TPUv1 到 TPUv4,谷歌有哪些想要分享的经验?
作为图灵奖得主、计算机架构巨擘,David Patterson 在 2016 年从伯克利退休后,以杰出工程师的身份加入了谷歌大脑团队,为几代 TPU 的研发做出了卓越贡献。
几个月前谷歌强势推出了 TPUv4,并撰写论文讲述了研发团队的设计思路和从前几代 TPU 中吸取的经验。
![]()
论文链接:https://www.gwern.net/docs/ai/2021-jouppi.pdf
当前,深度神经网络在商用领域的特定架构(DSA)已初步建立。该论文回顾了四代 DSA 的演变历程。生产经验推动了新设计的诞生,不再受限于 CPU 的缓慢发展和摩尔定律的衰退。
![]()
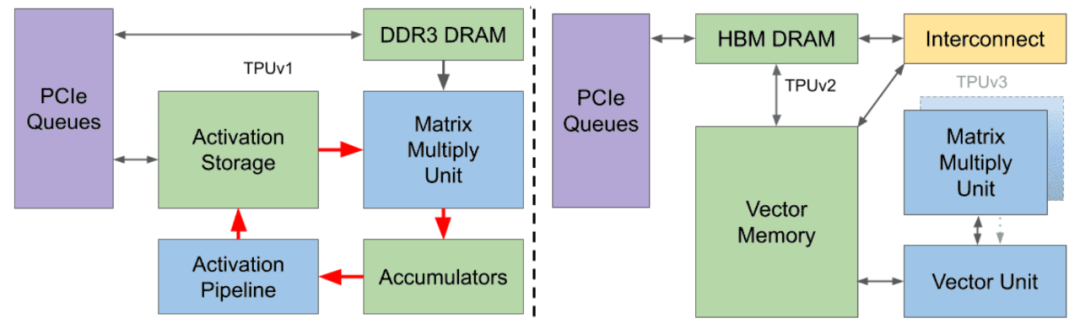
图 1:从 2015 年开始部署在谷歌数据中心的 3 个 TPU 的框图。
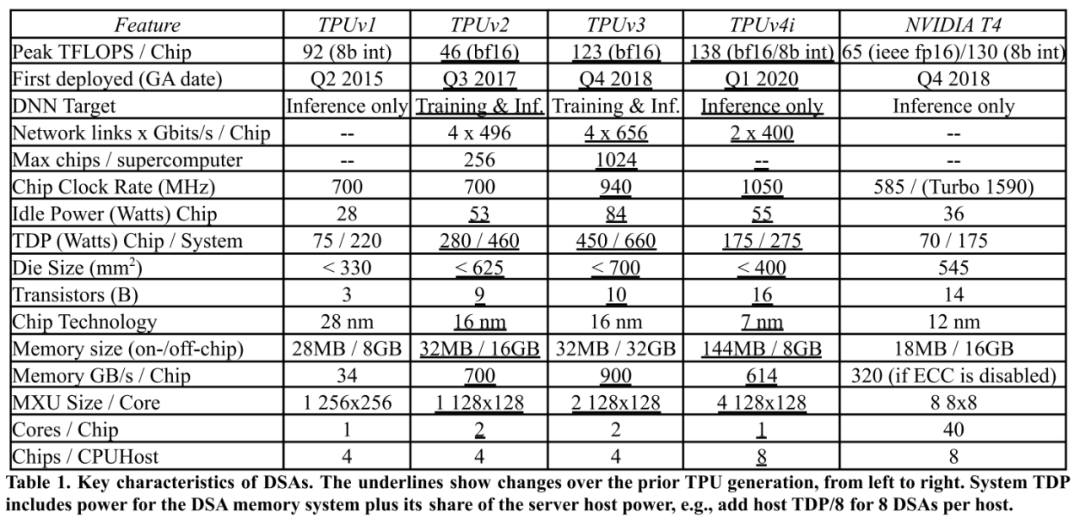
下表展示了几代 TPU 的关键特性,其中 TPUv4i 中 i 代表的是「推理」。
![]()
TPUv1 是谷歌第一代 DNN DSA(图 1 左),能够处理推理任务。近年来,模型训练的规模逐渐增大,所以一种新的改进是添加一个片到片的定制互连结构 ICI,使得搭载 TPUv2 的超级计算机芯片数量可多达 256 个。
与 TPUv1 不同,TPUv2 每个芯片有两个 TensorCore。芯片上的全局线不会随着特征尺寸的缩小而缩小 ,因此相对延迟会增加。每个芯片有两个较小的核,以避免单个大型全芯片核的过度延迟。谷歌并没有继续增加核的数量,因为他们相信两个强大的核比许多不够强的核更易于高效地编译程序。
