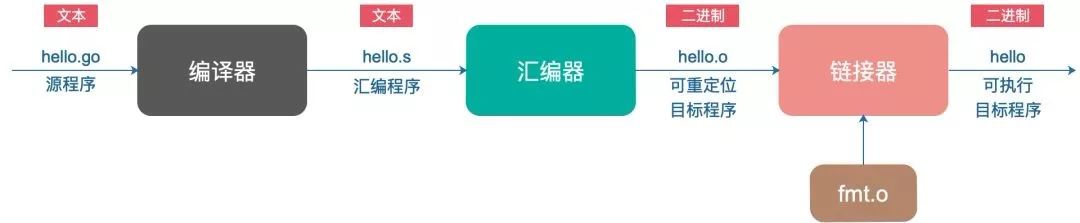
万字长文详解 Go 程序是怎样跑起来的?| CSDN 博文精选




package main
import "fmt"
func main() {
fmt.Println("hello world")
}:%!xxd

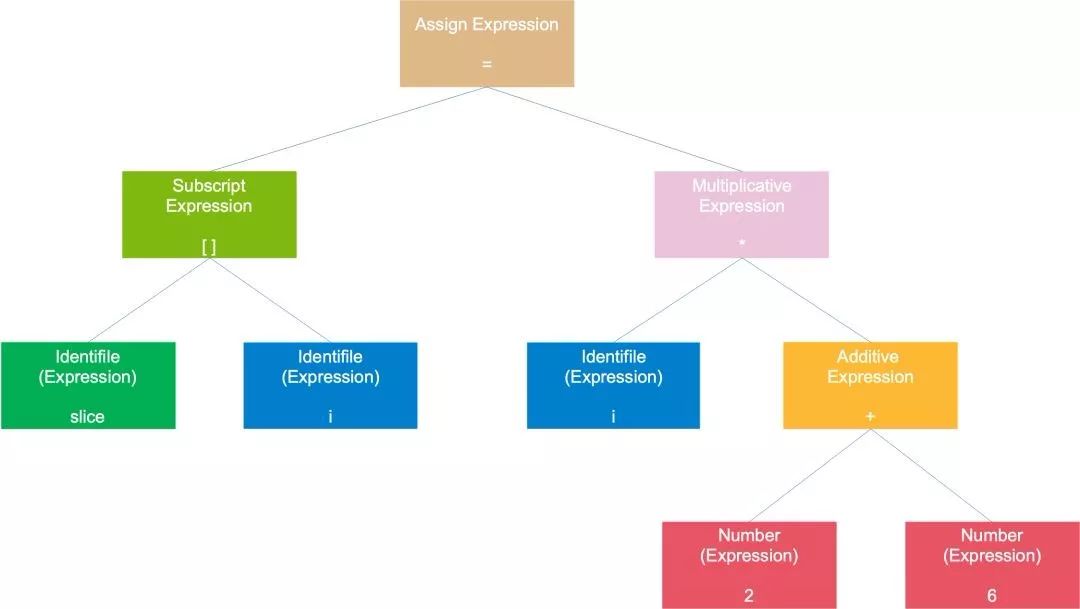
slice[i] = i * (2 + 6)| 记号 | 类型 |
|---|---|
| slice | 标识符 |
| [ | 左方括号 |
| i | 标识符 |
| ] | 右方括号 |
| = | 赋值 |
| i | 标识符 |
| * | 乘号 |
| ( | 左圆括号 |
| 2 | 数字 |
| + | 加号 |
| 6 | 数字 |
| ) | 右圆括号 |
src/cmd/compile/internal/syntax/token.go
var tokstrings = [...]string{
// source control
_EOF: "EOF",
// names and literals
_Name: "name",
_Literal: "literal",
// operators and operations
_Operator: "op",
_AssignOp: "op=",
_IncOp: "opop",
_Assign: "=",
_Define: ":=",
_Arrow: "<-",
_Star: "*",
// delimitors
_Lparen: "(",
_Lbrack: "[",
_Lbrace: "{",
_Rparen: ")",
_Rbrack: "]",
_Rbrace: "}",
_Comma: ",",
_Semi: ";",
_Colon: ":",
_Dot: ".",
_DotDotDot: "...",
// keywords
_Break: "break",
_Case: "case",
_Chan: "chan",
