全国知识图谱与语义计算大会竞赛冠军DeepBlueAI团队技术分享!

全国知识图谱与语义计算大会(CCKS 2020) 11月12日至15日在江西南昌举行,CCKS是(China Conference on Knowledge Graph and Semantic Computing)由中国中文信息学会语言与知识计算专委会定期举办的全国年度学术会议。
CCKS已经成为国内知识图谱、语义技术、语言理解和知识计算等领域的核心会议。CCKS 2020举办的各项挑战赛公布了最终结果,来自深兰科技北京AI研发中心的DeepBlueAI团队斩获了3项冠军和1项亚军,并获得了一项技术创新奖。

我们可以通过这篇文章了解下DeepBlueAI 团队在『新冠知识图谱构建与问答评测(一)新冠百科知识图谱类型推断』赛题中的解决方案。
赛题介绍
比赛任务
-
entity.txt:需要进行类型预测的所有实体,其中包含相关实体和噪音实体。 -
entity_pages_1.xml,entity_pages_2.xml,entity_pages_3.xml,entity_pages_4.xml:分别来自百度百科,互动百科,中文维基百科,医学百科的实体页面内容。保证 entity.txt 中的任意实体至少被一个页面文件所涵盖。实体页面文件中包含类型推断可能会用到的名称、标签、简介等信息。此处还可以使用其他公开数据集。 -
type.txt:包含 7 个目标类型,分别是病毒、细菌、疾病、药物、医学专科、检查科目、症状(非目标类型输出为 NoneType)。
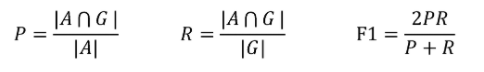
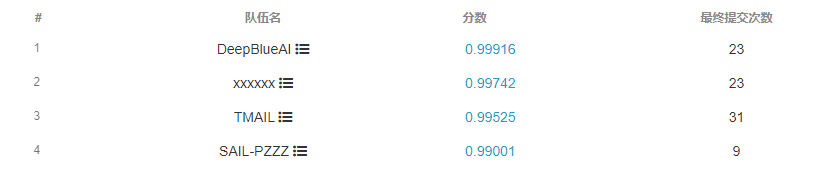
团队成绩
比赛难点
-
实体文本较短。给定实体平均长度为7;实体文本较短导致缺乏足够的信息,很多实体类型难以确定,其中真菌细菌名称近似,十分难以区分。 -
同一实体可能属于多个类型。同一实体在不同的百科数据中属于不同的类别,但最终只需要一个类别,训练集中如何确定其类别会影响测试集中的偏向。 -
类别不平衡。7个类别中,症状、疾病、药物占了大多数,其余类别对应的实体极少。
竞赛方案
数据处理
模型
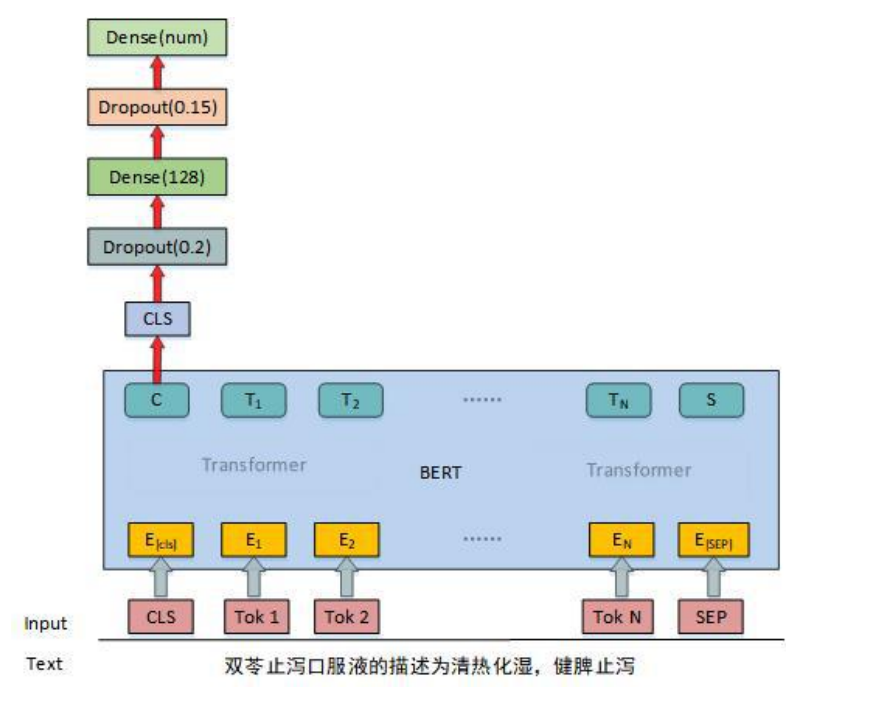 图1
图1
-
描述文本融入。 测试集中很多实体没有对应的文本,为了解决这个问题,在训练时,同时使用了仅实体和实体+描述两种输入,这样一来,对每一个实体,我们构造了两个样本。只使用实体作为输入时,可以训练模型有效的提取关键字信息;使用描述文本时,可以引入额外信息;通过这样的样本构建方式,也相当于做了数据增强,增加了训练集数据量。 -
对抗学习。 它在训练中构造了一些对抗样本加入到原数据集中,希望增强模型对对抗样本的鲁棒性。我们在模型训练的时候加入了对抗学习,所使用的对抗学习方法是 Fast Gradient Method(FGM)。 -
多模型融合。 针对数据集的特点,我们设计了3个模型,一个多分类模型,一个NoneType分类模型,一个细菌真菌分类模型。每个模型使用5折交叉验证,最终结果取平均。再对三个模型做人工规则融合。
补充信息引入
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
类别不均衡解决
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
后处理
比赛结果
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
总结与讨论
参考文献:


点击阅读原文,直达ICLR小组!
登录查看更多
相关内容
专知会员服务
36+阅读 · 2020年4月14日
Arxiv
0+阅读 · 2021年1月30日
Arxiv
4+阅读 · 2018年6月25日
Arxiv
3+阅读 · 2018年5月31日



相关VIP内容
专知会员服务
36+阅读 · 2020年4月14日
相关资讯
相关论文
Arxiv
0+阅读 · 2021年1月30日
Arxiv
4+阅读 · 2018年6月25日
Arxiv
3+阅读 · 2018年5月31日