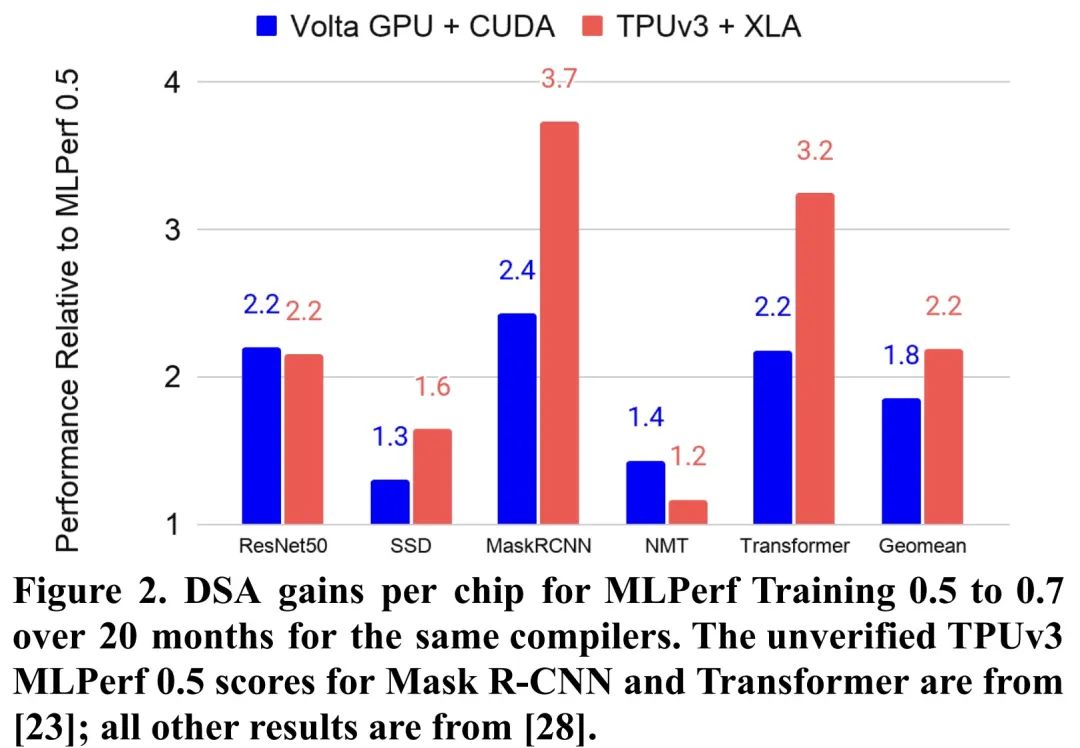
TPUv3 则在 TPUv2 的基础上微调了设计,采用相同的技术,拥有 2 倍的 MXU 和 HBM 容量,并将时钟频率、内存带宽和 ICI 带宽提高至 1.3 倍。一台 TPUv3 超级计算机可以扩展到 1024 个芯片。TPUv3 在使用 16 位浮点(bfloat16 vs IEEE fp16 时与 Volta GPU 相当。然而,Volta 需要使用 IEEE fp32 来训练谷歌的生产工作负载,因此 TPUv3 快了 5 倍以上。一些扩展到 1024 个芯片的应用程序可以获得 97%-99% 的完美线性加速。
1. 逻辑、线路、SRAM 和 DRAM 的发展不平衡
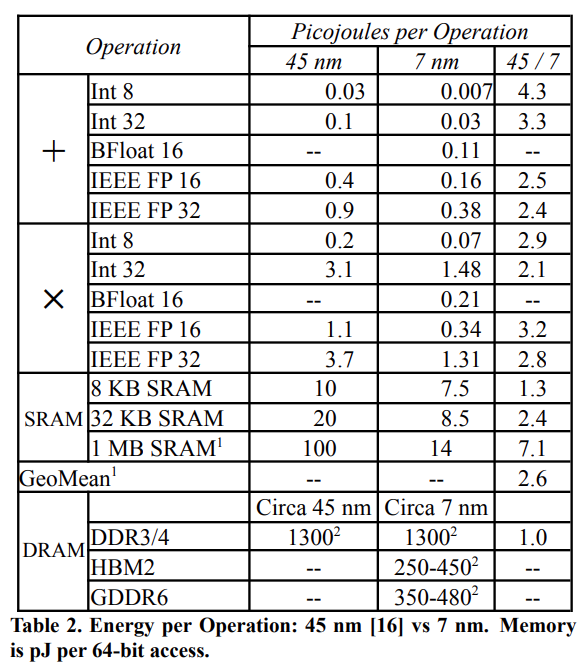
Horowitz 对操作功耗的见解启发了许多 DSA 的设计。表 2 显示 7 nm 相对于 45 nm 的平均增益是 2.6 倍,但并不均匀:
![]()
SRAM 访问只提高了 1.3 - 2.4 倍,部分原因是 SRAM 的密度扩展速度比之前慢。65 nm 与 7 nm 相比, SRAM 每平方毫米的容量密度仅约为理想扩展的 1/5;
得益于封装的革新,DRAM 访问量提高了 6.3 倍。HBM 将短 DRAM dies 栈放置在宽总线上靠近 DSA 的位置;
但每单位长度线路的功耗提高不到 2 倍(表 2 未显示这一点)。较差的线路延迟缩放导致 TPUv2/v3 相比于 TPUv1,从使用 1 个较大核变为使用 2 个较小核。