_Const: "const",
_Continue: "continue",
_Default: "default",
_Defer: "defer",
_Else: "else",
_Fallthrough: "fallthrough",
_For: "for",
_Func: "func",
_Go: "go",
_Goto: "goto",
_If: "if",
_Import: "import",
_Interface: "interface",
_Map: "map",
_Package: "package",
_Range: "range",
_Return: "return",
_Select: "select",
_Struct: "struct",
_Switch: "switch",
_Type: "type",
_Var: "var",
}src/cmd/compile/internal/syntax/scanner.go
func (s *scanner) next() {
// ……
redo:
// skip white space
c := s.getr()
for c == ' ' || c == '\t' || c == '\n' && !nlsemi || c == '\r' {
c = s.getr()
}
// token start
s.line, s.col = s.source.line0, s.source.col0
if isLetter(c) || c >= utf8.RuneSelf && s.isIdentRune(c, true) {
s.ident()
return
}
switch c {
// ……
case '\n':
s.lit = "newline"
s.tok = _Semi
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(c)
// ……
default:
s.tok = 0
s.error(fmt.Sprintf("invalid character %#U", c))
goto redo
return
assignop:
if c == '=' {
s.tok = _AssignOp
return
}
s.ungetr()
s.tok = _Operator
}

x = y op z
t1 = 2 + 6
t2 = i * t1
slice[i] = t2t1 = i * 8
slice[i] = t1

go build -gcflags "-N -l" -o hello src/main.go
[qcrao@qcrao hello-world]$ gdb hello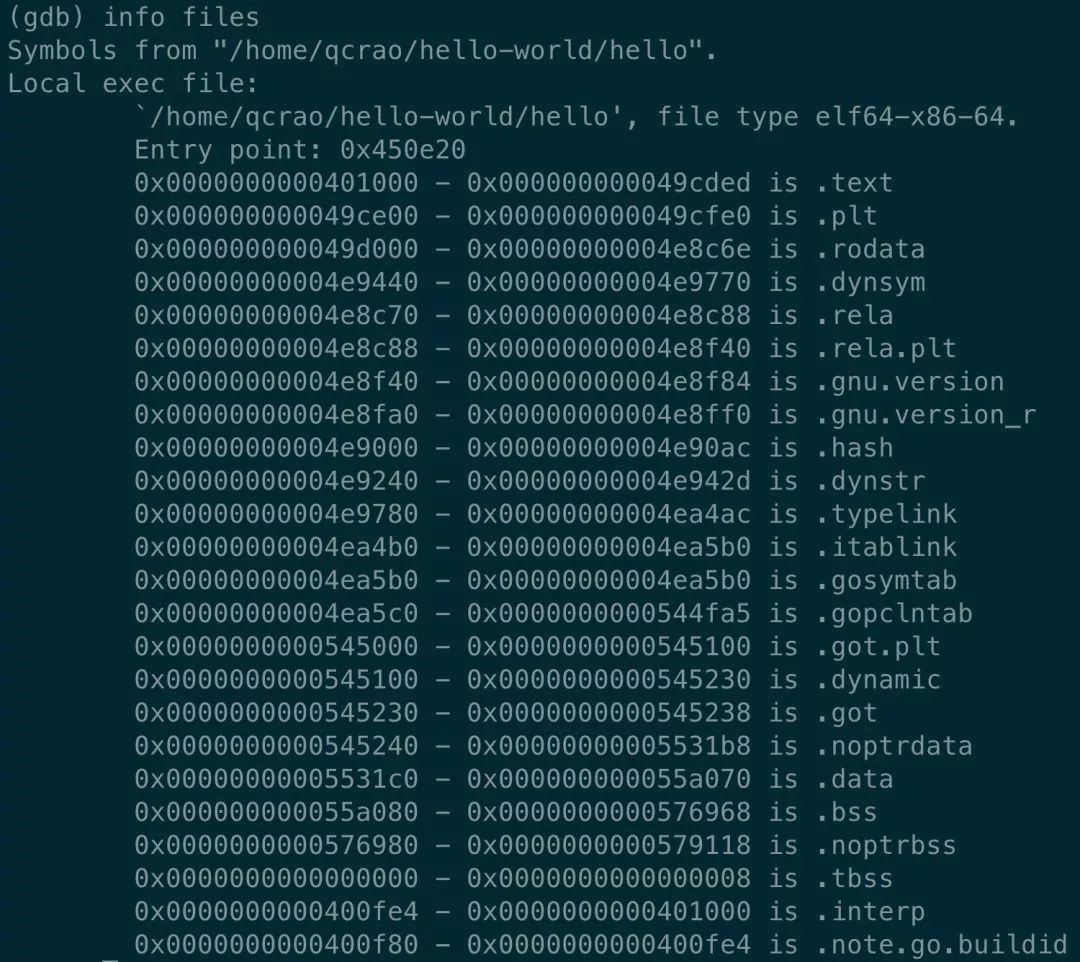
(gdb) b *0x450e20
Breakpoint 1 at 0x450e20: file /usr/local/go/src/runtime/rt0_linux_amd64.s, line 8.TEXT _rt0_amd64_linux(SB),NOSPLIT,$-8
LEAQ 8(SP), SI // argv
MOVQ 0(SP), DI // argc
MOVQ $main(SB), AX
JMP AXTEXT main(SB),NOSPLIT,$-8
MOVQ $runtime·rt0_go(SB), AX
JMP AXTEXT runtime·rt0_go(SB),NOSPLIT,$0
// 省略很多 CPU 相关的特性标志位检查的代码
// 主要是看不懂,^_^
// ………………………………
// 下面是最后调用的一些函数,比较重要
// 初始化执行文件的绝对路径
CALL runtime·args(SB)
// 初始化 CPU 个数和内存页大小
CALL runtime·osinit(SB)
// 初始化命令行参数、环境变量、gc、栈空间、内存管理、所有 P 实例、HASH算法等
CALL runtime·schedinit(SB)
// 要在 main goroutine 上运行的函数
