智能医疗诊断等领域:在医疗领域,深度学习的发展为包括诊断在内的多个方面带来了革命性的发展。数据驱动的方法必然需求大量的有标注数据,而标注医疗图像不仅耗时耗力,而且需要特定的专业知识,所以利用主动学习选择模型难以预测的样本进行选择地标注是非常有实际意义的。 有很多论文在研究主动学习在医疗领域的应用,但在实际应用和落地中,医疗诊断面临的最首要的问题还是精度和泛化性能。由于医疗数据是小样本,这些最重要和最基本的问题没有被彻底解决,所以主动学习的热度并不大。但是还是有一些公司在应用,例如腾讯 AI Lab 使用主动学习和难例挖掘方案 中国首款智能显微镜获批进入临床:病理诊断 AI 化,腾讯 AI Lab 打造
虽然考虑到主动学习的出发点和要解决的问题都比较实际,但是目前的主动学习方法在实际应用的话还是存在一些问题。 性能不稳定:制约主动学习最大的问题就是性能不稳定。主动学习是根据自己指定的选择策略从样本中挑选,那么这个过程中策略和数据样本就是影响性能的两个很重要的因素。对于非常冗余的数据集,主动学习往往会比随机采样效果要好,但是对于样本数据非常多样,冗余性较低的数据集,主动学习有的时候会存在比随机采样还差的效果。数据样本的分布还影响不同主动学习的方法,比如基于不确定性的方法和基于多样性的方法,在不同数据集上的效果并不一致,这种性能的不稳定是制约人们应用主动学习的一个重要因素。 在实际应用中,需要先根据主动学习进行数据选择和标注,如果此时的策略还不如随机采样,人们并不能及时改变或者止损,因为数据已经被标注了,沉没成本已经产生了。而优化网络结构和性能的这些方法就不存在这个问题,人们可以一直尝试不同的方法和技巧使得性能达到最好,修改和尝试的损失很小。 而主动学习被要求得更加苛刻,几乎需要将设计好的策略拿来直接应用就必须要 work 才行,如果不 work,那些被选择的样本还是被标注了,还是损失时间和金钱。苛刻的要求和不稳定的性能导致人们还不如省下这个精力,直接采用随机的标注方式。 