谷歌发布新一代定向人声分离系统,2.2MB模型提升设备端语音识别
机器之心发布
2018 年,谷歌科学家王泉等人发表 VoiceFilter 系统,利用声纹识别实现定向人声分离。最近,王泉等人挑战设备端语音识别难题,提出新一代定向人声分离系统 VoiceFilter-Lite,只需 2.2MB 大小的模型,就能将重叠语音的词错率(word error rate)降低 25.1%。
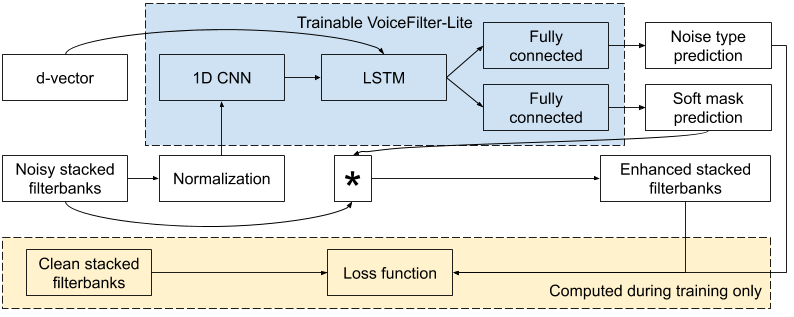
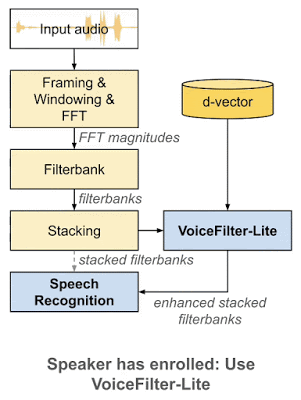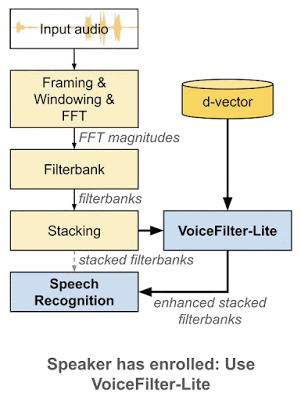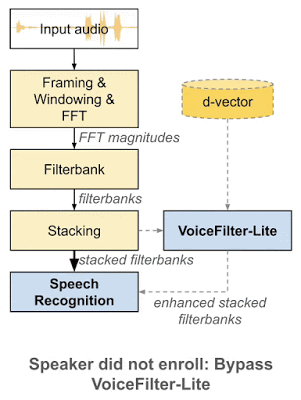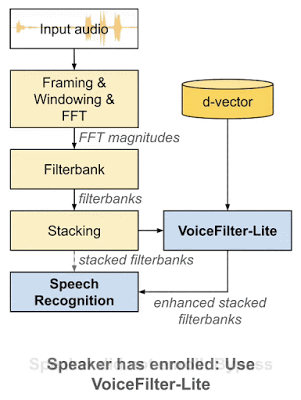
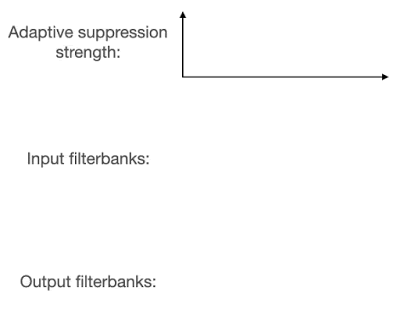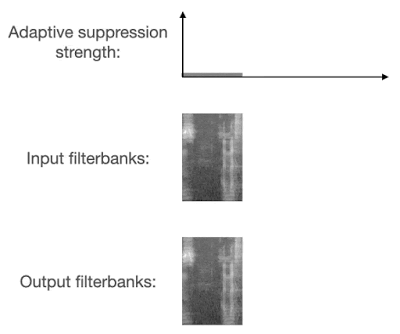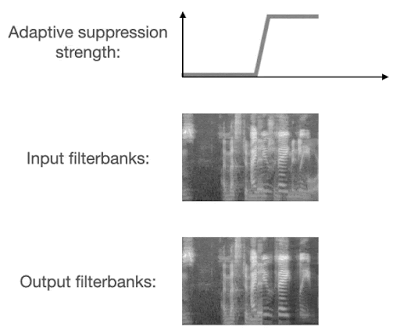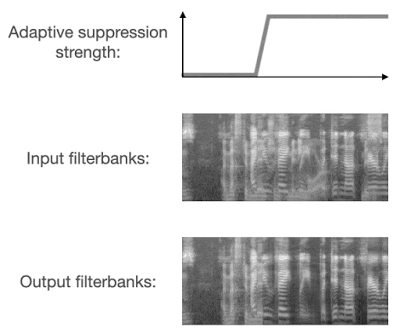
谷歌博客链接:https://ai.googleblog.com/2020/11/improving-on-device-speech-recognition.html
论文链接:https://arxiv.org/pdf/2009.04323.pdf
Amazon SageMaker实战教程(视频回顾)
10月15日-10月22日,机器之心联合AWS举办3次线上分享,全程回顾如下,复制链接到浏览器即可观看。
另外,我们准备了Amazon SageMaker 1000元服务抵扣券,帮助开发者体验各项功能。点击阅读原文,即可领取。

-
视频回顾地址: https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715443e4b005221d8ea8e3
主要介绍情感分析任务背景、进行基于Bert的情感分析模型训练、利用AWS数字资产盘活解决方案进行基于容器的模型部署。
视频回顾地址:https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715d38e4b0e95a89c1713f
视频回顾地址:https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715d6fe4b005221d8eac5d
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容

Arxiv
0+阅读 · 2021年1月27日
Arxiv
0+阅读 · 2021年1月26日
Arxiv
7+阅读 · 2019年4月18日
Arxiv
4+阅读 · 2018年4月19日
Arxiv
4+阅读 · 2017年12月2日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年1月27日
Arxiv
0+阅读 · 2021年1月26日
Arxiv
7+阅读 · 2019年4月18日
Arxiv
4+阅读 · 2018年4月19日
Arxiv
4+阅读 · 2017年12月2日