普通视频转高清:10个基于深度学习的超分辨率神经网络
作者简介:吴晓然,声网高级视频工程师,专注于视频编解码及相关技术研究,个人技术兴趣包括多媒体架构、深度学习。
在 AlphaGo 对弈李世石、柯洁之后,更多行业开始尝试通过机器学习优化现有技术方案。其实对于实时音视频来讲,对机器学习的研究已有多年,实时图像识别只是其中一种应用。我们还可以利用深度学习来做超分辨率。我们这次就分享一下用于超分辨率的深度学习基本框架,以及衍生出的各种网络模型,其中有些网络在满足实时性方面也有不错的表现。
▌机器学习与深度学习
对于接触机器学习与深度学习较少的开发者,可能会搞不清两者的差别,甚至认为机器学习就是深度学习。其实,我们用一张图可以简单区分这个概念。
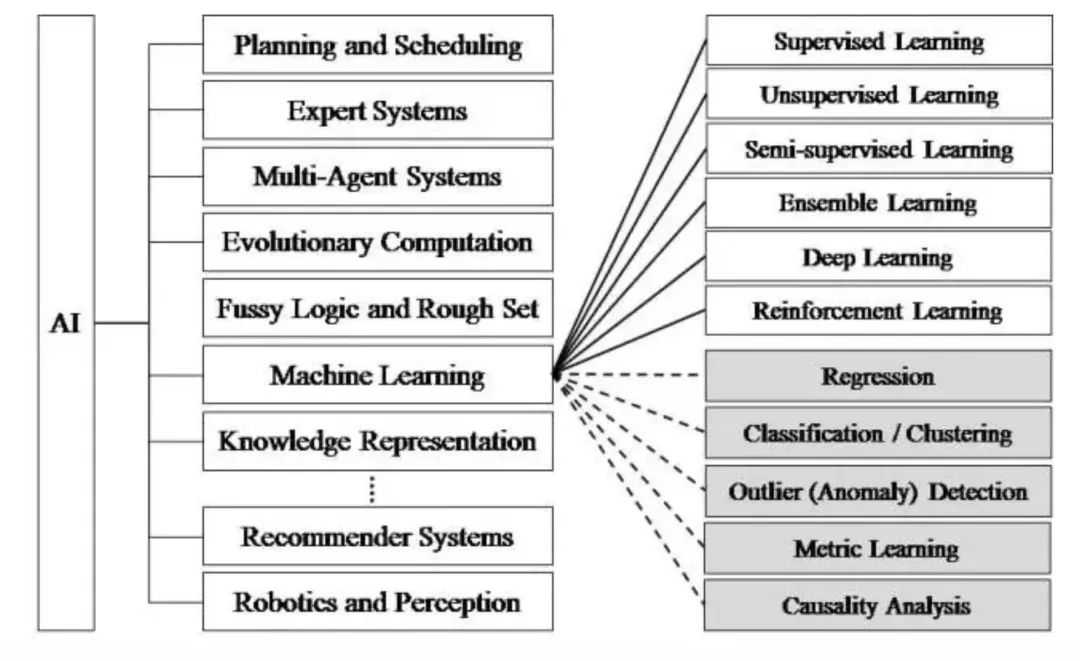
上世纪50年代,就有人工智能的概念,后来也有一些较基础的应用,比如国际象棋。但到了70年代,由于硬件性能的制约,以及训练数据集的匮乏,使得人工智能经历了一段低谷。人工智能包括了很多,比如机器学习、调度算法、专家系统等。到了80年代才开始出现更多机器学习的应用,比如利用算法来分析数据,并进行判断或预测。机器学习包括了逻辑树、神经网络等。而深度学习,则是机器学习中的一种方法,源于神经网络。
▌超分辨率是什么?
超分辨率是基于人类视觉系统提出的概念。1981年诺贝尔医学奖获奖者David Hubel、Torsten Wiesel,发现人类视觉系统的信息处理方式是分层级的。第一层是原始的数据输入。当人看到一个人脸图像时,首先会先识别出其中的点、线等边缘。然后进入第二层,会识别出图像中一些基本的组成元素,比如眼睛、耳朵、鼻子。最后,会生成一个对象模型,也就是一张张完整的脸。
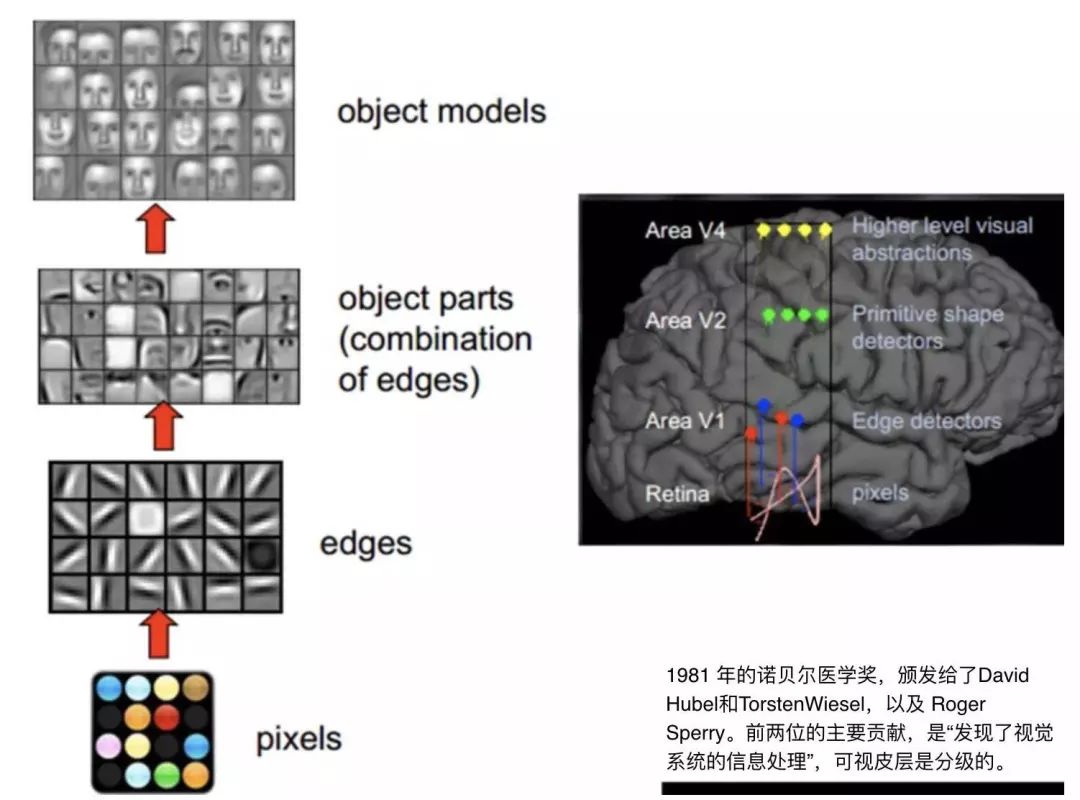
而我们在深度学习中的卷积神经网络(如下图为例),就是模仿了人类视觉系统的处理过程。正因此,计算机视觉是深度学习最佳的应用领域之一。超分辨就是计算机视觉中的一个经典应用。
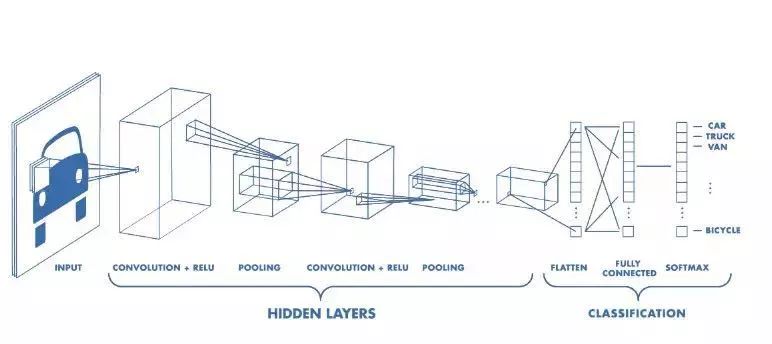
超分辨率是通过软件或硬件方法,提高图像分辨率的一种方法。它的核心思想,就是用时间带宽换取空间分辨率。简单来讲,就是在我无法得到一张超高分辨率的图像时,我可以多拍几张图像,然后将这一系列低分辨率的图像组成一张高分辨的图像。这个过程叫超分辨率重建。
为什么超分辨率可以通过多拍几张图像,就能提高图片分辨率呢?
这牵涉到抖动。我们经常说的拍照防抖动,其实防的是较明显的抖动,但微小的抖动始终存在。在拍摄同一场景的每张图像之间,都有细微差别,这些微小的抖动其实都包含了这个场景的额外信息,如果将他们合并,就会得到一张更为清晰的图像。
有人可能会问,我们手机都能前后置两千万,为什么需要超分辨率技术呢?这种技术应用场景是不是不多?
其实不是。了解摄影的人都知道。在相同的感光元器件上,拍摄的图像分辨率越高,在感光元器件上,单个像素占的面积越小,那会导致通光率越低,当你的像素密度到达一定程度后,会带来大量噪声,直接影响图像质量。超分辨率就可以解决这种问题。超分辨率有很多应用,比如:
数字高清,通过这种方法来提高分辨率
显微成像:合成一系列显微镜下的低分辨率图像来得到高分辨率图像
卫星图像:用于遥感卫星成像,提升图像精度
视频复原:可以通过该技术复原视频,例如老电影
但是,有很多情况下,我们只有一张图像,无法拍摄多张,那么如何做超分辨率呢?这就需要用到机器学习了。比较典型的例子,就是在2017年Google 提出的一项“黑科技”。他们可以通过机器学习来消除视频图像中的马赛克。当然,这项黑科技也有一定限制,以下图为例,它训练的神经网络是针对人脸图像的,那么如果你给的马赛克图像不是人脸,就无法还原。

▌超分辨率神经网络原理
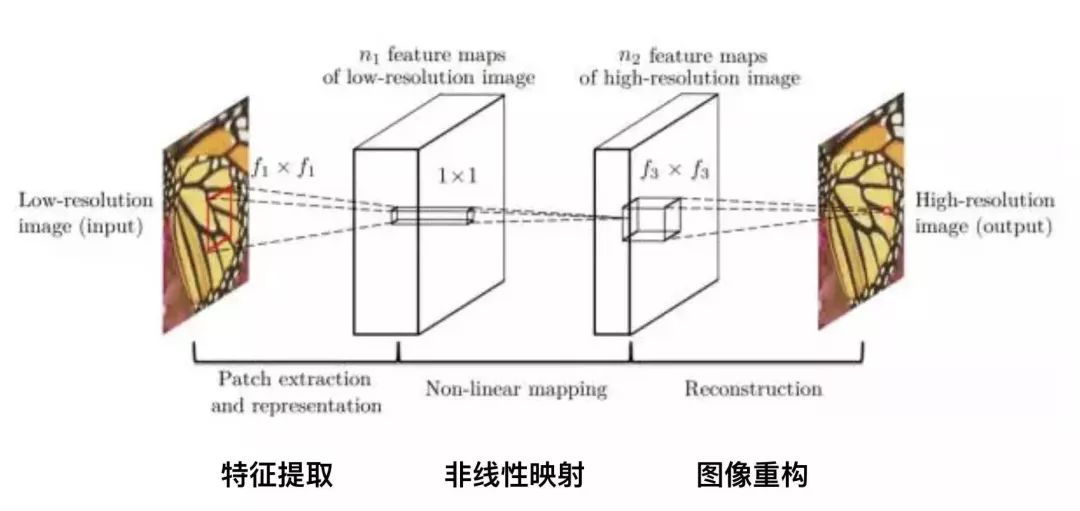
超分辨率神经网络(Super-Resolution CNN,SRCNN)是深度学习应用在超分辨率领域的首个模型。原理比较简单。它有三层神经网络,包括:
特征提取:低分辨率图像经过二项式差值得到模糊图像,从中提取图像特征,Channel 为3,卷积核大小为 f1*f1,卷积核个数为 n1;
非线性映射:将低分辨率图片特征映射到高分辨率,卷积核大小1*1;
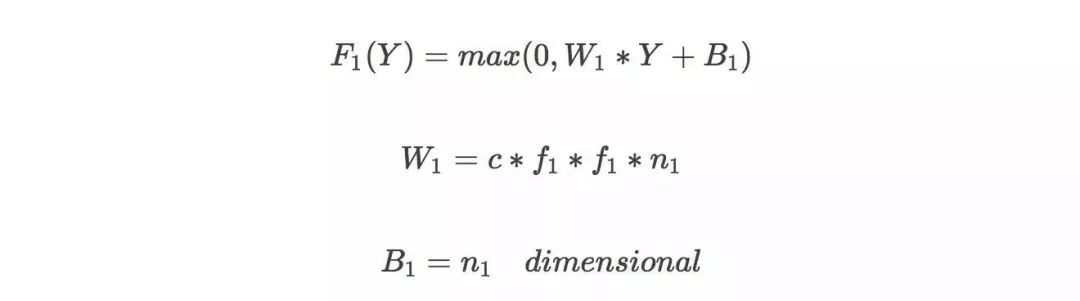
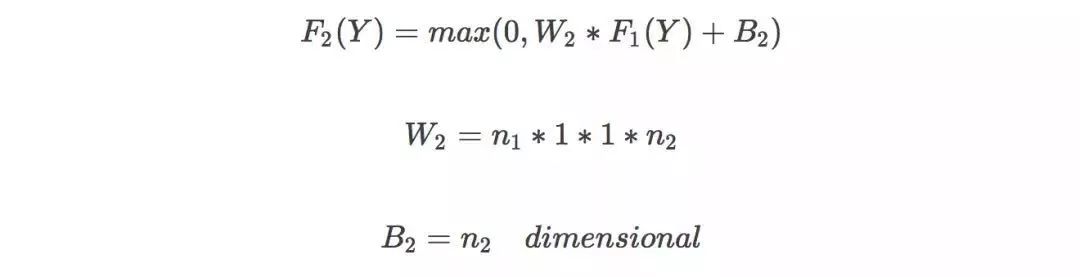
图像重构:恢复细节,得到清晰的高分辨率图像,卷积核为f3*f3;
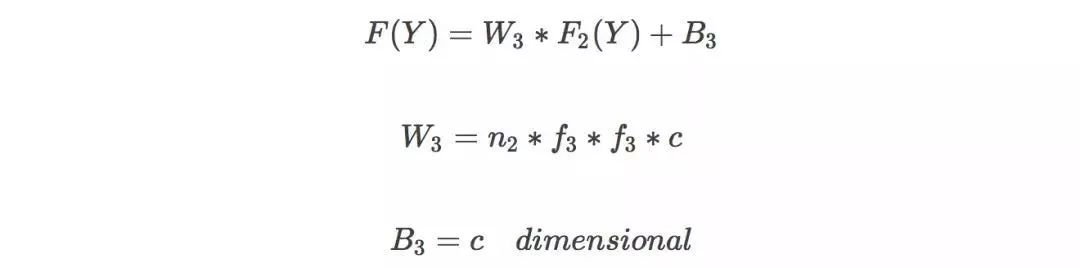
参数调节是神经网络中比较玄的部分,也是最为人诟病的部分。很多人认为参数调节很像老中医看病,通常缺少理论依据。在这里列出了几个在 n1 取不同值的时候,所用的训练时间和峰值信噪比(PSNR,用于判断图片质量的参数,越高越好)。

在训练中,使用均方误差(Mean Squared Error, MSE)作为损失函数,有利于获得较高的PSNR。
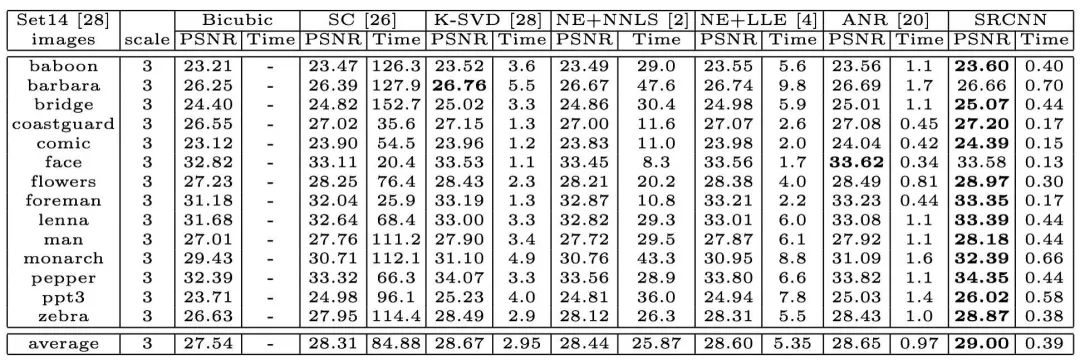
训练结果如何呢?在下表中,列出了几个传统方法与 SRCNN 方法的结果对比。最左一列是图片集,右侧分别列出了每个方法的所用训练时间和图片峰值信噪比。可以看出,尽管有些图片,传统方法得出的结果更优于深度学习,但是总体来讲,深度学习稍胜一筹,甚至所需时间更短。
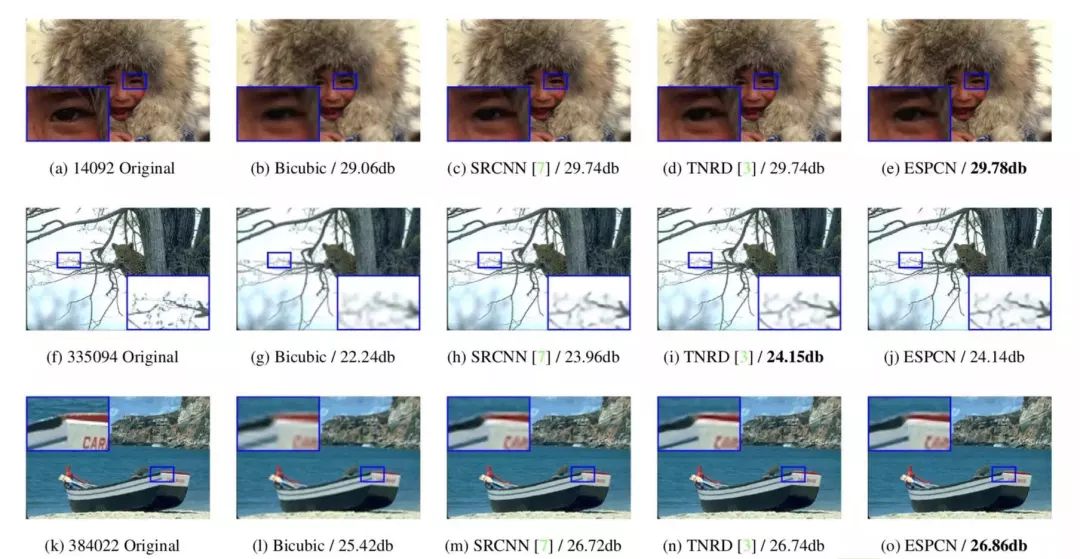
有人说一图胜千言。那么实际图片效果如何呢?我们可以看下面两组图片。每组第一张是小分辨率的原图,后面通过不同的方法来实现高分辨率的大图。相比传统方法,SRCNN 的图片边缘更加清晰,细节恢复的更好一些。以上就是最初的超分辨率的深度学习模型。

▌9个超分辨率神经网络模型
SRCNN 是第一个超分辨率的神经网络模型。在 SRCNN 这个模型出现后,更多应用于超分辨率的神经网络模型。我们以下分享几个:
FSRCNN
相对 SRCNN,这个方法不需要对原始图片使用二项式差值,可以直接对小分辨率图像进行处理。在提取特征值之后,缩小图片,然后经过 mapping、expending、反卷积层,然后得到高分辨率图片。它好处是,缩小图片可以降低训练的时间。同时,如果你需要得到不同分辨率的图片,单独训练反卷积层即可,更省时。
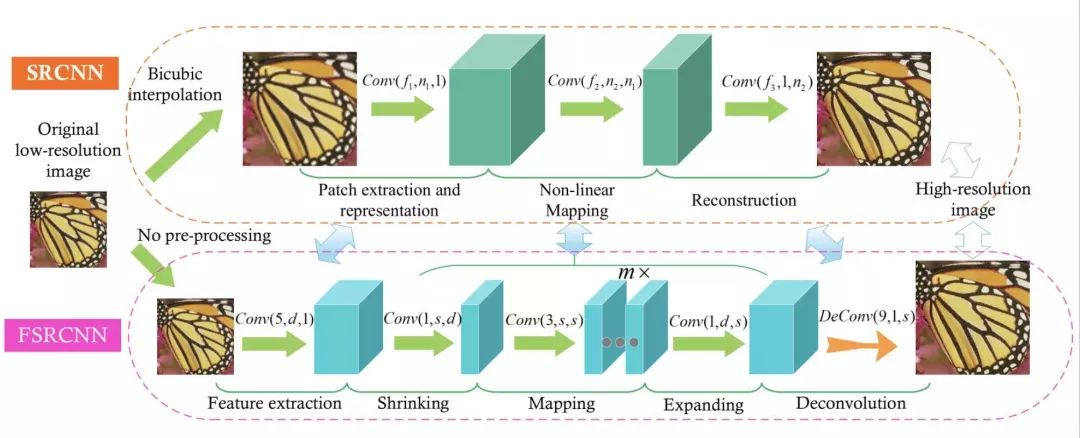
ESPCN
这个模型是基于小图进行训练。最后提取了 r² 个 Channel。比如说,我想将图片扩大到原图的3倍,那么 r 就是缩放因子 3,Channel 为9。通过将一个像素扩充为一个3x3的矩阵,模拟为一个像素的矩阵,来达到超分辨率的效果。
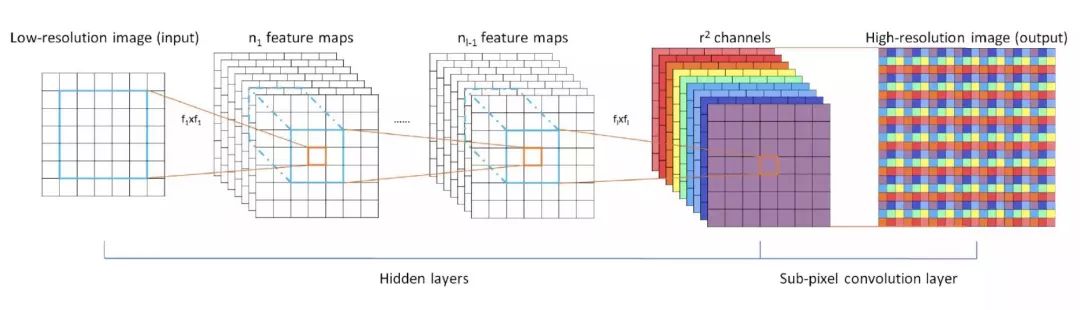
对实时视频进行超分辨率处理的实验结果也非常理想。对 1080 HD 格式的视频进行3倍放大,SRCNN 每帧需要0.435s,而 ESPCN 则只需0.038s。
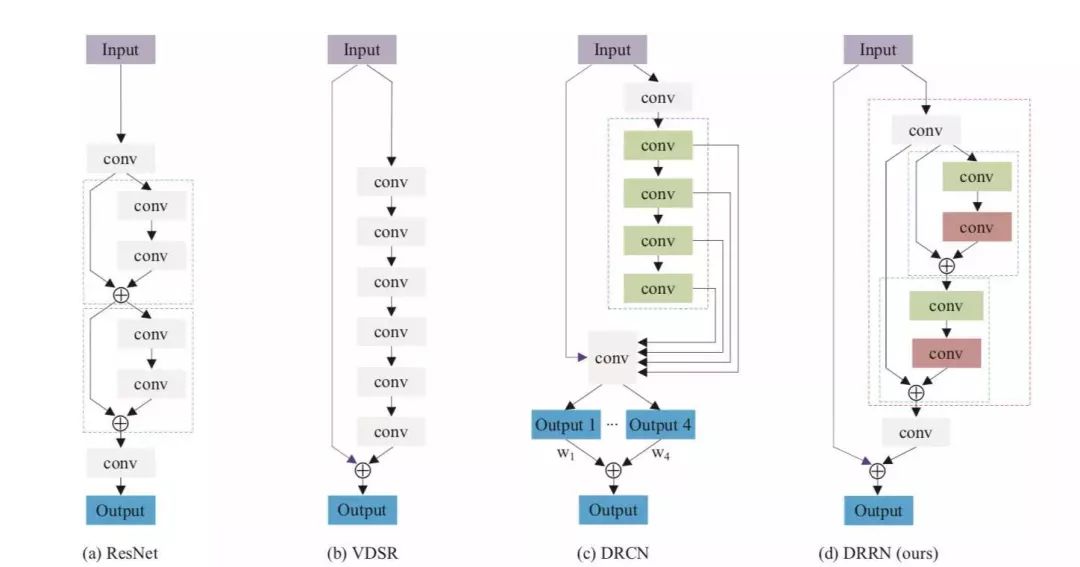
VDSR
这是2016年获奖的一个模型。我们做视频编解码的都知道,图像之间是存在残差的。它认为原始的低分辨率图片与高分辨率图片之间,低频分量几乎一样,缺失的是高频分量,即图片细节。那么训练的时候,只需要针对高频分量进行训练就行了。
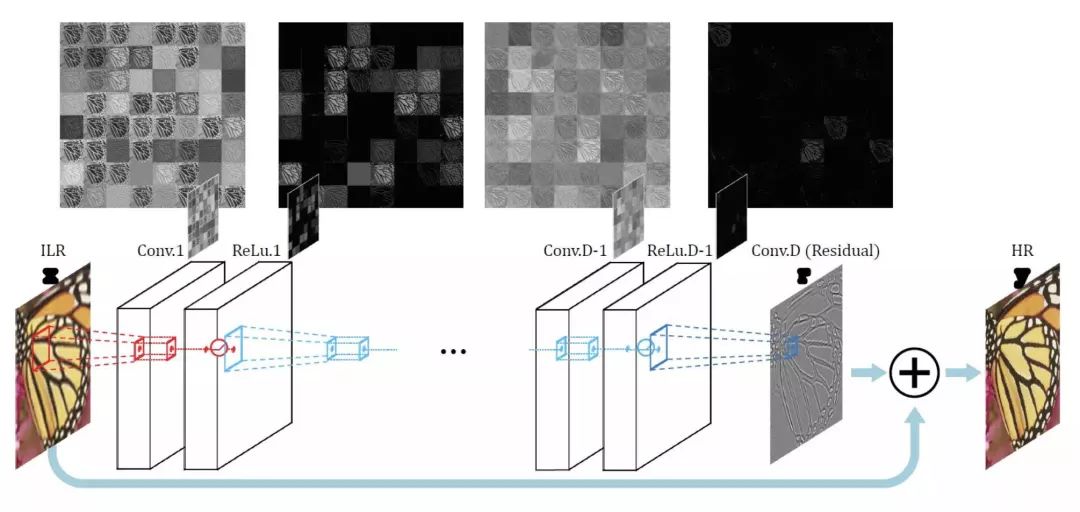
所以它的输入分为两部分,一是将整张原图作为一个输入,另一部分则是对残差进行训练然后得到一个输入,将两者加起来就得到一张高分辨率图像。这样就大大加快了训练速度,收敛效果也更好。
DRCN
它还是分为三层。但是在非线性映射这一层,它使用了一个递归网络,也就是说,数据循环多次地通过该层。将这个循环展开的话,等效于使用同一组参数的多个串联的卷积层。
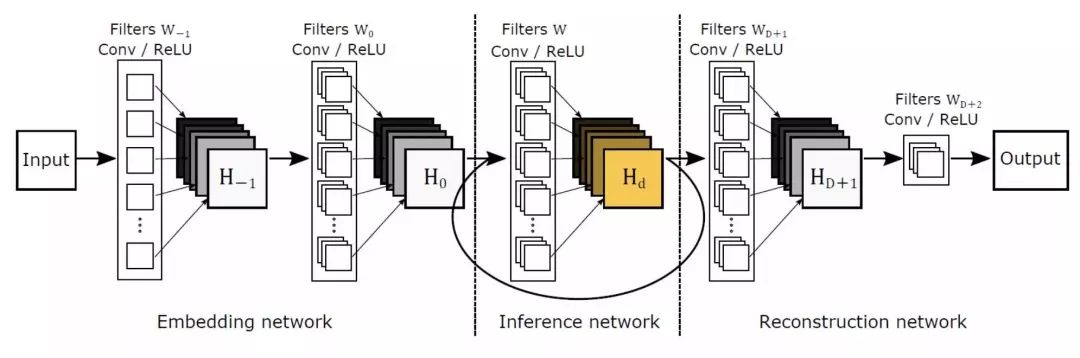
RED
每一个卷积层都对应一个非卷积层。简单来讲,可以理解为是将一张图片进行了编码,然后紧接着进行解码。它的优势在于解决了梯度消失的问题,而且能恢复出更干净的图片。它和 VDSR 有相似的思路。中间卷积层与反卷积层的训练是针对原始图片与目标图片的残差。最后原图会与训练输出结果相加,得到高分辨率的图片。
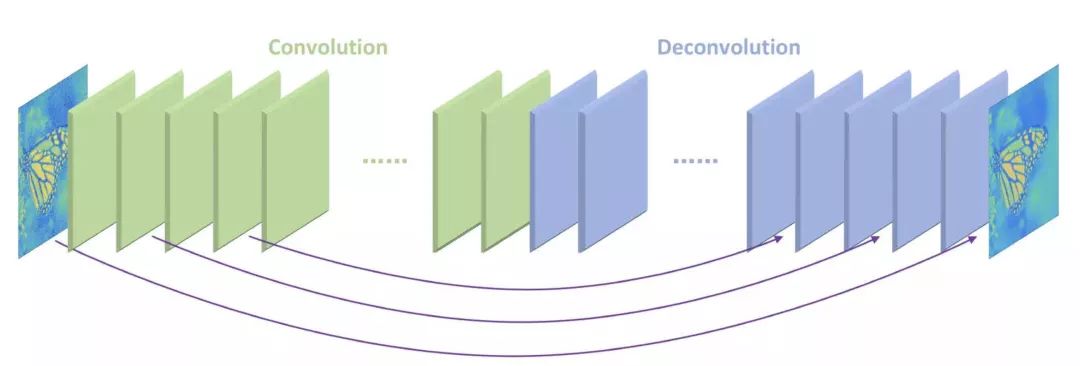
DRRN
在这个模型里你可以看到DRCN、VDSR的影子。它采用了更深的网络结构来提升性能。其中有很多个图片增强层。可以理解为,一张模糊的图片,经过多个增强层,一级级变得更加清晰,最终得出高清图片。大家可以在名为tyshiwo的 Github 上找到源码。
LapSRN
LapSRN 的特别之处在于引入了一个分级的网络。每一级都只对原图放大两倍,然后加上残差获得一个结果。如果对图片放大8倍的话,这样处理的性能会更高。同时,在每一级处理时,都可以得到一个输出结果。
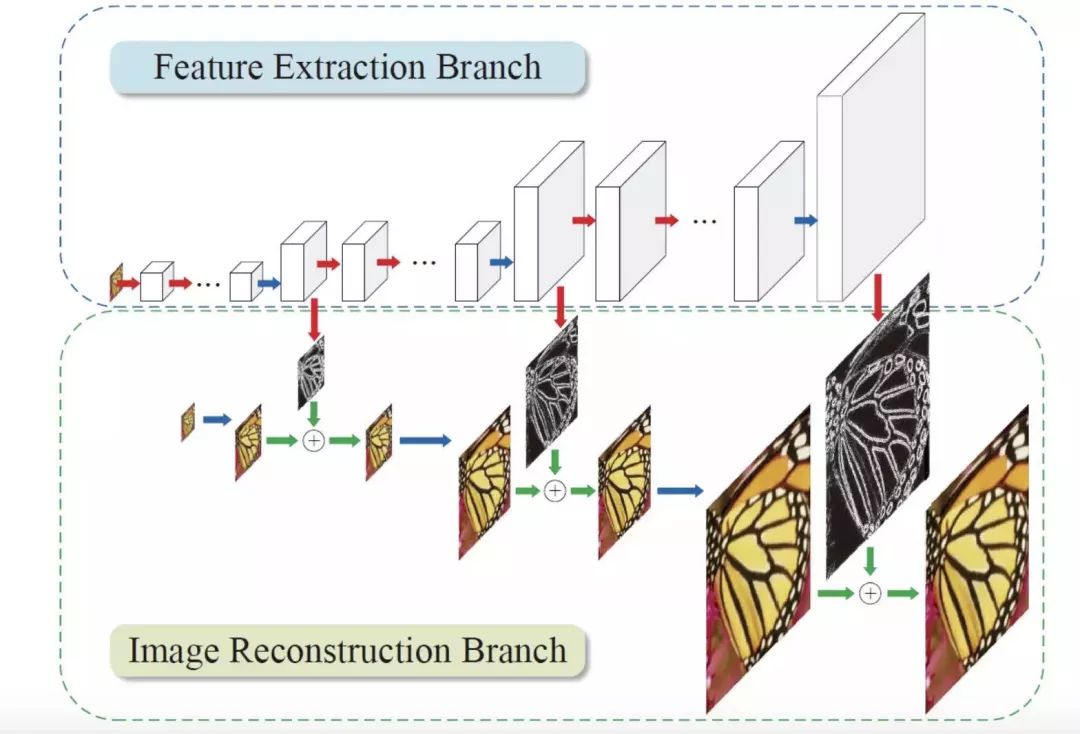
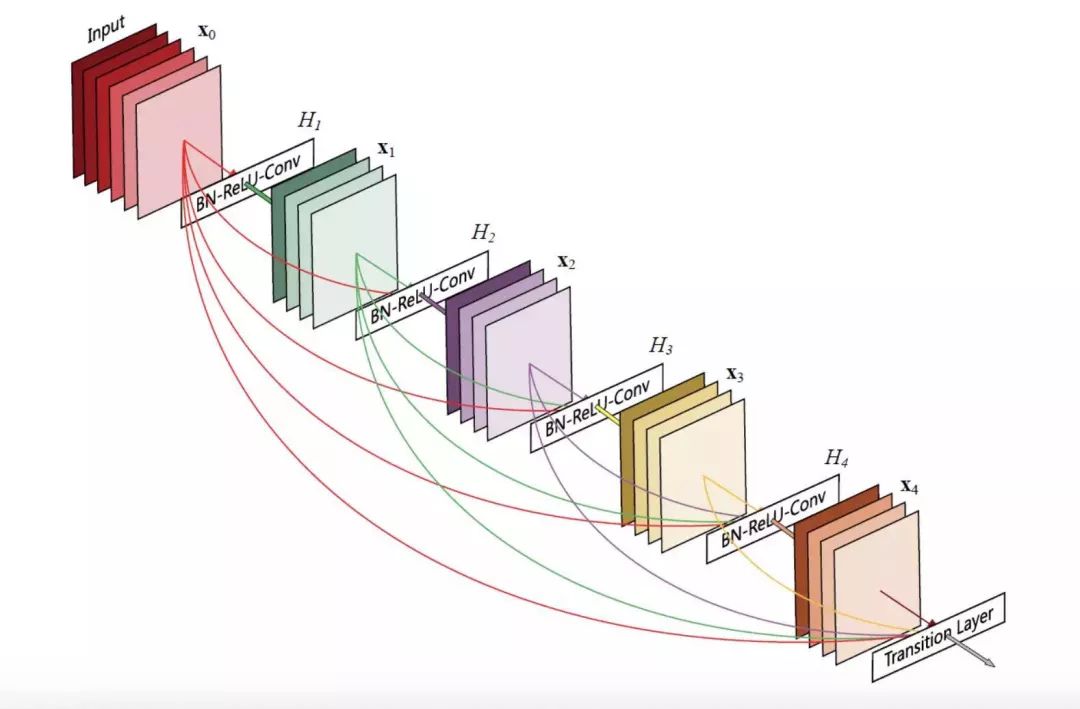
SRDenseNet
它引入了一个 Desent Block 的结构。上一层网络训练出的特征值会传递到下一层网络,所有特征串联起来。这样做的好处是减轻梯度消失问题、减少参数数量。而且,后面的层可以复用之前训练得出的特征值,不需要重复训练。
SRGAN
它可以利用感知损失(perceptual loss)和对抗损失(adversarial loss)来提升恢复出的图片的。

在这个模型中有两个网络,一个是生成网络,另一个是判别网路,前者会生成高分辨率图片,后者则会判断这张图是否是原图,如果结果为“否”,那么前者会再次进行训练、生成,直到可以骗过判别网络。
以上这些神经网络模型都可以应用于视频处理中,但实际应用还需要考虑很多因素,比如系统平台、硬件配置、性能优化。其实,除了超分辨率,机器学习与实时音视频有很多可结合的应用场景,比如音视频体验优化、鉴黄、QoE 改进等。
*推荐文章*
漫谈深度学习在Super Resolution(超分辨率)领域上的应用
看得“深”、看得“清” —— 深度学习在图像超清化的应用
CV 届的金鸡百花奖:盘点我心中的 CVPR 2018 创意 TOP10
PS.极市平台诚招计算机视觉算法工程师啦~工作要求请关注“极市平台”公众号(id:extrememart),点击菜单加入极市“诚招”栏或直接私信小助手(微信:Extreme-Vision),欢迎大牛来戳~



