,实现能够应对高度变化的 AI 应用程序空间的灵活执行。
![]()
SimpleMachines 的 Mozart 芯片。图源:SimpleMachines
该公司的首个 AI 芯片是 Mozart,该芯片针对推理进行了优化,在设计中使用了 16 纳米工艺,HBM2 高带宽内存和 PCIe Gen3x16 尺寸。2020 年,SimpleMachine 发布了第一代加速器,该加速器基于 Mozart 芯片,其由一个可配置的 tile 数组组成,它们依赖于控制、计算、数据收集等的专业化。
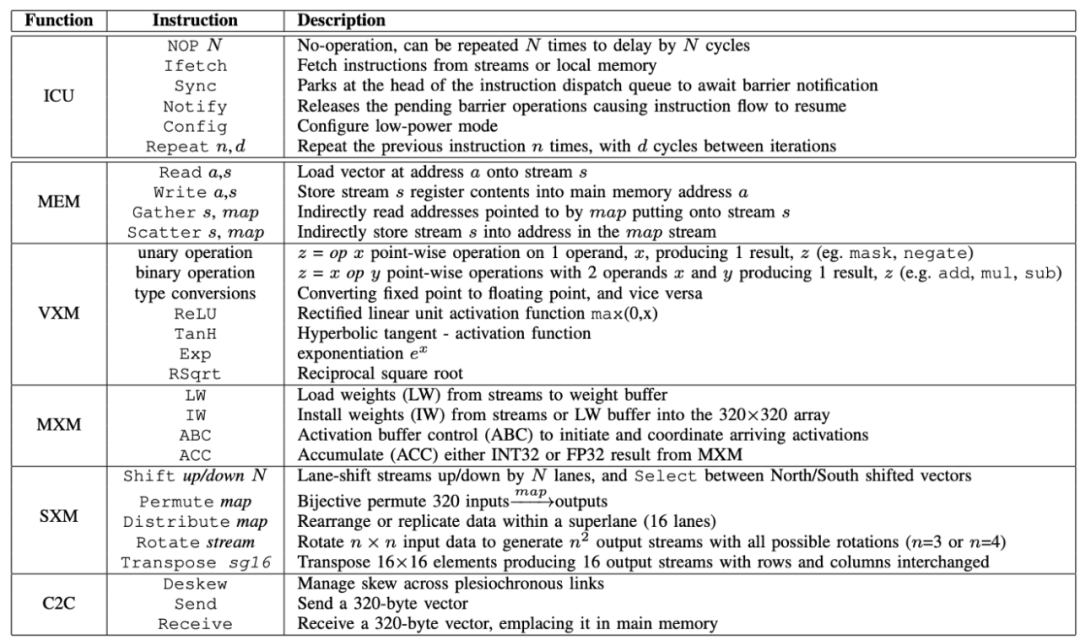
脉动阵列 + VLIW: TPUv1、Groq、Habana
世界上首个专门为 AI 量身定制的处理器之一是张量处理单元(TPU),也称张量处理器,是 Google 开发的专用集成电路(ASIC),专门用于加速机器学习。自 2015 年起,谷歌就已经开始在内部使用 TPU,并于 2018 年将 TPU 提供给第三方使用,既将部分 TPU 作为其云基础架构的一部分,也将部分小型版本的 TPU 用于销售。
![]()
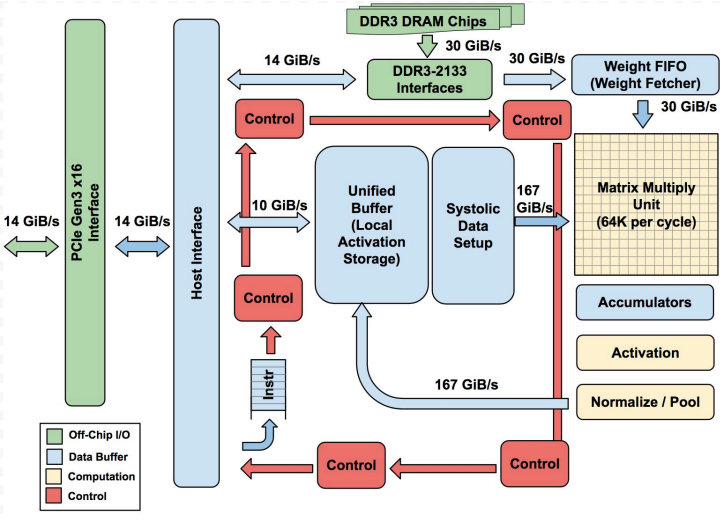
第一代 TPU 是一个 8 位矩阵乘法的引擎,使用复杂指令集,并由主机通过 PCIe 3.0 总线驱动,它采用 28 nm 工艺制造。TPU 的指令向主机进行数据的收发,执行矩阵乘法和卷积运算,并应用激活函数。
第二代 TPU 于 2017 年 5 月发布,值得注意的是,第一代 TPU 只能进行整数运算,但第二代 TPU 还可以进行浮点运算。这使得第二代 TPU 对于机器学习模型的训练和推理都非常有用。谷歌表示,这些第二代 TPU 将可在 Google 计算引擎上使用,以用于 TensorFlow 应用程序中。
第三代 TPU 于 2018 年 5 月 8 日发布,谷歌宣布第三代 TPU 的性能是第二代的两倍,并将部署在芯片数量是上一代的四倍的 Pod 中。
第四代 TPU 于 2021 年 5 月 19 日发布。谷歌宣布第四代 TPU 的性能是第三代的 2.7 倍,并将部署在芯片数量是上一代的两倍的 Pod 中。与部署的第三代 TPU 相比,这使每个 Pod 的性能提高了 5.4 倍(每个 Pod 中最多装有 4,096 个芯片)。
