CVPR2019|西交大和MSRA提出尺度不变性的人脸检测策略
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者:胡孟 https://zhuanlan.zhihu.com/p/81353261 来源:知乎,已获作者授权转载,禁止二次转载。
本笔记记录针对尺度不变性的人脸检测策略Group Sampling,西交大、MSRA作品;这篇论文文笔流畅、公式不多、图表清晰、实验对比有针对性,模型性能也很好,是一篇不错的美文;
现阶段wider face上的性能已经刷到快饱和了(hard set可能还能继续提升点,但已经是很极端的场景了,如果集成各种tricks弄成一个超级模型,性能是棒棒的,但个人觉得是有过拟合的风险),各类方案为了百尺竿头更进一步,取得sota,各种tricks无所不用其极,导致整套方案相对来说是比较臃肿的;有些论文做了很多很多的消融实验,集成了很多有效的tricks(无效的当然就不会写在论文里面啦~~~),性能是上去了,但看着心里总是有点犯嘀咕的,一来不好复现、技巧性太强,二来也会质疑其普适性;
Group Sampling和Soft-NMS、SNIP等方案比较类似,发现了现阶段人脸检测中存在的一个问题,提出解决这个问题的方案,最终性能也比较好,没有太多的工程技巧,看完论文后也会想,嗯,要不我也拿来用用,也容易实现,实验结果很好,说不定在我的任务上也能有帮助呢对吧;
名词定义:
1 Group Sampling:本文提出的人脸检测算法,严格意义上并不能称为一个算法,应该是模型训练阶段的数据组织策略,将作为训练样本的anchors按其尺度划分到各个groups,并确保各个group间的训练样本总数量大致相当,正负样本数量比例相似,最终就能减缓训练阶段正负样本比例不均衡的困扰,可参见fig 1、2;
Abstract
1 为了检测图像中不同尺度的人脸,现有策略一般是图像 / 特征金字塔,图像金字塔的弊端就是多尺度图像多次输入模型,检测速度比较慢;特征金字塔仅需输入一次图像(也有结合图像金字塔 + 特征金字塔的多尺度输入方案,不在本次讨论范围内),但通过多层次、多尺度的金字塔特征图,达到检测不同尺度人脸的目标,SSD、FPN等就是此类方案,利用多层特征图生成特征金字塔,不同分辨率的特征图检测不同尺度的人脸,大尺度人脸在高层特征图上检测,小尺度人脸在低层特征图上检测;
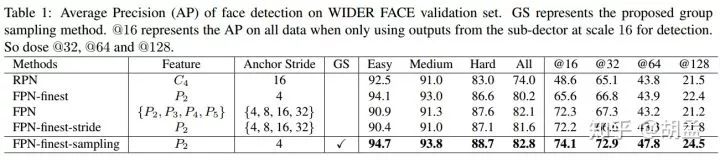
2 但本文通过实验发现(table 1):其实根本不需要通过多层次的特征金字塔上的多个分支做人脸检测,仅使用单层feature map上的特征,做人脸检测也能达到sota;那么,问题出在哪?单层feature map做人脸检测,性能如何提升?
3 文中发现,对于大尺度范围跨度的人脸,影响检测器的性能之处在于训练样本的不均衡问题,特别是不同人脸尺度上(对应到不同尺度anchor)的正负样本均衡问题,才是导致模型性能有无提升的关键(the balance of training samples, including both positive and negative ones, at different scales is the key);
4 本文进一步提出group sampling策略,将anchors按尺度划分到不同的groups里面,使得训练阶段每个group内正负样本的数量大致是相同的,核心思想可参照4.2小节;
5 文中仅使用FPN最后一层特征(the last layer of FPN as features,如fig 1,指的是P2的finest layer),未使用图像 / 特征金字塔的多分支检测,再结合group sampling,就能取得sota;实验 + 分析部分,也能充分证明group sampling本身是有效的,最终无需bells and whistles,就在FDDB、wider face、FDDB上取得了sota;
1. Introduction
人脸检测的场景中,小尺度、大尺度范围内变化的人脸是一个很大的挑战;Fast R-CNN / Faster R-CNN based人脸检测算法,都使用单尺度的feature map来检测各种尺度的人脸,但在小尺度人脸上性能一般,两个原因:
1 人脸尺度小,经过若干层conv + pooling操作后,人脸特征已淹没在feature map(如conv 4_3,下同)中,无法进一步做高质量的人脸判别;
2 conv4_3上anchor对应的stride = 16,导致小尺度人脸gt bbox本身就很难匹配到足够多、尺度合适的anchors,这样匹配上的anchor不仅尺度与之不是最匹配,数量也较少,大部分anchors都归类于负样本了,训练过程中正负样本不均衡的问题将比较严重;----- S3FD、ZCC还是提出了等比例密度的anchor采样策略,能缓解此类问题;
那么,为了解决此类小尺度人脸,人脸大尺度范围内变化的问题,一些解决方案如下:
1 如HR、SNIP,使用图像金字塔完成训练、预测;
2 如IO-Net、HyperNet,联合高低层特征图完成训练、预测;
3 如U-Net,使用top-down、skip connection结构,融合高低层特征图,最终仅使用高分辨率的单张特征图预测(a single high-level feature map with fine resolution);
4 如SSD、FPN,高低层特征图都用上,多个分支、全家桶似地检测不同尺度的人脸 / 目标;
以上四种方案都很牛逼,各有千秋,方案4效果最深入人心,对小尺度人脸检测效果最好,用的比例也最高;
此前大家经验主义地认为,SSD、FPN-style等检测器性能如此之好的原因,是因为使用了多层次、多尺度的特征表达,对比在单层次、单尺度上的特征图,有更多的尺度不变性,也带来了更多的鲁棒性;但本文发现,最起码在人脸检测中,事实的真相并不是这样子的(有点扎心了~~),文中发现在特征金字塔上做目标检测,将会为每层特征图上生成不同尺度、数量各异的anchors(各个尺度的anchors还对应到不同的stride,而非RPN中不同尺度的anchor使用相同的stride),这才是特征金字塔上目标检测性能优于单尺度特征图上结果的原因,而非特征金字塔本身的特征表达能力强,在FPN的实验中,也没有重视这个问题;在本文实验中,发现如果在单尺度特征图上也使用和FPN一样,相同数量的anchors,也能取得差不多的性能;---- 起码fig 1 + table 1中的结果能支持这个结论;
基于以上发现,文中做了海量实验,最终定位到当前anchor-based人脸检测器中存在的一个大问题:不同尺度目标上对应的anchor数量是不均衡的,且各个尺度anchor间正负样本的比例更不均衡;文中使用了Faster R-CNN中的RPN、FPN作为baseline,各个算法流程对比如fig 1:并进一步计算了训练阶段,各个anchor尺度下正负样本所占比例(横坐标为anchor尺度),如fig 2(a)、(b);
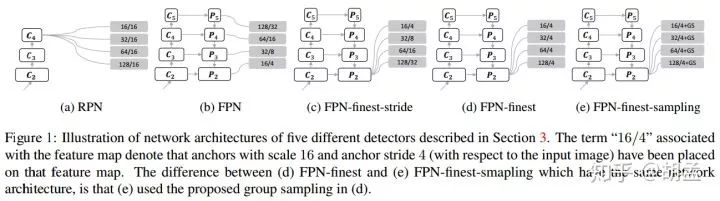
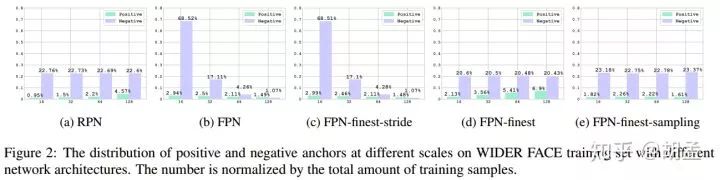
对RPN而言,单层特征图上提取特征并生成不同尺度的anchor,所有尺度的anchor对应相同的stride,小尺度anchor将很难匹配到合适尺度的目标(对比大尺度目标和大尺度anchor,小尺度anchor采样密度过低,过于稀疏,可参照S3FD、ZCC的解释),那么对于小尺度gt bbox而言,其匹配的anchor正样本就非常少,负样本数量繁多,最终性能也不会很好;
FPN使用低层高分辨率特征图检测小尺度目标,小尺度anchor专职操作于该feature map,如fig 1(b),P2上anchor的stride也不会与P3、P4、P5一刀切地保持一致,这样对比RPN,小尺度anchor的采样密度更高,负样本的绝对数量增加了很多(gives rise to several more times negative training samples for small objects than large objects),但anchor正样本的绝对数量也同步增加了,最终在coco、wider face上,FPN-based检测器性能优于RPN-based检测器,特别是在小尺度目标上性能更好;---- 也即,作者认为性能提升的关键,不在于特征金字塔的多层次多分支预测,而在于训练阶段正负样本的比例更均衡,以及带来的更多正样本;
再就是如fig 1(d)、fig 2(d),仅使用FPN的最后一层feature map操作(网络结构图显示的是finest layer,一个概念),分析正负样本的比例情况,可以发现与fig 2(a) RPN分布类似,仅在绝对数量上所有差异,此时小尺度anchor的采样密度高了,匹配的anchor数量也不错,但有一个问题:各个尺度anchor下对应的正负样本比例却不均衡了,大尺度anchor上正负样本比例明显更高,此类不均衡问题就冒出来了;那么FPN-finest最终在小尺度目标上的性能也很一般,原因也归结于:insufficient positive samples for small anchors;
再对比fig 2(d)、fig 2(e),多了group sampling策略(原理很简单:在训练阶段的每次迭代中,随机采样正负样本,保持各个尺度anchor间大致相同的正负样本比例和数量:randomly sample the same number of positive samples as well as the same number of negative samples at each scale during each iteration of the training process),参与训练的各个anchor尺度上,正负样本数量明显更加均衡了,那么FPN-finest-sampling还是很牛逼的,单层特征图上检测人脸,最终在wider face上性能优于FPN;
此外,文中进一步发现,Faster R-CNN的2nd-stage Fast R-CNN中同样面对着数据不均衡的问题(数据集中各个尺度上目标数量的分布是不均衡的),group sampling也可以应用于此,在对不同尺度的proposals经过RoI pooling提取特征和,再按尺度划分做一次均衡的采样(evenly sampling the features after RoI Pooling for different scales),还可以进一步提升检测性能;
本文贡献有三:
1 文中发现anchor不同尺度间的正负样本比例分布不均衡,而非特征金字塔上各个尺度feature map的特征表达能力,影响到多分支的检测性能,这点与之前对FPN的认知有点不一致;
2 文中发现anchor-based检测器的性能瓶颈在于:不同anchor尺度上正负样本比例分布不均衡;
3 本文提出group sampling,实现简单,确保了不同anchor尺度上正负样本的比例分布比较均衡,最终对检测性能有了较大的提升;
2. Related Work
Single scale feature for multi-scale detection
经典的如Fast R-CNN、Faster R-CNN,通过RoI pooling操作提取scale-invariant features,在单层、单尺度的feature map上检测多尺度目标,在性能 / 速度上达到了很好的平衡,但在小尺度目标上性能一般,文中认为原因出在对小尺度目标而言,缺乏足够数量的正样本参与训练(insufficient positive training samples),但group sampling可以消除此类弊端,并取得不错的性能提升;
Top-down architecture with lateral connections
top-down + lateral connection很经典,在U-Net、SharpMask、Stacked Hourglass Network中都性能棒棒哒,该结构的优势在于,将低层高分辨率细节信息丰富、高层低分辨率语义信息丰富的特征图,融合进一个single high-resolution feature map (优势互补),在本文的实验中也发现,top-down + lateral connection对人脸检测的帮助很大;
Multi-scale feature for multi-scale detection
如SSD、MS-CNN、FPN,特征金字塔、多特征图分支、在各个尺度特征图上检测不同尺度的目标,FPN也使用了top-down + lateral connection来增强特征表达能力,类似SSH、S3FD中也有采用,但文中发现这些算法性能提升的关键之处在于,anchor的采样分布对小尺度目标更有利(得到了更均衡的正负样本数量),而非多层次化的特征表达能力;
Data imbalance
数据类别间不均衡的问题在机器学习、数据挖掘、深度学习等方向上已经存在了很多年,也取得了很多研究成果;经典做法就是对训练数据的重采样策略,对数据量较多的类过采样、数据量较少的类重采样;或者使用cost-sensitive learning,对数据量少的训练样本对应的loss,给予更高权重的loss;在目标检测任务中,训练样本尺度不均衡的问题,也可以认为是类别不均衡的一种,经典的方案如OHEM、focal loss等能解决部分问题;再如S3FD中发现了,对小尺度目标而言,缺乏足够数量的训练正样本与之匹配,因此也使用了更小的IoU阈值以提升小目标所对应的正样本数量;
本文发现,尺度分布不均衡问题在正负训练样本中都存在,group sampling恰好为此而生,专门解决该问题,并取得了不错的性能;
3. Motivation: Scale Imbalance Distribution
本节进一步分析两个影响检测性能的因素:特征金字塔上的多尺度特征表达、不同尺度anchor间的正负样本均衡;
文中使用ResNet-50主干网 + top down + skip connections,如fig 3:
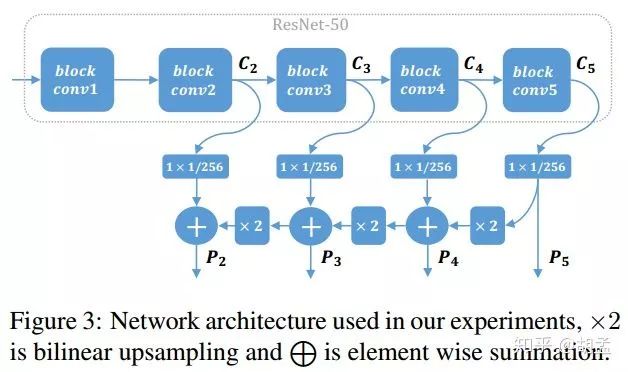
各个block conv对应的输出特征表示为C2、C3、C4、C5,先通过1 x 1 conv归一化feature map通道数,与上一层up-sampled操作后的特征层做element-wise addition,输出P2、P3、P4、P5等feature map(P5操作方式有点不同,不再赘述),Pi / Ci有相同的尺度,各个anchor尺度为:{16,32,64,128},长宽比:1,最后结合fig 1、fig 2,对比如下:
1 RPN:仅使用C4做人脸检测,所有尺度anchor都在C4上分布并提特征,对应stride = 16;
2 FPN:经典的算法,{P2、P3、P4、P5}上做人脸检测,anchor尺度 = {16,32,64,128},对应stride = {4,8,16,32};
3 FPN-finest-stride:与FPN类似,但所有尺度anchor都只作用于P2上,anchor尺度 = {16,32,64,128},对应stride = {4,8,16,32};---- This is implemented by sub-sampling P2 for larger strides,还多了这么一句话,费解;进一步上采样P2?
4. FPN-finest:所有尺度anchor都只作用于P2上,各个anchor的stride = 4;
5. FPN-finest-sampling:与FPN-finest一致,但新增了group sampling,使得训练阶段不同尺度anchor上的正负样本比例保持一致;
5个方案在wider face上使用相同的训练、测试策略,并在val set上测试,得到的结论如下:
Using multiple layer features is little helpful
FPN、FPN-finest-stride(fig 2(b)、(c))差异在于:在单层feature map还是多层feature map分支上完成目标检测,结果如table 1,FPN在easy / medium / hard上AP性能分别为90.9%、91.3%、87.6%,FPN-finest-stride分别为:90.4%、91.0%、87.1%,差异不大,说明两个问题:
1 多尺度feature map上的人脸检测对性能提升有限;
2 单尺度feature map上做人脸检测也是可以的,性能是足够的;
Scale imbalance distribution matters
进一步对比FPN-finest-stride、FPN-finest,从fig 1中可看到二者区别:二者为不同尺度anchor设置的stride不一样,后者保持stride = 4不变;从实验结果table 1中有以下发现:
1 FPN-finest在easy / medium上性能很好,因为对比FPN-finest-stride,前者可以获取更多的大尺度anchor参与训练;
2 尽管各个金字塔层上都是stride = 4(anchor尺度为16 pixel的也是如此),但FPN-finest在hard上性能一般;
从fig 2中可知不同检测算法中,各个尺度anchor中正负样本数所对应的比例,对应的结果如table 1,结论如下:
1 FPN、FPN-finest-stride性能相当,从fig 2(b)、(c)中可知,二者不同尺度anchor上正负样本数量比例也类似,说明之前的一个假设是有道理的,即:在总体anchor数量相当,不同尺度anchor下正负样本数量比例类似时,二者性能差异不大;
2 从fig 2(c)、(d)中可知,FPN-finest-stride、FPN-finest的不同尺度anchor间正负样本的分布比例是不均衡的,但二者分布情况也存在很大的差异,FPN-finest-stride在小尺度anchor上有更多数量的负样本,因此hard上性能也更好点、FPN-finest在大尺度anchor上有更多数量的正样本,因此easy上性能更好点;
结论:检测模型的性能,应该是有受到anchor内正负样本数量不均衡的影响,这从fig 2(a)中RPN在大尺度anchor上,对比FPN-finest-stride有更多的正样本数量,最终在easy上性能优于其2%,也可以得到证明;
受以上分析的启发,本文提出group sampling方案来处理各个尺度anchor间正负样本分布不均衡的问题,从fig 2(e)中也可知,对比其他4个方案,FPN-finest-sampling在训练阶段得到的anchor间正负样本比例明显更加均衡,table 1中得到的效果也是最好的;
4. Group Sampling Method
anchor based人脸检测器训练阶段的要点:将gt bbox、anchors按照IoU比例,对anchors划分正负样本标签,本小节先介绍本文使用的anchor匹配策略,再介绍group sampling方案;
4.1. Anchor Matching Strategy
当前经典的gt bbox、anchor的两步匹配方案:
1st-pass:每一个anchor与所有gt bbox计算一遍IoU,若IoU大于阈值λ1,则该anchor被划为正样本,小于阈值λ2,则被划分为负样本;--- 这种操作对某些小尺度gt bbox不利,因为可能某个小尺度gt bbox并不能匹配到合适的anchor;---- 可结合某些代码学习下,简单点说就是,若anchor_i与gt bbox_big IoU_1 > λ1,且anchor_i与gt bbox_small IoU_2 > λ1,但IoU_1 > IoU_2,此时会优先匹配anchor_i与gt bbox_big IoU_1,二者相互配对,此时若gt bbox_small与其他任意anchor_j的IoU < λ1,此时就相当于没有与gt bbox_small匹配的正样本anchor了;再通俗点,anchor_i是女神,gt bbox_big IoU_1是高帅富,gt bbox_small IoU_2是高帅富三缺二,此时高帅富与女神配对是天经地义,高帅富三缺二就只能对女神望而兴叹了,其他任意anchor_j就是某个默默陪伴高帅富三缺二的妹纸,奈何人家不降低择偶标准,也只能落花有意流水无情,gt bbox_small就只能这样孤注身,所有anchor都不配对了;---- 当然了,现实情况并不是这样,高帅富三缺二。。。嗯,理论上只要不缺钱,拿下女神并不是难题~~~ 跑偏了,收;
2nd-pass:进一步为1st-pass中未与anchor匹配的gt bbox(也即gt bbox_small)寻找匹配的anchor,下面会进一步介绍;
先做些定义:
{pi}_i = 1~n:anchor的定义,i:anchor的indx,n:所有尺度anchor的总数量;
{gj}_j = 1~m:gt bbox的定义,j:gt bbox的dinx,m:所有gt bbox的总数量;
匹配阶段,先生成匹配矩阵M ∈ R^(n×m),表征gt bbox与anchor的匹配关系,且M(i, j) = IoU(pi, gj);在1st-pass中,每个anchor pi与所有gt bbox匹配一波,以寻找最大IoU,表示为:C(i) = max(1≤j≤m) M(i, j),此时,pi对应的标签L(i)为:
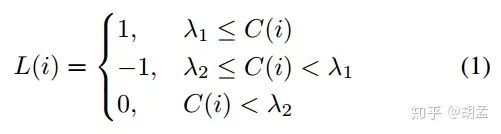
λ1=0.6、λ2=0.4:预定义阈值,1:正样本anchor,0:负样本anchor,-1:未被gt bbox匹配的anchor,训练阶段弃用;
刚才提到了,在1st-pass阶段,一些小尺度gt bbox可能不会匹配到任何anchor,2nd-pass就要避免此类悲剧的发生(也是本着对标注的gt bbox高效利用的原则,不然岂不是白白做标定了?make full use of all gt boxes to increase the number of positive training samples),那么对任意未被匹配的gt bbox gj,若anchor pi同时满足以下三个条件,也可以认为是匹配成功(三个条件,缺一不可):
1 该anchor pi此前未与其他gt bbox匹配;---- 烦请女神专一点,严禁脚踏两只船,高帅富三缺二卑微的尊严神圣不可侵犯;
2 IoU(pi, gj) ≥ λ2;---- 高帅富三缺二,你要是找不到女神就放低标准撒,还真准备单身一辈子啊;
3 j = argmax(1≤u≤m) IoU(pi, gu);---- 妹纸也可以权利反转,找一个最适合的gt bbox gj匹配;
4.2. Group Sampling
anchor与gt bbox匹配后,作为训练样本的anchor间,存在以下两种不平衡情况:
1 anchor内正负样本数量不均衡:负样本数量远超正样本数量,目标检测任务中很常见,毕竟大部分区域都是背景;
2 各个尺度anchor间,正负样本数量也不均衡:现有的gt bbox与anchor匹配策略,导致小尺度gt bbox要匹配合适的anchor,比大尺度gt bbox势必要付出更多的艰辛与妥协;---- 心酸,屌丝就只配跪舔白富美,不配拥有完美的爱情;
问题1在之前已经被发现,并广泛且深入地研究了,如OHEM,训练阶段控制正负样本比例为1:3(按score排序),但问题2被研究得偏少;
那么为了解决以上2个问题,group sampling(scale aware sampling strategy)应运而生,操作如下:
1 将所有参与训练的anchors按其尺度,划分为若干个groups;---- divide all the training samples into several groups according to the
anchor scale, i.e., all anchors in each group have the same scale;
2 对每个group内的训练样本做随机采样,确保数量相同,且每个sampled group内正负样本比例1:3,若正样本欠缺,那就提升负样本的采样数量,使得所有group间训练样本的数量保持一致;---- 这种情况下,anchor间正负样本比例不会完全一致了,会有些许可接受的波动;
公式表示为,Ps、Ns:尺度 s 下,随机采样的正、负anchor样本:
Ps ⊆ {pi|L(i) = 1, S(i) = s}
Ns ⊆ {pi|L(i) = 0, S(i) = s} ---- 比较好理解;
group sampling先确保|Ps| + |Ns| = N(常数:N),再在每个anchor尺度 s 上,确保3|Ps| = |Ns|,此时对每个尺度 s 而言,都能保证足够数量、且均衡比例的正负样本参与模型训练;----- 整篇论文核心思想就这一部分,还是比较容易理解的;
Grouped Fast R-CNN
Fast R-CNN的2nd-stage中,得到RoIs后,通过RoI pooling提取特征,再进一步做cls + reg,文中发现,各个RoIs尺度内,正负样本分布也是不均衡的(the scale distribution of the training samples for Fast RCNN is also unbalanced),也可以使用group sampling操作使得每个group内总训练样本数保持一致,且正负样本比例1:3,实验部分也证明Grouped Fast R-CNN是有效果的;---- anchor确实是有不同的尺度和分布,但要看代码层面是怎么操作的;
Relation to OHEM and Focal Loss
OHEM:bp操作中筛选top-k难分样本参与模型参数更新;--- keep the top K samples with highest training loss for back propagation;
Focal Loss:给予每个训练样本一个动态调整的权重;--- give each sample a specific weight;
整体上就是,对难分样本给予更高的权重,更多的关注度,对每个训练样本分别采用hard / soft manner(比较容易理解,OHEM是一刀切,focal loss按score动态地降低权重),也即implicitly / dynamic地处理数据不平衡问题,但group sampling属于explicitly地处理数据不均衡的方案;
5. Training Process
介绍训练数据集、损失函数、实现细节等;
Training dataset
wider face训练+测试,FDDB测试,不再赘述;
Loss function
分类还是经典的softmax loss,回归采用了新的loss,替代Smooth L1 loss:IoU based loss,IoU least square loss:
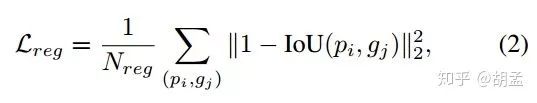
(pi, gj):匹配的anchor pi、gt bbox gj对;
对比smooth-L1 loss,新的损失函数直接优化的IoU ratio本身,这也是与我们按照IoU计算mAP的评估标准保持一致的(可参照IoU-Net),文中提到UnitBox中IoU loss function = - ln(IoU),但当IoU = 1时,UnitBox中IoU损失函数得到的梯度不为零(non-zero gradient,画个ln(x)函数图就明白了),但IoU least square loss不会,得到zero gradient,起码网络收敛也会更稳定;
Optimization details
基于pytorch,使用torchvision的ResNet-50作为主干网的预训练模型,在wider face train set上训练,lr、epoch、wd、syn SGD等参数参照论文;
数据增强:scale jitter + random horizontal flip,尺度扰动区间[1,8],从中随机选择数字n,图像将会按0.25 x n的比例做resize,再从resized后的图像中,randomly crop出一个子区域,确保其长宽不超过1200 pixels,最后加入到训练数据集中;
预测:基于图像金字塔的多尺度测试,所有检测结果合并后再做NMS,测试图像长边尺度不超过3000 pixels;
6. Experiments
分析影响人脸检测性能的因素,消融实验证明group sampling的性能,并基于FPN finest-layer在FDDB、wider face上取得了sota;
6.1. Factors Affecting Detection Accuracy
对fig1、2中介绍的五个检测器,做深入分析,五个检测器主要有2点差异:
1 anchor放置于feature map的不同层上;
2 anchor在feature map上的stride不同;stride越小,feature map层数越低,一般配置的anchor数量也越少;feature map尺度也是与原图尺度,按stride关系对应的,对FPN-finest-stride,特征图P2上对应的anchor尺度 = {16, 32, 64, 128},等价于原图上stride = {4, 8, 16, 32};
评估标准:在easy / medium / hard set上计算AP,但并不能反映检测器在各个特定目标尺度范围内的性能(原因是模型测试一般使用到了图像金字塔,我们无法确定一个128 x 128 pixel的人脸,是被预定义的128 pixel anchor检测到的,还是被图像金字塔中缩小版图像的16 pixel anchor检测到的),为了评估每个sub-detector的性能,分别对应@16,@32,@64,@128,结果如table 1:
结论如下:
Imbalanced training data at scales leads to worse (better) accuracy for the minority (majority)
anchor训练样本各个尺度间,正负样本数量均衡很重要,正样本数量越多,性能会更好点;FPN-finest、FPN-finest-stride唯一的差异在于anchor尺度(fig 2(c)、(d)),这样每个anchor尺度上对应的anchor数量不一致,正负样本比例也不一致,scale = 16下,stride一致,anchor数量一致,但table 1中@16对应的性能却不一致(65.6% 、72.2%),原因如fig 2,FPN-finest中@16下正样本数量对比其他尺度比较不足,性能自然比较弱;但在FPN-finest-stride中,@16下正负样本数量都比其他尺度多,性能自然好点;
Similar anchor distribution, similar performance
各个anchor尺度下,正负样本分布比例类似,性能也会类似;FPN、FPN-finest-stride性能接近,二者唯一差异体现在用单层、还是多层feature map做目标检测,从结果上来看,多层feature map上的检测并不能带了性能上的提升,那么另一个问题:是不是各个anchor尺度间,相似的anchor正负样本比例分布,导致了相似的性能?再对比RPN、FPN-finest,二者有一处比较类似:anchor大尺度下,正样本数量比较多,那么对比FPN,在@16下性能都比较弱,但@128下性能都比较强,也同样能说明相似的anchor正负样本数量分布,会有相似的性能;---- 这个例子的解释,我觉得有点牵强;
Data balance achieves better result
各个anchor尺度下,,正负样本分布均衡会带来更好的性能;fig 2中(a) ~ (d)四个算法都存在各个尺度anchor间正负样本分布不均衡的问题,FPN-finest-sampling对比FPN-finest有更均匀的正负样本分布,从table 4中也可以发现性能是更好的;
6.2. Ablation Experiments
The effect of feature map
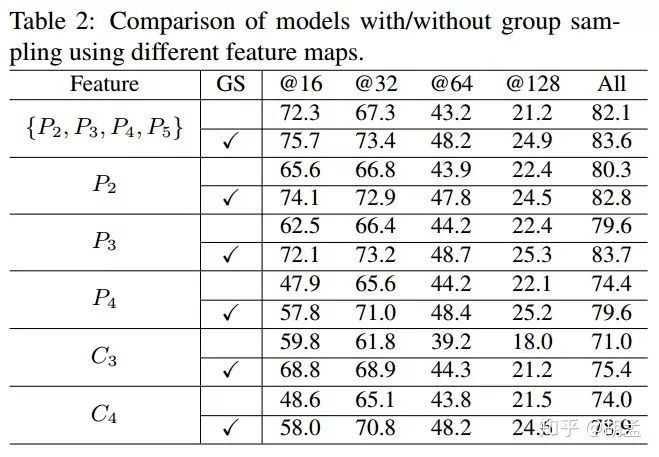
table 2比较了使用不同feature map做人脸检测 + 是否使用group sampling下的性能,结论如下:
1 top down + lateral connection操作对模型性能有提升,从P3 / P4性能优于C3 / C4可知;
2 若使用高分辨率的低层feature map做人脸检测,会生成更多小尺度的训练样本,这有助于小尺度人脸的检测;
3 group sampling对所有feature map上做人脸检测的性能都有提升;本文最终在P2上输出检测结果;
The effect of the number of training samples N

在每个anchor尺度下,随机选择N个训练样本参与模型训练,如fig 4,结论如下:
1 N越大,模型性能越好;
2 N大于2048后,模型性能保持平稳,不再提升;
3 FPN、FPN-finest有点例外,随着N数量增大,性能下降了,原因也很简单,此时正负样本数量更不均衡了;
The effect of the proposed loss
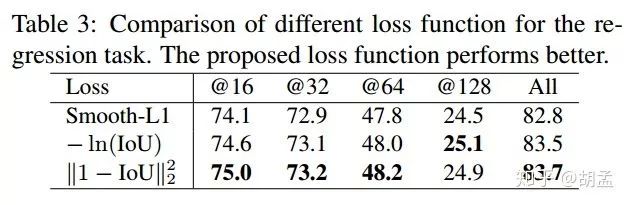
检测器使用FPN-finest-sampling,对比两个经典loss + 本文提出的least square IoU loss,本文提出的loss更牛逼,同时也是因为直接优化的IoU,与评估标准mAP计算依照IoU方式保持一致,后两者性能明显优于Smooth L1 loss;
Comparison with OHEM and Focal Loss
本小节对比OHEM、Focal loss、group sampling三种方案,都用于处理训练数据不平衡;
OHEM:在所有训练样本中,动态选择B个highest loss样本参与模型参数更新,实验中设置B = 1024;
Focal Loss:与原论文保持一致,α = 0.25、γ = 2;
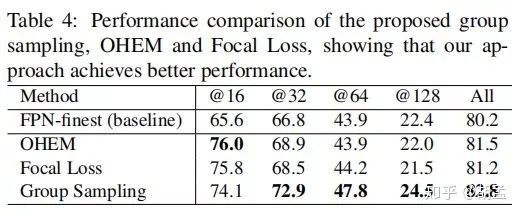
可以发现三者对模型性能提升都有帮助,特别是对小尺度人脸性能提升明显,但group sampling对模型在所有尺度上的性能提升是非常具有持续性和一致性的,最终All上性能也最好的;
6.3. Grouped Fast R-CNN
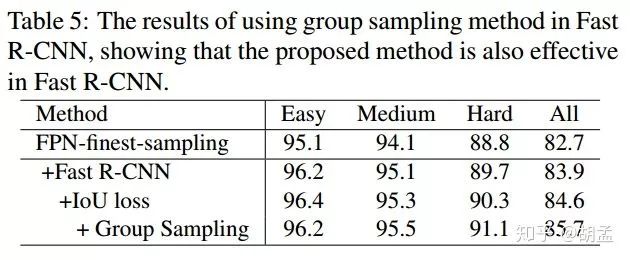
table 5使用FPN-finest-sampling为baseline,可以发现使用Fast R-CNN后性能有所提升,group sampling进一步提升模型性能,并在wider face hard上取得sota,充分说明二者可以完美结合;
7. Comparison with State-of-the-Art
与其他sota在FDDB、wider face上比较一下;
wider face:
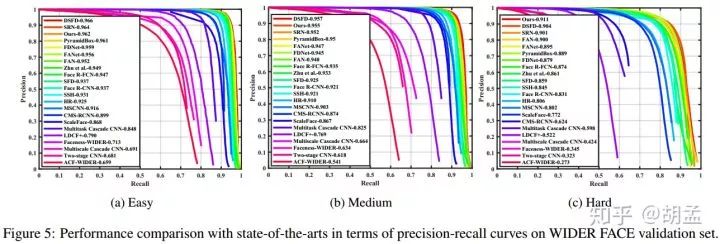
使用group sampling策略训练的模型性能如fig 5,在hard set上领先还是蛮多的;
FDDB:
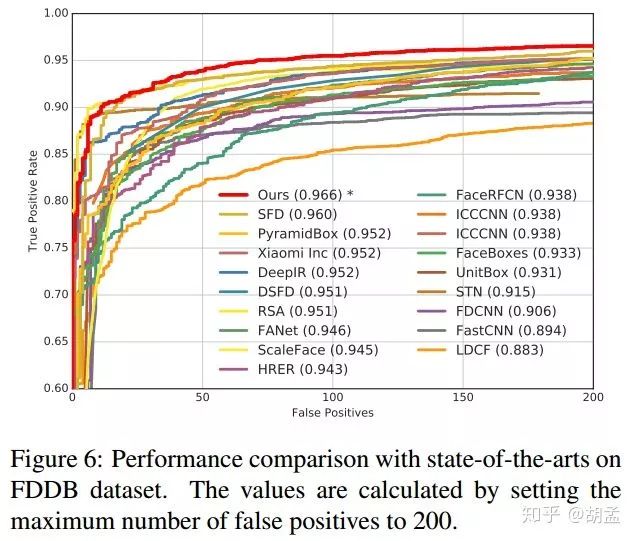
采用S3FD源码中提供的工具,将group sampling模型输出的矩形bbox转换为椭圆形bbox,最终在dis-continuous score上的性能如fig 6,ROC曲线面积最大,是sota;
8. Conclusion
1 本文仔细分析了影响人脸检测性能的因素,发现人脸检测任务中,根本不需要利用多层次的特征金字塔上的多分支检测,仅使用单层feature map做人脸检测也能达到sota,并定位到对于大尺度跨度范围内的人脸,影响检测器的性能之处在于训练样本的不均衡问题,特别是不同人脸尺度上的正负样本均衡问题,才是导致模型性能有无提升的关键;
2 本文提出group sampling策略,将anchors按尺度划分为不同的groups里面,使得训练阶段每个group内正负样本的数量、比例大致是相同的,核心思想可参照4.2小节;
3 文中仅使用FPN最后一层特征(last layer of FPN as features,如fig 1,指的是P2的finest layer),未使用图像 / 特征金字塔,再结合group sampling,就能取得sota,实验 + 分析部分,也能充分证明group sampling能带来性能的提升,最终无需bells and whistles,就在FDDB、wider face上取得了sota;
4 进一步地,将来会继续探索group sampling在通用目标检测器上的有效性;
论文参考
CVPR2019_Group Sampling_Group Sampling for Scale Invariant Face Detection
论文链接:
http://openaccess.thecvf.com/content_CVPR_2019/papers/Ming_Group_Sampling_for_Scale_Invariant_Face_Detection_CVPR_2019_paper.pdf
-End-
*延伸阅读
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~