脏数据的挑战:现在几乎所有的论文都在公开的数据集、现成的数据集上进行测试和研究。而这些数据集其实已经被选择和筛选过了,去除了极端的离群值,甚至会考虑到样本平衡,人为的给少样本的类别多标注一些,多样本的类别少标注一些。而实际应用中,数据的状况和这种理想数据集相差甚远。主动学习常用不确定性的选择策略,不难想象,噪声较大的样本甚至离群值总会被选择并标注,这种样本可能不仅不会提升模型的性能,甚至还会使性能变差。 实际中还存在 OOD(out of distribution)的问题,例如想训练一个猫狗分类器,直接从网络中按关键字搜索猫狗收集大量图片,里边可能存在一些老虎、狮子、狼等不在猫狗类别的无关样本,但是他们的不确定性是非常高的,被选中的话,并不会提升模型的性能。 难以迁移:主动学习是一种数据选择策略,那么实际应用中必然需求更通用、泛化性更好的主动学习策略。而目前的主动学习策略难以在不同域、不同任务之间进行迁移,比如设计了一个猫狗分类任务的主动学习策略,基于不确定性或多样性,达到了较好的性能,现在需要做一个新的鸡鸭分类的任务,那么是否还需要重新设计一个策略?如果任务是病变组织的分类呢? 由于不同任务的数据分布特点可能不一样,不同任务的难易不一样,无法保证主动学习的策略能够在不同数据不同任务中通用,往往需要针对固定的任务设计一个主动学习策略。这样就耗费了精力,如果能有一个通用性好的主动学习策略,那么就可以被不同任务迁移,被更广泛地应用,甚至直接将其部署为通用标注软件,为各种任务、数据集,提供主动选择和标注功能。 交互不便:数据选择策略与标注过程联系紧密,理想的流程是,有一个整合的软件能够提供主动数据选择,然后提供交互界面进行标注,这就是将主动学习流程与标注软件结合。仅有高效的主动学习策略,而不方便标注交互,也会造成额外的精力浪费。在流程上,现在主动学习普遍是选择出一批待标注的样本后,交给人们去标注,而期望人们能尽快标注交给模型,模型继续训练后再次选择。 