CVPR 2019 | 智能体张量融合,一种保持空间结构信息的轨迹预测

AI 科技评论按,本文是计算机视觉领域国际顶级会议 CVPR 2019 入选论文《Multi Agent Tensor Fusion for Contextual Trajectory Prediction》的解读。该论文由 MIT 支持的自动驾驶初创公司 ISEE Inc,北京大学王亦洲课题组,UCLA,以及 MIT CSAIL 合作共同完成。该论文主要提出了一种基于深度学习的车辆和行人轨迹预测方法,提出了一个可以保持空间结构信息的多智能体张量融合网络,在机动车驾驶和行人轨迹数据集中对模型的性能进行了验证。

正文内容如下,AI 科技评论获其授权转载。
· 简介 ·
人类驾驶员不断地预测其附近的车辆和行人未来的行为,从而避免与其他车辆和行人冲撞,以规划安全迅捷的行车路线。自动驾驶汽车也必须预测其他人和车的轨迹,以便在未来的社会互动发生之前主动规划,而不是被动地在意外发生后才作出反应。这样做可以尽量避免不安全的行为,如急刹车、急并道、急转弯等。从根本上来说,轨迹预测让自动驾驶车辆得以推断他们将遇到的未来可能情况,以评估特定规划相对于这些情况的风险,从而得以选择最小化该风险的行车规划。这为自动驾驶系统增加了一层可解释性,对于调试和验证至关重要。
轨迹预测问题之所以具有挑战性,是因为智能体的动作是随机的,并且取决于他们的目的地、与其他智能体的社会交互、以及其所在场景的物理约束。预测还必须对不同场景中不断变动的智能体数量和类型具有泛化性。基于神经网络的预测算法往往很难编码类似的信息,因为标准的神经网络架构只接受固定的输入、输出和参数维度;而对于这类预测任务,这些参数维度会因场景而异。之前的论文或利用面向智能体(agent-centric)的方法进行轨迹预测,例如 Social LSTM [1],Social GAN [2];或利用面向空间结构(spatial-centric)的编码方式解决这个问题,例如 Chauffeur Net [3]。面向智能体的编码在多个智能体的特征向量上运行聚合函数,而面向空间结构的方法则直接在鸟瞰视角的场景表示图上进行运算。
而多智能体张量融合(Multi-Agent Tensor Fusion, MATF)则提出了一种创新的多智能体张量融合编码器-解码器(Encoder-Decoder)网络架构。该架构结合了面向智能体和面向空间结构的轨迹预测方法的长处,通过端到端训练学习表示和推理有关社会互动和场景物理约束的所有相关信息。图 1 展示了 MATF 的核心张量 MAT 的构造,该张量在空间上将场景的特征编码与场景中每个智能体的过去轨迹的特征编码向量对齐,保持了静态场景以及多智能体的空间位置关系。接下来,通过全卷积网络(Fully Convolutional Layers)构造出融合的多智能体张量编码(见下一个小节)。这种编码方式一方面可以像面向空间结构的方法那样很自然地保持多智能体张量中的所有智能体和静态场景的空间结构以捕捉空间信息,另一方面也可以像面向智能体的方法那样敏感捕捉多智能体间的微妙社会互动。
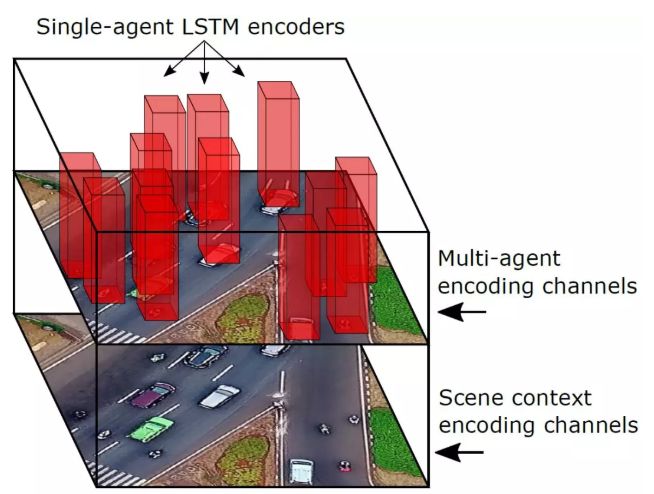
MAT 编码是一个鸟瞰视角的静态场景和动态多智能体的特征图(Feature Map),包括多智能体编码通道(Multi-Agent Encoding Channels)(上)和静态场景编码通道(Scene Context Encoding Channels)(下)。单智能体长短时记忆网络(Single Agent LSTM)编码器输出的多智能个体特征向量(红色)在空间上根据这些智能体的坐标对齐,构造出多智能体编码通道。多智能体编码通道与静态场景编码通道(场景编码全卷积网络的输出特征图)对齐,以保持智能体与场景间的空间结构。
MAT 紧接着将融合了社会互动和场景物理制约的 MAT 编码结果解码,以同时预测场景中所有智能体的未来轨迹。现实世界中人的行为不是确定性的,智能体可以在同一个场景中做出不同的行为,MATF 使用条件生成对抗训练(Conditional GAN)来捕获预测轨迹的这种不确定性。
MATF 对新提出的模型在驾驶数据集和行人人群数据集上进行了实验验证。该论文报告了来自以下数据集的结果:公开的 NGSIM 驾驶数据集,斯坦福无人机行人数据集(Stanford Drone dataset),ETH-UCY 人群数据集,以及最近收集的暂未公开的马萨诸塞州驾驶数据集。文章汇报了定量和定性实验结果,显示了模型每个部分的贡献。与领域最先进论文的定量比较表明所提出的方法在高速公路驾驶和行人轨迹预测方面都有着最好的表现。
· 网络架构 ·
多智能体张量融合(MATF)的网络架构简图如下所示:
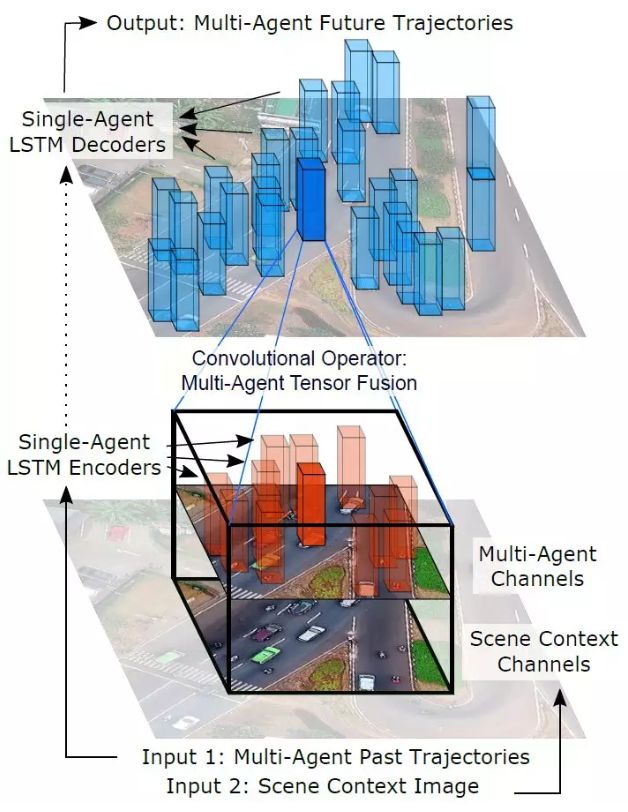
该网络的输入是在过去时间段内的所有智能体的轨迹,以及鸟瞰视角下的静态场景图像。每个智能体的过去轨迹和静态场景图像分别通过循环(Single-Agent LSTM Encoders)和卷积编码流独立编码。编码后的多智能体向量和静态场景特征图在空间上对齐以构造出多智能体张量。例如,图中 3-D 黑框(下方)显示的是橙色智能体周围的多智能体张量切片。
接下来,结构类似 U-Net 的全卷积网络(Convolutional Operator: Multi-Agent Tensor Fusion)作用在构造出的多智能体张量上,用以推断社会交互和空间物理约束,同时始终保持空间结构和空间局部性特征,该全卷积网络最终输出融合的多智能体张量(上方)。每个融合的智能体向量从该张量切片得出,包含了推理加工过的相应智能体的社会互动信息、自身历史轨迹信息、以及其周围的场景物理约束信息。值得指出的是,因为 MATF 架构运行共享卷积运算,所以在同一次正向传播中可以计算得出的所有智能体的相应融合向量。例如,实心蓝框(上方)所表示的智能体融合向量融合了来自卷积层感受野内的该智能体附近的所有智能体和场景特征的综合推断信息。
MATF 在此之后将这些融合的特征向量作为残差(Residual)加到相应智能体的原始编码向量上,以获得最终智能体编码向量。这些向量最终将被循环神经网络解码器(Single-Agent LSTM Decoders)独立地解码为网络对这些智能体的未来的轨迹的预测结果。MATF 整个架构是完全可微的,并且支持端到端的训练。
· 驾驶数据集实验结果样例 ·
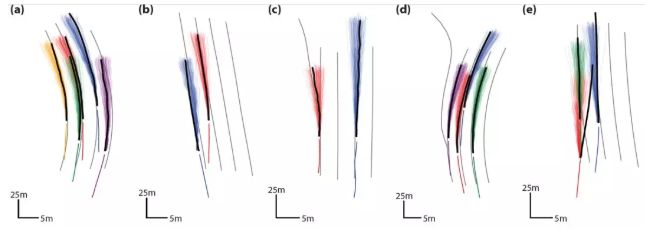
马萨诸塞州驾驶数据集的定性实验结果样例如上所示。每辆车的过去轨迹以不同的颜色显示,其后连接的是网络对这些车未来轨迹的预测的采样。正确结果(Ground Truth)的轨迹以黑色显示,车道中心以灰色显示。
(a)一个涉及五辆车的复杂情景;MATF 准确地预测了所有车的轨迹和速度分布;
(b)MATF 正确地预测了红色车辆将完成换道;
(c)MATF 捕捉到红色车辆是否将驶入高速公路出口的不确定性。
(d)当紫色车辆通过高速公路出口后,MATF 预测它将不会退出。
(e)在这里,MATF 无法预测精确的真实未来轨迹;然而,一小部分采样轨迹成功预测到了红色车辆将持续变道。
