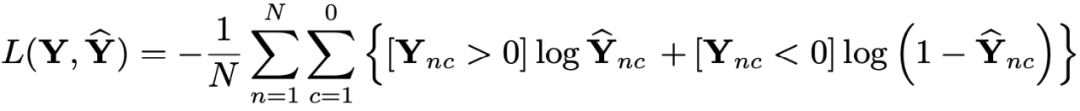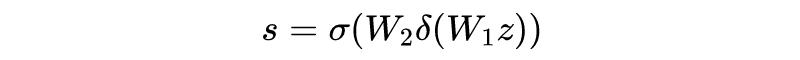引言
区域学习(RL)和多标记学习(ML)在人脸动作单元(AU)检测领域受到越来越多的关注。由于 AUs 在面部稀疏区域是活跃的,RL 旨在识别这些区域以获得更好的特异性。另一方面,一个关于 AU 相关性的强有力的统计证据表明 ML 是一种自然的方法来模拟探测任务。
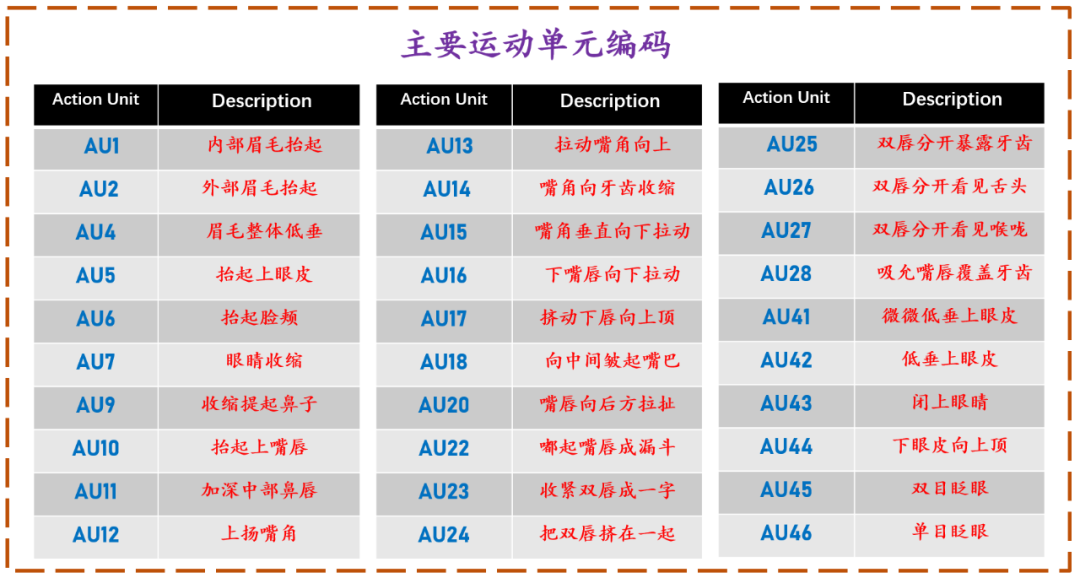
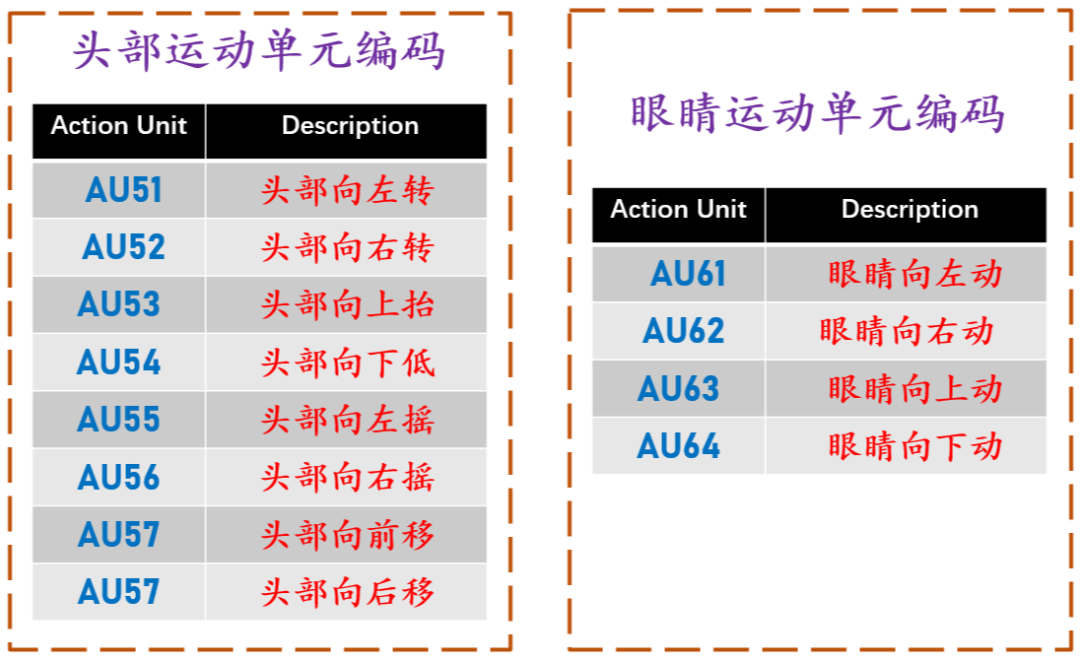
FACS (Facial Action Coding System) 即面部行为编码系统,它特指一组面部肌肉运动状态。本文整理的是第一次出版于 1978 年的 FACS,在2002 年 FACS 又进行了一些实质性的更新。通过使用面部行为编码系统可以对情绪进行分析。本文详细的整理了面部行为编码对应的编号,主要可以分为三大类主要运动单元编码,头部运动单元编码和眼睛运动单元编码,如下图([FC])和([HE])所示。
▲ 图2.头部和眼睛运动单元编码
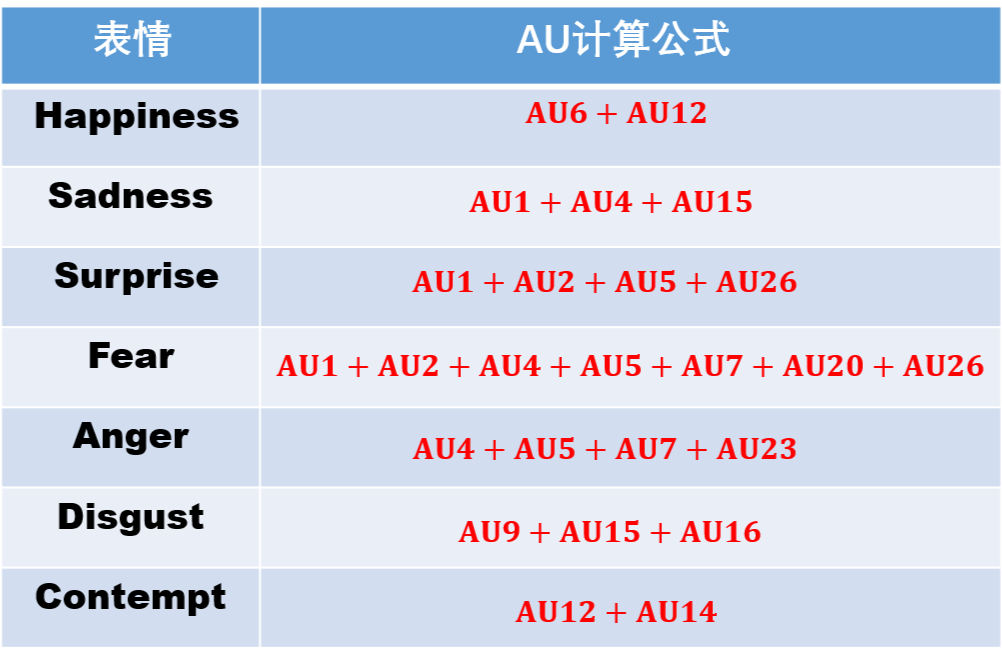
根据上面的面部运动编码编码可以得出相应的情绪计算公式,具体计算公式如下所示:
▲ 图3.情绪计算公式
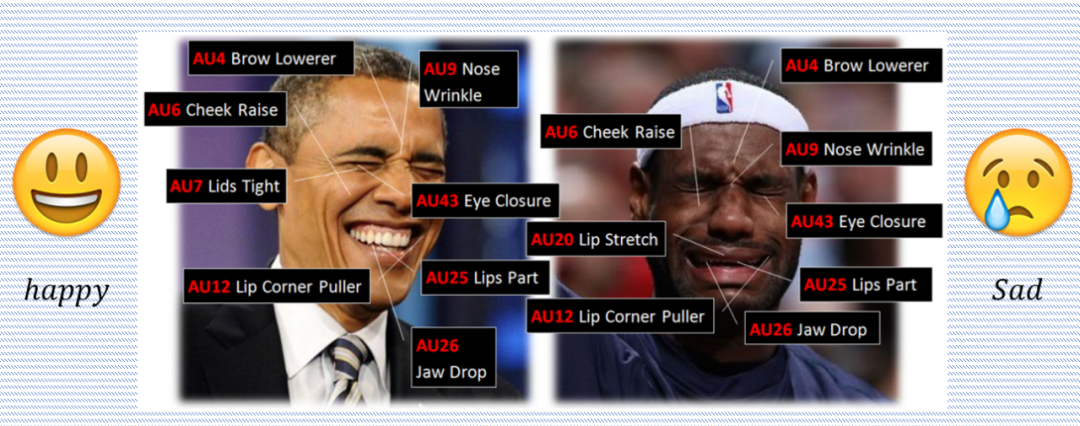
如下图两个例子展示了不同的表情相应的 AU 单元的标注,分别是奥巴马开心的表情和詹姆斯伤心的表情。
