从草图到人脸:这篇SIGGRAPH2020论文帮你轻松画出心中的「林妹妹」,开源「计图」实现代码
机器之心编辑部
不会画画却也想画出帅哥美女?梦中情人不用空想!近日一篇被计算机图形学顶会 SIGGRAPH 2020 接收的论文提出了一种新的基于草图深度生成人脸图像的方法。
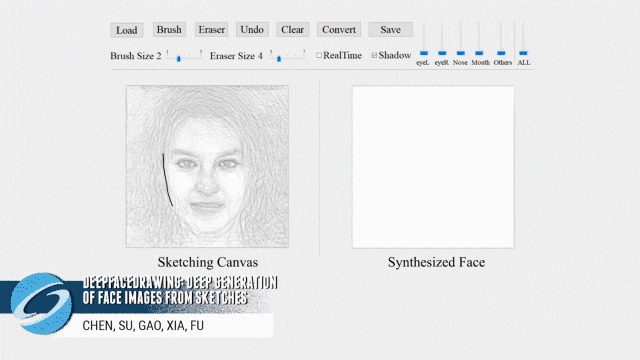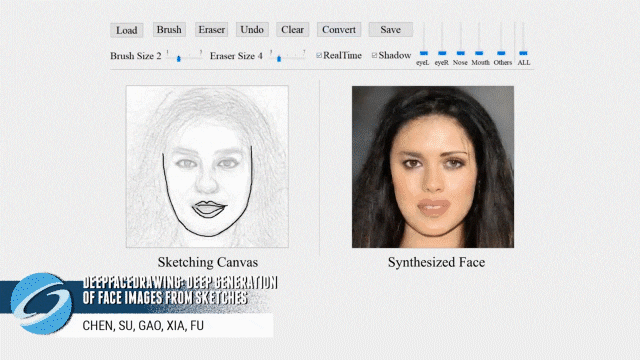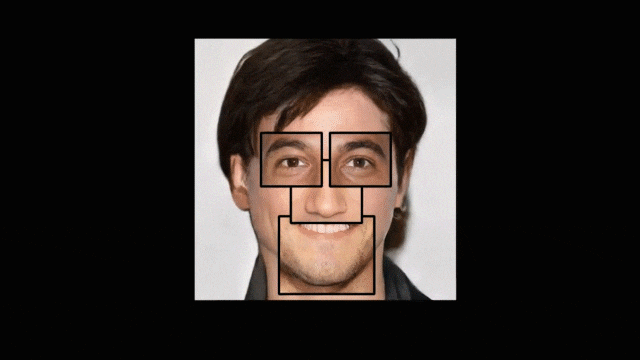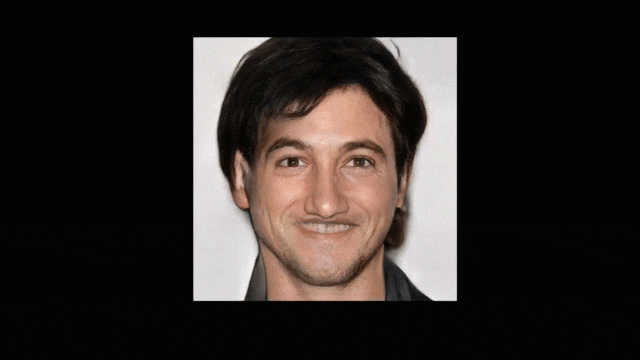


