【ACL2022报告】生成更好文本:概率文本生成新采样方法,ETH-Ryan Cotterell

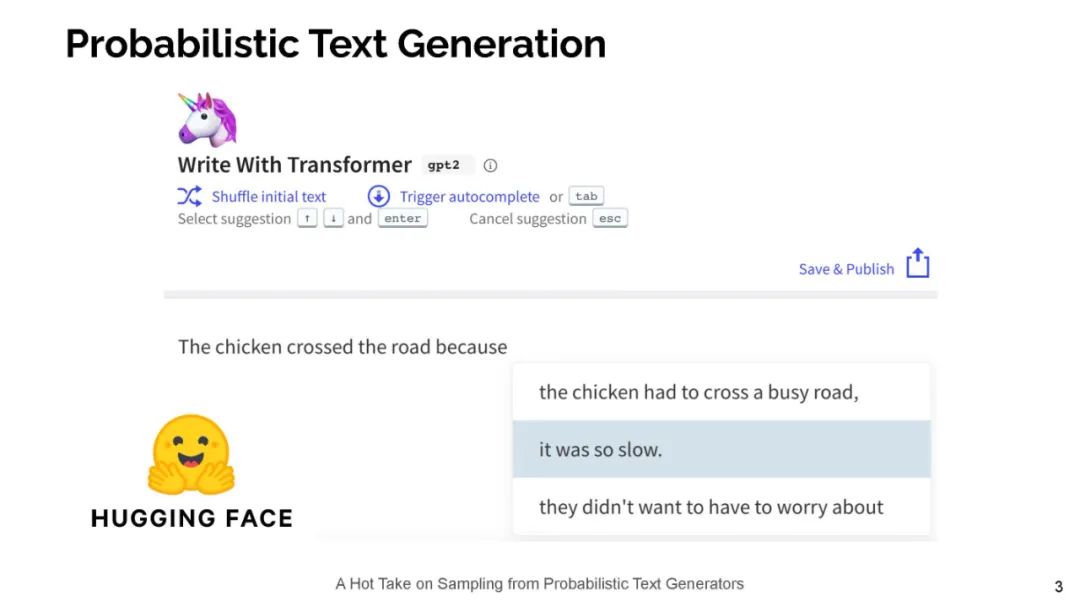
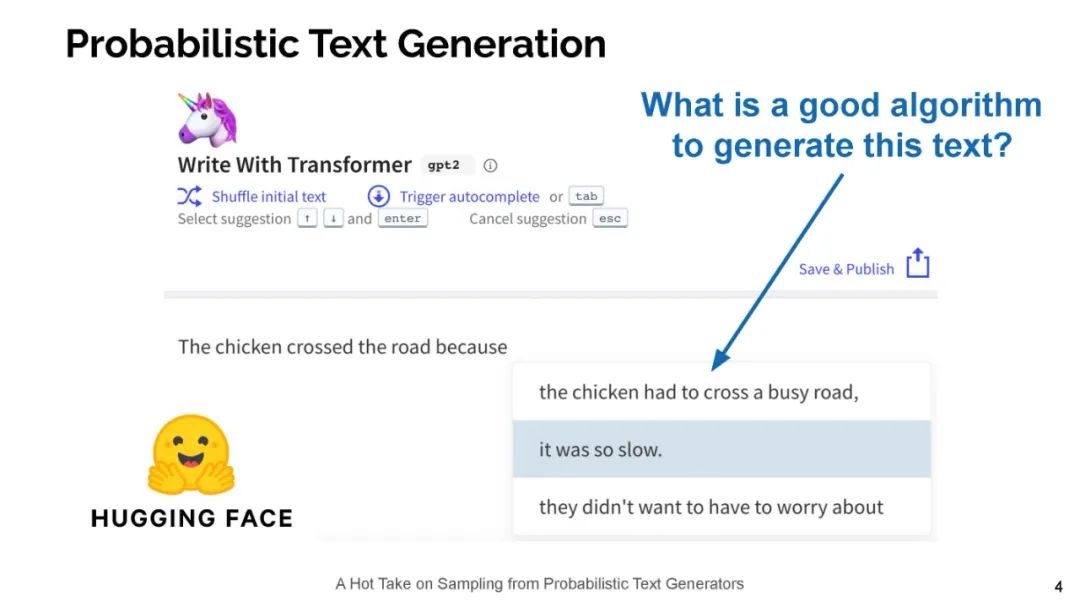
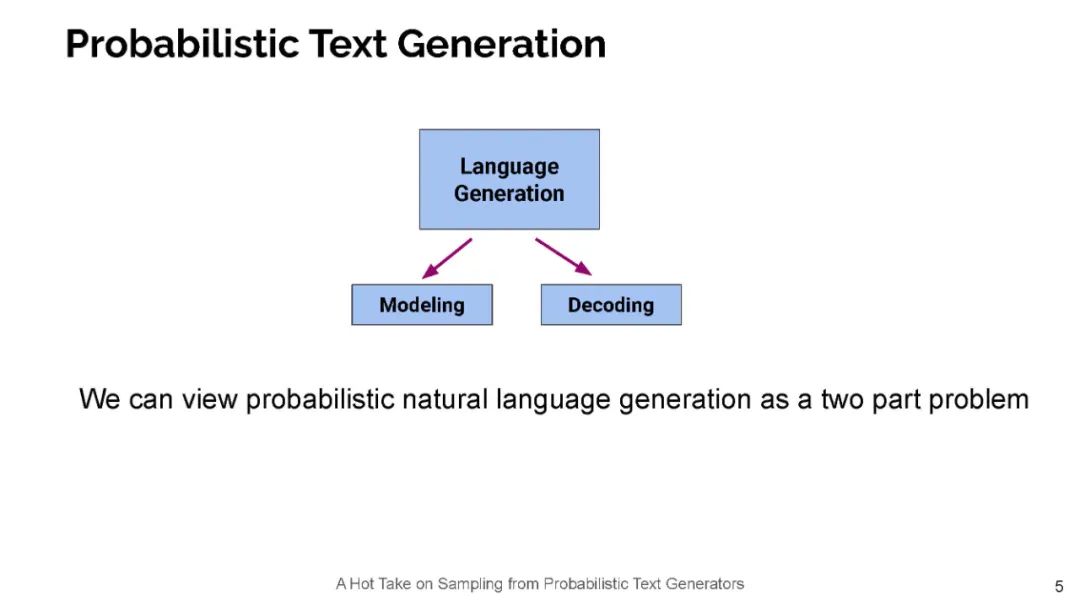
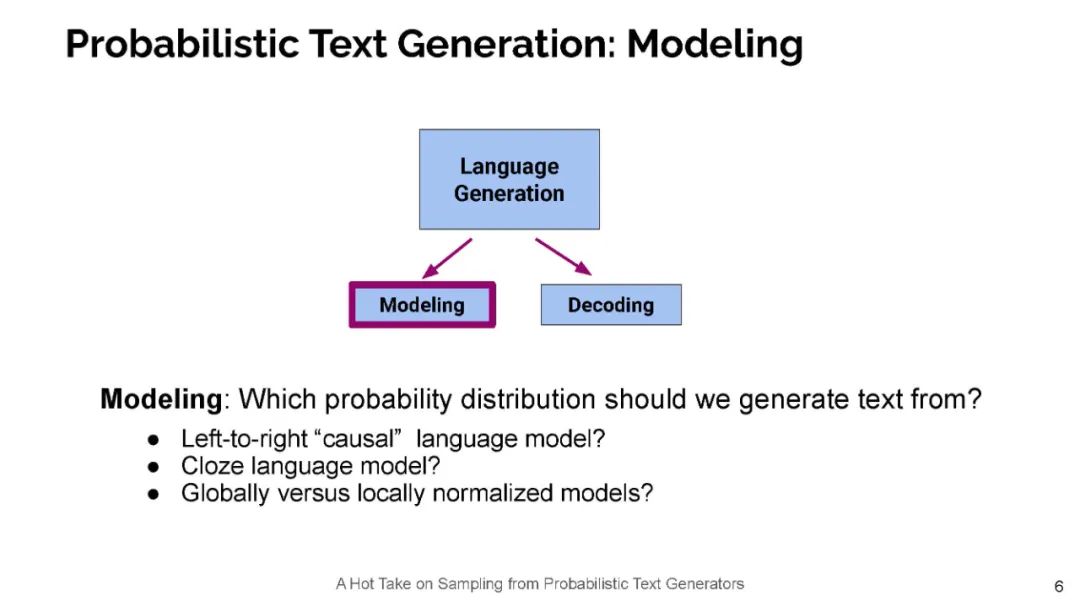
今天的神经语言模型似乎很好地模拟了句子的分布情况,也就是说,它们能够给递出的文本分配高概率。然而,在用于生成文本时,这些相同的模型经常表现不佳——实际上,文本神经语言模型放置的高概率通常是枯燥和重复的。所以,一个好奇的人可能会问:这是怎么回事?在这次演讲中,我将通过信息理论的视角来探讨这一明显的矛盾。具体来说,我认为人类使用语言作为一种沟通渠道。在这种情况下,人们往往会说出既简洁高效,又容易理解的句子。因此,我断言,当我们使用语言模型来生成文本时,我们应该采用类似的原则。这一原则导致了一个简单的抽样策略,我称之为典型抽样。典型的抽样不是每次迭代都从分布的高概率区域中选择单词,而是选择信息量(负对数概率)接近条件分布p(y | y1,…,yk)熵的单词,即分布的平均信息量。我们发现,典型抽样在质量方面优于最近提出的几种抽样算法,同时持续减少退化重复的数量。




专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“PTG” 就可以获取《【ACL2022报告】生成更好文本:概率文本生成新采样方法,ETH-Ryan Cotterell》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2022年7月27日
Arxiv
0+阅读 · 2022年7月22日
Arxiv
21+阅读 · 2020年12月17日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年7月27日
Arxiv
0+阅读 · 2022年7月22日
Arxiv
21+阅读 · 2020年12月17日