针对临床终点预测的异构时序事件联合表示学习
本文发表于AAAI 2018,原文链接地址:
https://arxiv.org/abs/1803.04837
代码:https://github.com/pkusjh/HELSTM
引用信息:
Luchen Liu, Jianhao Shen, Ming Zhang*, Zichang Wang, Jian Tang*. Learning the Joint Representation of Heterogeneous Temporal Events for Clinical Endpoint Prediction. AAAI 2018.
ICU病房的医师在重症病人护理的过程中,要综合大规模的数据,做出一系列临床决策。这些数据源包括生理指标,化验结果,用药记录,重要症状等。随着医疗信息化的发展,这些数据都被记录在了电子病历记录中。

(上述图片来源于网络)
面对这些体量大,累计速度快,类型异构的临床大数据,不仅是普通患者,甚至不非常资深的医生,都会难以全面客观地进行分析。
这造成了当今医疗系统的临很多挑战:例如把治疗的目标,放在了化验指标而非疾病本身;同时,没有充分考虑患者的个性化特征进行诊断,把药物实验的统计学意义代替了实际治疗中的临床意义。
循证医学中一个比较本质的衡量标准是临床终点,即临床中的目标结果(如死亡,治愈,发生某种症状)。病例记录和临床终点的关系是一种关于医疗知识本质的客观洞察,可以从医疗大数据中挖掘并运用。
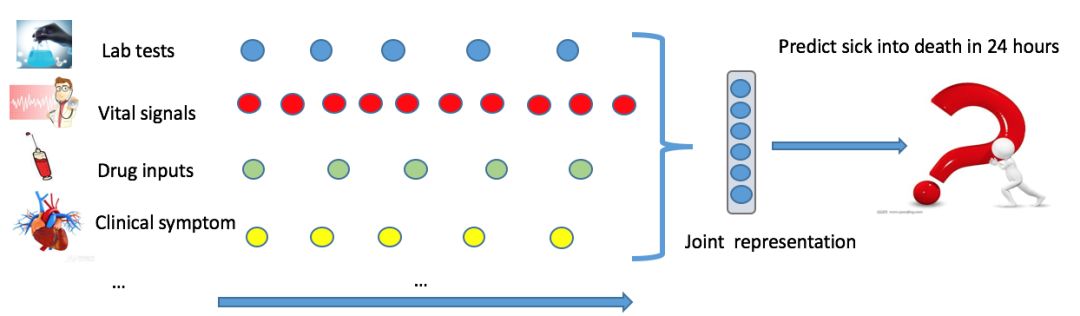
本文研究端到端的基于历史电子病历的临床终点预测。先综合病例临床事件的信息,映射为反应客观的疾病机制的患者状态向量,再以此为基础通过临床终点预测提供个性化的诊疗判断。
我们首先需要分析医疗事件数据特点以及性质。电子病历记录可以抽象成上千种带有时序信息相互关联的医疗事件,不仅上千种事件之间有不同的记录频率,相同类型的事件由于其事件属性不同,也有很大差异。比如药物注射事件就包含药剂类型、剂量、注射速率三个属性;化验事件的属性包括化验异常与否、指标的值这两个属性。

这种数据的主要特点是时序性和异构性,所以可以称其为异构时序事件。
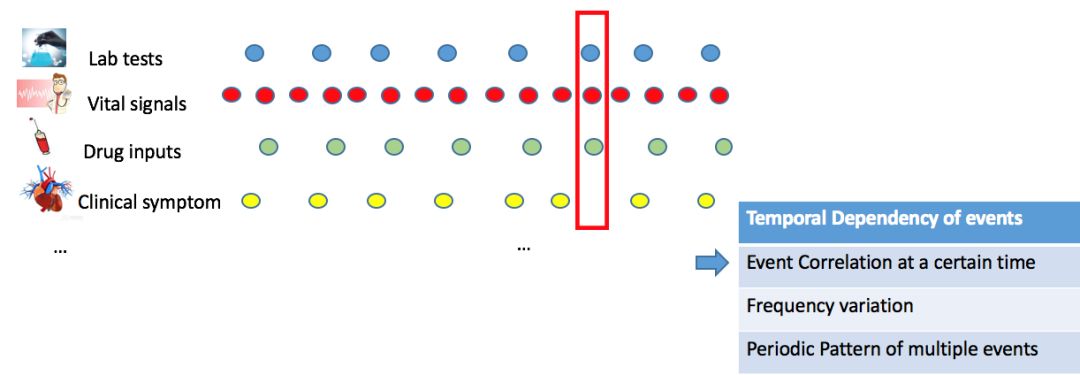
在概念空间上,异构时序事件的事件类型上千;时序层面上,他们各自具有不同尺度的记录频率。时空交织,使得他们之间有复杂的时序依赖性质。
第一种是同一时间点的事件共现
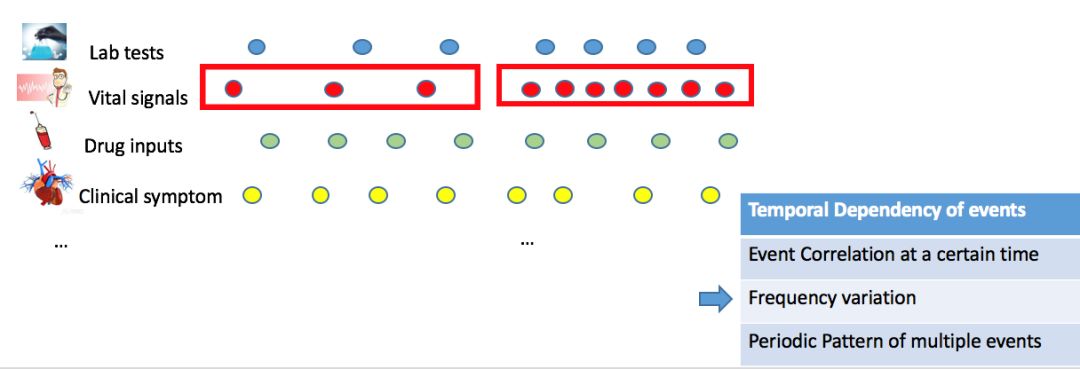
第二种是某个事件发生频率的改变
第三种是多种不同事件在响应时间的模式
例如:左旋去甲肾上腺素注射后(the drug input of levophed)四小时之内没有提升主动脉压,并且处于昏迷状态是一种较危险的信号
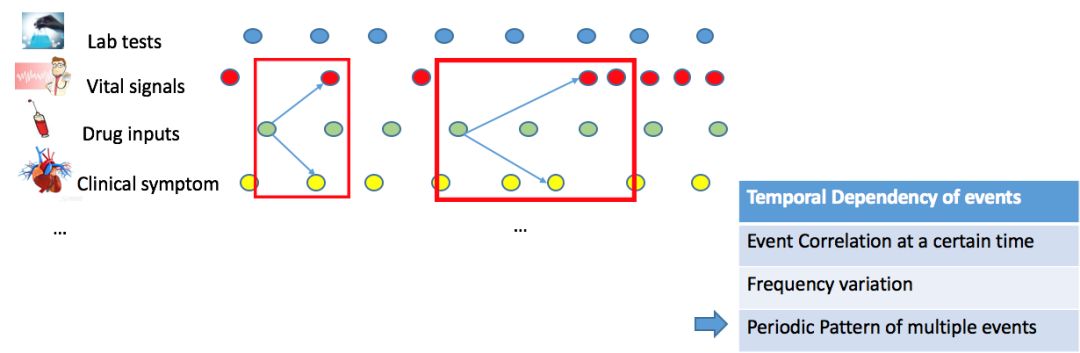
我们学到的联合表征必须要能刻画这些依赖关系。
本文提出了异构事件LSTM(HE-LSTM)模型,其核心思路是“分工合作”。神经元分别以不同的周期,异步地追踪记录不同事件簇的信息。
在经典LSTM的基础上,我们为每个隐藏层神经元设计了一个事件门(event gate)。如果事件门打开,那就正常按照LSTM来更新;如果事件门关闭,就保持原来的值不变,就当这个没有这个输入。
事件门(event gate)根据事件类型和事件记录的时间来决定开关,由一个事件类型的前馈网络分类器(event filter)和一个脉冲震荡函数相位门(phased gate)乘积得到。
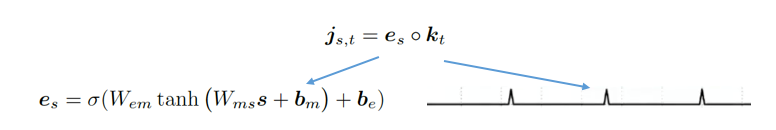
对于某个神经元,只有符合对应事件门的类型条件,并且在其采样周期中的事件信息才会被更新进入到神经元中,因此可以认为,这个神经元表示了某一类事件在某种采样周期下的状态。

所有事件按时间顺序排成一列进入异构事件LSTM(HE-LSTM)模型,每个事件提供三个信息:类型、属性和记录时间。类型向量和属性向量求和作为异构事件LSTM的输入,类型向量和时间送入事件门控制更新。
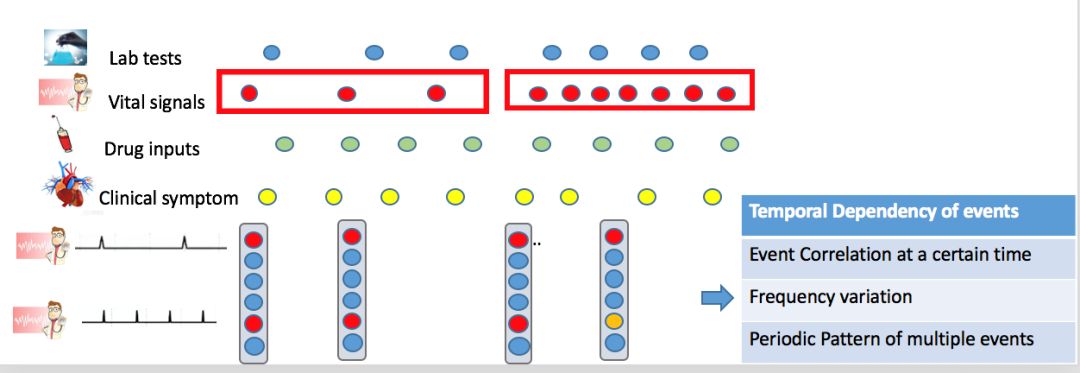
这样模型学到的向量表征便可以对之前提到的三种时序依赖比较敏感。比如:当化验事件发生频率低时,低频化验神经元和高频神经元没有明显差异,但化验事件发生的频率高时,高频神经元因为更新计算了更多次,与低频神经元差距放大,我们的联合表征便可以由此分辨关键事件的频率变化。
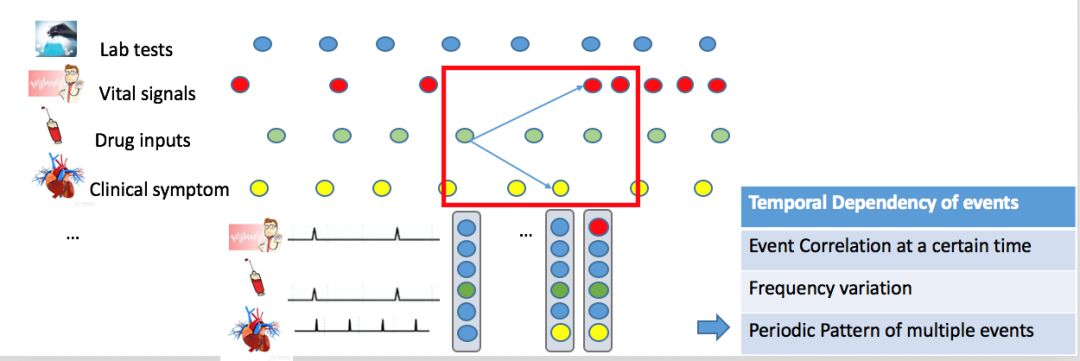
在另外一种情况下,由于低频药物注射神经元比较好的追踪保持了注射事件信息,在序列输入一系列其他事件之后,这个值依然可以参与生命体征信息的计算,从而区分不同事件之间的周期响应模式。
实验
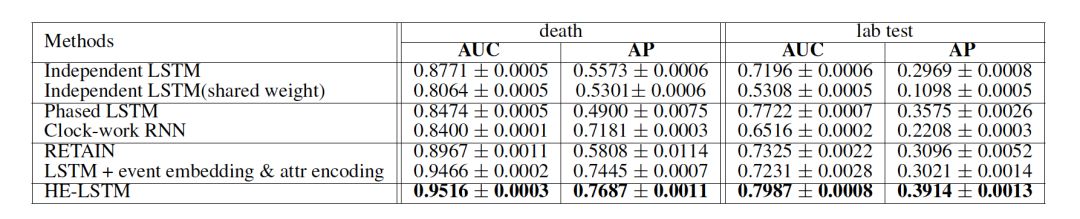
在死亡预测和钾离子化验异常预测任务中,相比于单独对各个数据源进行序列建模的模型和延迟更新的RNN模型,以及异构序列模型,异构事件LSTM(HE-LSTM)在AUC和AP上都有更好的表现。
这是由于模型适应不同类型事件的多重规模的采样频率,追踪并计算不同事件的依赖关系。
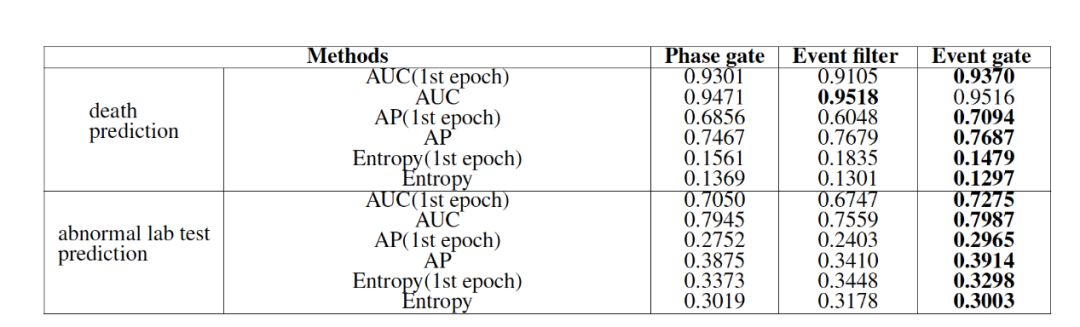
如果把事件门的两个因子——事件过滤器(event filter)和相位门(phased gate)分别去掉,可以发现相位门利用延迟更新从而保留了误差梯度,其主要作用是使模型快速收敛,大多数情况下,第一轮迭代的测试集指标就已经接近最终结果。
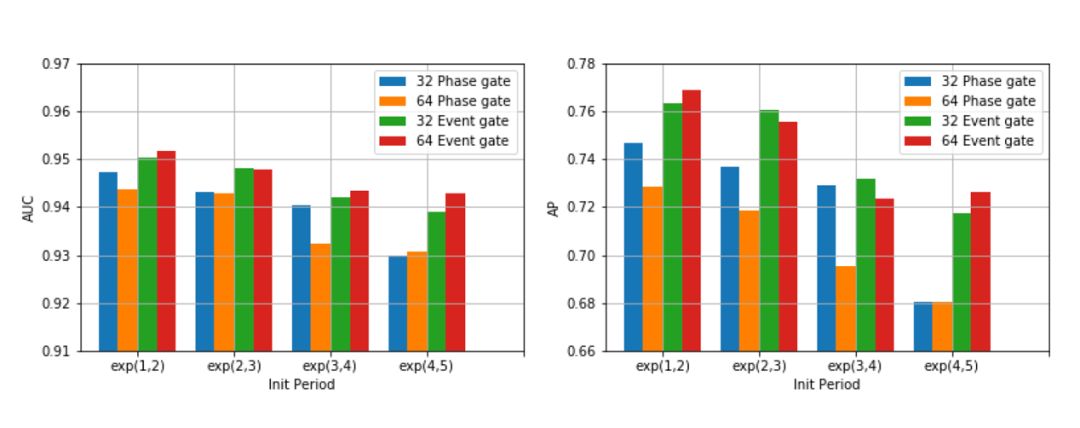
本文使用不同的采样周期去初始化模型,可以发现异构事件LSTM由于时间过滤器的加入,提升了模型的鲁棒性,在不同的初始化条件下测试集AUC和AP表现保持得比较稳定。
本文是2017年11月被AAAI 2018录用为口头报告论文的。两个月之后,谷歌Jeff Dean团队于2018年1月在arxiv发表了Scalable and accurate deep learning for electronic health records 的文(https://arxiv.org/abs/1801.07860),谷歌这篇文章提出了对于这种全体未加工数据的记录格式Fast Healthcare Interoperability Resources (FHIR) format,并以此格式为基础,进行深度学习建模,从而预测多种重要的结果性事件。
在电子病历记录的基本格式层面,我们的方法与其不谋而合,不仅可以比较宽松地适应各个医院的病例记录形式和预测问题,也基本不因为数据规则化而丢失重要信息。
本文的一作刘卢琛、二作沈剑豪两位同学参加AAAI会议并且做口头报告时,正好谷歌论文的一个作者Android Dai是session chair。Andorid非常赞赏本文的模型和研究框架。