谷歌在云产品中提供了 TPU,他们的目标是满足谷歌的 AI 需求并服务于自己的内部工作负载。因此,谷歌针对特定需求量身定制了 TPU。
2016 年,一个由 TPU 架构师组成的团队离开谷歌,他们设计了一种与 TPU 具有相似基线特征的新处理器,并在一家名为 Groq 的新创业公司中将其商业化。
![]()
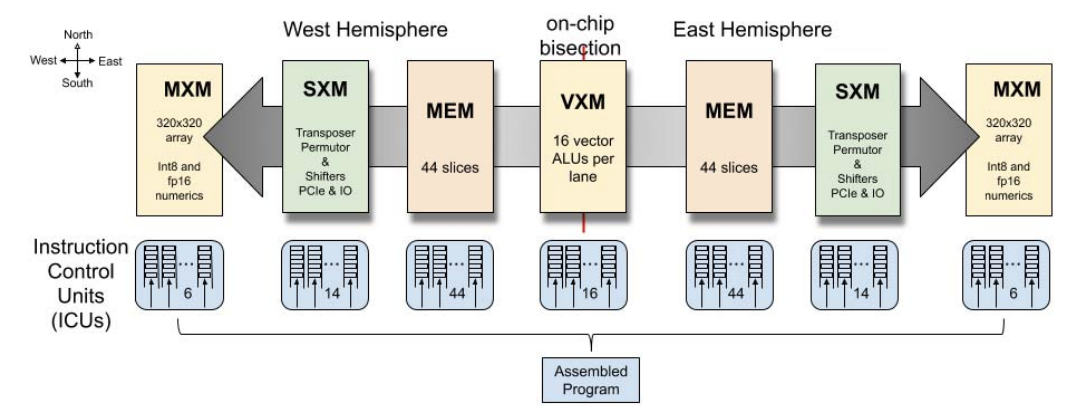
Groq 的核心是张量流处理器(TSP)。TSP 架构与 TPU 有很多共同之处:两种架构都严重依赖脉动阵列来完成繁重的工作。与第一代 TPU 相比,TSP 增加了向量单元和转置置换单元(在第二代和第三代 TPU 上也可以找到)。
![]()
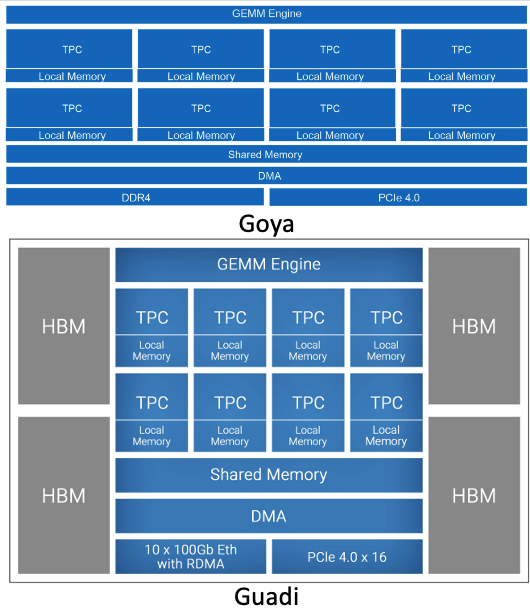
Habana 成立于 2016 年初,是一家专注于数据中心训练和推理的 AI 加速器公司。Habana 已推出云端 AI 训练芯片 Gaudi 和云端 AI 推理芯片 Goya。
Goya 处理器已实现商用,在极具竞争力的包络功率中具有超大吞吐量和超低的实时延迟,展现出卓越的推理性能。Gaudi 处理器旨在让系统实现高效灵活的横向、纵向扩展。目前 Habana 正在为特定超大规模客户提供样品。
![]()
![]()
Goya、 Gaudi 架构图。图注:Habana
Goya 和 Gaudi 芯片具有相似架构,它们都依赖于 GEMM 引擎,该引擎是一个脉动矩阵乘法单元,与一组 tile 并排工作。每个 tile 包含一个本地软件控制的暂存器内存和一个张量处理核心(TPC),具有不同精度的矢量计算单元,即它们可以计算 8 位、16 位或 32 位的矢量化操作。TPC 和 GEMM 引擎通过 DMA 和共享内存空间进行通信,并通过 PCIe 与主机处理器进行通信。
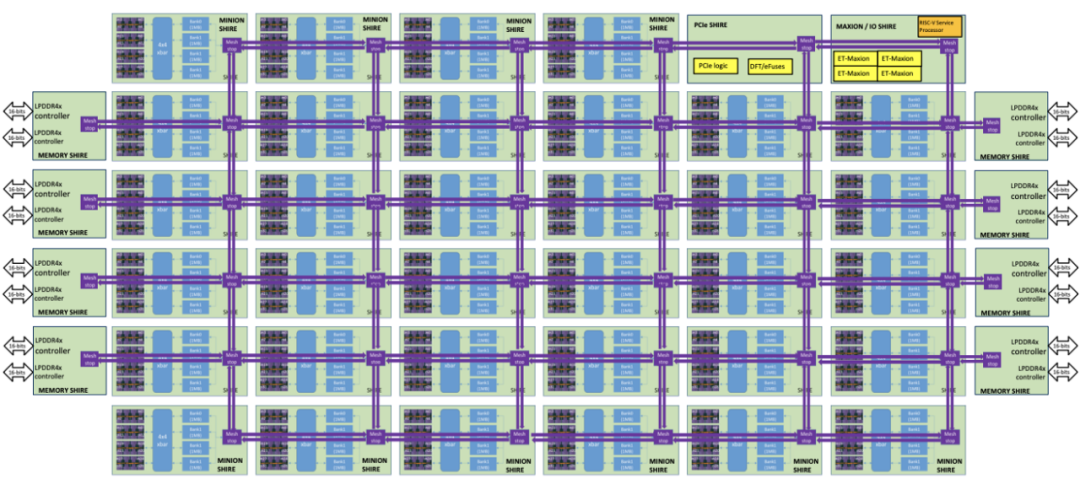
Esperanto 成立于 2014 年,并在相当长一段时间内一直处于隐身模式,直到 2020 年底才宣布他们的第一款产品 ET-SoC-1 芯片,其基于台积电 7nm 工艺构建的 SoC 上集成了 1000 多个 RISC-V 内核、160M BYTE 的 SRAM 和超过 240 亿个晶体管,是该公司 AI 加速器系列的第一款产品。ET-SoC-1 是一款推理加速器,预计在今年投产。
