Kaggle知识点:伪标签Pseudo Label
Pseudo Label
在现实,标注数据少,未标注数据多;
在竞赛,训练集有标注,测试集未标注;
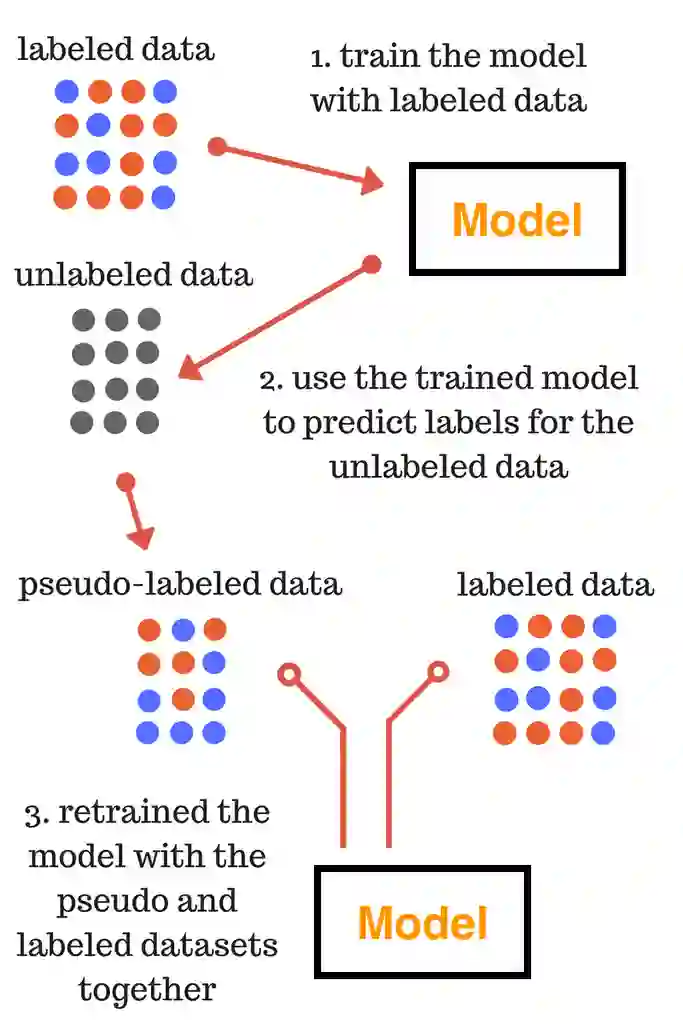
如果初期有标注的数据集比较少,则每次加入的伪标签也不能很多;
上述对未标注数据进行预测和加入训练的过程是迭代进行,不是单次进行的。
在竞赛中伪标签不是万能的,一般情况下伪标签适用于:
非结构化数据,使用深度学习的常见下;
模型的精度较高的情况下,加入的伪标签才精确;
非Kernel赛:线下伪标签,线下预测,进行伪标签训练,再预测;
Kernel赛:线上伪标签,线上预测,伪标签再训练预测,再预测;
伪标签(Pseudo Label)对未标注数据进行预测,进行二次训练;
软标签(Soft Label)对标签转为离散值,进行二次训练;
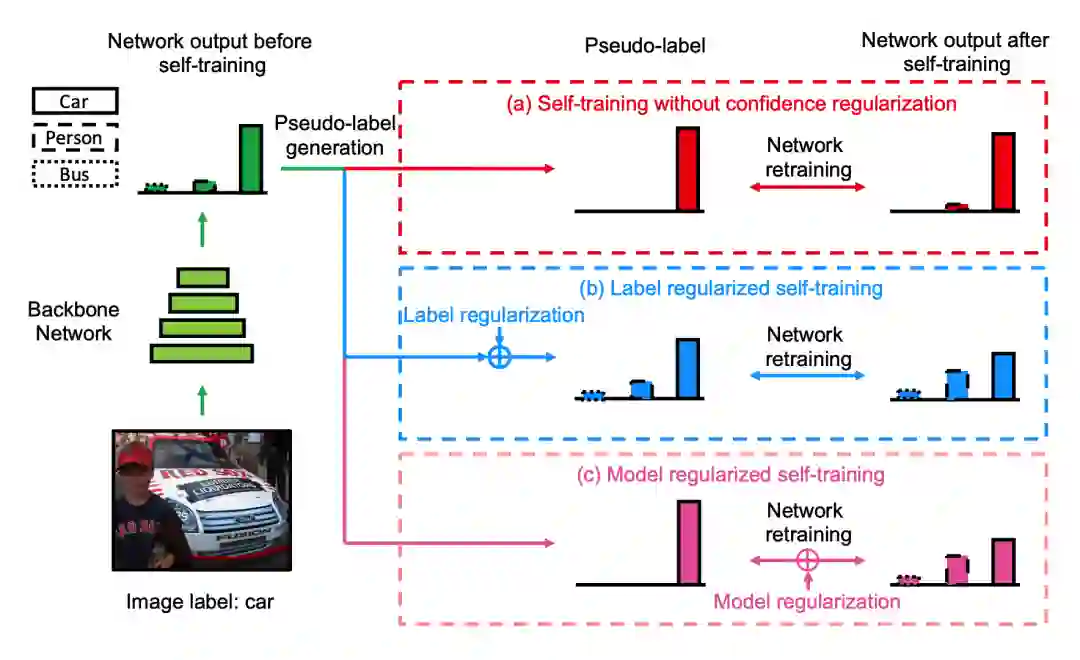
当然也可以将软标签与伪标签同时使用,如下图的思路。在图中照片的原始标签为car,但照片还有person的类别,如果直接使用硬标签进行训练,会带来一定的模型噪音。
可以将模型的预测概率结果(每类概率分布)代替原始图片的标签进行训练,这样图片的标签就更加合理,模型训练过程也会更加稳定。
-
在竞赛中如果没有其他涨分的方法,再建议尝试伪标签,否则不建议尝试; -
伪标签适合用在深度学习方法中,且一般选择预测执行度高的样本加入训练; -
伪标签是否能使用,需要按照举办方规定;
Instant Gratification,kernel赛
Global Wheat Detection,kernel赛
https://www.kaggle.com/nvnnghia/fasterrcnn-pseudo-labeling
https://www.kaggle.com/nvnnghia/yolov5-pseudo-labeling
Challenges in Representation Learning
https://www.kaggle.com/c/challenges-in-representation-learning-the-black-box-learning-challenge/discussion/4726

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏





