谷歌神经网络人声分离技术再突破!词错率低至23.4%

新智元报道
来源:venturebeat、Arxiv
新智元报道
编辑:克雷格
【新智元导读】谷歌和Idiap研究所的研究人员训练了两个独立的神经网络,能够显著降低多说话者信号的语音识别词错误率。
把一个人的声音从嘈杂的人群中分离出来是大多数人潜意识里都会做的事情——这就是所谓的鸡尾酒会效应。像谷歌Home和亚马逊的Echo这样的智能扬声器实现分离人群中的声音可能还要再经历一段时间,但多亏了AI,它们或许有一天能够像人类一样过滤掉声音。
谷歌和位于Switerzland的Idiap研究所的研究人员发表在Arxiv上的一篇论文中描述了一种新的解决方案。他们训练了两个独立的神经网络——说话者识别网络(a speaker recognition network)和声谱掩码网络(a spectrogram masking network)——这两个网络一起“显著”降低了多说话者信号的语音识别词错误率(WER)。
他们的工作建立在麻省理工学院计算机科学和人工智能实验室今年早些时候发表的一篇论文的基础上,该论文描述了一个名为PixelPlayer的系统,该系统能够将单个乐器的声音从YouTube视频中分离出来。

论文:
VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
论文地址:
https://arxiv.org/pdf/1810.04826.pdf
在最新的论文中,研究人员写道:“我们的任务是将一部分感兴趣的说话者的声音与所有其他说话者和声音的共性分离开来。例如,这样的子集可以由一个目标扬声器对个人移动设备发出语音查询,或者由一个家庭成员对一个共享的家庭设备进行交谈而形成。”
研究人员的语音过滤系统分为两部分,包括LSTM模型和卷积神经网络(只有一个LSTM层)。第一个采用预处理的语音采样和输出扬声器嵌入(即矢量形式的声音表示)作为输入,而后者预测来自嵌入的软掩模或滤波器以及根据噪声音频计算的幅度谱图。掩模用于生成增强幅度谱图,当与噪声音频的相位(声波)组合并变换时,产生增强的波形。

AI系统被训练以便最大限度地减少屏蔽幅度频谱图与从干净音频计算的目标幅度频谱图之间的差异。
该团队为训练样本提供了两个数据集:(1)来自13.8万名演讲者的大约3400万个匿名语音查询日志;(2)开源语音库LibriSpeech、VoxCeleb和VoxCeleb2的汇编。VoiceFilter网络对来自CSTR VCTK数据集(由爱丁堡大学维护的一组语音数据)和LibriSpeech的2338个贡献者的语音样本进行了训练,并使用来自73名演讲者的话语进行评估。
在测试中,VoiceFilter在双扬声器方案中将字错误率从55.9%降低到23.4%。
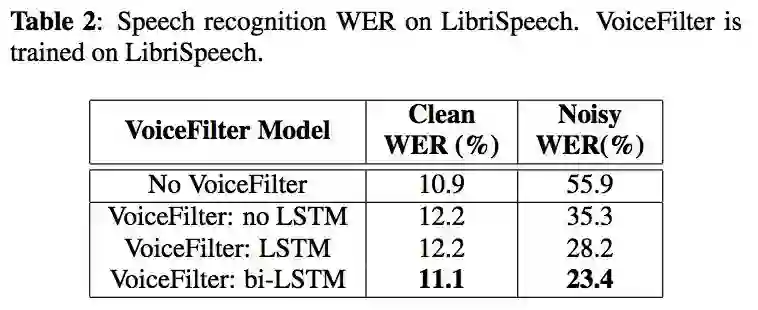
研究人员写道:“我们已经证明了使用经过专门训练的扬声器编码器来调整语音分离任务的有效性。这样的系统更适用于真实场景,因为它不需要事先知道扬声器的数量……我们的系统完全依赖于音频信号,可以很容易地通过使用具有高度代表性的嵌入向量来推广到未知的扬声器。”
新智元AI WORLD 2018
世界人工智能峰会全程回顾
新智元于9月20日在北京国家会议中心举办AI WORLD 2018世界人工智能峰会,邀请机器学习教父、CMU教授 Tom Mitchell,迈克思·泰格马克,周志华,陶大程,陈怡然等AI领袖一起关注机器智能与人类命运。
全程回顾新智元 AI World 2018 世界人工智能峰会盛况:
爱奇艺
上午:https://www.iqiyi.com/v_19rr54cusk.html
下午:https://www.iqiyi.com/v_19rr54hels.html
新浪:http://video.sina.com.cn/l/p/1724373.html

震撼!AI WORLD 2018世界人工智能峰会开场视频




