作者:Adi Fuchs
机器之心编译
机器之心编辑部
在上一篇文章中,前苹果工程师、普林斯顿大学博士 Adi Fuchs 解释了为什么现在是 AI 加速器的黄金时代。在这篇文章中,我们将聚焦 AI 加速器的秘密基石——指令集架构 ISA、可重构处理器等。
![]()
这是本系列博客的第三篇,我们来到了整个系列的架构基础部分。
在这一章节中,Adi Fuchs 为我们介绍了 AI 加速器的架构基础,包括指令集架构 ISA、特定领域的 ISA、超长指令字 (VLIW) 架构、脉动阵列、可重构处理器、数据流操作、内存处理。
ISA 描述了指令和操作如何由编译器编码,然后由处理器解码和执行,它是处理器架构中面向程序员的部分。常见的例子是 Intel 的 x86、ARM、IBM Power、MIPS 和 RISC-V。我们可以将 ISA 视为处理器支持所有操作的词汇表。通常,它由算术指令(如加、乘)、内存操作(加载、存储)和控制操作(例如,在 if 语句中使用的分支)组成。
![]()
目前看来,CPU ISA 已被分类为精简指令集计算 (RISC) 和复杂指令集计算 (CISC):
通常,CISC 程序比其等效的 RISC 程序代码占用空间更小,即存储程序指令所需的内存量。这是因为单个 CISC 指令可以跨越多个 RISC 指令,并且可变长度的 CISC 指令被编码为使得最少的位数代表最常见的指令。然而,为了体现复杂指令带来的优势,编译器需要做的足够复杂才能实现。
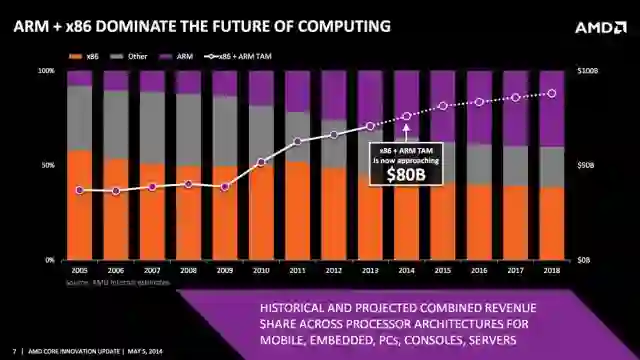
![]()
x86(橙色)相对于 ARM(紫色)的计算市场递减率预测。图源:AMD/ExtremeTech
早在 1980 年、1990 年和 2000 年代初期,就有「RISC 与 CISC 之战」,基于 x86 的 Intel 和 AMD 主要专注于 CISC ,而 ARM 专注于 RISC。其实每种方法都有利弊,但最终,由于基于 ARM 的智能手机的蓬勃发展,RISC 在移动设备中占据了上风。现在,随着亚马逊基于 ARM 的 AWS Graviton 处理器等的发布,RISC 在云中也开始占据主导地位。
值得注意的是,RISC 和 CISC 都是用于构建通用处理器的通用指令集架构。但在加速器的背景下, CISC 与 RISC 相比, RISC 具有简单性和简洁性,更受欢迎(至少对于智能手机而言)。
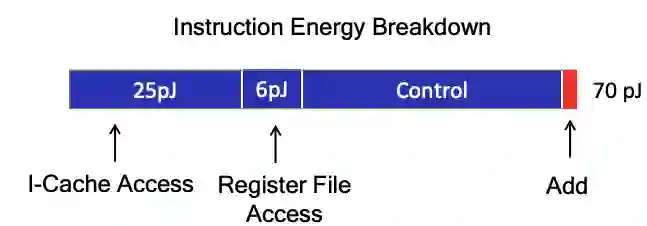
![]()
45nm CMOS 处理器中执行 ADD 指令能耗。图源:M.Horowitz ISSCC 2014
很多 AI 加速器公司采用特定领域的 ISA。鉴于现有的精简指令集架构(以及潜在的处理核心),可以通过仅支持目标应用领域所需的指令子集来进一步减少它。特定领域的 ISA 进一步简化了处理内核和硬件 / 软件接口,以实现高效的加速器设计。在通常由线性代数和非线性激活组成的 AI 应用中,不需要许多「奇异」类型的运算。因此,ISA 可以设计为支持相对较窄的操作范围。
使用现有 RISC ISA 的简化版本的好处是,一些 RISC 公司(如 ARM )出售现有 IP,即支持完整 ISA 的现有处理内核,可用作定制处理的基线,用于加速器芯片的核心。这样,加速器供应商就可以依赖已经过验证并可能部署在其他系统中的基线设计;这是从头开始设计新架构更可靠的替代方案,对于工程资源有限、希望获得现有处理生态系统支持或希望缩短启动时间的初创公司尤其有吸引力。
VLIW 架构是由 Josh Fisher 在 20 世纪 80 年代早期提出,当时集成电路制造技术和高级语言编译器技术出现了巨大的进步。其主要思想是:
就像特定领域的 ISA 可以被认为是 RISC 思想(更简单的指令,支持的操作较少)的扩展,同样地,我们可以将 CISC 进行多个操作组合成单个复杂指令扩展,这些架构被称为超长指令字 (VLIW)。
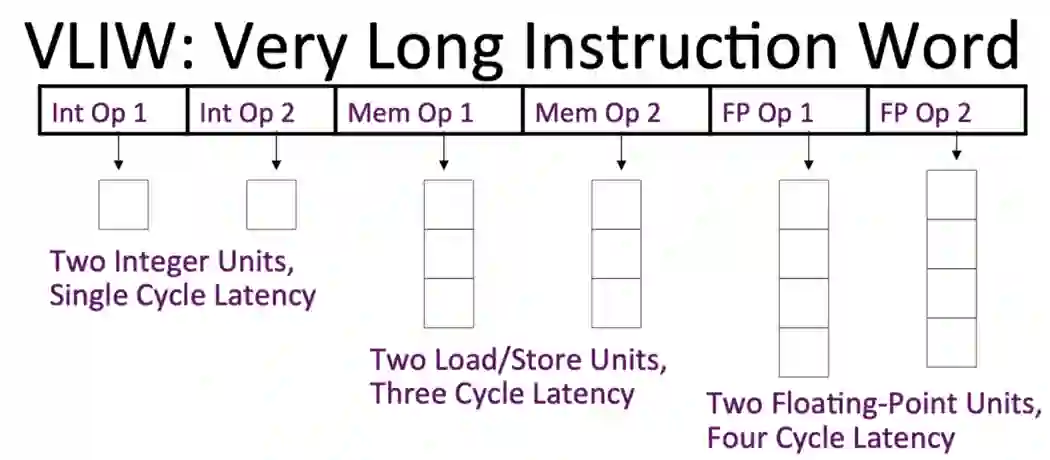
VLIW 架构由算术和存储单元的异构数据路径阵列组成。异构性源于每个单元的时序和支持功能的差异:例如,计算简单逻辑操作数的结果可能需要 1-2 个周期,而内存操作数可能需要数百个周期。
![]()
一个简单的 VLIW 数据路径框图。图源:普林斯顿大学
VLIW 架构依赖于一个编译器,该编译器将多个操作组合成一个单一且复杂的指令,该指令将数据分派到数据路径阵列中的单元。例如,在 AI 加速器中,这种指令可以将张量指向矩阵乘法单元,并且并行地将数据部分发送到向量单元和转置单元等等。
VLIW 架构的优势在于,通过指令编排处理器数据路径的成本可能显着降低;缺点是我们需要保证数据路径中各个单元之间的工作负载得到平衡,以避免资源未得到充分利用。因此,要实现高性能执行,编译器需要能够进行复杂的静态调度。更具体地说,编译器需要分析程序,将数据分配给单元,知道如何对不同的数据路径资源计时,并以在给定时间利用最多单元的方式将代码分解为单个指令。归根结底,编译器需要了解不同的数据路径结构及其时序,并解决计算复杂的问题,以提取高指令级并行 (ILP) 并实现高性能执行。
脉动阵列由 H. T. Kung 和 C. E. Leiserson 于 1978 年引入。2017 年,Google 研发的 TPU 采用脉动阵列作为计算核心结构,使其又一次火了起来。
脉动阵列本身的核心概念就是让数据在运算单元的阵列中进行流动,减少访存次数,并且使得结构更加规整,布线更加统一,提高频率。整个阵列以「节拍」方式运行,每个 PE (processing elements)在每个计算周期处理一部分数据,并将其传达给下一个互连的 PE。
![]()
脉动结构是执行矩阵乘法的有效方式(DNN 工作负载具有丰富的矩阵乘法)。谷歌的 TPU 是第一个使用 AI 的脉动阵列。因此,在这之后,其他公司也加入了脉动阵列行列,在自家加速硬件中集成了脉动执行单元,例如 NVIDIA 的 Tensor Core。
我们所熟悉的处理器包括 CPU、GPU 和一些加速器,它们的流程依赖于预先确定数量的算术单元和运行时行为,这些行为是在运行时根据执行的程序指令确定的。但是,还有其他类别的处理器称为「可重构处理器」。
![]()
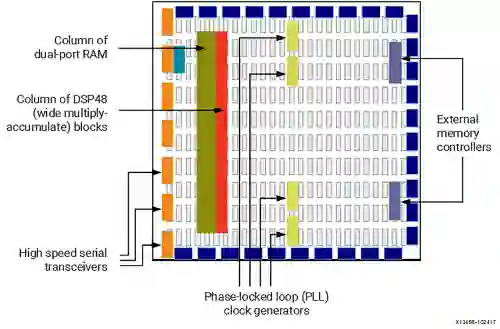
可重构处理器由包含互连计算单元、内存单元和控制平面的复制阵列组成。为了运行程序,专用编译器会构建一个配置文件,这个文件包含设置数组中每个元素行为的控制位。最常见的可重构处理器类别是现场可编程门阵列 (FPGA)。
FPGA 通过启用位级可配置性来支持广泛的计算范围:可以配置算术单元来实现对任意宽度数量进行操作的功能,并且可以融合片上存储块以构建不同大小的存储空间。
可重构处理器的一个优点是它们可以对用硬件描述语言 (HDL) 编写的芯片设计进行建模;这使公司能够在几个小时内测试他们的设计,而不是流片芯片,这个过程可能需要几个月甚至几年的时间。FPGA 的缺点是细粒度的位级可配置性效率低下,典型的编译时间可能需要数小时,并且所需的额外线路数量占用大量空间,而且在能量上也是浪费。因此,FPGA 通常用于在流片之前对设计进行原型设计,因为由此产生的芯片将比其 FPGA 同类产品性能更高、效率更高。
![]()
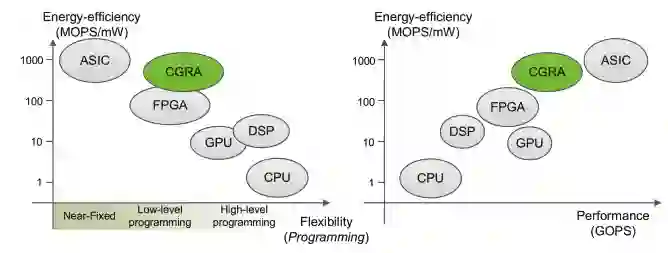
处理器架构的性能、功耗和灵活性的比较。图源:ACM Computing Surveys
虽然 FPGA 在性能和功耗方面存在问题,但可重构性仍然是 AI 加速器一个非常理想的特性。一般来说,一个芯片的设计周期大约是 2-3 年,每天会有数不清的实验依赖芯片运行。但是,一个近期制造完成并花费数百万美元的芯片,往往是基于两年多前存在的 AI 模型的假设设计的,可能与当前的模型无关。
为了将高效、性能和可重构性结合起来,一些初创公司设计了可重构处理器,它们被称为 CGRA(Coarse-Grained Reconfigurable Arrays)。
CGRA 在 1996 年被提出,与 FPGA 相比,CGRA 不支持位级可配置性,并且通常具有更严格的结构和互连网络。CGRA 具有高度的可重构性,但粒度比 FPGA 更粗。
数据流(Dataflow)已经有一段时间了,起源可以追溯到 1970 年代。不同于传统的冯诺依曼模型,它们是计算的另一种形式。
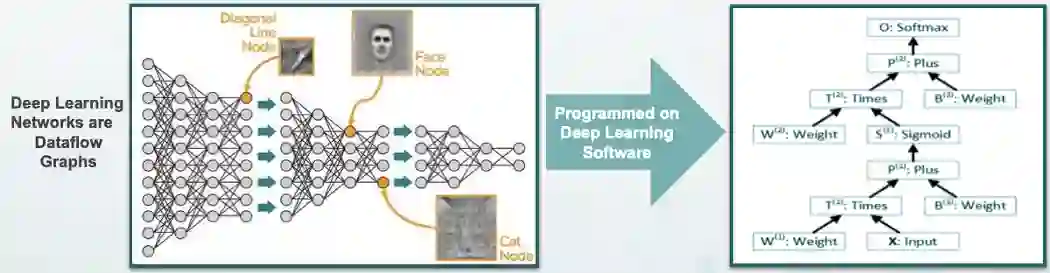
在传统的冯诺依曼模型中,程序被表示为一系列指令和临时变量。但在数据流模型中,程序被表示为数据流图(DFG,dataflow graph),其中输入数据的一部分是使用预定的操作数(predetermined operands)计算的,计算机中的数据根据所表示的图一直「流动」到输出,这一过程由类似图形的硬件计算而来。值得注意的是,硬件本质上是并行的。
![]()
深度学习软件到数据流图映射的例子。图源:Wave Computing — HotChips 2017
在 AI 加速器的背景下,执行数据流有以下两个优势:
深度学习应用程序是结构性的,因此有一个由应用程序层的层级结构决定的计算图。所以,数据流图已经被放入代码中。相比之下,冯诺依曼应用程序首先被序列化为一系列指令,这些指令随后需要(重新)并行化以提供给处理器;
数据流图是计算问题的架构不可知(architecturally-agnostic)表示。它抽象出所有源于架构本身的不必要的约束(例如,指令集支持的寄存器或操作数等),并且程序的并行性仅受计算问题本身的固有并行维度的限制,而不是受计算问题本身的并行维度限制。
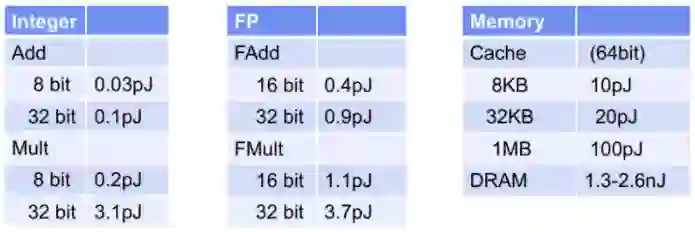
研究人员在提高加速器的计算吞吐量 (FLOP) 上花费了大量精力,即芯片(或系统)每秒提供的最大计算数量。然而,片上计算吞吐量并不是全部,还有内存宽带,因其片上计算速度超过片外内存传输数据的速度,造成性能瓶颈。此外,从能量角度来看, AI 模型中存在着很高的内存访问成本,将数据移入和移出主存储器比进行实际计算的成本高几个数量级。
![]()
45nm CMOS 技术的典型内存和计算成本。图源:ISSCC 2014 / M.Horowitz
AI 加速器公司为降低内存成本常采用「近数据处理,near-data processing」方法。这些公司设计了小型且高效的软件控制存储器(也称为便笺存储器,Scratchpad Memory),它们将处理过的部分数据存储在核心芯片上,用于高速和低功耗并行处理。通过减少对片外存储器(大而远存储器)的访问次数,这种方法在减少访问数据时间和能源成本方面迈出了第一步。
近数据处理的极端是 PIM(Processing-in-Memory),这种技术可以追溯到 1970 年代。在 PIM 系统中,主内存模块是用数字逻辑元件(如加法器或乘法器)制造的,计算处理位于内存内部。因此,不需要将存储的数据传送到中间线缓冲器。商业化的 PIM 解决方案仍然不是很常见,因为制造技术和方法仍然稳定,而且设计通常被认为是僵化的。
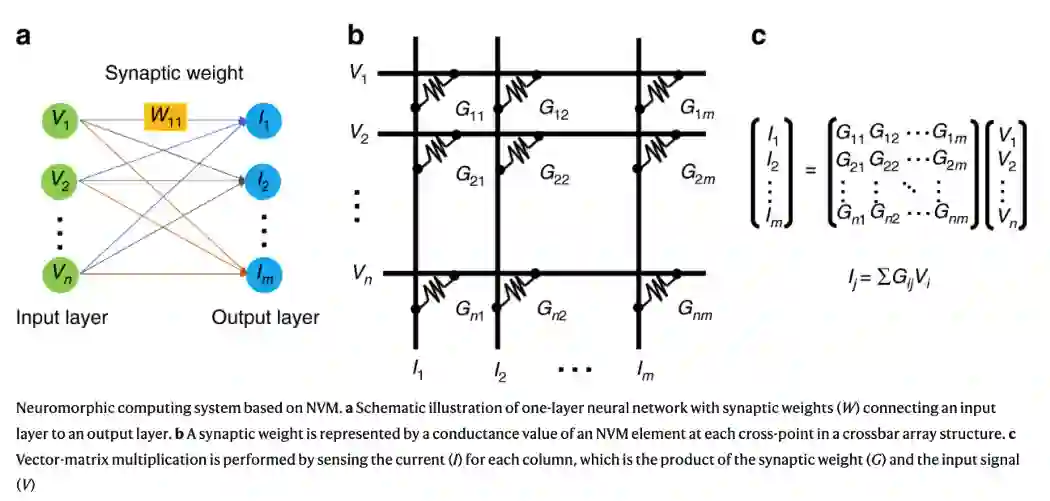
![]()
基于点积模拟处理的神经形态计算。图源:Nature Communications
许多 PIM 依赖于模拟计算(analog computations)。具体来说,在 AI 应用中,加权点积在模拟域中的计算方式类似于大脑处理信号的方式,这就是为什么这种做法通常也被称为「神经形态计算」的原因。由于计算是在模拟域中完成的,但输入和输出数据是数字的,神经形态解决方案需要特殊的模数和数模转换器,但这些在面积和功率上的成本都很高。
原文链接:https://medium.com/@adi.fu7/ai-accelerators-part-iii-architectural-foundations-3f1f73d61f1f
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com