【沙龙干货】主题四:美团外卖中的单量预估及列表优化

讲师简介
王兴星,美团点评高级技术专家,负责外卖广告技术工作。加入美团前,担任搜狗广告技术部资深研究员,负责搜狗PC、无线联盟的整体算法工作。所研发的特征框架、训练系统应用于搜狗多个商业产品线。曾获多次公司年度最佳个人,广告技术部犀牛、MVP等奖项。他也是数据挖掘爱好者,曾获百度电影推荐大赛第一名、品友互动RTB算法竞赛Offline/Online第一名等奖项。
分享内容
相对于团购,外卖有三个特点:移动化、本地化、场景化。
移动化,从2011年开始到2015年移动战略是逐渐上升的。对应外卖2014年移动占比一下子占到75%以上,是更加移动化的一个产品。背后的一个原因是跟用户的使用场景有关系,比如我们进行定餐的时候,配送员会给我们打电话,天然的跟我们手机绑定在一起。
第二个就是本地化。在外卖里面目前最大的品类是美食,这个美食里面一公里以内它的一个战位基本上达到了65%左右。这个是非常强的限制,会对技术选型产生非常大的影响。
最后一个特点也是一个非常场景化的一个东西。外卖在一天里面订单随着时间的变化,有明显的两个波峰,对应背后的意义:一个是午餐的场景,一个是晚餐的场景。

从城市纬度去看订单量的预估,这个里面第一个出发点是什么?每个城市都会有波动,这个波动到底是否是正常的,这个时候我们需要进行人工,每天有一百多个城市都需要确认,这个工作量非常大。影响这个订单量背后的因素非常多,人工的方法很难确认到底这个波动由哪个因素造成的。即使找到了这个因素,这个因素带来的订单量增长的一个具体的数量,人工不太好确定的,这是是人工做的时候遇到的一些问题。

通过模型需要解决的问题:首先需要做自动的监控、报警;第二模型需要发现其中造成异常,这个异常的原因是什么;确定这个原因之后,那我们需要知道这个原因对我们订单量到底是什么样一个影响,是一个量化的事情。
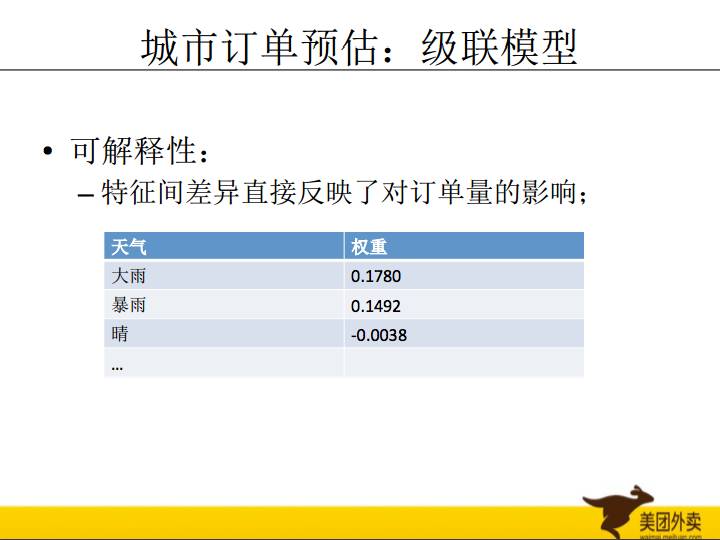
首先我们会利用历史订单建立一个自回归模型;第二步,会利用真实值/第一步预测值作为label,建立“倍数”模型。如果第二模型出来是一个1.2的值,我比第一步预测的基础之上我再涨20%。这样建模有两个优点:1,利用boosting的思想,精度得到进一步提升;2,借助于第二步的模型,做到较好的可解释性。
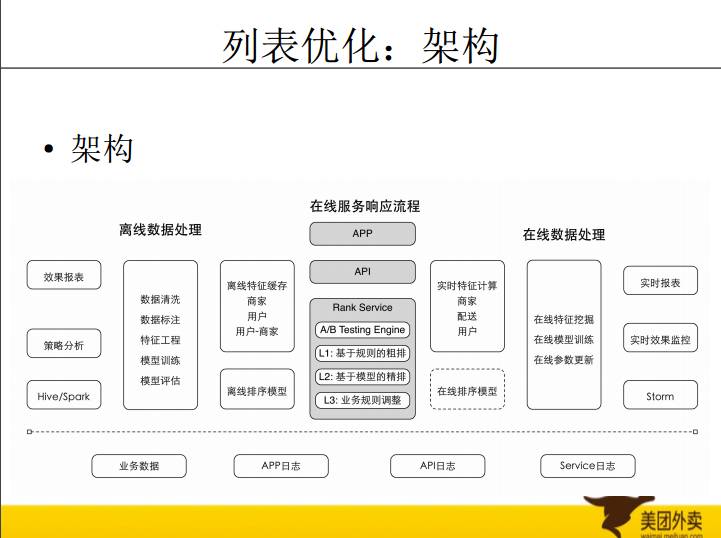
第二点我们来看列表的优化。
这个图是整个列表的一个架构,可以分为三个方面: 第一部分就是日志,这个数据分析、策略的源头;第二部分是我们离线处理,包括我们策略的分析、模型训练;第三部分为在线服务,前端打请求到API,API再请求对应的在线服务,这个有一些具体的模块:abtest测试框架,触发、排序框架,此外还有一些在线的实时的数据处理。
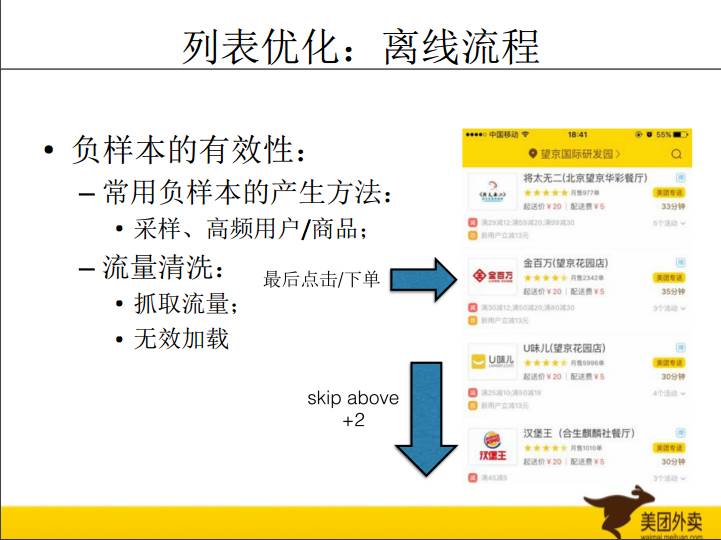
这模型训练过程中遇到的一个问题是如何选择负样本,正样本是用户显式的反馈。在很多场景都会遇到这个问题,没有负样本怎么办?会做负样本的选取。有几种方法:1,随机选取;2,选取用户没有行为的热门商品;3,从行为较多的用户的候选集合中选。负样本选取本质上是在猜可能看了什么但没发生行为,所以猜的越准,效果越好。在外卖列表场景下,我试了Skip-above的效果还不错。
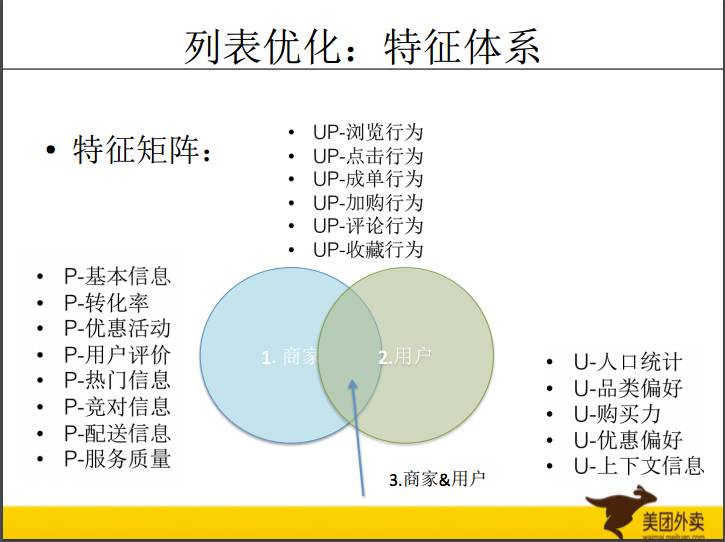
这是特征体系,传统做特征体系有三个方面,第一个是场景,第二个是用户,第三个是商品,两两相交,三者相交,有七个象限。在外面应用中,场景的特征不是太强,主要特征有三类就够了,一类是商家,第二个是用户,第三个是两者相交的部分,每个类型列举了一些例子。

树模型擅长处理稠密、枚举类型特征,这个是为什么在美团树模型比较流行的部分原因,因为纯在很多像评分、距离这样的连续类型特征,这个是线性模型不太擅长处理的。
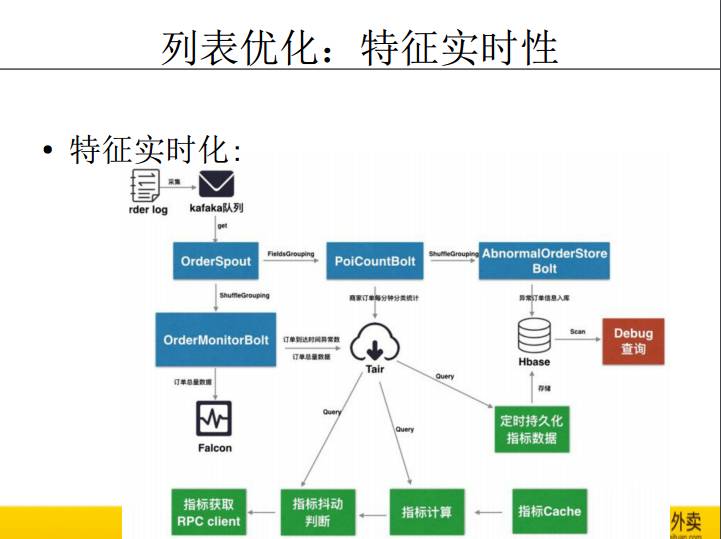
我们做实时性,通常有几种方案,一个方案,非统计类型的特征,直接做模型驱动,达到实时性;第二个方案是,特征都是统计类型的特征,多次训练模型差别不大,这个时候的实时性,通过实时更新特征达到的,例如商家活动力度可能实时变化;第三,就是两者的结合。
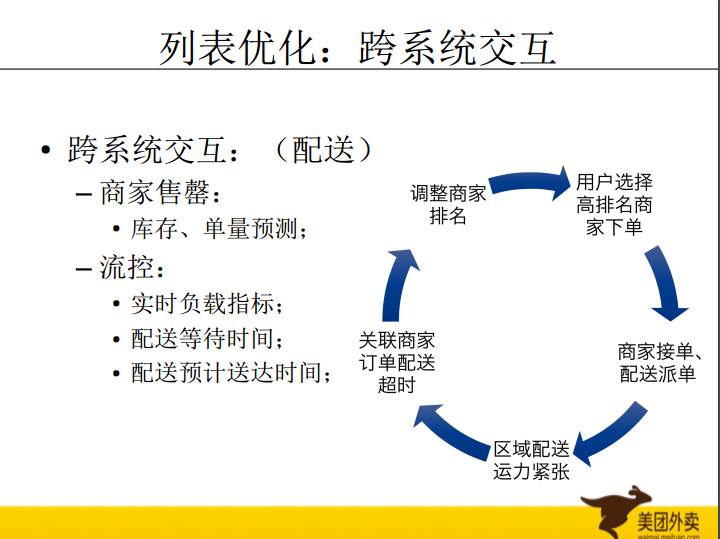
还有一个在这个里面比较头疼的地方,外卖跟传统的互联网有一些不一样的地方,会有一些非常强大的配送。配送会涉及到一些交互,例如商家配送时间变长了,这个时候我们反映在排序结果上。
此外,还有遇到一个新商家、新用户的问题,这是比较难做的地方。
几种可行的方案,第一个固定位置,定义好新商家规则,在这个位置上只出新商家,你符合规则在固定位置展示。这个方法优点是:简单,用户好理解,运营好操作,技术好实施。这个方法也会有一些问题,比如新商家的周期为一周,第一天展示的商家和第七天展示的商家,可以拿到信息的量是不一样的,可以区分对待,E&E是一个可以解决的方法;第三种解决方法,平台提供一个流量入口,你只要付出成本就可以获得流量,例如广告是一个比较合适的方案。
美团点评技术沙龙由美团-点评技术团队主办,每月一期,每期沙龙邀请美团-点评及其他互联网公司的技术专家分享来自一线的实践经验,覆盖各主要技术领域。