· 行人数据集实验结果样例 ·
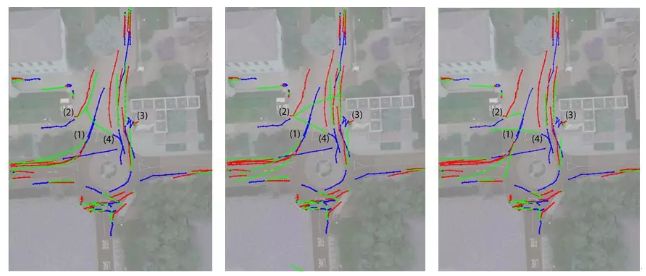
斯坦福无人机数据集的定性实验结果样例如上所示。从左到右分别是 MATF 多智能体-场景推断模型,MATF 多智能体-无场景推断模型,和 LSTM 基准模型的预测结果,所有用来预测的模型都是确定性模型。蓝线显示的是过去的轨迹,红色是真实的未来轨迹,绿色的是三个模型分别预测的未来轨迹。MATF 可以通过一个正向传播同时预测该图所示的所有的智能体的未来的轨迹。绿色的预测轨迹越接近红色的真实未来轨迹,预测就越准确。MATF 多智能体-场景推断模型成功预测了:
(1)两个人或自行车从顶部进入环形交叉口,并将向左驶出;
(2)环形交叉路口左上方路径的一位行人正在转弯向左移动到图像的顶部;
(3)一个人在环形交叉路口的右上方建筑物门口减速;
(4)在一个有趣的失败案例中,环形交叉路口右上方的人向右转,向图像顶部移动;该模型成功预测了此次转弯,但失败在无法预测转弯的急缓程度。
MATF 多智能体-场景推断模型正确预测了这些和其他各种场景的轨迹情形,其中一些情形也被 MATF 多智能体-无场景推断模型近似地预测了出来,但大多数情形都没有被基准的 LSTM 模型预测出来。
更多细节和实验结果请参考论文原文:
https://arxiv.org/abs/1904.04776
参考文献:
[1] A. Alahi, K. Goel, V. Ramanathan, A. Robicquet, L. Fei Fei, and S. Savarese. Social lstm: Human trajectory prediction in crowded spaces. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, 2016.
[2] A. Gupta, J. Johnson, L. Fei Fei, S. Savarese, and A. Alahi. Social gan: Socially acceptable trajectories with generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, 2018.
[3] M. Bansal, A. Krizhevsky, and A. S. Ogale. Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst. CoRR, abs/1812.03079, 2018.
由中国计算机学会主办、雷锋网和香港中文大学(深圳)联合承办的 2019 全球人工智能与机器人峰会( CCF-GAIR 2019),将于 2019 年 7 月 12 日至 14 日在深圳举行。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

今日限量赠送3张1000元门票优惠码,门票原价1999元,打开以下任一链接领券优惠850元,现价仅1149元,限量3张,送完即止。(打开以下任意一条链接即可兑换,先到先得)
https://gair.leiphone.com/gair/coupon/s/5cff23c18bcf3
https://gair.leiphone.com/gair/coupon/s/5cff23c18ba10
https://gair.leiphone.com/gair/coupon/s/5cff23c18b6ea