逻辑方面的改进速度比线路和 SRAM 快得多。HBM 比 GDDR6 和 DDR DRAM 更节能,且 HBM 的每 GB/s 的带宽成本最低。
自 20 世纪 80 年代以来,新架构的命运与编译器的质量密切相关。事实上,编译器问题可能会破坏安腾(Itanium)的 VLIW 架构,但许多 DSA 依赖于 VLIW,包括 TPU。
架构师希望在模拟器上开发出出色的编译器,然而大部分进展发生在硬件可用之后,因为这样编译器编写者能够测量代码所花费的实际时间。因此,如果能够利用预先的编译器优化而不是从头开始重新编写,那么快速实现架构的全部潜力会容易得多。
3. 性能 / TCO 和性能 / CapEx 的设计
CapEx 指的是一个项目的价格。OpEx 指的是运营成本,包括电力消耗和电力供应。标准的会计处理方法是在 3-5 年内摊销计算机 CapEx,因此 3 年的 TCO = CapEx + 3 ✕ OpEx。
谷歌等大多数公司更关心生产应用程序的性能 / TCO (perf/TCO),而不是基准的原始性能或性能 / CapEx (perf/CapEx) 。虽然 TCO 是谷歌在产品设计过程中优化的主要变量,但资本支出仍然会影响一些业务决策。
一些 DNN 具有上市时间限制,因为及时性可能会带来经济价值。在这种情况下,向后 ML 兼容性成为一种原则。新 CPU 的目标是相同的,即应该获得完全相同的结果,包括相同的异常行为和相关性能,从 TPUv2 开始,训练和围绕TPU生成的服务都是按照这种情况设计的。
75W TPUv1 和 280W TPUv2 采用风冷,但 450W 功率的 TPUv3 使用了液冷。液冷需要将 TPU 放置在几个相邻的机架中,以分摊冷却基础设施。这种放置限制对于训练已经由几个相邻机架组成的超级计算机来说不是问题。此外,将训练限制在拥有更多空间的几个数据中心的缺点是很小的,因为没有必要进行广泛部署。
DNN 量化旨在维持使用整数下的实时推理模型质量,即使所有训练都是在浮点下完成的。量化计算可以节省面积和功耗,但这需要和质量降低、延迟部署进行权衡,并且一些应用程序在量化时不能很好地工作。
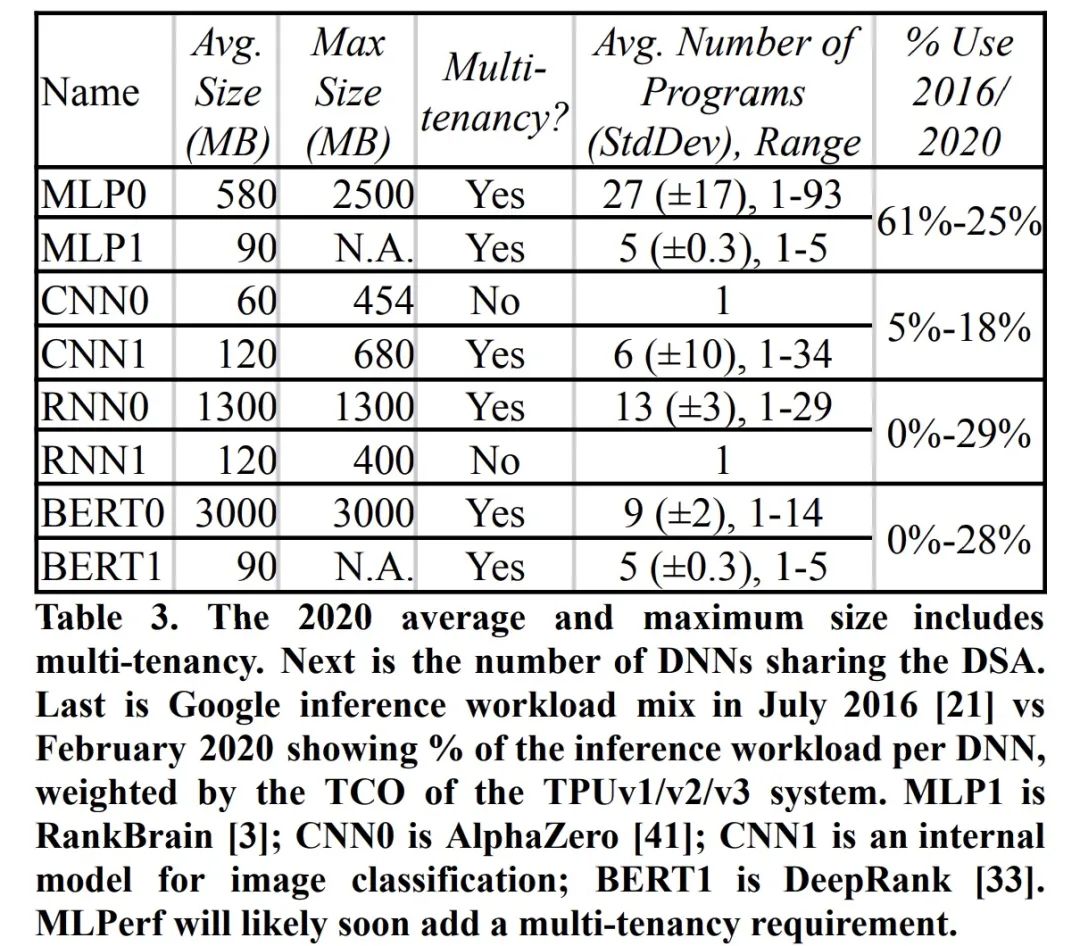
与 CPU 一样,DSA 应该支持多租户(multi-tenancy)模式。如果应用程序使用许多模型,共享则可以降低成本并减少延迟。例如,翻译 DNN 需要许多语言对,而语音 DNN 必须处理多种方言。多租户模式还支持多种批大小,以权衡吞吐量和延迟。另一方面,采用良好的软件工程实践方式也是很重要的,例如面向一小部分客户尝试新功能,或缓慢部署新版本以减少出现问题的机会。表 3 显示了超过 80% 的生产推理工作负载需要多租户。
![]()
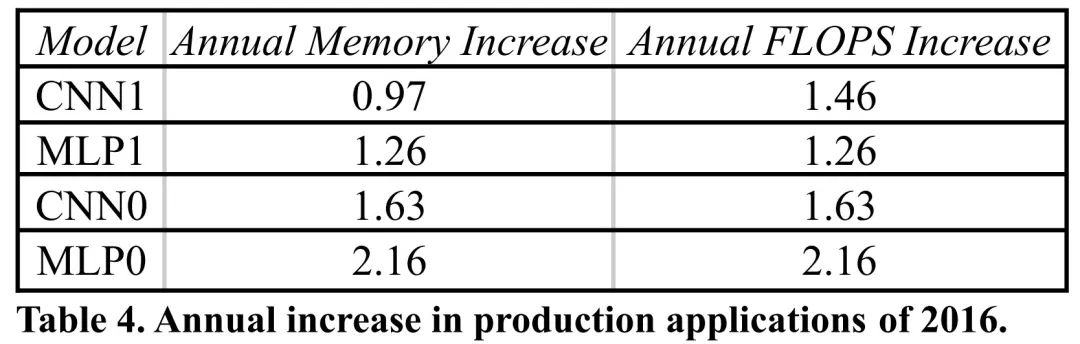
8. DNN 的内存和计算需求每年约增长 1.5 倍
与基准测试不同,程序员不断改进生产应用程序,这通常会增加内存大小和计算需求。表 4 跟踪了仍然在 TPUv1/v2/v3 上运行的四个原始生产推理应用程序的内存大小和计算量的年均增长。生产 DNN 每年约增长 1.5 倍,增长速度与摩尔定律一样快,就像早期的 PC 软件一样。这个比率表明架构师应该提供空间,以便 DSA 可以在其整个生命周期内保持有用。
![]()
表 3 中的 DNN 约占谷歌 2020 年推理工作负载的 100%。2016 年的 MLP 和 CNN 仍然很受欢迎,尽管一些应用程序从 MLP 切换到 BERT DNN (28%)。BERT 出现于 2018 年,但它已经占了 28% 的工作负载。为了提高质量,transformer编码器加上 LSTM 解码器 (RNN0) 和 Wave RNN (RNN1) 取代了 LSTM (29%)。这个经验说明了可编程性和灵活性对于推理DSA的重要性。
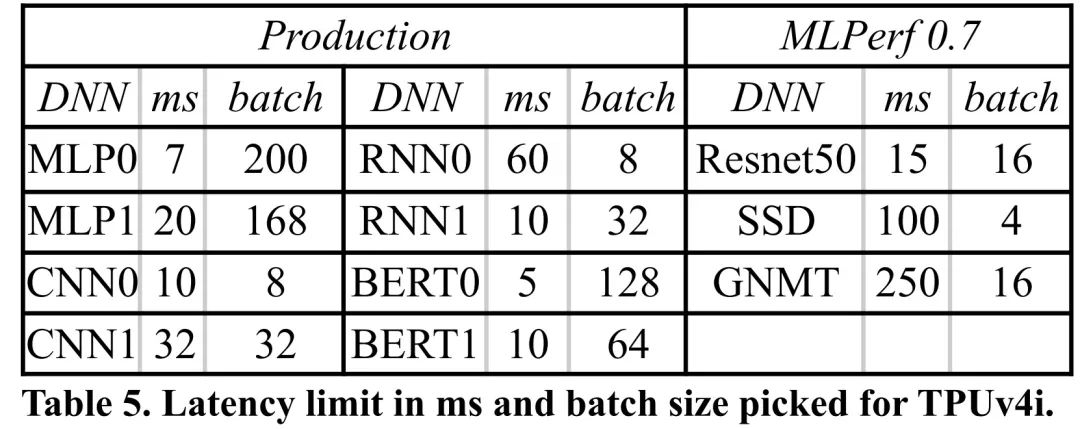
10. 推理 SLO 的限制是 P99 延迟,而不是批大小
近来 DSA 的论文根据批大小重新定义了延迟限制,通常设置为 1。表 5 给出了生产应用程序的 P99 时间 SLO 和 MLPerf 推理基准测试,并显示了近来符合 SLO 的 TPU 的最大批。显然,数据中心应用程序限制了延迟,而不是批大小。未来的 DSA 应该利用更大的批大小。
![]()
鉴于利用预先的编译器优化和向后 ML 兼容性的重要性,再加上重用早期硬件设计的好处,TPUv4i 沿袭了 TPUv3 的一些设计。该论文集中讨论了 TPUv3 和下一代的不同之处,谷歌重新考虑了构建单个芯片的策略,使芯片既能优化训练,又能用于推理。
编译兼容,而不是二进制兼容。鉴于 TPUv2 和 TPUv3 共享 322 位 VLIW 指令包长度,传统架构思想是 TPUv4i 和 TPUv4 尝试保持向后的二进制兼容性,但谷歌选择了编译兼容。
在片上SRAM存储中增加了普通内存CMEM。DSA 在编译之后首先考虑的是内存系统。限制内存开销可以提高 perf/CapEx,但是可能会影响 perf/TCO。除了推理之外,多租户、快速增长的 DNN 和 HBM 的高能效,都促使 TPUv4i 继续使用类似于 TPUv3 的 HBM。
四维张量 DMA。内存系统架构对于任何 DNN 加速器都是至关重要的,因此应被设计为满足常用情况工作负载的最大性能,同时对于其他模型足够灵活。TPUv4i 包含张量 DMA 引擎,分布在整个芯片的非核心部分,以减轻互连延迟和线路扩展的影响。
自定义片上互连(OCI)。快速增长和不断发展的 DNN 工作负载促使 TPU 的非核心具备更大的灵活性。过去 TPU 设计的每个组件都是点对点连接的(如图 1 所示),随着内存带宽的增加和组件数量的增加,点对点方法变得过于昂贵,需要大量路由资源和 die area。它还需要预先选择支持哪种通信模式,这限制了未来软件使用芯片的方式。
因此 TPUv4i 增加了一个共享的片上互连 OCI,它连接了 die 上所有的部件,并且可以基于当前的部件来扩展它的拓扑。OCI 对于增加 CMEM 来说特别重要,在 HBM、CMEM 和 VEM 之间进行分配和数据传输的方式会持续进化。
运算改进。另一个重要变化是运算单元。需要量化的风险和 ML 向后兼容性的重要性意味着,尽管要进行推理,仍然要保留 TPUv3 中的 bf16 和 fp32。谷歌还希望对 TPUv1 的应用程序进行量化,以便轻松地将其移植到 TPUv4i,TPUv4i 也支持 int8。