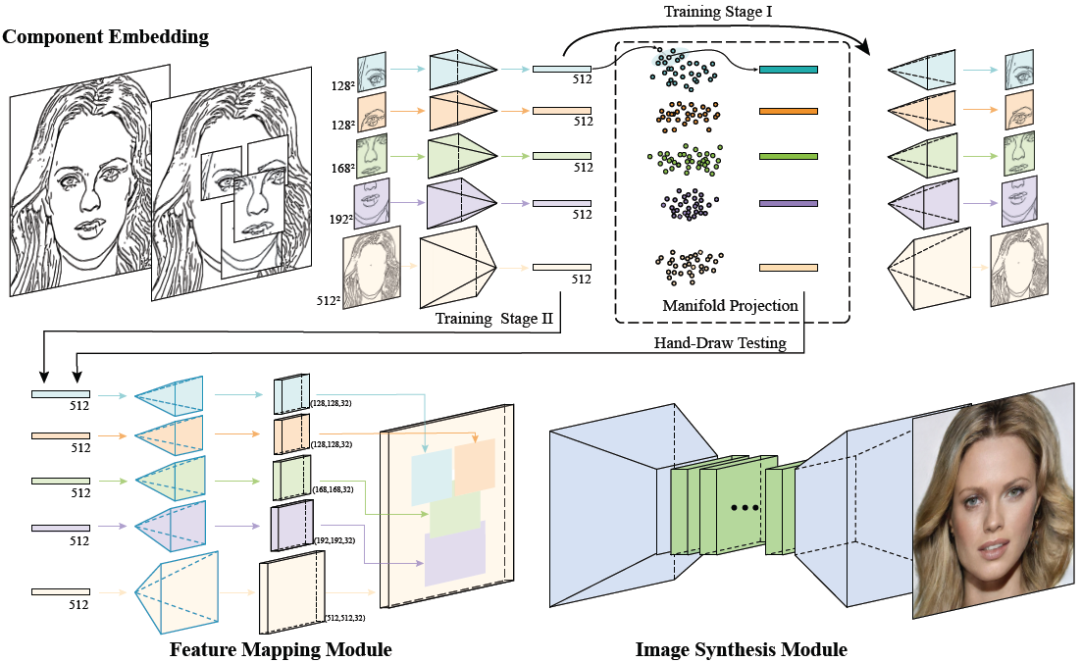
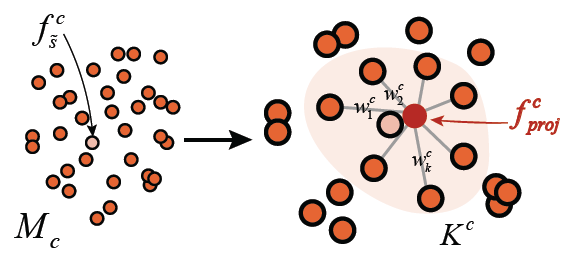
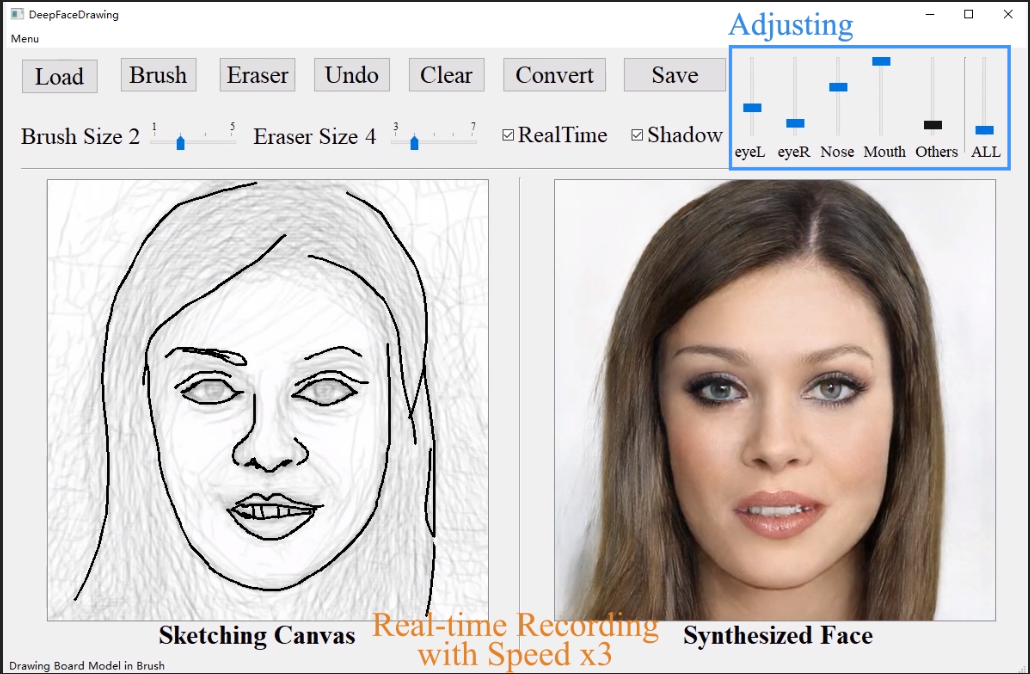
-
智能人脸画板系统和论文见项目主页: http://www.geometrylearning.com/DeepFaceDrawing/ -
Jittor 实现代码:https://github.com/IGLICT/DeepFaceDrawing-Jittor


登录查看更多
相关内容

ACM SIGGRAPH年度会议是关于计算机图形学和交互技术的理论和实践的全球规模最大,最具影响力的年度会议,通过教育,卓越和互动来激发进步。它们共有四个基本目标:通过社区忠诚度,贡献者质量,外部认可和竞争对手的反应来衡量的首要地位。学科专家和整个行业认可的领先优势。通过贡献者,委员会和社区满意度和参与度来衡量教育,互动和卓越的有效性。可持续的连续性,通过志愿者的承诺,社区利益和财务自给自足来衡量。
官网地址:http://dblp.uni-trier.de/db/conf/siggraph/index.html
专知会员服务
22+阅读 · 2020年3月18日
Arxiv
4+阅读 · 2017年12月30日


相关VIP内容
专知会员服务
22+阅读 · 2020年3月18日
相关资讯
相关论文
Arxiv
4+阅读 · 2017年12月30日