在电子病历建模层面,我们和大多数现有模型的差异比较大。一般模型会根据数据类型的角度,区分离散的数据(如ICD诊断编码)和连续时间序列变量(如血压时间序列),单独建模。比如谷歌论文中的Feed forward Model with Time-Aware Attention 直接建模离散数据event sequence的embedding,同时用Boosted embedded time-series model 对每个时间序列,自举10大类时序谓词(如在某个时间点T之后值大于V等),最后筛选出10万中谓词,作为特征输入神经网络。
在对于记录时间的处理上,通常会用区间把固定时间间隔的事件给一个统一时间戳,如谷歌论文中的Weighted RNN模型把离散事件序列数据分成10个左右的大类,固定12小时为时间间隔,把序列划分为事件组的序列,每一类序列分别学习向量表示,在预测结果层面进行整合输出。
而我们的思路不是以病例的数据形式做最初的划分依据,而是以医疗过程中的事件为基本单位,保留精确的事件发生时间,进行建模的。这样可以更大程度地保留和反映各个事件之间的关系,以及不同事件发生的频率结构。
电子病历以结构化数据为主,看起来形式简单,但其中蕴含的异构时序事件的时空关系错综复杂,我们以此文抛砖引玉,希望能有更多医疗专家和人工智能专家进行相关的研究。北大张铭教授领导的文本挖掘和机器学习研究团队(http://net.pku.edu.cn/dlib/)也将继续努力,让基于大数据的智慧医疗模型不仅能融合异构的数据形式,更能够敏锐地把握到其中的潜在的数据性质,在数学模型的层面印证和细化医理,更好地服务于医疗和健康领域。




