图像标注哪家强?
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文转自AI公园
作者:Surya Remanan
编译:ronghuaiyang
给大家介绍图像标注的种类,应用场景,以及各种标注的优缺点。

介绍
“如果没有数据分析,公司就会变得既盲又聋,就像高速公路上的鹿一样在网络上游荡。”
— Geoffrey Moore
每个数据科学任务都需要数据。具体地说,是输入系统的干净易懂的数据。说到图像,计算机需要看到人类眼睛看到的东西。
例如,人类有识别和分类物体的能力。同样,我们可以使用计算机视觉来解释它接收到的视觉数据。这就是图像标注的作用。
图像标注在计算机视觉中起着至关重要的作用。图像标注的目标是为和任务相关的、特定于任务的标签。这可能包括基于文本的标签(类),绘制在图像上的标签(即边框),甚至是像素级的标签。我们将在下面探讨这一系列不同的标注技术。
人工智能需要的人工干预比我们想象的要多。为了准备高精度的训练数据,我们必须对图像进行标注以得到正确的结果。数据注释通常需要较高水平的领域知识,只有来自特定领域的专家才能提供这些知识。
需要标注的计算机视觉任务:
-
物体检测 -
线/边缘检测 -
分割 -
姿态预测/关键点识别 -
图像分类
1) 目标检测
进行目标检测的技术主要有两种,即2D和3D包围框。
对于多边形物体,可以使用多边形方法。让我们详细讨论一下。
2D 包围框
在这种方法中,只需要在被检测的物体周围绘制矩形框。它们用于定义对象在图像中的位置。边框可以由矩形左上角的x、y轴坐标和右下角的x、y轴坐标来确定。

优点和缺点:
-
标注起来快速和容易。 -
不能提供重要的信息,如物体的方向,这对许多应用来说是至关重要的。 -
包括不属于物体一部分的背景像素。这可能会影响训练。
3D 包围框或者立方体
类似于2D边框,除了它们还可以显示目标的深度。这种标注是通过将二维图像平面上的边界框向后投影到三维长方体来实现的。它允许系统区分三维空间中的体积和位置等特征。
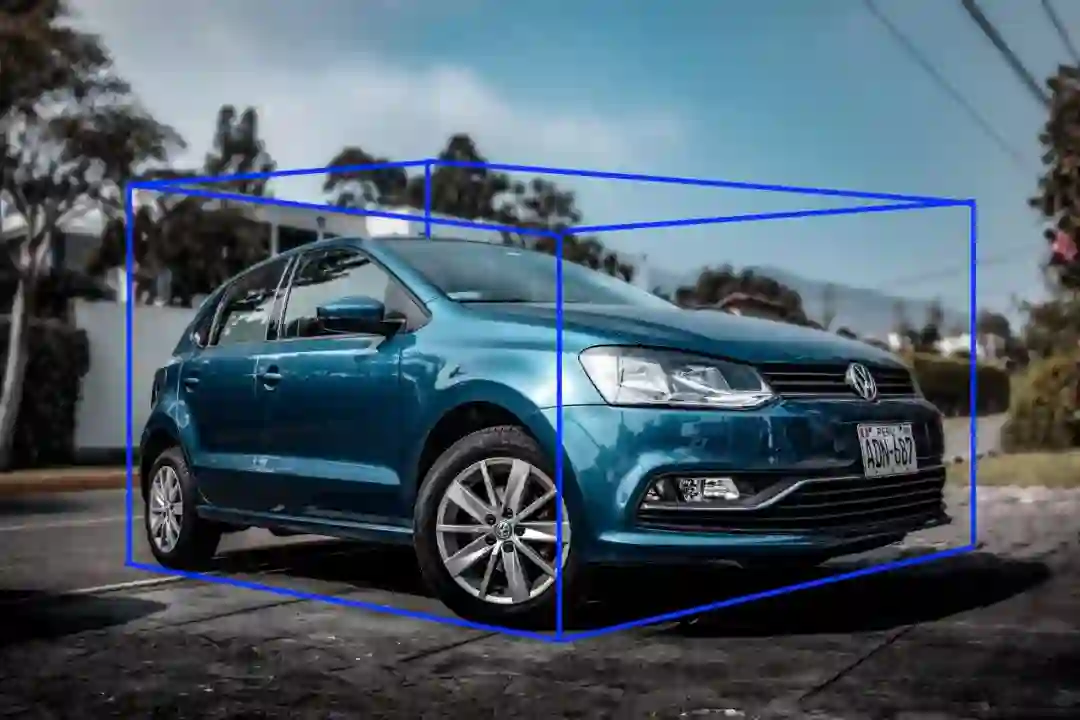
优点和缺点:
-
解决了物体方向的问题。 -
当物体被遮挡,这种标注可以想象包围框的维度,这可能会影响训练。 -
这种标注也会包括背景像素,可能会影响训练。
多边形
有时,必须标记形状不规则的物体。在这种情况下,使用多边形。注释时只需标记物体的边缘,我们就能得到要检测的物体的完美轮廓。

优点和缺点:
-
多边形标记的主要优点是它消除了背景像素,并捕获了物体的精确尺寸。 -
非常耗时,如果物体的形状是复杂的,很难标注。
注:多边形方法也用于物体形状的分割。我们将在下面讨论分割。
数据采集是ML冷启动的问题。但是,即使你有了一个可行的数据集,构建和测试模型也是需要技巧的。
2) 线/边缘检测(线和样条)
在划分边界时,线和样条是有用的。将区分一个区域和另一个区域的像素进行标注。

优点和缺点:
-
这种方法的优点是,连线上的像素不需要都是连续的。这样在检测有中断的线或部分遮挡的物体是非常有用的。 -
手动标注图像中的线是非常累人和费时的,特别是图像中有很多的线的时候。 -
当物体碰巧是对齐的时候,可能会给出误导的结果。
3) 姿态预测 / 关键点识别
在许多计算机视觉应用中,神经网络常常需要识别输入图像中重要的感兴趣的点。我们把这些点称为地标或关键点。在这种应用中,我们希望神经网络输出关键点的坐标(x, y)。

4) 分割
图像分割是将一幅图像分割为多个部分的过程。图像分割通常用于在像素级定位图像中的物体和边界。图像分割方法有很多种。
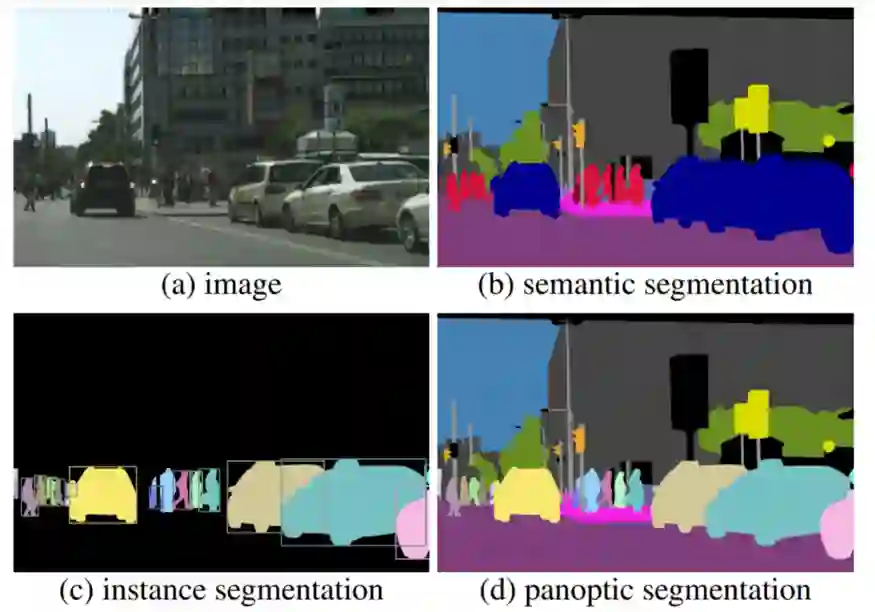
-
语义分割: 语义分割是一项机器学习任务,它需要像素级标注,其中图像中的每个像素都被分配给一个类。每个像素都带有语义意义。这主要用于环境背景非常重要的情况。 -
实例分割: 实例分割是图像分割的一种子类型,它在像素级别上标识图像中每个物体的每个实例。实例分割和语义分割是图像分割的两种粒度级别之一。 -
全景分割: 全景分割结合了语义分割和实例分割,所有像素都被分配一个类标签,所有目标实例都被唯一地分割。
5) 图像分类
图像分类不同于目标检测。目标检测的目的是识别和定位目标,而图像分类的目的是识别和识别特定的目标类。这个用例的一个常见示例是对猫和狗的图片进行分类。标注者必须为一只狗的图像分配一个类标签“dog”,对猫的图像分配类标签“cat”。

图像标注的用例
在本节中,我们将讨论如何使用图像标注来帮助机器模型执行特定行业的任务:
-
零售: 2D边框可以用于标注产品的图像,然后机器学习算法可以使用这些图像来预测成本和其他属性。图像分类在这方面也有帮助。 -
医学:多边形可用于在医用x射线中标记器官,以便将它们输入深度学习模型,以训练x射线中的畸形或缺陷。这是图像标注最重要的应用之一,需要医学专家具有较高的领域知识。 -
自动驾驶汽车:这是另一个重要的领域,图像标注可以应用。利用语义分割对图像中的每个像素进行标记,使车辆能够感知到道路上的障碍物。这一领域的研究仍在进行中。 -
情绪检测:这是里程碑,可以用来检测一个人的情绪(高兴,悲伤,或自然)。这可以应用于评估受试者对特定内容的情绪反应。 -
制造行业:线和样条可用于标注工厂的图像线跟随机器人工作。这可以帮助自动化生产过程,人力劳动可以最小化。
图像标注的一些挑战
-
时间复杂度:手工标注图像需要很多时间,机器学习需要大量的数据集,需要大量的时间来有效地标注这些基于图像的数据集。 -
计算复杂度:机器学习需要精确标注的数据来运行模型。如果标注者在给图像做标注的时候,注入任何一种错误,都可能会影响到训练,所有的努力都可能付诸东流。 -
领域知识:如前所述,图像标注通常需要特定领域的高级领域知识。因此,我们需要知道该标注什么的注解者,以及该领域的专家。

英文原文:https://heartbeat.fritz.ai/data-annotation-fundamentals-part-1-image-annotation-76f89ccf84f2
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com

扫描关注视频号,看最新技术落地及开源方案视频秀 ↓





