数据正负样本数不平衡的解决方法-SMOTE
点击蓝字关注这个神奇的公众号~
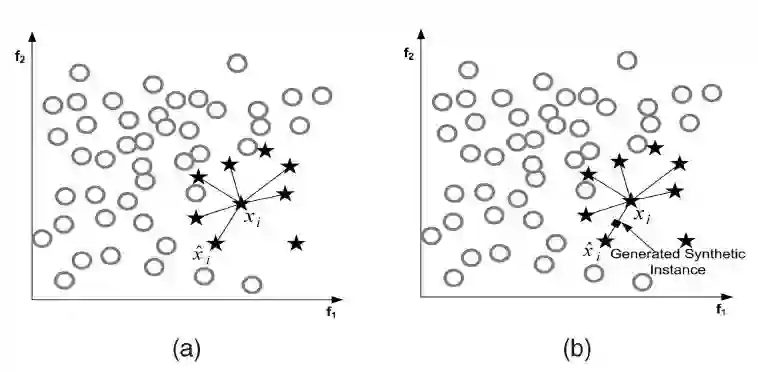
SMOTE(Synthetic Minority Oversampling Technique),合成少数类过采样技术.它是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别(Specific)而不够泛化(General),SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中,具体如下图所示,算法流程如下。
(1)对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻。
(2)根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为xn。
(3)对于每一个随机选出的近邻xn,分别与原样本按照如下的公式构建新的样本。
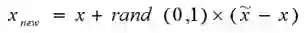
smote算法的伪代码如下:

马上登机了~觉得这个文章不错,火速分享给大家!
转自:http://blog.csdn.net/Yaphat/article/details/52463304?locationNum=7

你可以选择关注我
也可以不关注

微信号:凡人机器学习
长按二维码关注
登录查看更多
相关内容

专知会员服务
10+阅读 · 2020年4月4日
相关VIP内容
专知会员服务
10+阅读 · 2020年4月4日
相关资讯
相关论文