![]()
Esperanto 的 ET-SoC-1 的架构图。图源:Esperanto/HotChips
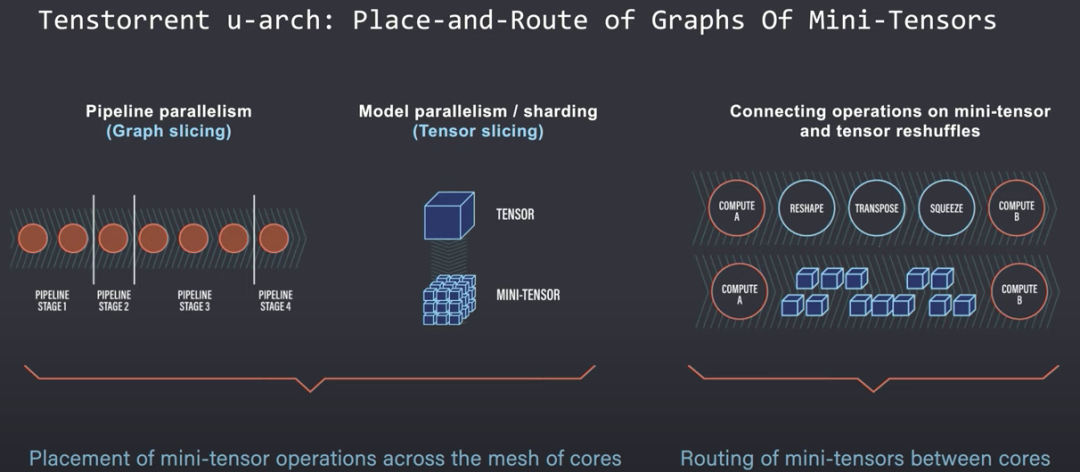
TensTorrent 成立于 2016 年,总部位于加拿大多伦多,目前估值 10 亿美元,这是一家计算公司,开发旨在帮助更快和适应未来算法的处理器。TensTorrent 提供的芯片系列不仅针对数据中心,也针对小型平台,此外,他们还提供 DevCloud。
![]()
TensTorrent:图的并行性与张量切片。图源:YouTube/TensTorrent
![]()
TensTorrent 核心。图源:YouTube/TensTorrent
Mythic 是 AI 硬件领域最早的初创公司之一,它成立于 2012 年。迈克・亨利(Mike Henry)和戴夫・菲克(Dave Fick)为公司的核心创始人,他们分别担任 Mythic 公司的董事长和 CTO。该公司非常重视具备能源效率和成本更低的模拟技术,Mythic 提出了如何在模拟电路中使用较小的非数字电路电流来降低能量的消耗。
![]()
矩阵乘法运算中的权重和输入 / 输出数据差分。图源:Mythic
2020 年底,Mythic 推出了其第一代 AI 芯片 M1108 AMP。与很多 AI 芯片不同,M1108 基于更加成熟的模拟计算技术,而非数字计算。这提高了 M1108 的能效,也使网络边缘设备访问更加容易。
Mythic 还推出了一个模拟计算引擎 (ACE,Analog Compute Engine),它使用闪存而不是 DRAM 来存储权重。本质上,它们不是从内存中获取输入和权重数据,而是将输入数据传输到权重闪存,并将其转换为模拟域,在模拟域中执行 MAC (multiply-and-accumulate)计算,并将其转换回以获取输出数据,从而避免从内存中读取和传输权重成本。
LightMatter 是一家诞生于 MIT 的初创公司,该公司押注于一种用光子而非电子执行运算的计算机芯片。这种芯片从根本上与传统的计算机芯片相区分,有望成为能够满足 AI「饥饿」的有力竞争者。LightMatter 首席执行官尼克・哈里斯(Nick Harris)曾说:「要么我们发明的新计算机继续下去,要么人工智能放慢速度。」