时钟速率和 TDP。用于推理的风冷和减少 TCO 导致时钟频率变为 1.05 GHz,芯片 TDP 为 175W,再次接近 TPUv1(75W)而不是 TPUv3(450W)。
ICI 扩展。为了给未来的 DNN 增长提供空间,TPUv4i 有 2 个 ICI 链路,这样每块板上的 4 个芯片可以通过模型分区快速访问附近的芯片内存(TPUv3 使用 4 个 ICI 链路)。随着软件的成熟和 DNN 的增长,应用程序可能会用到这些扩展。
工作负载分析特征。基于 TPUv1 的经验,TPUv4i 包含了大量的追踪和性能计数器硬件特征,特别是在非核心部分。它们被软件堆栈用于测量和分析用户工作负载中的系统级瓶颈,并指导持续的编译级和应用级优化,如下图2所示。这些特征增加了设计时间和面积,但这种尝试是值得的。随着 DNN 工作负载的增加和发展,这些特征可以显著提升系统级性能,并提高产品在整个生命周期中的生产力(如表 4 所示)。
![]()
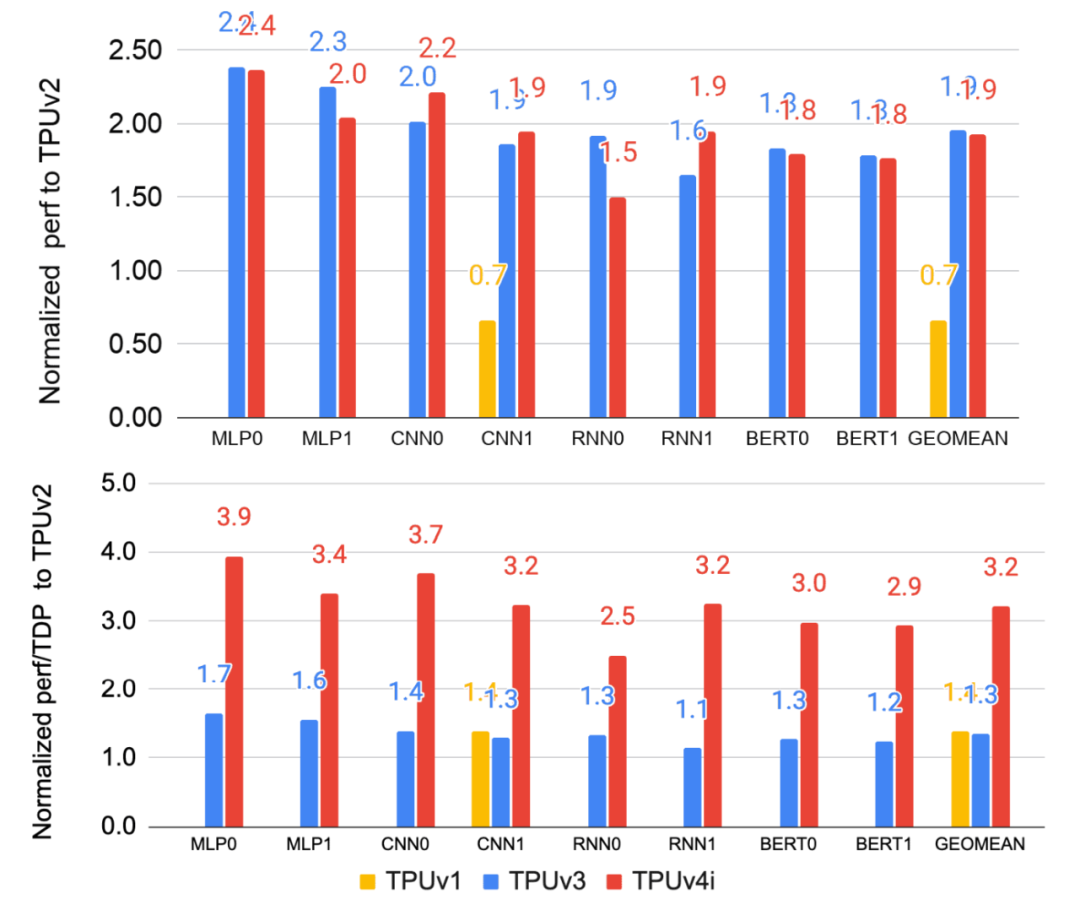
下图比较了TPUv1、TPUv3和TPUv4i在生产推理应用上相对于TPUv2的性能和perf/TDP。TPUv3 和 TPUv4i 都比 TPUv2 快 1.9 倍以上,TPUv1 的速度大概是 TPUv2 的 70% 左右。更大、更热的 TPUv2/v3 芯片有两个内核,而较小的 TPUv4i 芯片有一个内核,这使 TPUv4i 芯片在 perf/TCO 和部署方面更胜一筹。
![]()
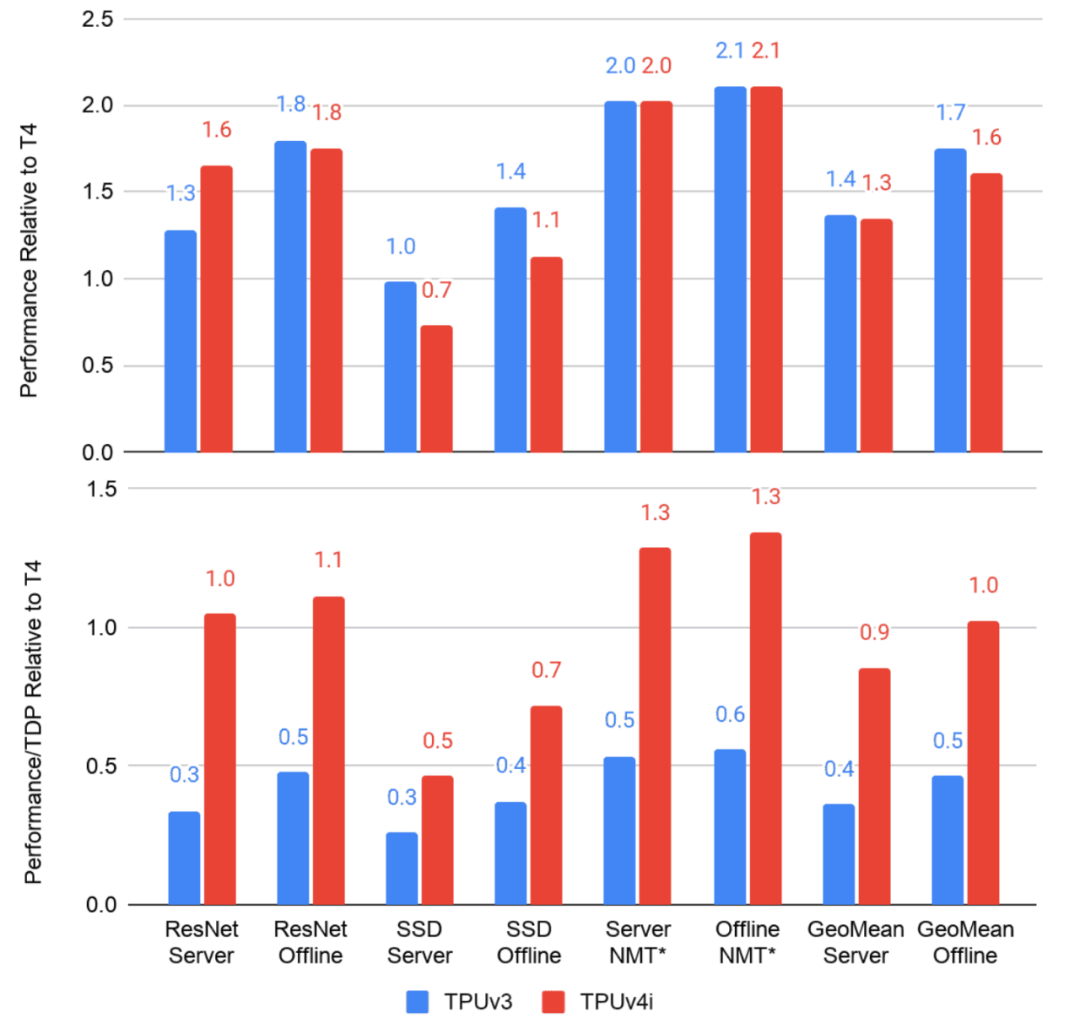
下图使用 MLPerf 推理 0.5-0.7 版本基准测试比较了 TPUv3 和 TPUv4i 相比于 NVIDIA T4 的性能和 perf/(system)TDP。
![]()
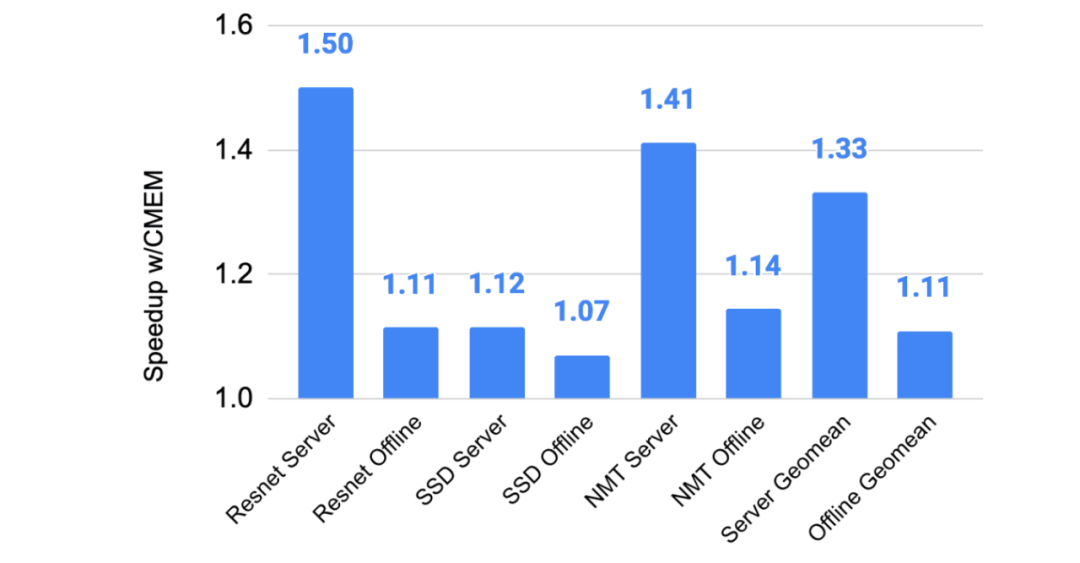
下图展示了 TPUv4i 增加 CMEM 给 MLPerf 推理 0.5-0.7 基准测试带来的收益。由于延迟和延迟受限服务性能之间的关系在某些效用点上是非线性的,因此离线的平均收益只有 1.1 倍,而服务的平均收益是 1.3 倍。
![]()
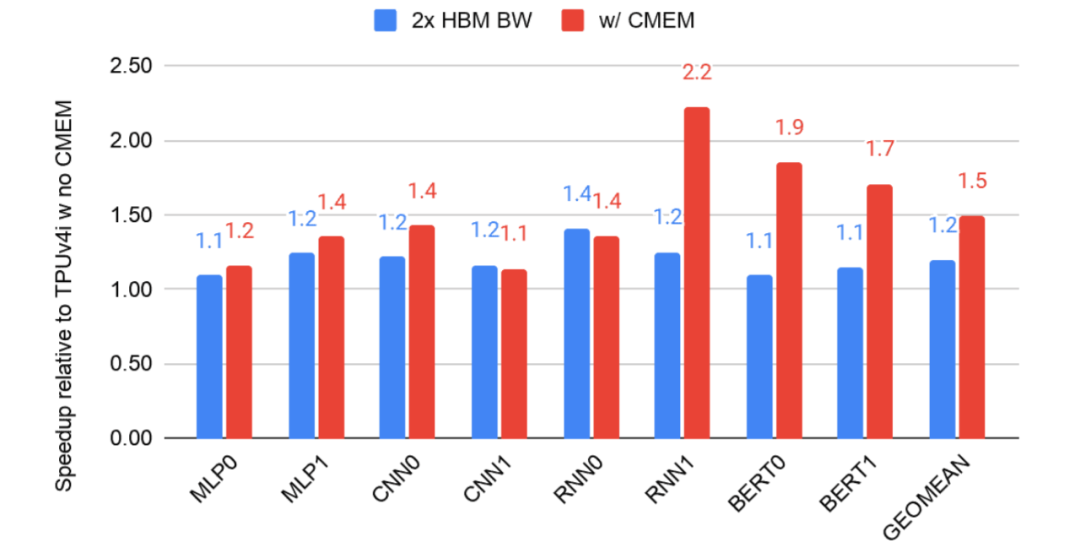
为了理解 CMEM 对生产应用的影响,下图比较了启用 CMEM 的双倍 HBM 带宽与启用 CMEM 的标准 HBM 带宽的性能。通过编译标志来禁用 CMEM,同时在 TPUv4 运行时禁用一个内核,使得一个内核的 HBM 带宽增加了一倍。
![]()
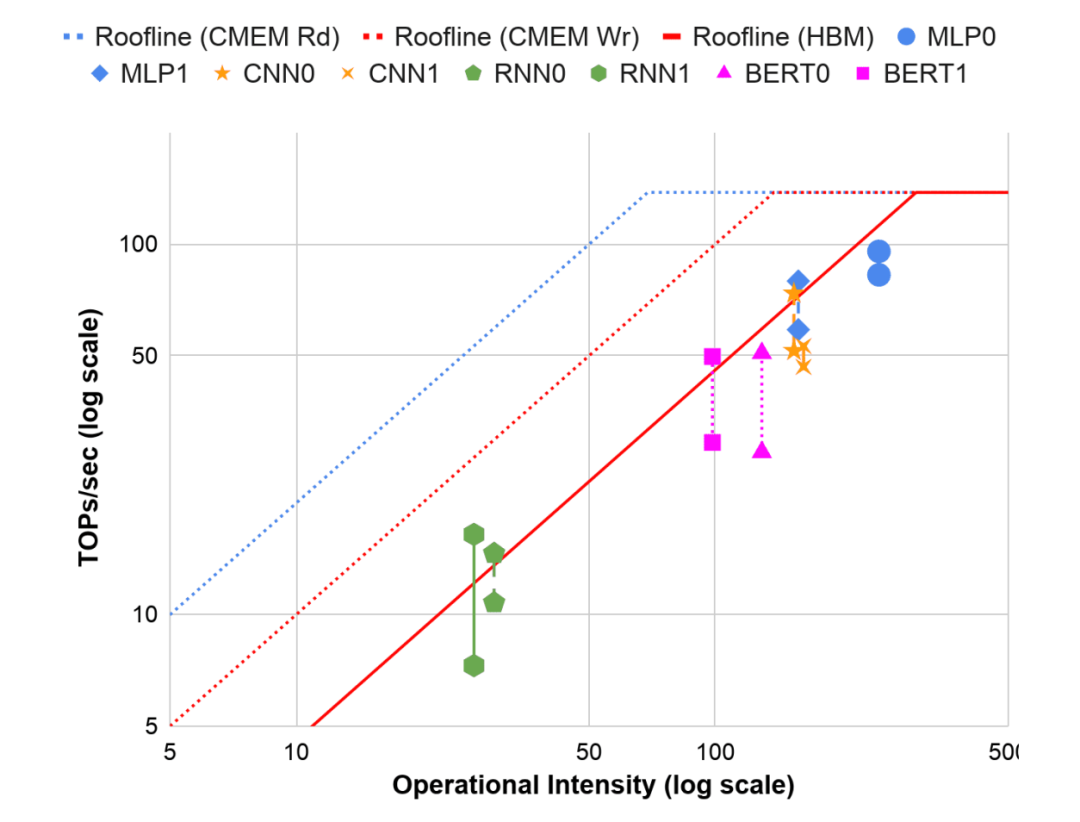
下图是借助 Roofline 模型解释内在原理。它将应用程序划分为计算受限或内存受限,使用操作强度来确定应用程序相对于其 Roofline 的位置。
![]()
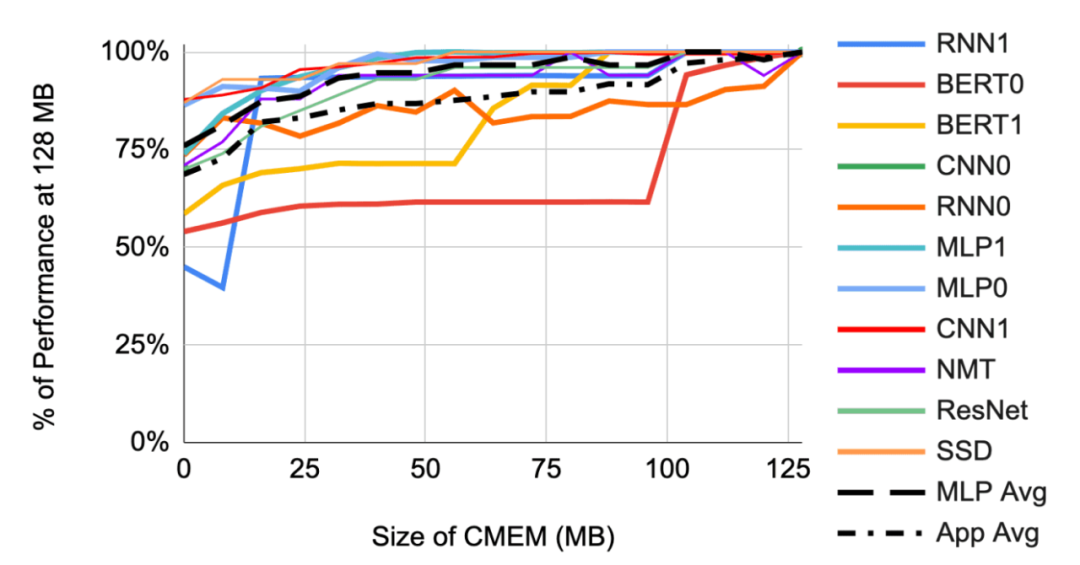
最后,下图展示了小于 128 MB 的 CMEM 对应用程序和 MLPerf 服务基准测试的影响。
![]()
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com