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
PUSHQ $0 // arg size
// 新建一个 goroutine,该 goroutine 绑定 runtime.main,放在 P 的本地队列,等待调度
CALL runtime·newproc(SB)
POPQ AX
POPQ AX
// 启动M,开始调度goroutine
CALL runtime·mstart(SB)
MOVL $0xf1, 0xf1 // crash
RET
DATA runtime·mainPC+0(SB)/8,$runtime·main(SB)
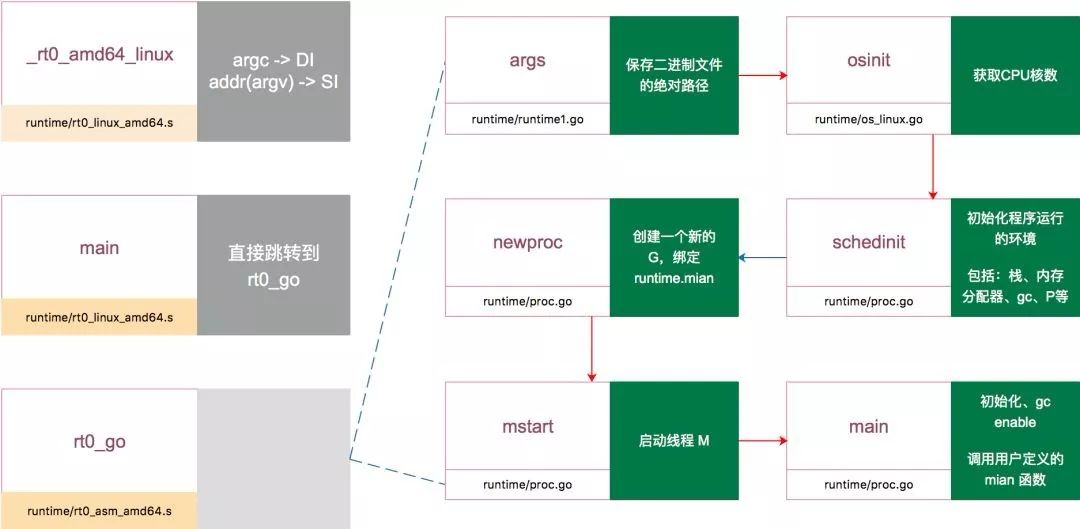
GLOBL runtime·mainPC(SB),RODATA,$8检查运行平台的CPU,设置好程序运行需要相关标志。
TLS的初始化。
runtime.args、runtime.osinit、runtime.schedinit 三个方法做好程序运行需要的各种变量与调度器。
runtime.newproc创建新的goroutine用于绑定用户写的main方法。
runtime.mstart开始goroutine的调度。
exit(0)
for {
var x *int32
*x = 0
}


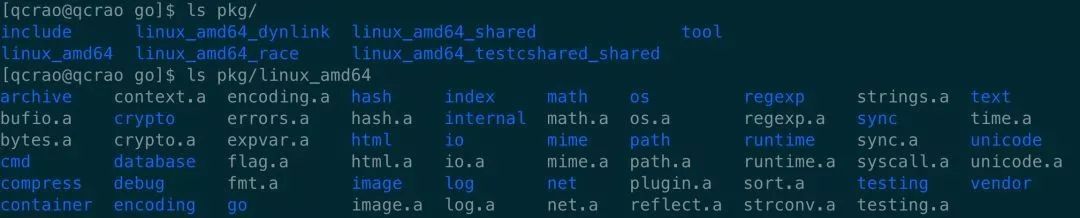

src
pkg
bin
go
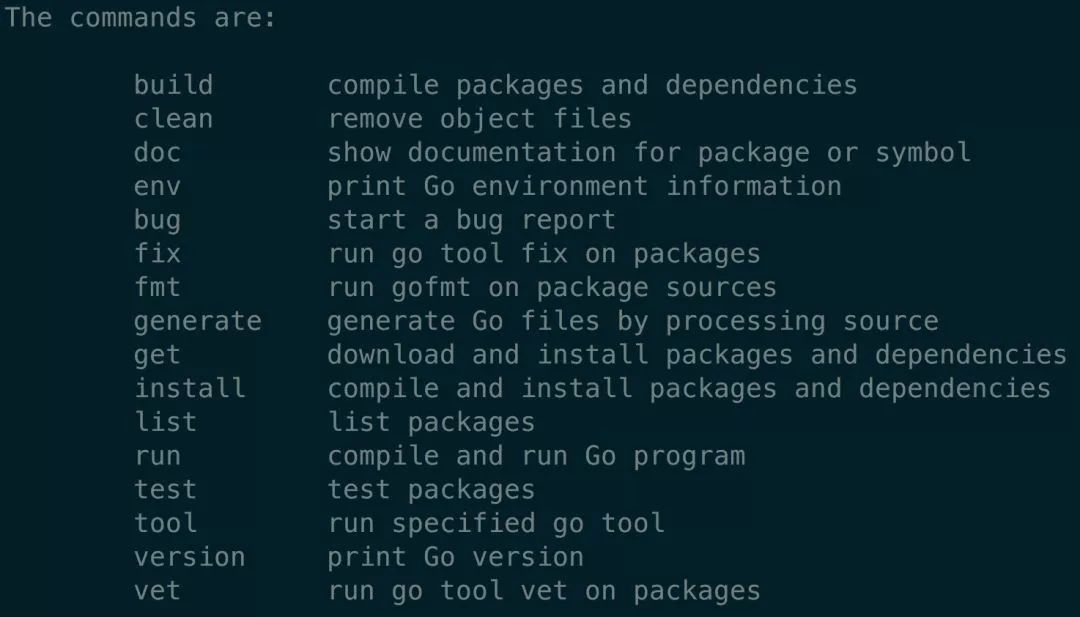
go build
go install
go runusage: go build [-o output] [-i] [build flags] [packages]
命令源码文件:是 Go 程序的入口,包含 func main() 函数,且第一行用 packagemain 声明属于 main 包。
库源码文件:主要是各种函数、接口等,例如工具类的函数。
测试源码文件:以 _test.go 为后缀的文件,用于测试程序的功能和性能。