人们标注的时候,模型既不能训练,主动学习也不进行其他操作,是个串行的过程,需求等待人工标注结束后,才能进行接下来的训练。这样的流程就不那么方便和高效,想象把主动学习+标注的系统给医生应用,策略先选出了一些样本,医生仅标注这些样本就标注了几天,然后再给模型训练,模型训练一段时间后,又选择出一些样本给医生,医生和模型互相等待对方的操作,降低了效率和便利性。
最新研究方向及论文推荐
下面我介绍一些主动学习目前最新的阅读价值较高的论文,供大家把握研究方向和热点。如果大家有兴趣,可以持续关注我 github 上的 awesome-active-learning paper list,我会实时更新有价值的主动学习方面的工作,供大家学习和交流。
8.1 主动学习问题和方法的探究
目前主动学习的基本方法和问题还存在一些不足,有一些最新的方法试图解决这些问题。 Mind Your Outliers! Investigating the Negative Impact of Outliers on Active Learning for Visual Question Answering (作者之一,李飞飞)
Contrastive Coding for Active Learning Under Class Distribution Mismatch:https://openaccess.thecvf.com/content/ICCV2021/html/Du_Contrastive_Coding_for_Active_Lea
基于以下假设:标记数据和未标记数据是从同一类分布中获得的,主动学习 (AL) 是成功的。然而,它的性能在类别分布不匹配的情况下会恶化,其中未标记的数据包含许多标记数据的类分布之外的样本。为了有效地处理类分布不匹配下的AL问题,作者提出了一种基于对比编码的 AL 框架,名为 CCAL。 