【干货】神经机器翻译全流程解析,one-shot 和 zero-shot 学习成亮点
新智元编译
来源:微信AI 授权转载
作者:白明
【新智元导读】从统计机器翻译到神经机器翻译,以及谷歌采用的最先进的 one-shot 和zero-shot 的方式,作者阐述了机器翻译这个特定任务的全流程,并提出思考: NMT 是否可以扩展到如基因序列、社交网络等其他基于建立联系的任务上?

曾经有人好奇,是否自然地认为翻译问题应该是一种密码学问题。被誉为机器翻译之父的Warren Weaver,曾说过:“This is really written in English, but it has been coded in some strange symbols. I will now proceed to decode. ”。希望计算机能够应付翻译问题,理论基础之一是 McCulloch 和 Pitts 于 1943 年证明的定理。定理说明,用某种形式的再生回路构建的机器程序,能够从有限的前提中推断出任何合法的结论。
神经机器翻译(NMT)是近些年基于纯的神经网络(NN)提出的一种机器翻译框架。首先参考文献 [Cho et al., 2014; Sutskever et al.,2014; Kalchbrenner and Blunsom, 2013] 等,解释最基本的 encoder-decoder 模型。在 2015 年 Bahdanau et al. 把 attention 机制集成到基本的 encoder-decoder 模型中,当时在很多语言(en-fr, en-de, en-tr, en-zh)上得到 state-of-the-art 的机器翻译结果 [Gulcehre et al.,2015; Jean et al., 2015]。同时,上述机器翻译的技术框架也成功应用到图像和视频描述产生上 [Xu et al., 2015;Li et al., 2015]。
首先简述一下基础知识,如果让机器把 A 语言的文本翻译成 B 语言的话,那么称 A 语言为源语言,B 语言为目标语言。不失一般性,本文都以句子翻译为例。机器翻译发展了 20 多年,有多种技术框架,例如:让即懂源语言又懂目标语言的人给出一些规则,显然这不是一种好方法,因为总结出一种语言的通用规则都不是易事。随后,用统计方法尝试从大量语料中显示地或隐式地“提取”这些规则。这些统计方法被统称为统计机器翻译。
简单来说,统计机器翻译就是找一个函数,把源语言映射到目标语言,如下图所示:

机器翻译的重要特性之一是目标函数,不是机器学习的常用应用中的一对一或多对一(例如分类是多对一),而是一对多,即源语言一句可能有目标语言正确的多句对应。所以,我们用条件概率 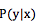
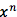
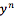
有了训练数据之后,怎么评价模型的好坏呢?最直观的想法是把每个样本在模型上的 log-likelihood 进行平均来量化。样本的 log-likelihood 是反应模型认为样本的 log-probability(记为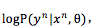
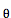
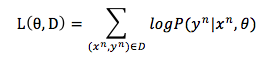
如果 log-likelihood 较小,说明当前模型对正确结果给出的概率较小。所以我们希望找到更好的
在20多年前,IBM Watson 研究中心采用 log-linear 模型的方法,建模条件概率 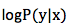
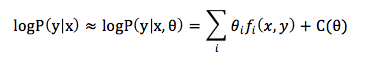
其中,C 是正则化常量。从而一批论文的贡献集中在寻找好的特征函数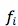
在统计机器翻译框架下,机器学习主要是为了平衡不同的特征来找到一组参数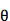
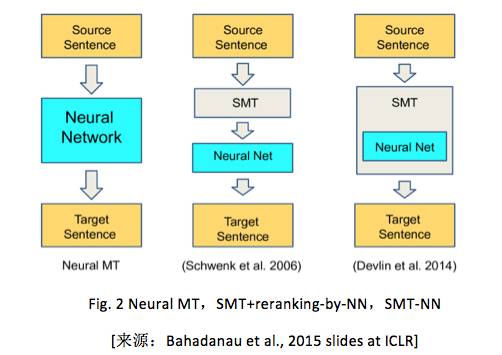
近些年,NMT 不再依赖预先设计的特征函数。然而,NMT 的目标是设计一个能通过语料可训练的模型(记为 M )。它始于源语言的表达,终于目标语言的表达。
虽然,以 word 作为最小单元,对于自然语言来说可能不够客观,但是,对于基本原理解释,却不失一般性地,用字典中的 index 表示一句话中的每个 word 。设 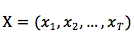
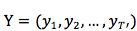
对于NLP的任务有个特点,输入和输出的序列长度 T 或 T’ 都不是固定的。目前大多数算法用 RNN 来解决此问题。广泛使用的前馈 NN ,例如 CNN ,不能保持内部状态,因为当一个 sample 进入前馈 NN 后,网络内部状态或隐层单元的激活都从头计算,不受先前 sample 计算的状态影响。然而,RNN 保留了 word 序列输入的内部状态。假设在 t 步,RNN 依赖之前的积累 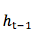
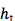
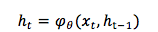
[Pascanu et al.,2014] 阐述了几种 RNN 类型,框架如下图:
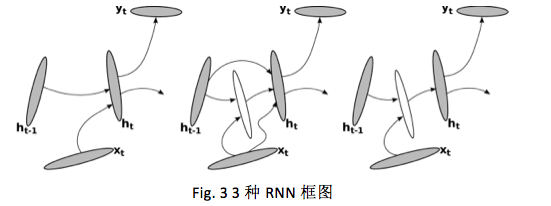
其中 RNN 中的激活函数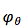
其实,在创新此公式 :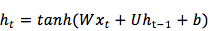
言归正传,用上述 RNN 建模机器翻译中的序列概率问题,需要把问题转成 recurrent 形式:
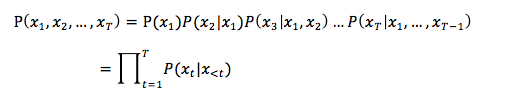
所以 t 时刻的 RNN 模型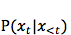
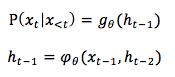
试想一下,我们大脑是怎样把 “ I love you ” 翻译成”我爱你“的呢?一种思路是,翻译过程包括2个过程:一个 encoder 和一个 decoder ,前者把一序列的 words 转换成一系列的神经激活,后者从激活中得到目标语言的序列。在 2013 年 Kalchbrenner and Blunsom 在 Oxford 开始采用此框架,随后著名的工作有 Sutskever et al., 2014; Cho et al., 2014; Bahdanau et al., 2015 等。此框架本身不对 encoder 和 decoder 的模型做任何限制,只是大多数论文都用 RNN 表示。下图是一个 NMT 的总体框图:
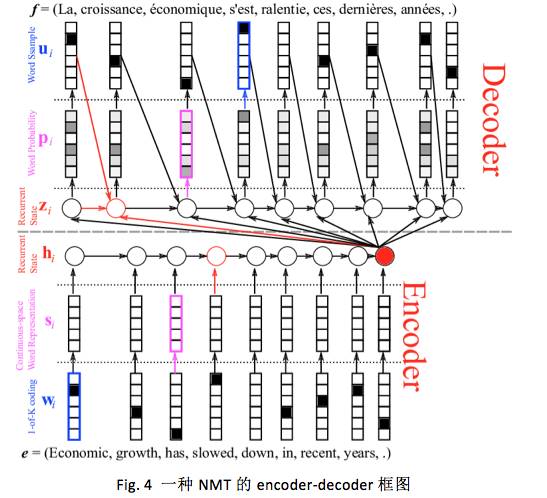
首先,encoder 过程按照 Fig. 4 中可分为 3 步:
1. 把一个 word 表示为 one-hot 向量;
2. one-hot 向量转化成连续空间表达(例如,word2vec);
3. 由 RNN 网络 summarize 成一个序列;
句子中,每个 word 表示成 one-hot 向量或 1-of-K 编码向量,这种表达让 words 之间失去 relation 信息,是一种最简单的表示。encoder 通过矩阵 E 把每个 word 线性映射成一个连续向量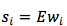
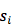
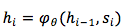
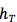
为了衡量此 summary 信息到底长啥样,Sutskever et al. 2014做了个实验,通过 PCA 把多维向量映射成 2 维空间上,从而在下图能粗略地观察到原始空间中 summary 向量的相互“距离”。

图中我们可以看到 ,相似句子“距离”更近 ,上述 summary 向量一定程度保留了句子的语义(semantics)和句法结构(syntax)信息(请参见http://talks.cam.ac.uk/talk/index/58498)。
然后,decoder 按照 Fig. 4中可分为3步:
1. 计算内部状态向量 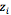
2. 计算下一 word 的概率;
3. 采样下一个 word ;
源语言句子的 summary 向量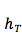
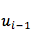
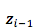
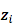
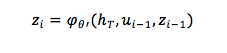
待 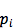
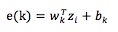
当目标 word 向量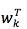
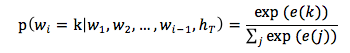
有了目标 word 的概率分布之后,就可以用多项式分布采样的方法选择一个 word 。
假设选择了第 i 个 word ,那么就又回到上述计算
经过上述过程,一个 NMT 模型有了。可是怎么训练它呢?和大多数机器学习模型一样,有多种方法训练。下面,我们只介绍在 encoder-decoder 框架下的最 log-likelihood 的基本方法。
首先,准备好平行训练语料,每个句子中的 word 用整数索引值代替,相当于 one-shot 向量。
然后,左乘矩阵(矩阵例如可用 word2vec 表示),得到矩阵的第 i 列( one-hot 中第 i 个元素是1 )。于是给定 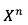
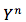
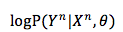
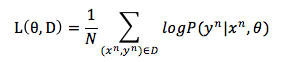
剩下,就是用类 SGD 的方法簇来最大化 log-likelihood 函数。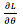
很多工程师“随便”调调初始学习率,mini-batch 大小,学习率自变化方案,动量因子及其自动变化方案等就认为很“牛逼“啦。这个话题不是本文的重点,故不展开描述。
目前来看,在机器翻译的模型中使用 Adadelta [Zeiler, 2012] 或 Adam [Kingma and Ba,2015] 得到的结果不会太差(可参考 http://imgur.com/a/Hqolp 在马鞍面上一点,采用不同学习率算法的收敛可视化的例子)
众所周知,深度学习算法绝大部分都用 GPU 计算,NMT 也不例外。我们还是粗略地计算一下,一个样本的 forward 过程的计算量(当然对于一条样本不会包含所有的 word ):
1.源语言 embedding :T×|V|,其中 T 是源句子的 word 个数,|V| 是源语言词表大小;
2. 从源语言 word 的 embedding 到 encoder: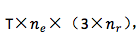
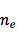
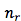
3. 从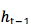
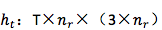
4. 从 context 向量到 decoder :
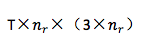
5. 从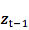
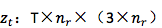
6. 从 decoder 到目标 word 的 embedding :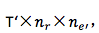
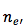
7. 从目标 word 的 embedding 到输出: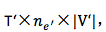
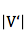
8. softmax 输出:
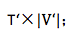
除了上述前向过程,还有同等量级的后向计算。上述中的 |V| 和 |V’| 通常是十万到百万量级,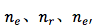
在基本的 encoder-decoder 框架,encoder 转换输入序列到固定长度的向量(即 contex 向量),decoder 有此产生翻译。直观上看,context 向量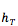
简单的框架不区分输入句子的长度(意指信息含量多少),这显然是违背直觉的。就连 zip 个文件的结果也与文件含有的信息复杂程度相关。
为了后续讨论简单,我们假设句子长度的大小与句子含有信息量成正比。于是想到不把句子表示成固定长度的向量,而是让它体现出“层次”信息,BiRNN 分别从 2 个方向独立地“读”句子一遍。
假设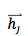
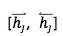
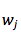
考虑了源语言句子的变长表示之后,decoder 对于每个目标 word 来说,也需要选择性地把注意力集中在一个或多个 context-dependent 词表达或辅助向量( annotation vector )上。可是每次应该怎么聚焦呢?想象一下,当人已经翻译了 i-1 个 word 后,正在翻译第 i 个 word ,人在翻译时是怎么决定的呢?通常,人在看每个词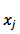
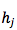
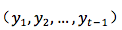
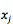
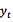
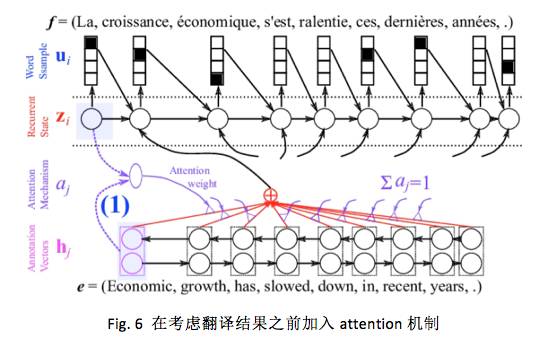
Dzmitry Bahdanau 2014 提出在 decoder 中引入一个 NN 来做上述的 attention model(记为 AM )。此 AM 的输入是前一时刻的 decoder 隐状态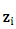
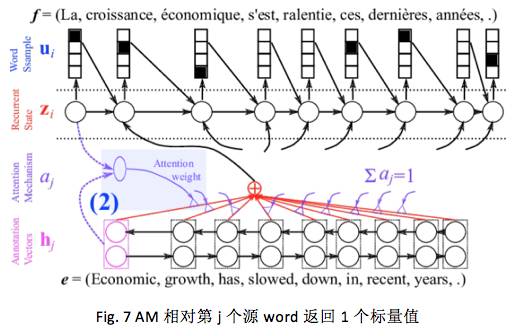
一旦得到每个源 word 的得分后,就可以用 softmax进行归一化:
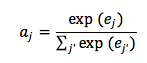
这里做归一化的原因有多种解释,其中一种解释是把 attention 机制纳入到概率论框架中,认为 attention 的权重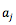
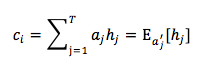
上述期望向量 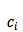
当前 attention mechanism 已经成了 deep learning 中的一个热点,不仅仅体现在 NLP 上 ,也体现在图像研究中 [Cho et al., 2015]。下图表示在没有特意地针对对齐做监督的情况下,模型自己学习到了某种 attention 或对齐的一个例子:

线条的粗细表示 AM 模型给出的 attention 权重大小。通常弱监督形势常被用来表示 reinforcement learning ,在此 attention 机制等同了弱监督效果,除了给定翻译的目标句子外,没有任何中间的对应和对齐的直接监督信息。
此外,再分别对比下 neural turing machine [Graves et al. 2014] 和 memory network [Weston et al. 2014]与带有 attention 机制的 NMT 。首先,假设把 context-dependent 词表达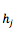
立刻会有人问,机器翻译与 image caption 有什么一毛钱关系吗?回想一下,现在的 NMT 技术路线在做翻译时不需要利用任何一种语言的特定信息,也就是说任何 2 种语言间的翻译在 NMT 来看是一样的。让我们发散一下,这种技术框架,对于需要返回输入数据的定长向量表达,或者寻求一系列它的映射空间下对应向量的需求,很可能是一种不错的选择,只要能把数据合适地灌进框架中。这已经被蒙特利尔大学和多伦多大学的 paper 证实了。论文中用 CNN 替换了 encoder ,在 attention-based encoder-decoder 框架下完成了 image caption 任务,如下图所示:
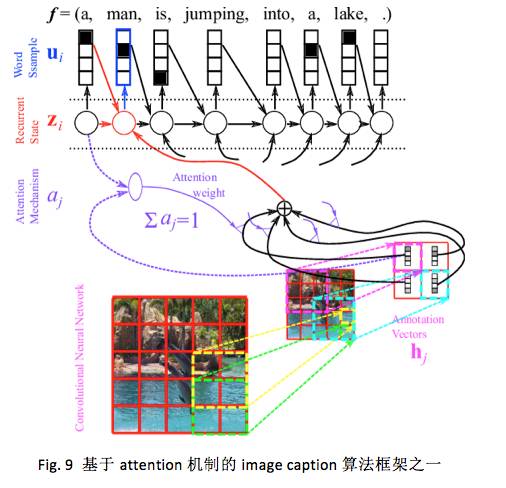
此外类似的 papers 还有 Donahue et al.,2014; Fang et al., 2014; Karpathy and Li, 2014; Kiros et al., 2014; Mao et al.,2014 等。
值得一提的是,让 decoder 利用 video 的时域结构, Li et al. 2015 和 Venugopalan et al. 2015 用类似的 attention-based 方法产生了 video 描述,如下图所示:

同理,attention 机制 + 从一种结构化的输入映射到另一种结构化的输出的框架已经成功应用到多种任务上。 Vinyals et al.2015 应用到离散优化问题上,解决了旅行商问题。Kyunghyun et al. 2015 应用此框架到更多的多媒体任务中。
关于机器翻译这个特定任务的全流程已经有很多研究者评论了,这里说的展望不特指任何一种 task 。
目前大多数还是以 word 为单一单元建模句子序列,是否应该考虑 hierarchical 单元。在 RNN 中的反向传播算法的时间代价与序列长度成正比。是否有更好的算法能处理更长的序列,例如段落,文档等。在处理序列时,大部分的学习很可能还是局部的,权重还是不加区别地在线更新的,是否可以改变这种传统形式。
NMT 考虑的是自然语言中的逻辑关系,它还可以扩展到以其他机制建立联系的任务上吗?例如:基因序列、社交网络等以 relation 维系的图结构。
虽然 google 已经用 one-shot 和 zero-shot 方式,但是我们还是要思考如何引入其他信息源来做 multimodal learning 。
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” arXiv preprint arXiv:1409.0473 (2014).
Bastien, Frédéric et al. “Theano: new features and speed improvements.” arXiv preprint arXiv:1211.5590 (2012).
Bergstra, James et al. “Theano: a CPU and GPU math expression compiler.” Proceedings of the Python for scientific computing conference (SciPy) 30 Jun. 2010: 3.
Bridle, J. S. (1990). Training Stochastic Model Recognition Algorithms as Networks can lead to Maximum Mutual Information Estimation of Parameters. In Touretzky, D., editor, Advances in Neural Information Processing Systems, volume 2, (Denver, 1989).
Brown, Peter F et al. “The mathematics of statistical machine translation: Parameter estimation.” Computational linguistics 19.2 (1993): 263-311.
Cho, Kyunghyun et al. “Learning phrase representations using RNN encoder-decoder for statistical machine translation.” arXiv preprint arXiv:1406.1078 (2014).
Cho, Kyunghyun, Aaron Courville, and Yoshua Bengio. “Describing Multimedia Content using Attention-based Encoder–Decoder Networks.” arXiv preprint arXiv:1507.01053 (2015).
Denil, Misha et al. “Learning where to attend with deep architectures for image tracking.” Neural computation 24.8 (2012): 2151-2184.
Donahue, Jeff et al. “Long-term recurrent convolutional networks for visual recognition and description.” arXiv preprint arXiv:1411.4389 (2014).
Fang, Hao et al. “From captions to visual concepts and back.” arXiv preprint arXiv:1411.4952 (2014).
Forcada, Mikel L, and Ñeco, Ramón P. “Recursive hetero-associative memories for translation.” Biological and Artificial Computation: From Neuroscience to Technology (1997): 453-462.
Graves, Alex, Greg Wayne, and Ivo Danihelka. “Neural Turing Machines.” arXiv preprint arXiv:1410.5401 (2014).
Graves, Alex, Greg Wayne, and Ivo Danihelka. “Neural Turing Machines.” arXiv preprint arXiv:1410.5401 (2014).
Gregor, Karol et al. “DRAW: A recurrent neural network for image generation.” arXiv preprint arXiv:1502.04623 (2015).
Gulcehre, Caglar et al. “On Using Monolingual Corpora in Neural Machine Translation.” arXiv preprint arXiv:1503.03535 (2015).
Kalchbrenner, Nal, and Phil Blunsom. “Recurrent Continuous Translation Models.” EMNLP 2013: 1700-1709.
Karpathy, Andrej, and Li, Fei-Fei. “Deep visual-semantic alignments for generating image descriptions.” arXiv preprint arXiv:1412.2306 (2014).
Kingma, D. P., and Ba, J. “A Method for Stochastic Optimization.” arXiv preprint arXiv:1412.6980 (2014).
Kiros, Ryan, Ruslan Salakhutdinov, and Richard S Zemel. “Unifying visual-semantic embeddings with multimodal neural language models.” arXiv preprint arXiv:1411.2539 (2014).
Koehn, Philipp. Statistical machine translation. Cambridge University Press, 2009.
Mao, Junhua et al. “Deep Captioning with Multimodal Recurrent Neural Networks (m-RNN).” arXiv preprint arXiv:1412.6632 (2014).
Mnih, Volodymyr, Nicolas Heess, and Alex Graves. “Recurrent models of visual attention.” Advances in Neural Information Processing Systems 2014: 2204-2212.
Pascanu, Razvan et al. “How to construct deep recurrent neural networks.” arXiv preprint arXiv:1312.6026 (2013).
Schwenk, Holger. “Continuous space language models.” Computer Speech & Language 21.3 (2007): 492-518.
Sukhbaatar, Sainbayar et al. “End-To-End Memory Networks.”
Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. “Sequence to sequence learning with neural networks.” Advances in Neural Information Processing Systems 2014: 3104-3112.
Venugopalan, Subhashini et al. “Sequence to Sequence–Video to Text.” arXiv preprint arXiv:1505.00487 (2015).
Weston, Jason, Sumit Chopra, and Antoine Bordes. “Memory networks.” arXiv preprint arXiv:1410.3916 (2014).
Xu, Kelvin et al. “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.” arXiv preprint arXiv:1502.03044 (2015).
Yao, Li et al. “Video description generation incorporating spatio-temporal features and a soft-attention mechanism.” arXiv preprint arXiv:1502.08029 (2015).
(本文来源微信AI,经作者白明授权转载,特此感谢!)


3月27日,新智元开源·生态AI技术峰会暨新智元2017创业大赛颁奖盛典隆重召开,包括“BAT”在内的中国主流 AI 公司、600多名行业精英齐聚,共同为2017中国人工智能的发展画上了浓墨重彩的一笔。
文字实录:新智元“春节”引爆AI原力,群星纵论中国AI大棋局
访问以下链接,回顾大会盛况:



