性能不打折,内存占用减少90%,Facebook提出极致模型压缩方法Quant-Noise
机器之心报道
机器之心编辑部
对于动辄上百 M 大小的神经网络来说,模型压缩能够减少它们的内存占用、通信带宽和计算复杂度等,以便更好地进行应用部署。最近,来自 Facebook AI 的研究者提出了一种新的模型量化压缩技术 Quant-Noise,让神经网络在不降低性能的前提下,内存占用减少 90% 以上。

论文地址:https://arxiv.org/abs/2004.07320
项目地址:https://github.com/pytorch/fairseq/tree/master/examples/quant_noise

将名为「Quant-Noise」的量化噪声应用到权重的随机子集上,来学习更适用于 int4、 int8 和 PQ 算法等各种量化方法的网络;
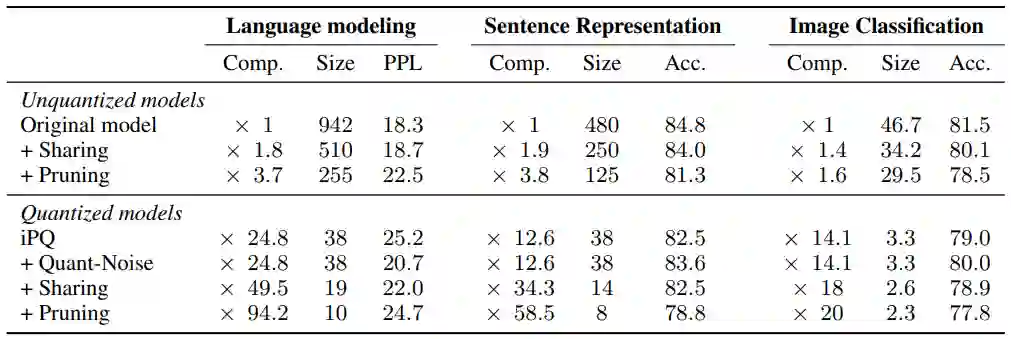
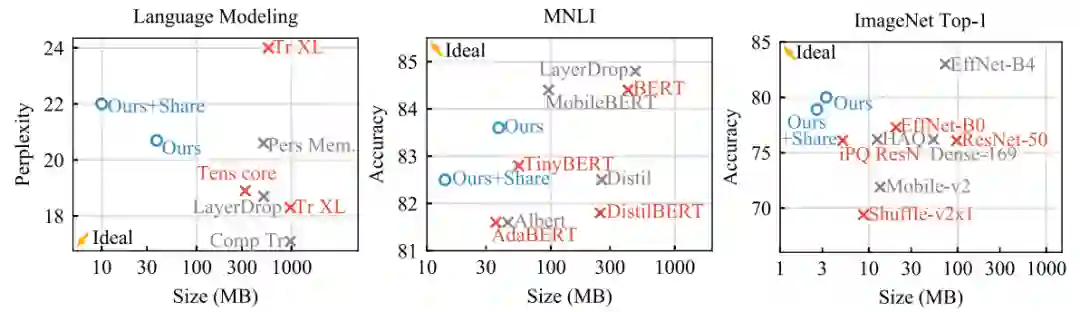
在 PQ 算法上添加 Quant-Noise,实现准确率和模型大小综合结果上的 SOTA 水平。使用该方法进行压缩后,在自然语言处理方面,RoBERTa 在压缩到 14MB 的前提下,在 MNLI 上实现了 82.5% 的准确率;在计算机视觉方面,EfficientNet-B3 在压缩到 3.3 MB 的前提下,在 ImageNet 上实现了 80.0% 的 top-1 准确率。
使用 Quant-Noise 训练的网络,通过结合 PQ 算法和 int8 来量化网络的权重和 activation,获得在固定精度计算条件下的极致压缩效果,实现了 ImageNet 数据集上的 79.8% top-1 准确率和 WikiText-103 数据集上的 21.1 困惑度。
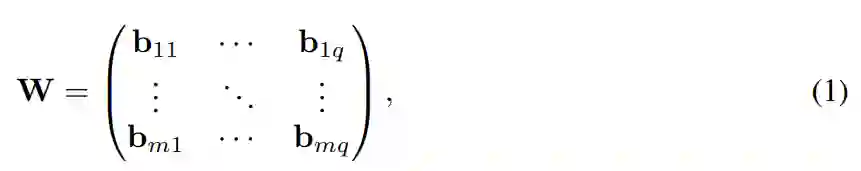
 ,
使得 b_kl = c [I_kl]。
研究者将标量量化(如 int8,即每个块 b_kl 由一个权重组成)与向量量化(将多个权重共同量化)区分开来。
,
使得 b_kl = c [I_kl]。
研究者将标量量化(如 int8,即每个块 b_kl 由一个权重组成)与向量量化(将多个权重共同量化)区分开来。

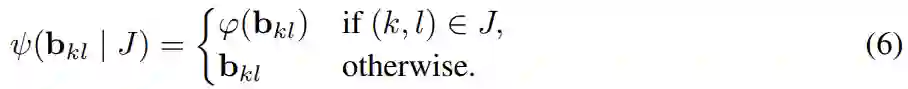



登录查看更多
相关内容
Arxiv
5+阅读 · 2018年4月5日



相关VIP内容
相关资讯