与现有的 AL 方法专注于选择信息量最大的样本进行标注不同,CCAL 通过对比学习提取语义和独特的特征,并将它们组合在查询策略中,以选择具有匹配类别的信息量最大的未标记样本。理论上,作者证明了 CCAL 的 AL 误差具有严格的上限。 LADA: Look-Ahead Data Acquisition via Augmentation for Active Learning:
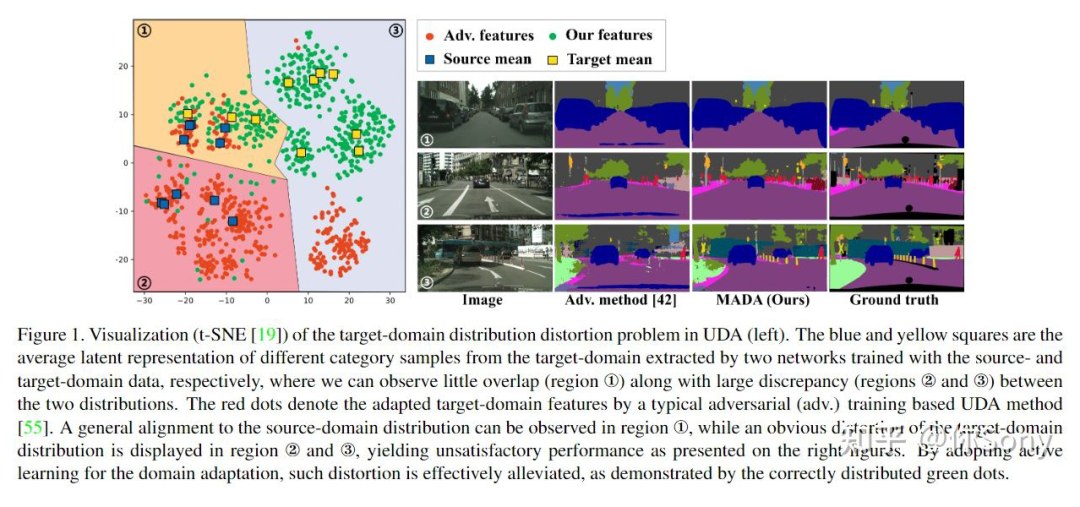
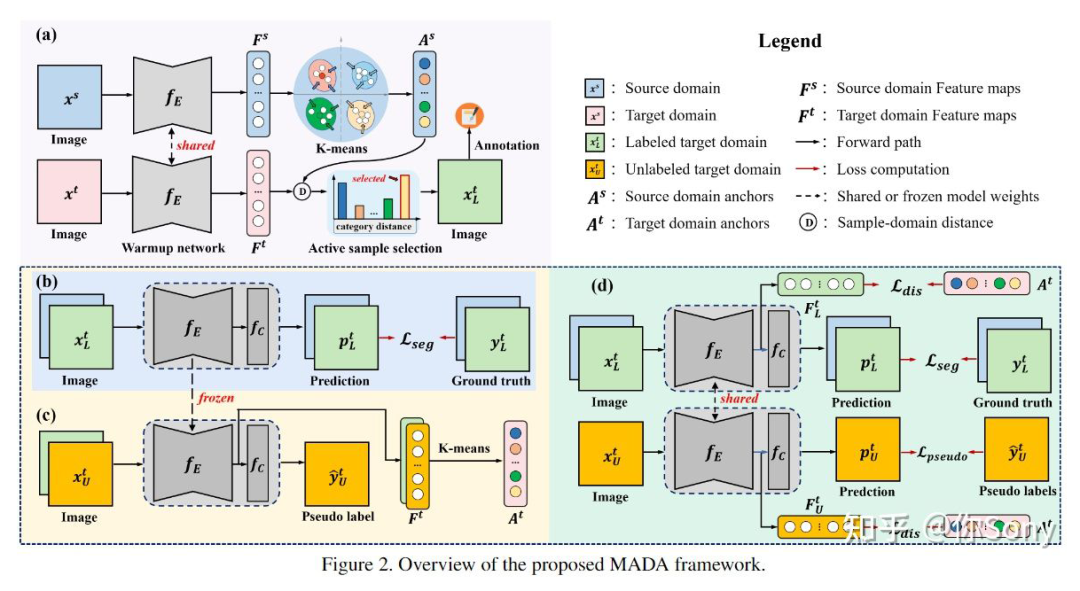
8.3 主动学习与无监督域自适应结合 无监督域自适应要对齐目标域与源域,使模型利用源域的数据和标签,在无标签的目标域上取得较好的性能。目前出现一些工作考虑源域和目标域的关系,设计了主动学习策略提升模型在目标域的性能。 Multi-Anchor Active Domain Adaptation for Semantic Segmentation:https://arxiv.org/abs/2108.08012 将目标域的分布无条件地与源域对齐可能会扭曲目标域数据的特有的信息。为此,作者提出了一种新颖的基于多锚点的主动学习策略,以协助域自适应语义分割任务。通过创新地采用多个点而不是单个质心,可以更好地将源域表征为多模态分布,实习从目标域中选择更具代表性和互补性的样本。手动注释这些样本的工作量很小,可以有效缓解目标域分布的失真,从而获得较大的性能增益。另外还采用多锚策略来对目标分布进行建模。通过软对齐损失,对多个锚点周围紧凑的目标样本的潜在表示进行正则化,可以实现更精确的分割。
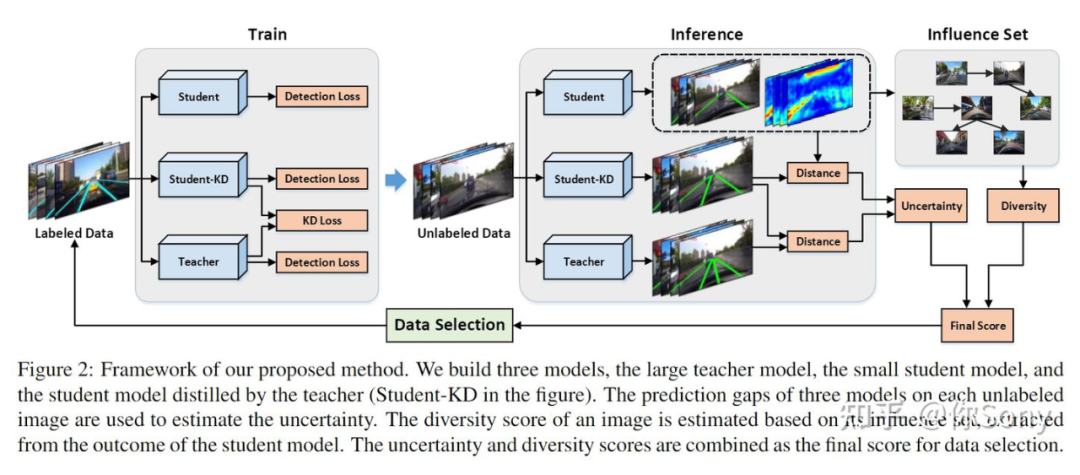
8.4 主动学习与知识蒸馏结合 知识蒸馏过程中,teacher 给 student 传递知识,但是什么样的样本能够帮助这一过程,也是主动学习可以研究的一个方向。 Active Learning for Lane Detection: A Knowledge Distillation Approach:
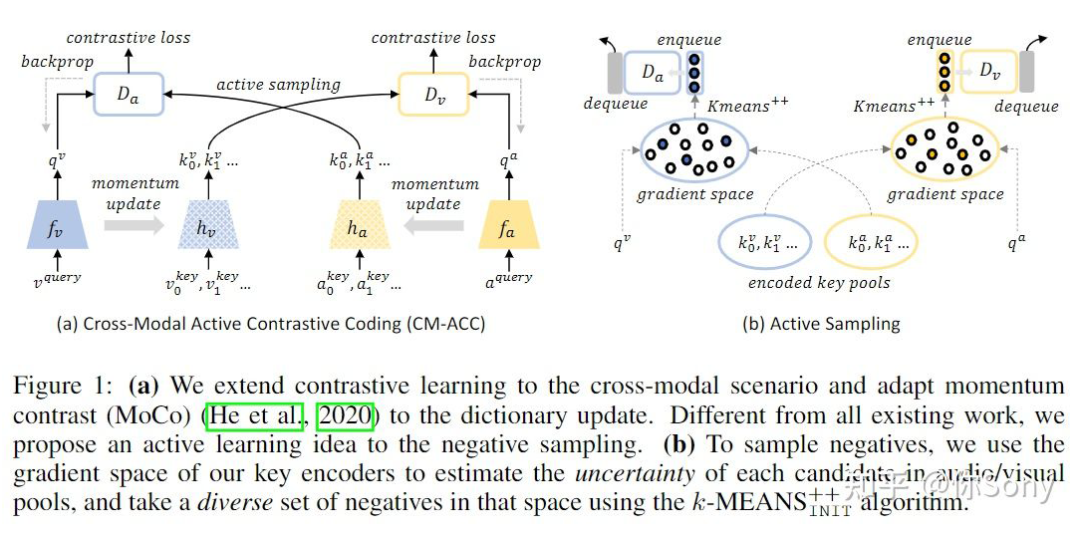
8.5 主动学习与对比学习结合 对比学习最近势头比较猛,最近也有主动学习与对比学习结合解决对比学习的问题,大家可以欣赏一下。 Active Contrastive Learning of Audio-Visual Video Representations:https://arxiv.org/abs/2009.09805 对比学习已被证明可以通过最大化实例的不同视图之间的互信息(MI)的下限来生成音频和视觉数据的可概括表示。然而,获得严格的下限需要 MI 中的样本大小指数,因此需要大量的负样本。我们可以通过构建一个大型的基于队列的字典来合并更多的样本,但是即使有大量的负样本,性能提升也存在理论上的限制。 作者假设随机负采样导致高度冗余的字典,导致下游任务的次优表示。在本文中,作者提出了一种主动对比学习方法,该方法构建了一个 actively sampled 字典,其中包含多样化和信息丰富的样本,从而提高了负样本的质量,并提高了数据中互信息量高的任务的性能,例如,视频分类。
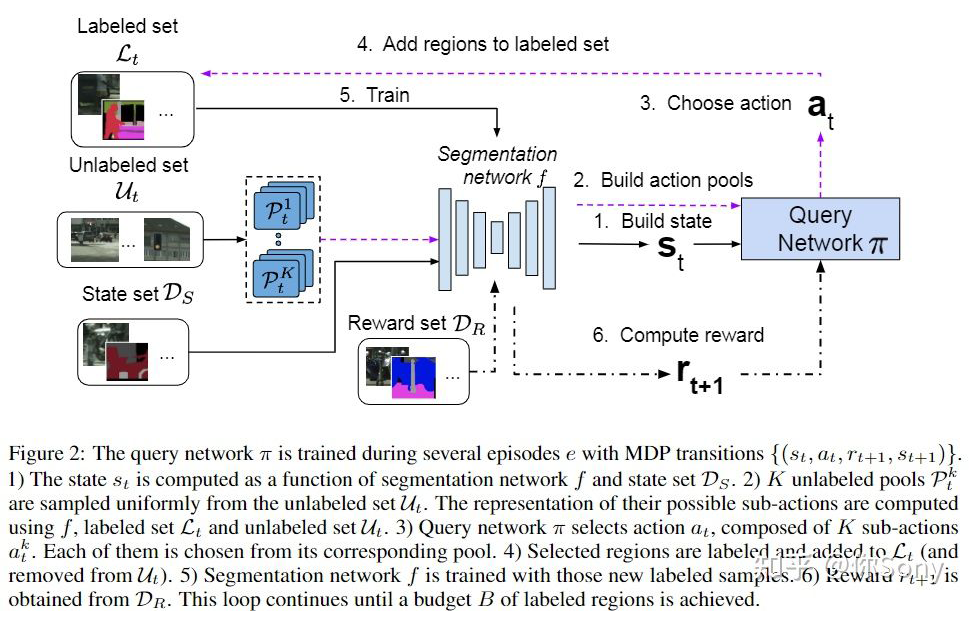
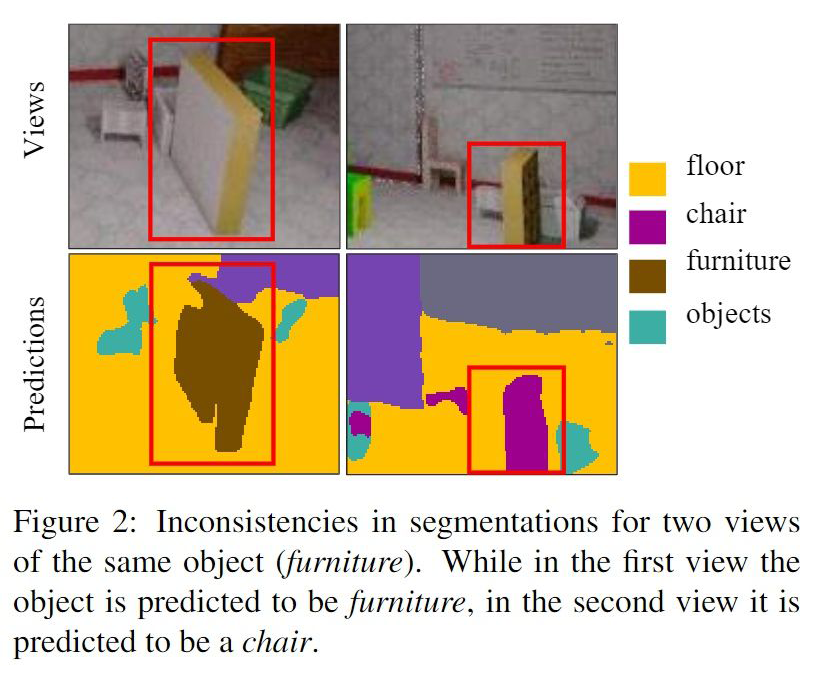
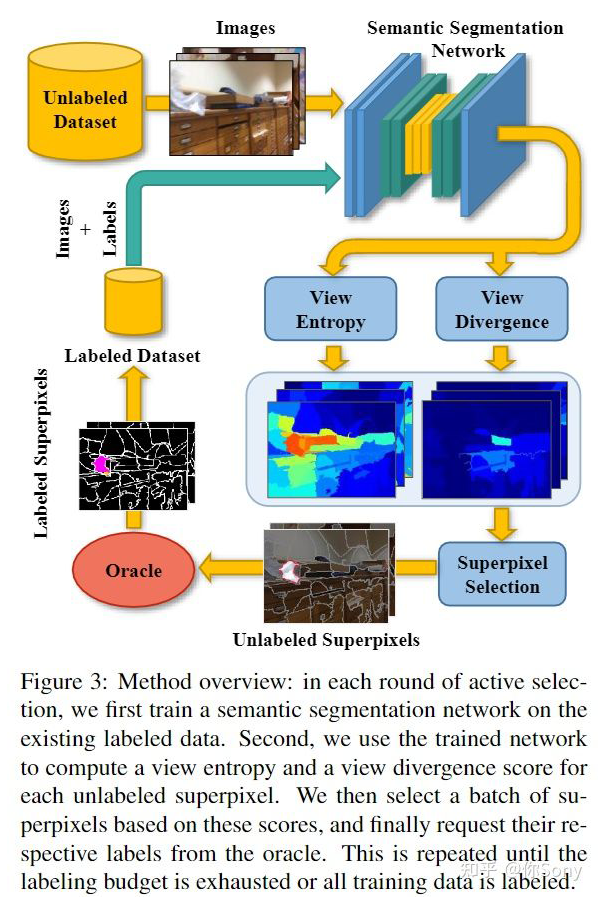
8.7 主动学习在点云方面 点云比图像的标注时间更长更费精力,尤其是像素级的点云标注。近期主动学习在点云方面的工作渐渐崭露头角,而且效果非常惊人,值得期待。下面我介绍一篇有代表性的点云语义分割的工作。 ViewAL: Active Learning with Viewpoint Entropy for Semantic Segmentation: