学界 | KDD 2018:滴滴提出WDR模型显著提升ETA预测精度
AI 科技评论按:国际数据挖掘领域的顶级会议 KDD 2018 在伦敦举行,今年 KDD 吸引了全球范围内共 1480 篇论文投递,共收录 293 篇,录取率不足 20%。其中滴滴共有四篇论文入选 KDD 2018,涵盖 ETA 预测 ( Estimated Time of Arrival, 预估到达时间) 、智能派单、大规模车流管理等多个研究领域。
四篇论文分别是(文末附论文打包下载地址)
Efficient Large-Scale Fleet Management via Multi-Agent Deep Reinforcement Learning
Kaixiang Lin (Michigan State University); Renyu Zhao (AI Labs, Didi Chuxing); Zhe Xu (AI Labs, Didi Chuxing); Jiayu Zhou (Michigan State University)
Multi-task Representation Learning for Travel Time Estimation
Yaguang Li (University of Southern California); Kun Fu (DiDi AI Labs); Zheng Wang (DiDi AI Labs); Cyrus Shahabi (University of Southern California); Jieping Ye (DiDi AI Labs); Yan Liu (University of Southern California)
Large-Scale Order Dispatch in On-Demand Ride-Sharing Platforms: A Learning and Planning Approach
Zhe Xu (AI Labs, Didi Chuxing); Zhixin Li (AI Labs, Didi Chuxing); Qingwen Guan (AI Labs, Didi Chuxing); Dingshui Zhang (AI Labs, Didi Chuxing); Qiang Li (AI Labs, Didi Chuxing); Junxiao Nan (AI Labs, Didi Chuxing); Chunyang Liu (AI Labs, Didi Chuxing); Wei Bian (AI Labs, Didi Chuxing); Jieping Ye (AI Labs, Didi Chuxing)
Learning to Estimate the Travel Time
Zheng Wang (Didi Chuxing); Kun Fu (Didi Chuxing); Jieping Ye (Didi Chuxing)
本文是对滴滴 KDD 2018 Poster 论文《Learning to Estimate the Travel Time》的详细解读,在这篇文章中,滴滴技术团队设计了一种使用深度神经网络来预测预估到达时间(ETA)的方案,通过将 ETA 建模成一个时空回归问题,构建了一个丰富有效的特征体系,进一步提出 Wide-deep-recurrent(WDR)模型,能在给定出发时间和路线的情况下更加准确地预测。这一事件在雷锋网学术频道 AI 科技评论旗下数据库项目「AI 影响因子」中有相应加分。

从规则模型到完整的机器学习方案
ETA 是智能交通和位置信息服务(Location Based Service,LBS)中至关重要、又极具复杂性和挑战性的问题。它不仅需要考虑交通系统的空间特性,比如途径红绿灯的个数、道路的限速、是否可以绕远走快速路;还要考虑交通系统的时间特性,比如早晚高峰的规律性拥堵和交通事故导致的偶发性拥堵等。同时,因为交通系统的运行需要人和车作为主体来参与,也少不了外部因素的影响,因此时间预估问题还需要引入对个性化特征和外部特征的建模,比如司机驾驶习惯、雨天雾天对行车速度的干扰等。
在滴滴平台,ETA 是一项必不可少的基础服务。无论是行程前的预估接驾时间、预估价格显示,还是派单、调度、拼车等系统决策,亦或是行程中的预计到达终点的时间计算等,离不开高精度 ETA 的辅助。滴滴每天有约 700 亿次的 ETA 请求,峰值时每秒要处理约 400 万次。
用规则模型计算 ETA 是此前地图行业通用做法之一。即分别计算各段路的行驶时间,全部加起来再根据红绿灯时间做一个偏移修正。用数学来描述,预估时间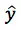
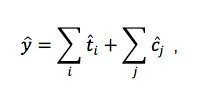
其中,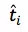
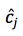
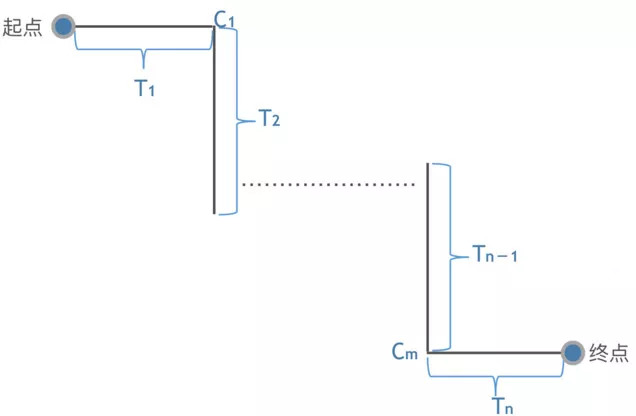
这是完全根据物理结构构建起来的模型,而其中最关键的部分在于每一路段的时间和每一个红绿灯时间的获取。考虑到路段的通行状态每时每刻都在动态变化,一个比较实际的做法是利用最新的历史数据(比如,刚刚过去的 5 分钟)来估计路段的实时通行时间,而把历史平均通行时间作为默认值来填充信息缺失的路段(若一个路段在最近没有滴滴车辆经过,此时它的通行状态是未知的)。红绿灯亦可采用类似的做法从数据中去挖掘每个红绿灯的历史平均等待时间,用作
规则模型虽然在线服务计算量小,易于实现,但其使用大量基于经验和直觉的人为规则,不仅缺乏科学的探索方法;局限多、扩展差,也容易遗漏了很多重要信息,比如个性化特征等;此外,简单的统计量也不足以分析出复杂的交通模式,核心指标往往容易面临瓶颈,无法再靠添加新规则进行优化。
为了更好地发挥海量出行数据的潜力,滴滴于 2015 年首创了一整套机器学习系统来解决 ETA 问题。从类型上看,ETA 是一个很典型的回归问题:给定输入特征,模型输出一个实数值,代表了预测的行程时间。滴滴探索和构建了一套系统的地图领域的特征和表达集合,包括空间信息、时间信息、交通信息、个性化信息、扩展信息等几个方面,能充分考虑连通起点和终点的全部路径、涉及的路段、路口和红绿灯,以及所经过区域的 POI、行程对应的时间属性、实时路况、司机的驾车行为以及天气、交通管制情况等。
考虑到用户对误差的敏感程度更多的和相对值有关,滴滴将 MAPE(mean absolute percentage error)选择为目标函数,对应于 MAPE 的优化问题为:
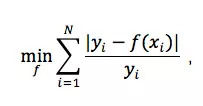
其中,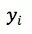
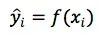
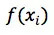
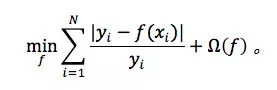
而在回归模型上,滴滴先后考虑过两种在业界比较流行的模型,Tree Based model 和 Factorization Machine。其中,树模型的最终输出是多棵树的集成结果,可以写成:
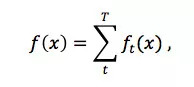
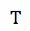
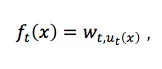
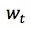
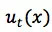
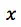
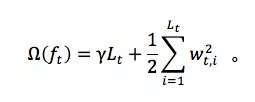
直观来看,第一项对叶子节点的数目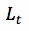
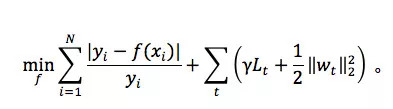
而 FM 模型的核心思路是将特征交互的权重矩阵进行分解,表达为向量内积的形式,以此来减少参数数量。二阶 FM 的计算为
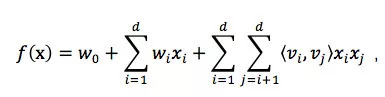
其中 d 是特征维度,通常在千万级别甚至更高。而参数向量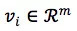
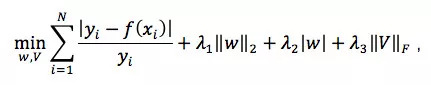
其中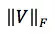
Wide-Deep-Recurrent 模型进一步提升精度
虽然这一完整的机器学习解决方案,为滴滴带来了显著的 ETA 准确度提升,但由于大部分回归模型比如 XGBoost,能够接收的输入向量必须是固定长度的,而一段行程对应的路段(以下称为 link)数变动范围很大,因此在实际使用时,舍去了 link 级的特征,取而代之使用整体统计值。所以在细节信息层面,这一解决方案还有优化的空间。
为了最大化信息的无损,保留模型对 link 序列信息的建模能力,滴滴创新地将深度学习应用到 ETA 上。这一 ETA 模型的核心思路是 global model + recurrent model。其中 global model 的作用类似于上一代模型,针对行程的全局信息进行学习;而 recurrent model 则专注于对 link 序列等局部细节的学习。
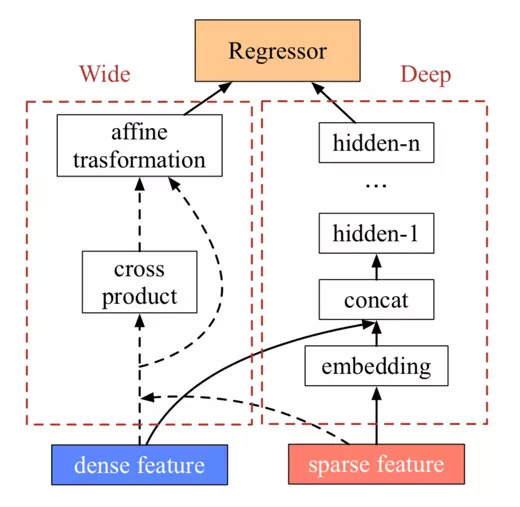
在 global model 部分滴滴考虑了近年来在推荐系统领域受到关注的 Wide & Deep 模型,以保证所有模块都可以进行端到端的训练。其 Wide 分支其实和 FM 是源出一脉的,对特征进行二阶交叉,对历史数据拥有一定的记忆功能。而它的 Deep 分支就是传统的多层感知机结构,有较好的泛化能力。两个分支强强联手,能互取所长。
WD 模型的大体结构如下图所示:
Recurrent model 的选择则比较丰富,不仅仅限于 RNN(包括变种 GRU、LSTM、SRU 等),还可以是一维卷积 CNN,或者是纯粹的 Attention model。以最流行的 LSTM 为例,它通过引入 additive memory 和 gate 来缓解简单 RNN 的梯度消失问题:
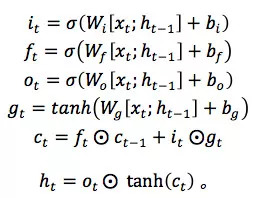
将它和 WD 模型组合之后,就得到了 Wide-Deep-Recurrent model (WDR)。结构见下图:
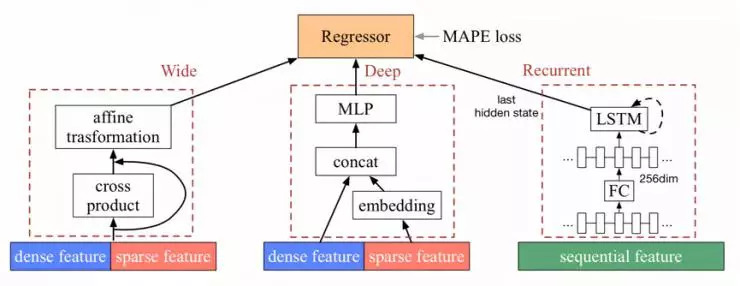
可以看到,这一模型总共有三类特征:
Dense feature:行程级别的实数特征,比如起终点球面距离、起终点 GPS 坐标等。
Sparse feature:行程级别的离散特征,比如时间片编号、星期几、天气类型等。
Sequential feature:link 级别的特征,实数特征直接输入模型,而离散特征先做 embedding 再输入模型。注意,这里不再是每个行程一个特征向量,而是行程中每条 link 都有一个特征向量。比如,link 的长度、车道数、功能等级、实时通行速度等。
其中,Wide 和 Deep 模块对行程的整体信息进行建模,而 Recurrent 模块对行程的轨迹进行细致的建模,可以捕捉到每条 link、每个路口的信息。在最终汇总时,Wide 模块通过仿射变换把输出变到合适维度,Deep 模块直接把顶层 hidden state 作为输出,而 Recurrent 模块将 LSTM 的最后一个 hidden state 作为输出。三个模块的输出向量被拼接起来,进入最终的 Regressor 进行预测,得到 ETA 值。全部参数都基于 MAPE loss 做梯度下降来训练。
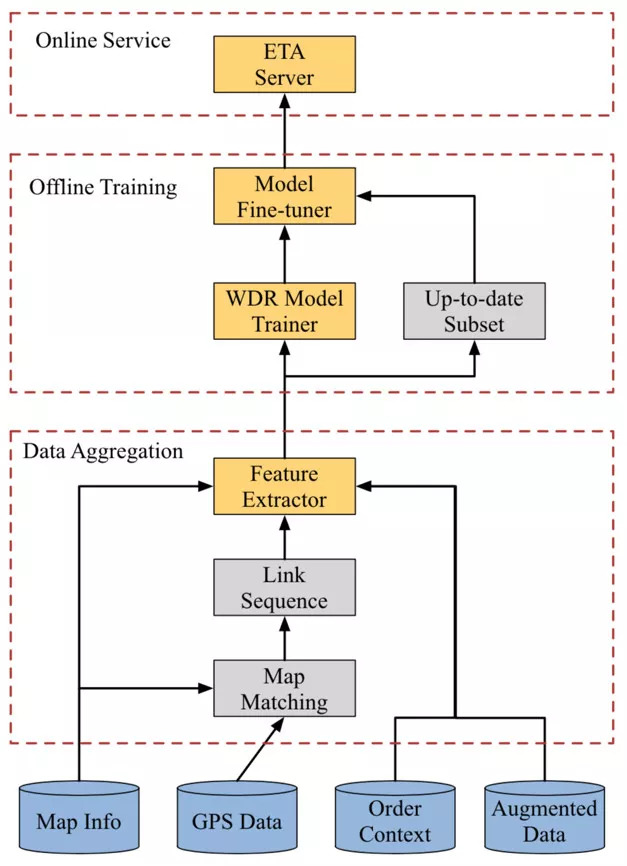
系统架构如下图所示。最底层为数据源,分别是地图信息、GPS 轨迹、订单记录和其它必要的附加信息。然后,原始数据经过特定的处理,变为模型可用的格式,用于训练模型。注意这里有一个小分支,表示在训练完成之后还单独取出了一小批 up-to-date 数据进行 finetune,使得模型更倾向于最新收集的数据。线下训练好的模型,最后被推送到线上系统,对外服务。
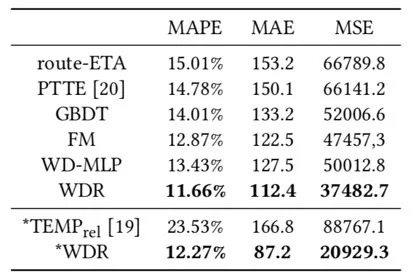
线下实验中,滴滴对 2017 年前五月北京滴滴平台的数据进行了适当的过滤,发现无论是 pickup(司机去接乘客)还是 trip(司机送乘客前往目的地),其 WDR 模型有较大幅度的提升。
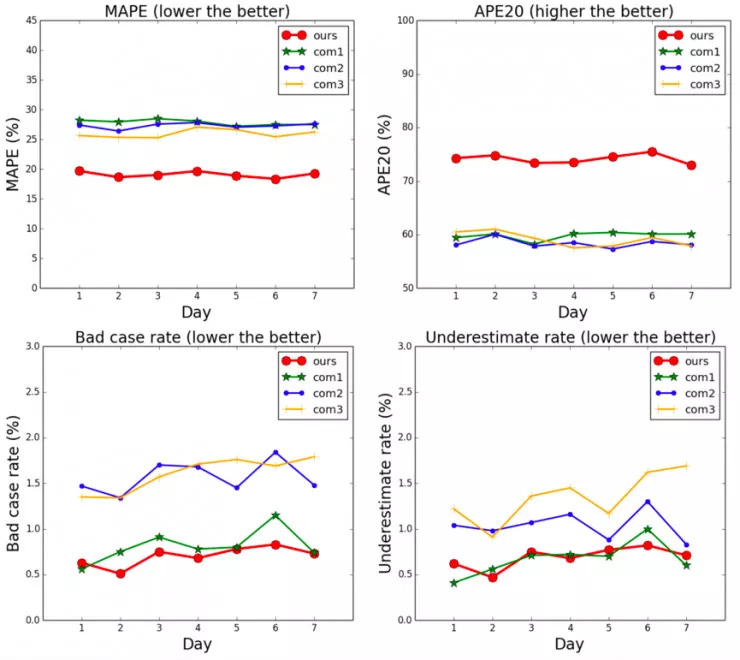
滴滴也进行了为期一周的线上评估,从曲线可以看到,其模型在线上实际系统中也有着领先的性能。
滴滴团队指出,虽然其 WDR 模型能进行更准确的预测,但仍然有很多问题需要进一步地探索,比如怎样引入路网的拓扑图结构,如何与路径规划进行融合,如何将路况算法与 ETA 联合起来进行端到端的学习,如何预测时间区间而不是单个时间,如何提高线上系统的服务性能等,然是需要深入研究的课题。
(论文地址:Learning to Estimate the Travel Time
http://www.kdd.org/kdd2018/accepted-papers/view/learning-to-estimate-the-travel-time)
或点击阅读原文移步AI研习社社区下载四篇论文。