![]()
光子学与电子学计算属性。图源:HotChips/LightMatter
LightMatter 设计了一种基于脉动阵列的方法,通过使用编码为光信号波中不同相位的相移来操纵光子输入信号,以执行乘法和累加操作。由于光子学数据以光速流动,LightMatter 芯片以非常高的速度执行矩阵和矢量化运算,并且功率可降低几个数量级。
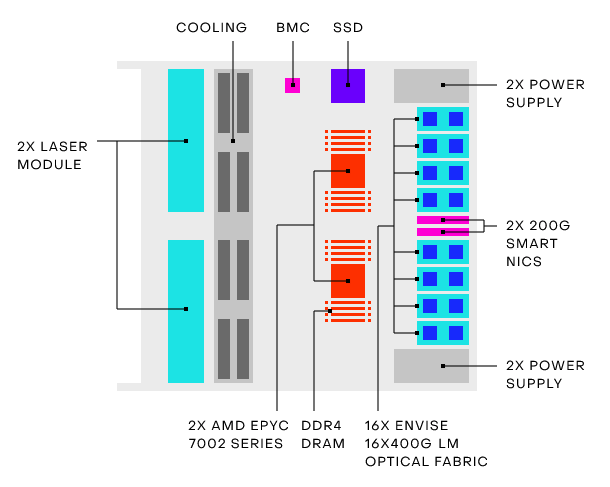
LightMatter 在 2021 年开始发售其首款基于光子的 AI 芯片 ——Envise,并为常规数据中心提供包含 16 个这种芯片的刀锋服务器。该公司目前已从 GV(前 Google Ventures)、Spark Capital 和 Matrix Partners 筹集到了 2200 万美元。
LightMatter 声称,他们推出的 Envise 芯片的运行速度比最先进的 Nvidia A100 AI 芯片快 1.5 至 10 倍,具体根据任务的不同有所差异。以运行 BERT 自然语言模型为例,Envise 的速度是英伟达芯片的 5 倍,并且仅消耗了其六分之一的功率。
![]()
NeuReality 是一家于 2019 年在以色列成立的初创公司,由 Tanach 、 Tzvika Shmueli 和 Yossi Kasus 共同创立。
2021 年 2 月,NeuReality 推出了 NR1-P,这是一个以 AI 为中心的推理平台。2021 年 11 月,NeuReality 宣布与 IBM 建立合作伙伴关系,其中包括许可 IBM 的低精度 AI 内核来构建 NR1,这是一种非原型生产级服务器,与 FPGA 原型相比, AI 应用程序效率更高。
![]()
NeuReality NR1-P 原型。图源:ZDNet
原文链接:https://medium.com/@adi.fu7/ai-accelerators-part-iv-the-very-rich-landscape-17481be80917
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com