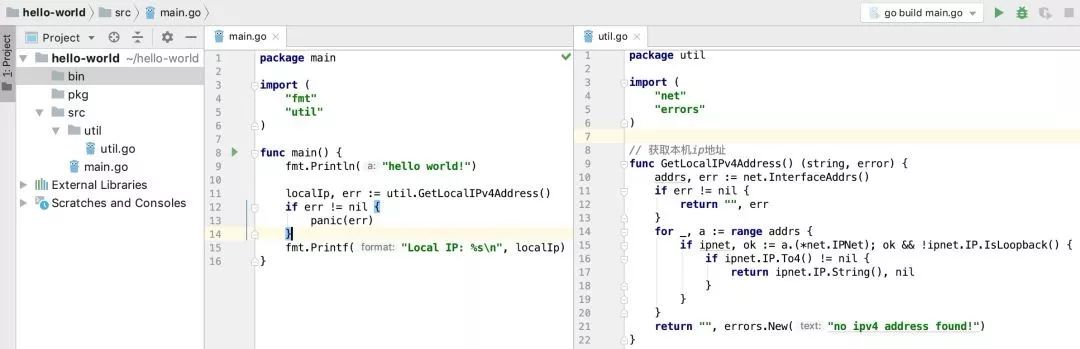
hello world!
Local IP: 192.168.1.3go build -o bin/hellogo build utilgo build -v -x -work -o bin/hello src/main.go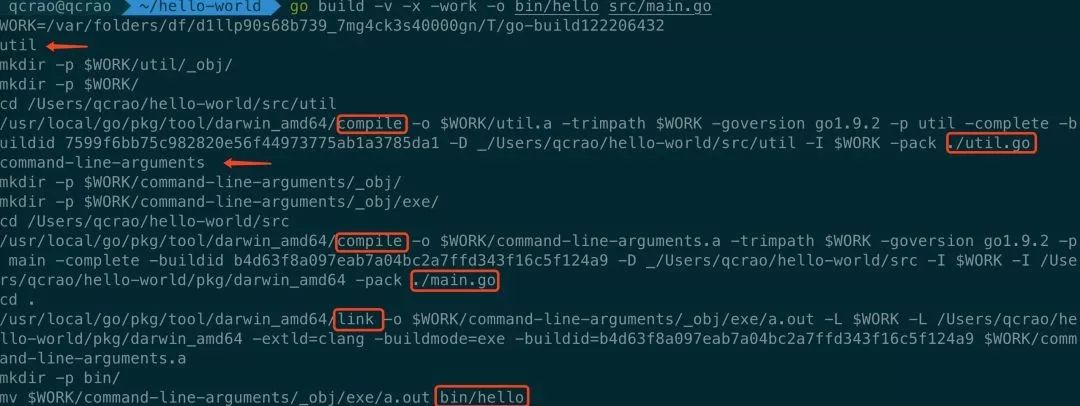
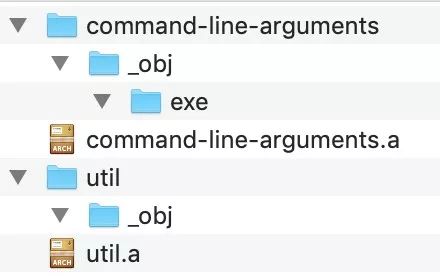
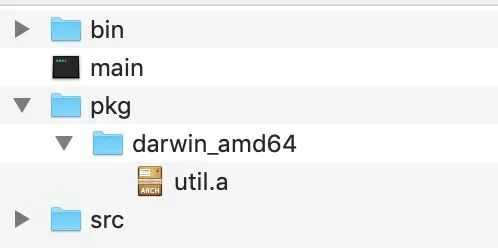
GOOS 和 GOARCH。这两个环境变量不用我们设置,系统默认的。
GOOS 是 Go 所在的操作系统类型,GOARCH 是 Go 所在的计算架构。
Mac 平台上这个目录名就是 darwin_amd64。
go install src/main.go
或者
go install util
go run -x -work src/main.go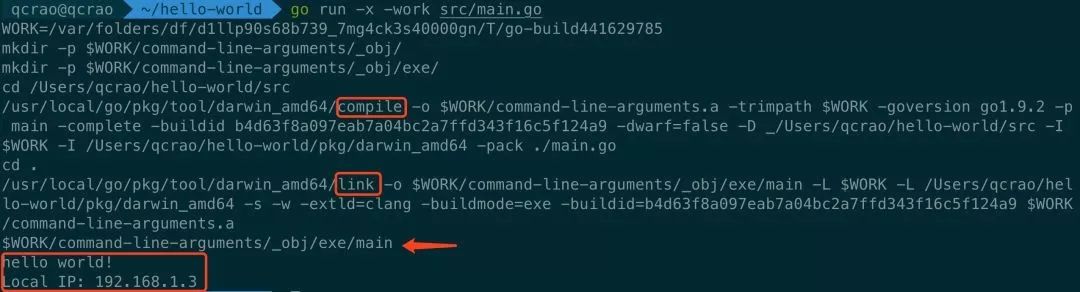


【《程序员的自我修养》全书】https://book.douban.com/subject/3652388/
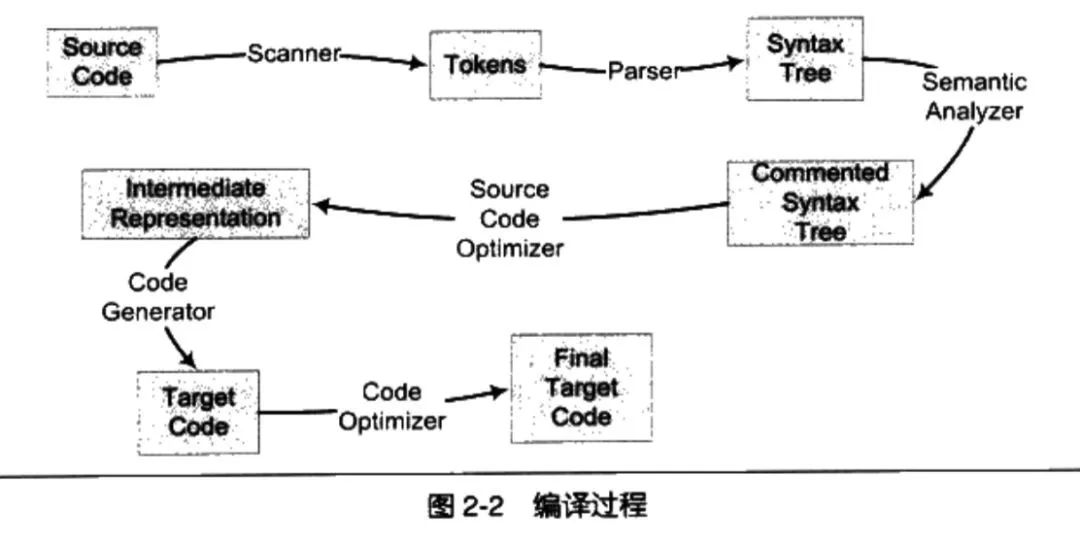
【面向信仰编程 编译过程概述】https://draveness.me/golang-compile-intro
【golang runtime 阅读】https://github.com/zboya/golangruntimereading
【Go-Questions hello-world项目】https://github.com/qcrao/Go-Questions/tree/master/examples/hello-world
【雨痕大佬的 Go 语言学习笔记】https://github.com/qyuhen/book
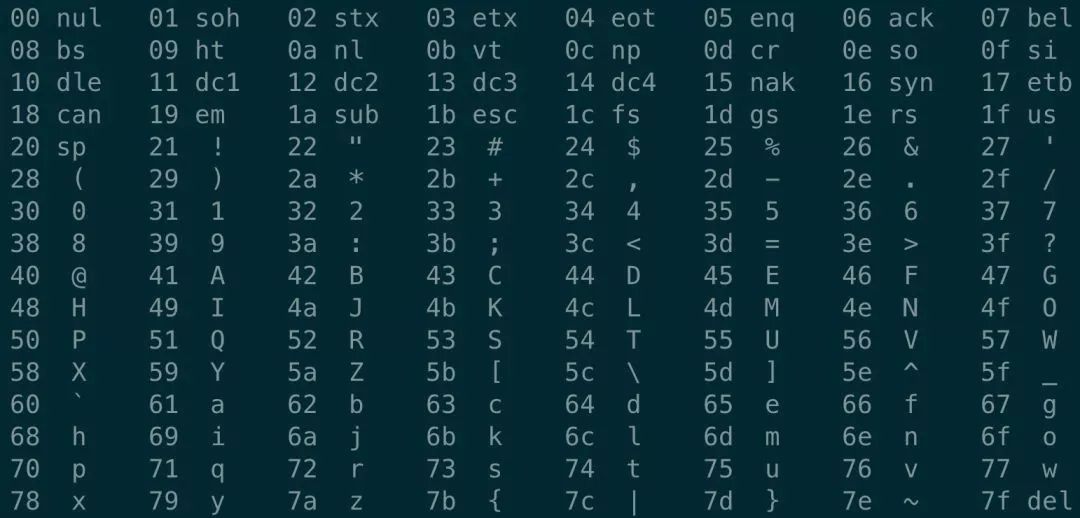
【vim 以 16 进制文本】https://www.cnblogs.com/meibenjin/archive/2012/12/06/2806396.html
【Go 编译命令执行过程】https://halfrost.com/go_command/
【Go 命令执行过程】https://github.com/hyper0x/gocommandtutorial
【Go 词法分析】https://ggaaooppeenngg.github.io/zh-CN/2016/04/01/go-lexer-%E8%AF%8D%E6%B3%95%E5%88%86%E6%9E%90/
【曹大博客 golang 与 ast】http://xargin.com/ast/
【Golang 词法解析器,scanner 源码分析】https://blog.csdn.net/zhaoruixiang1111/article/details/89892435
【Gopath Explained】https://flaviocopes.com/go-gopath/
【Understanding the GOPATH】https://www.digitalocean.com/community/tutorials/understanding-the-gopath
【讨论】https://stackoverflow.com/questions/7970390/what-should-be-the-values-of-gopath-and-goroot
【Go 官方 Gopath】https://golang.org/cmd/go/#hdr-GOPATHenvironmentvariable
【Go package 的探索】https://mp.weixin.qq.com/s/OizVLXfZ6EC1jI-NL7HqeA
【Go 官方 关于 Go 项目的组织结构】https://golang.org/doc/code.html
【Go modules】https://www.melvinvivas.com/go-version-1-11-modules/
【Golang Installation, Setup, GOPATH, and Go Workspace】https://www.callicoder.com/golang-installation-setup-gopath-workspace/
【编译、链接过程链接】https://mikespook.com/2013/11/%E7%BF%BB%E8%AF%91-go-build-%E5%91%BD%E4%BB%A4%E6%98%AF%E5%A6%82%E4%BD%95%E5%B7%A5%E4%BD%9C%E7%9A%84%EF%BC%9F/
【1.5 编译器由 go 语言完成】https://www.infoq.cn/article/2015/08/go-1-5
【Go 编译过程系列文章】https://www.ctolib.com/topics-3724.html
【曹大 go bootstrap】https://github.com/cch123/golang-notes/blob/master/bootstrap.md
【golang 启动流程】https://blog.iceinto.com/posts/go/start/
【探索 golang 程序启动过程】http://cbsheng.github.io/posts/%E6%8E%A2%E7%B4%A2golang%E7%A8%8B%E5%BA%8F%E5%90%AF%E5%8A%A8%E8%BF%87%E7%A8%8B/
【探索 goroutine 的创建】http://cbsheng.github.io/posts/%E6%8E%A2%E7%B4%A2goroutine%E7%9A%84%E5%88%9B%E5%BB%BA/


热 文 推 荐
☞花了 4 天,破解 UNIX 联合创始人 39 年前的密码!
☞2019年胡润百富榜发布,比特大陆创始人詹克团成「中国区块链首富」!
点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。