▲ 图4.AU单元示例图
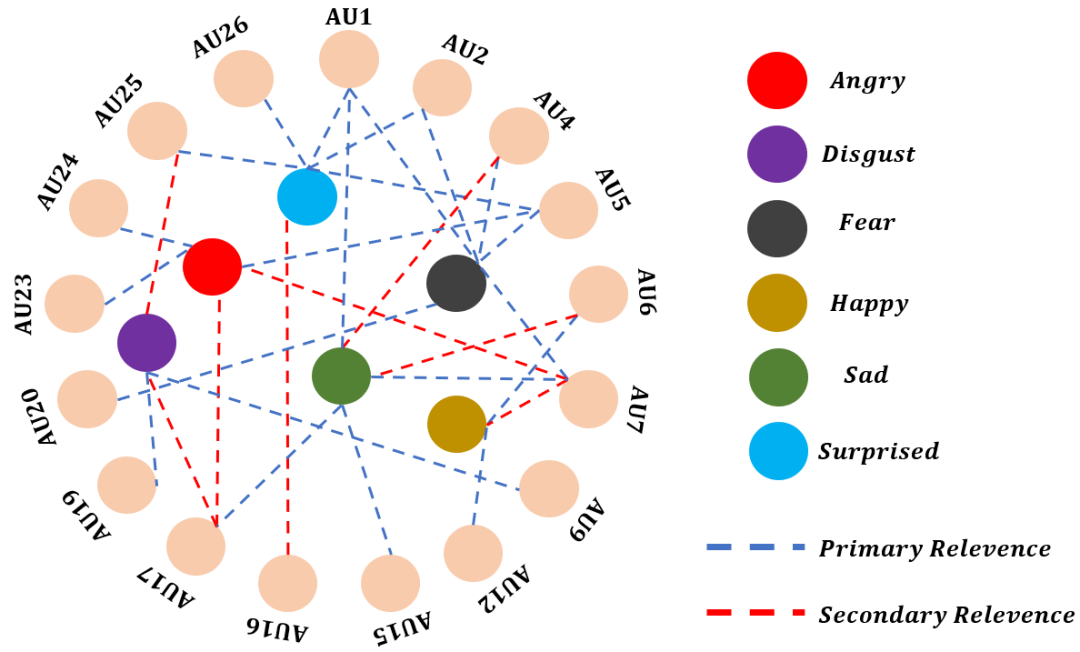
为了能够更加清楚情绪与 AU 单元的对应关系,下面两幅图列出了人类的七中基本情绪与不同 AU 单元的对应关系。
▲ 图5.情绪与AU单元的对应情况
▲ 图6.情绪与AU单元的对应情况
为了能够更加清楚 AU 单元之间的对应关系,下图列出了不同 AU 单元之间的对应关系。
▲ 图7.AU单元之间的对应情况
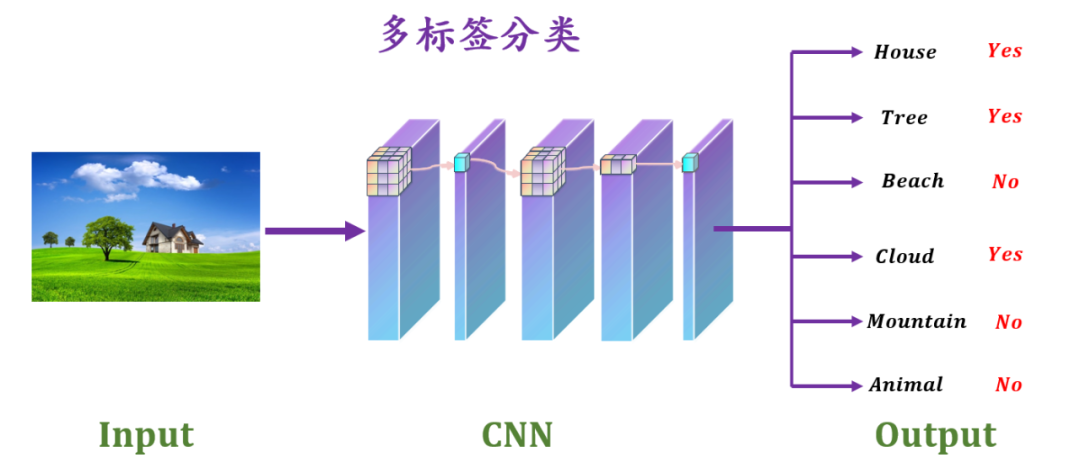
需要注意的一点是,对于一种情绪对应着多个 AU 单元,AU 单元分类器是一个多标签的分类器,多标签分类器不同于多分类,如下图所示为一个多标签分类器。Scikit-learn 提供了一个独立的库用于多种标签分类,Scikit-multilearn 库网址为:
http://scikit.ml/api/datasets.html
▲图8.多标签分类器
FACS的多标签探测
论文链接: https://openaccess.thecvf.com/content_cvpr_2016/papers/Zhao_Deep_Region_and_CVPR_2016_paper.pdf
论文时间:
在该论文中作者提出一种了在 AU 领域中深度区域和多标签学习(DRML)的方法。DRML 的一个关键方面是一个新颖的区域层,它使用前馈功能来诱导重要的面部区域,能够学习到的权重来捕捉面部的结构信息。完整的网络是端到端可训练的,并自动学习表示,鲁棒的内在变化的局部区域,最终的网络是端到端的可训练的,并且比替代模型更快地收敛与更好地学习 AU 关系。
如上图所示显示了该论文的主要思想,图(a)中是传统的基于补丁的方法,图(b)是该论文中提出的 DRML 方法,DRML 通过构建人脸重要区域和多个 AUs 之间的关系模型,表现出较好的定位和分类能力。
下图显示了该论文的 DRML 架构。从左到右依次是对对齐的人脸图像进行标准卷积层滤波,然后是区域层、一个池化层和四个卷积层,三个全连通层,最后是一个多标签交叉熵损失层。颜色说明在每一层产生的 feature map。由于 AUs 的面部外观变化是区域性的和微妙的,所以确保每一层都保留来自前一层的足够的面部信息。
设 AU 个数为
,样本个数为
,真实的标签为
,
表示的是
中的
个元素,预测标签为
。输入层的多目标的 sigmoid 的交叉熵函数:
其中
是一个指示函数。该论文中的训练的模型有大约 5600 万个参数,比AlexNet(6000 万个)少 7%,比 DeepFace 少 53%。
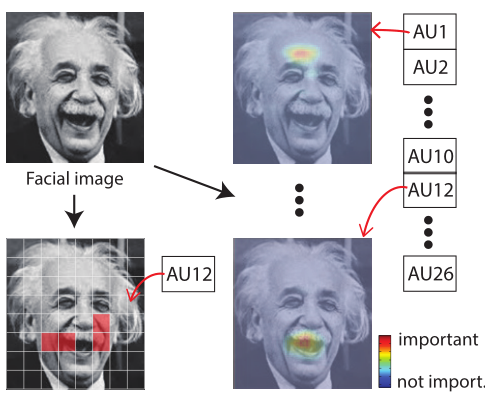
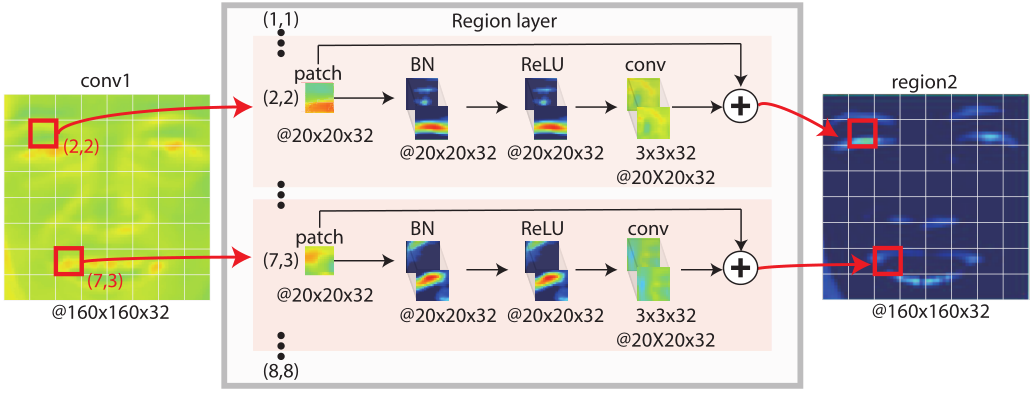
下图所示,论文中提出的区域层包含三个部分:patch 裁剪、局部卷积和身份添加。patch 裁剪模块均匀地将一个 160×160 特征图切片成一个 8×8 的网格。局部卷积模块学习捕捉局部外观变化,学习到的每个 patch 中的权值独立更新。身份添加模块在训练网络的过程中有助于避免消失梯度问题。
如下图所示为 10 个常见 AU 的学习到的显著性 patch 示意图,作者对 DRML 与标准的 ConvNet 进行了比较。所有网络在 BP4D 数据集上进行训练,并使用多标签 sigmoid 交叉熵损失。可以直观的发现,DRML 对相应的 AU 学习了更具体、更集中的区域。
作者在两个数据集 BP4D 和 DISFA 上评估了 DRML 模型。BP4D 包含 41 名青年在与实验人员互动过程中各种情绪的 2D 和 3D 视频。作者使用了 328 个视频,10 个 AU 编码,最终得到约 140000 有效的人脸图像。对于每个AU,作者为每个视频采样 100 个正帧和 200 个负帧。
DISFA 包含 27 个观看视频片段的被试,并提供 8 个 AU 标注。有大约 13 万张有效的面部图像。作者将AU强度为
级或更高的框架作为正样本,其余为负样本。
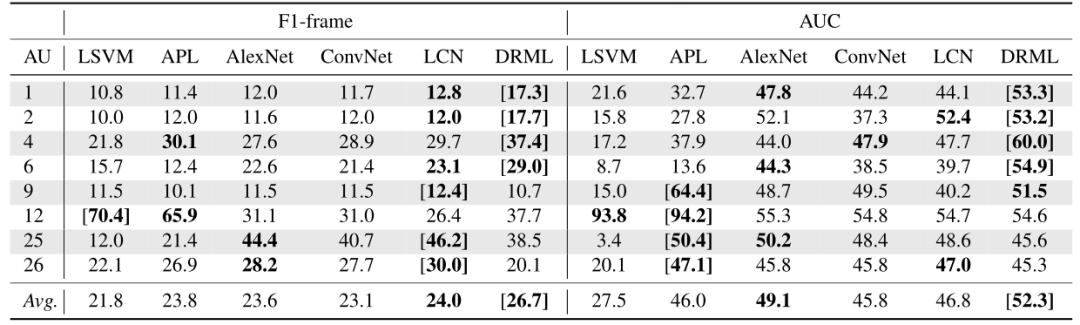
图(9)和图(10)分别显示 了 BP4D 的 12 个 AUs 和 DISFA 的 8 个 AUs 的结果。作者从特征表示、多标签学习、区域层效应、区域与多标签联合学习、运行时间五个方面来讨论结果。这一段讨论了学习特征的好处。
▲图9
如上图可知 AlexNet 的 F1-frame 和 AUC 分别提高了约 2% 和 13%,并且 LSVM、AlexNet、LCN、DRML 的特征尺寸分别为 6272、4096、2048 和 2048。事实上,即使学习到的特征是低维的,但是对于 AlexNet、LCN 和 DRML 来说,超过 40% 的学习到的特征是零。可以推断出学习到的特征可以捕获更多的判别性和稀疏性特征,用于检测 AUs。
▲图10
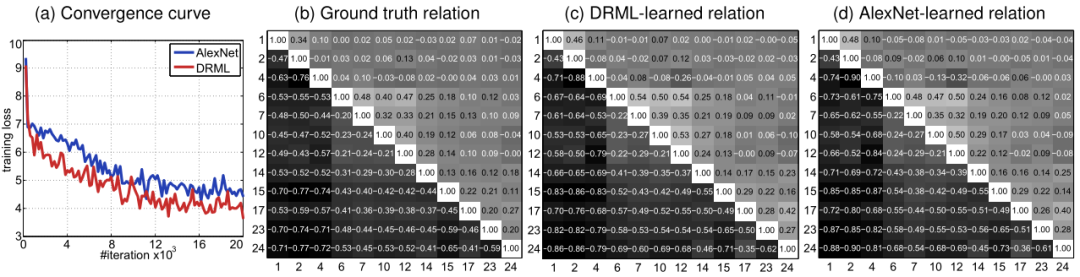
如下图所示,DRML 比 AlexNet 收敛更快,训练损失更低。作者的实验结果中还可以知道 DRML 与真实标签的元素欧式距离为 0.0068,AlexNet 为 0.0077,这说明 DRML 能够学习接近真实统计的 AU 关系。
▲图11
FACS的分区域探测
https://arxiv.org/abs/2002.04023
4.1 论文贡献 该论文是关于人脸表情分析类的文章。人脸动作单元检测是人脸表情分析的基础,由 Section 2 可以知道 AU 只发生在人脸的小区域内,好处是关注特定区域有助于消除身份的影响,但也会带来丢失信息的风险。在该论文种作者将人脸分为三个大区域,上、中、下,并根据它发生的位置对 AU 进行分组,并提出了一种基于三个区域的注意网络。该论文的贡献可以分为如下三个部分:
作者提出了一种便于训练的端到端深度学习框架,可以用于 AU 的检测。
作者在提取特征的时候,使用硬掩模和软注意掩模来提取关键特征。
作者使用挤压-激励(SE)模块来学习所有模块中的特征,便于提取全局信息。
4.2 模型介绍
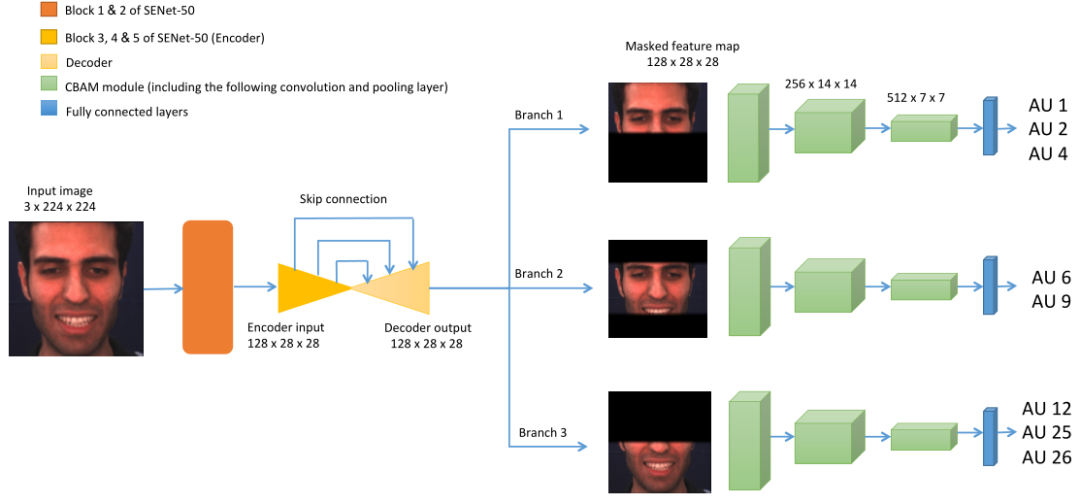
该论文作者提出了一个检测 AU 的框架 TRA-Net ,具体结构如下图所示。该模型使用预先训练的 SENet50 用于提取全局特征。SENet50 是一个经典的 Resnet50 网络,它包含挤压激励模块。在卷积层中考虑到了每个通道对模型的贡献情况,要知道许多经典网络框架都没有考虑通道间的关系。
SENet 包含压缩过程,这意味着模型可以将全局空间信息压缩到一个通道中进行描述。给定特征
,使用全局平均池化函数将空间维数
压缩为 1,具体公式如下所示:
其中,
为特征
的第
个元素,
为特征
的第
个元素。然后将
输入到全连接神经网络中具体公式如下所示:
和
分别是为神经网络第一层和第二层的权重,
为激活函数。
将输出
扩展为
,其中同一通道内的每个像素值相等。
可视为信道权重,则输出
具体的计算公式如下所示:
在上采样后,采用由三个硬掩模组成的硬注意模块,将 feature map 划分为上、中、下三个区域,并使用位于鼻尖和鼻根中间的标志作为中心点进行类似的变换,中心点总是靠近该标志。
设
为中心点为
的输入特征映射,硬掩模分别为
,
,
,并且硬掩模与输入特征具有相同的尺寸,数值只包含集成 0 和 1。掩模的计算公式如下所示:
用
、
和
表示蒙面特征图,分别作为上区域分支、中区域分支和下区域分支的输入。它们被输入到三个连续的软掩膜注意力块中,以便逐步细化注意力并学习更高层次的特性。
该论文中使用的卷积注意力块是(CBAM),最后将扩展的空间掩码与输入的特征映射相乘,得到被掩码的特征映射。由下图可知这是一个多标签分类器 ,不同的分支负责预测不同区域的标签。
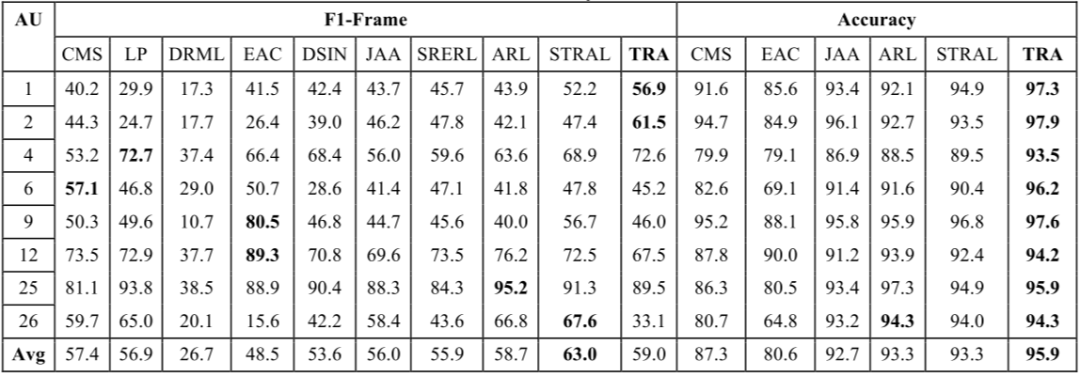
作者比较了 TRA-Net 和其他 AU 检测方法,包括 CMS、LP、DRML、EAC、DSIN、JAA、SRERL、ARL、STRAL。结果如下图所示。对于 DISFA 数据集,TRA-Net 方法比最先进的方法分别提高了 9% 和 28.7%。对于其他地区,TRA-Net 并没有带来显著的改善。
AU1, AU2, AU4 的检测是由上区域分支输出的,这意味着 TRA-Net 对于检测发生在上表面的 AUs 有了显著的改进。由于 DISFA 是一个高度不平衡的数据集,大部分标签都是负的,所以高准确性主要是由于对负样本的正确预测。这证明了该论文提出的方法处理真实数据的能力。
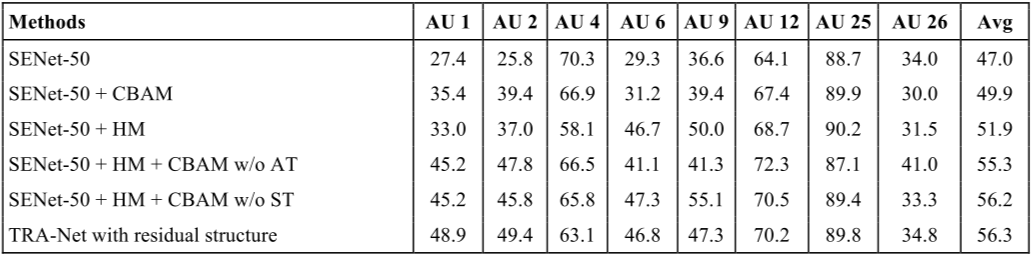
为了评估 TRA-Net 每个模块的有效性,作者对去掉多个模块的模型进行了实验。如下图所示,可以发现注意模块并没有对下面部 AUs 的检测带来任何改善,但 CBAM 模块能够大大的提升性能。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学习心得 或技术干货 。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品 ,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱: hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」 ,小助手将把你带入 PaperWeekly 的交流群里。