如何用 R 创作古诗
引子
最近中国诗词大会很受欢迎,才女武亦姝凭借超强的记忆力和超快的反应能力一炮走红,成为大家心目中的偶像。

在欣赏节目的同时,我也不禁想到,既然古代的诗人能够创作出这些美好的诗篇,那我是不是也能创作几首属于自己的诗词作品呢?可惜,经过一番尝试,我发现自身的文学功底不够,恐怕无法完成这样艰巨的任务。看来人和人还是有很大的差距。
当然,我并没有气馁。就像著名的无限猴子定理阐述的那样,哪怕是让一只猴子在打字机上随机地按键,只要按键的时间足够长,那么几乎必然能够打出任何特定的文字,甚至是莎士比亚的全套著作。我觉得我的编程能力应该比猴子还是要略强一筹,所以打算试试用我熟悉的语言R 来创作几首『歪诗』。
词频分析
既然要创作诗词,那么就要先了解诗词中最常出现的词汇和意象是什么。我在 github 上找到了一些古典中文的语料库(链接),其中有不少唐诗宋词的文本,只不过是繁体的。我选择了《宋词三百首》作为了我的文本库,对它进行词频分析。
其实做法很简单,大概就是分这么几步:
把文本拆分成一个一个的单词;
把单词按照出现的频率、次数进行排序
用可视化把结果展示出来
下面的部分我会讨论一下具体的操作,不感兴趣的观众请往后翻到结果的部分。
第一步、第二步
导入文本库:
> fileName <- "宋詞三百首.txt"
> SC <- readChar(fileName, file.info(fileName)$size)
# 大概检查一下
> substr(SC, 1000, 1100)
[1] "醒。送春春去幾時回,臨晚鏡。傷流景。往事後期空記省。○沙上並禽池上暝。雲破月來花弄影。重重簾幕密遮燈,風不定。人初靜。明日落紅應滿徑。\n\n詞牌:青門引\n作者:張先\n詞文:乍暖還輕冷。風雨晚來方定。庭軒寂"用分词包『结巴R』 (链接) 里面的 worker() 公式完成分词:
> cc = worker()
> analysis <- as.data.frame(table(cc[SC]))
# 重新排序
> analysis <- analysis[order(-analysis$freq),]
# 简单改变一下文件的命名、格式
> names(analysis) <- c("word","freq")
> analysis$word <- as.character(analysis$word)
# 看一下这个分词文件的开头
> head(analysis)
word freq
470 作者 310
6120 詞文 310
6121 詞牌 310
1024 又 75
1014 去 55
3124 月 54看来在宋词三百首中,出现最多的词语是『作者』,『词文』,『词牌』,总共出现了310次。这是因为每首诗词开始时,文档中都会介绍这首诗词的作者、词文和词牌,从而干扰了我们的文本分析。
第二步
我用 R 包 wordcloud2把结果简单地进行了一下可视化:
wordcloud2(analysis)然后得到了这张图。

嗯,硕大的一个『词文』出现了很多次,看来我们在可视化的时候要把它去掉。
我把出现频率大于300次的词语刨除之后,根据分词结果的字数(一字,二字,三字)重新进行了可视化,结果如下:
wordcloud2(analysis[analysis$freq>1& analysis$freq < 300 & nchar(analysis$word) == 1,])
wordcloud2(analysis[analysis$freq>1& analysis$freq < 300 & nchar(analysis$word) == 2,])
wordcloud2(analysis[analysis$freq>1 & analysis$freq < 300 & nchar(analysis$word) == 3,])

现在的结果就正常多了。我们看到,一个字的词语中,出现频率较多的有『谁』,『又』,『人』,『去』,『梦』, 『是』, 『处』,『月』 等等。

两个字的词语中,『何处』,『斜阳』,『相思』这些词使用频率最多,给我一种在看网络小说标题的感觉。

三个字的词语中,出现最多的往往是词牌名和作者名。
完成了简短的词频分析,下面就要开始最重要的『诗词创作』部分了!

诗词创作
准备
创作宋词,先要明确一个词牌名。我选择了李白的《清平乐·画堂晨起》作为范例。
画堂晨起,来报雪花坠。高卷帘栊看佳瑞,皓色远迷庭砌。盛气光引炉烟,素草寒生玉佩。应是天仙狂醉,乱把白云揉碎。
R 的中文分词包『结巴R』的功能中,有一项可以用来分辨词语的词性。我将范例进行分词后,再用这项功能分析一下各部分的词性。
> cipai <- "画堂晨起,来报雪花坠。高卷帘栊 看 佳瑞,皓色远 迷 庭砌。盛气光引 炉烟,素草寒生玉佩。应是天仙狂醉,乱把白云揉碎。"
> tagger <- worker("tag")
> cipai_2 <- tagger <= cipai
> cipai_2
n x x n v a n g v
"画堂" "晨起" "来报" "雪花" "坠" "高" "卷帘" "栊" "看"
x x a v x n x x x
"佳瑞" "皓色" "远" "迷" "庭砌" "盛气" "光引" "炉烟" "素草"
x nr x n x d p nr v
"寒生" "玉佩" "应是" "天仙" "狂醉" "乱" "把" "白云" "揉碎" 其中每个字母代表什么词性,我也没有很理解。据我的猜测,n 应该是名词,x是没有分辨出来的词性,v是动词, a是形容词,至于『nr』, 『p』, 『d』是什么,实在是猜不出来,在帮助文档中也没有找到。如果有朋友知道的话,希望能不吝赐教。
最后,我从之前提炼的宋词词频库中,选取了至少出现过两次的一字或两字词语,作为诗词创作的素材库:
> example <- subset(analysis, freq >1 & nchar(word) <3 & freq < 300)
# 提取词性文件
> cixing <- attributes(cipai_2)$names
# 将素材库进行词性分类
> example_2 <- tagger <= example$word创作
下面,我们终于要开始用 R 创作诗歌了!我自己想了一个创作的算法,可以说很简单,甚至说有点可笑。
步骤是这样的:我从范本词牌的第一个词开始,随机在素材库中选取词性相同,字数相等的单词,填入提前设置好的空白字符串中。
举个例子,原诗的第一个词是『画堂』,是个二字的名词。那么,我就在素材库中随机选择一个二字的名词,填入这个空间中。然后,继续分析下一个词。
具体方程的代码如下:
> write_songci <- function(m){
set.seed(m)
empty <- ""for (i in 1:length(cipai_2)){
temp_file <- example_2[attributes(example_2)$name == cixing[i]]
temp_file <- temp_file[nchar(temp_file) == nchar(cipai_2[i])]
empty <- paste0(empty, sample(temp_file,1))
}
result <- paste0(substr(empty, 1,4), ",",
substr(empty,5,9),"。",
substr(empty, 10,16), ",",
substr(empty, 17,22),"。",
substr(empty, 23,28), ",",
substr(empty, 29,34),"。",
substr(empty, 35,40), ",",
substr(empty, 41,46),"。")
}结果
做了这么多工作,终于到了验收结果的部分。请各位来欣赏几首 R 创作的歪词作品吧:
> lapply(1:5, write_songci)
[[1]]
[1] "幽香凝佇,春空賞花回。淨關塞旆感春歸,朝天淺爭前度。江聲已失無跡,香非凝笑秋千。過盡細雨歸鴻,欲對蓬萊歸來。"
[[2]]
[1] "流年漏永,春空愁腸覺。穩黃花笮收敗壁,數峰深鋪已斷。寄語舊香非煙,歸夢如夢殷勤。沈沈啼鶯老來,卻把丁香不堪。"
[[3]]
[1] "愁腸簾外,前度芳心困。少陽臺瘞切桃蹊,幾人細鎖新樣。腸斷缺月中酒,潘鬢行遍何曾。歸雁芳草修竹,不對秋水垂下。"
[[4]]
[1] "一川晏殊,阮郎斷鴻展。重暮雲菰訪楊花,畫閣滿聽金尊。敗葉孤城雪滿,晝永隋堤碧雲。無準黃金年光,漸因綺羅開時。"
[[5]]
[1] "煙柳清景,謝娘桃花如。窄蝴蝶琮誤中酒,花間碎挂斷煙。幽夢曉來千樹,蕭娘數峰翩翩。蟲網暗想未醒,曾向丁寧聚散。"既然是计算机生成的诗,自然谈不上什么文学性。不过,虽然大部分内容看上去不知所云,有些词句还是有些意思的,比如『幽香凝伫』,『愁肠帘外』,『孤城雪满』等等。之前在调试的时候,还出现过类似于『风烟泪暗霜前, 古岸频听金莲』这样的词句,无厘头之余,莫名地居然还有些押韵。
感想
这篇文章到此就结束了,希望大家读得还愉快。最后谈谈自己的感想。
很多读者可能会问,既然用 R 写出来的诗毫不合文理,为什么还要进行这样的工作呢?这种练习是不是在侮辱中文和古典诗词呢?我倒是觉得,我们对语言应该存有一种开放的态度。诗词说到底,也是一种风雅的文字游戏。我们又何尝不能抱着游戏的态度,把这个练习当做一个有趣的消遣呢?
用计算机代码作诗的主意并非是我原创。清华大学早在一年前就推出过作诗机器人薇薇,宣称可以通过图灵测试。


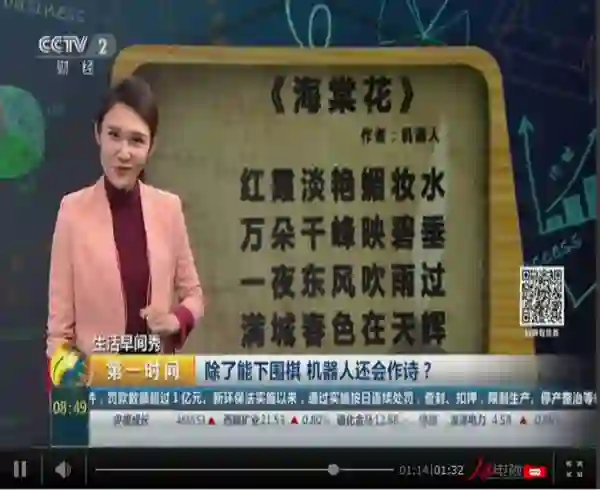
有些词句,如『何处东风约』,『万朵千峰映碧垂』等还是略显生硬,不过比我这里创作的诗词已经强的太多了。本文的小程序比较简短,总共只使用了不到50行代码,可以说是比较粗略的一个版本,仅供大家参考。感兴趣的读者可以设计更精密的算法,使用更高级的统计方法改进创作的质量。
古诗词向来被认为具有很高的艺术价值。今天的我们有越来越多的工具,可以系统化地总结、归纳诗词的规律,这大概也是过去的诗人怎么也想不到的。或许有一天,计算机真的能学习出作诗的秘诀,给我们带来更多全新的灵感和更好的诗句。我们拭目以待。
参考资料
古典中文语料库
jiebaR 的CRAN page
jiebaR 的帮助文档
R中的普通文本处理汇总
百度百科:清平乐
无限猴子定理
「归雁芳草修竹,不对秋水垂下。—— R」
∑编辑 | Gemini
知乎专栏:知叶堂

算法数学之美微信公众号欢迎赐稿
稿件涉及数学、物理、算法、计算机、编程等相关领域,经采用我们将奉上稿酬。
投稿邮箱:math_alg@163.com





