近期热门领域新鲜数据集汇总!

来源:程序媛的日常
本文长度为2721字,建议阅读4分钟
本文为你分享一些新颖的数据集,涵盖了阅读理解、对话系统、新闻摘要等热门领域。
今天想跟大家分享一些近期看到的比较新颖的数据集。随着很多基础设置下的简单问题被解决,想要去检验一个模型是否具有更强的能力,就需要更好的更复杂的数据集做支持。由此,许多研究者通过各种方法爬取、构造了一些高质量且有新意的数据集。今天想分享的涵盖了许多热门领域:阅读理解、对话系统、新闻摘要等。
Johannes Welbl, Pontus Stenetorp, Sebastian Riedel. "Constructing Datasets for Multi-hop Reading Comprehension Across Documents". arXiv preprint 2017.
Mandar Joshi, Eunsol Choi, Daniel Weld, Luke Zettlemoyer. "TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension". ACL 2017.
Yanran Li, Hui Su, Xiaoyu Shen, Wenjie Li, Ziqiang Cao, and Shuzi Niu. "DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset". IJCNLP 2017.
Layla El Asri, Hannes Schulz, Shikhar Sharma, Jeremie Zumer, Justin Harris, Emery Fine, Rahul Mehrotra, Kaheer Suleman. "Frames: A Corpus for Adding Memory to Goal-Oriented Dialogue Systems". SIGDIAL 2017.
Hannes Schulz, Jeremie Zumer, Layla El Asri, Shikhar Sharma. "A Frame Tracking Model for Memory-Enhanced Dialogue Systems". arXiv preprint 2017.
Shereen Oraby, Vrindavan Harrison, Lena Reed, Ernesto Hernandez, Ellen Riloff, Marilyn Walker. "Creating and Characterizing a Diverse Corpus of Sarcasm in Dialogue". SIGDIAL 2016.
Piji Li, Lidong Bing, Wai Lam. "Reader-Aware Multi-Document Summarization: An Enhanced Model and The First Dataset". Proceedings of the EMNLP 2017 Workshop on New Frontiers in Summarization (EMNLP-NewSum'17).
一
第一个要分享的是一篇多轮/级推理阅读理解数据集的论文(Multi-hop Reading Comprehension)[1]。这个项目名叫 QAngaroo,并且在论文中通过同样的方法构造了两个多轮推理阅读理解数据集,一个叫 WikiHop 一个叫 MedHop。
以 WikiHop 为例。现有的大部分 RC 数据集经常只需要利用局部信息匹配(问题中的词和原始文档中的词)就可以找到准确答案。这样的数据集其实对于模型的推理能力要求很低。为了测试推理能力(multi-step inference),以 Wikipedia 文章为例,很多时候为了回答一个问题,可能需要综合多篇文档中的信息(evidence piece)来得到一个最终答案。看论文中给出的例子:

这篇论文不仅给出了基于二部图的构造数据的方法,还在构造了最初的原始数据后,进行了重采样,从而减缓数据集的偏见(bias)。他们还将现有的一些比较常用的 RC 模型在自己新制作的数据集上进行了评测,发现哪怕是基于神经网络的 RC 模型也只能达到 42.9% 的正确率,而人类则可以达到 74%。也因此,他们认为现有的模型还有很大提升空间。
二
另一份多轮推理的阅读理解数据集来自 ACL 2017 的工作[2]。这篇工作中提出的数据集叫做 TriviaQA,它主要有以下三大特点:
数据集中的文本的句法比较复杂,需要很多复合信息
数据集中的文本的语法和用词也比较复杂,简单的文本匹配方法可能会失效
数据集中的信息常常跨过多句,为了得到答案需要多级推理(cross sentences)
也因此,它和上文的 WikiHop 的区别还是比较明显的。一个是跨文档推理,一个是跨句推理。一个是简单的问题(query),一个是复杂的句法。来看一个 TriviaQA 的例子:

在这篇论文中,他们还给出了一个横向对比几大 RC 数据集的表格。由此可见,他们非常在意能否有比较强的 Evidence Excerpt。

最后,和 WikiHop 一样。现有的 RC 模型在 TriviaQA 上表现并不佳,大概也是 40% 和 80%(人类表现)的差距,还有很大提升空间。
三
分享完两篇阅读理解的数据集,来看看同样很火的聊天对话的数据集。这篇论文[3] 中给出了一个针对日常聊天场景的多轮对话数据集 DailyDialog。作者指出,现在已有的对话数据集很多并非源自真正的对话,比如主流的有来自微博和 Twitter 这种社交网络的 post-reply pair,也有来自电影台词的。前者往往会掺杂很多非正式的缩写与网络用语,而且也会有信息残缺的问题;后者中的台词往往过短,台词轮数过多,导致模型训练不够好。
为了挖掘更好的能服务于日常沟通的对话模型,作者通过爬取英语口语对话网站构造了 DailyDialog 这个数据集。因为是日常生活中的对话,所以对话涵盖了很多情感信息,也有很多比较自然的对话模式。可以看一个作者给出的例子:

在上面的例子中,紫色加下划线的词有比较明显的情感倾向。可以看到对话中,A 先是比较苦恼,后在 B 的宽慰和开导下有了一些转变。从 B 的话语中也可以看到,B 能主动询问 A 为什么苦恼,以及给 A 提供一些建议(斜体字)。而这些建议往往涵盖着新的信息,也是我们日常对话中能增进互动的一种表达方式。
为了让模型能更好地学习这些日常对话中的特征,作者将爬取的语料进行了人工标注。每一个对话中的每一轮对话(utterance turn)都标注有 dialog act 和 emotion 两种信息。这也可以说是比较少见的在对话语料中同时含有这两类信息的数据了。以下就是这份数据的一些简单统计:
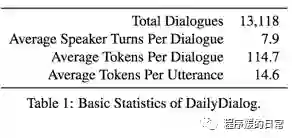
四
继续说对话的数据集。刚才的 DailyDialog[3] 主要针对的还是比较偏闲聊(chit-chat)的对话语料(其中也有一些 task-oriented 的,但比较少且不典型)。下面要介绍的这份语料 Frame,来自 Maluuba 团队[4][5] 则主要是针对 task-oriented 也就是任务导向型对话的新语料和新任务。
Frame 这个数据集之所以叫这个名字,主要是其论文中[4]提出了一种新任务,叫 Frame Tracking。区别于传统任务导向型对话中的 Dialogue State Tracking(DST)是以每个对话轮(turn)为粒度,Frame 相当于将对话切割成了更大更粗粒度的一个个小目标。以一个例子来说明,比如我们在定制一次旅行计划的时候,往往会很向对比很多个目标(酒店、机票、城市组合等),这些横向对比的小目标可能是在几个对话轮中都提到的,又可能在对话进行到后面的时候重新被提起(比如做横向比较的时候),那么这些时候就会涉及到 frame refering 的问题。
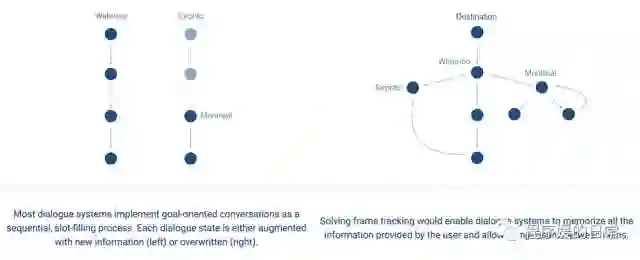

上图是一个对话案例。可以看到整个对话中,共构成了两个 frame,基本可以认为是两种不同的旅行计划。而对话的任务请对话系统帮忙判断哪个旅行计划更优。那么这个更优就和传统的任务导向型对话很相关,因为也涉及了很多用户约束(比如哪天出行,比如价格范围等)。所以说 frame tracking 这个任务中的 frame 几乎 DST 任务中的 semantic frame 的一个超集(有一点点例外,详细请看论文)。
五
在论文[4] 中,Frame tracking 这个任务是这样定义的:已知用户说的每句话,并且每句话有 dialogue acts,slot typles,slot values 这些标签,请将每个 dialogue act 相应的话进行分类,对应到其正在讨论的 frame。如果对于这个任务还是不好理解,则可以看论文[5] 中对这个任务的数据进行的一些分析,里面给出了一些 frame 变化的场景和案例。
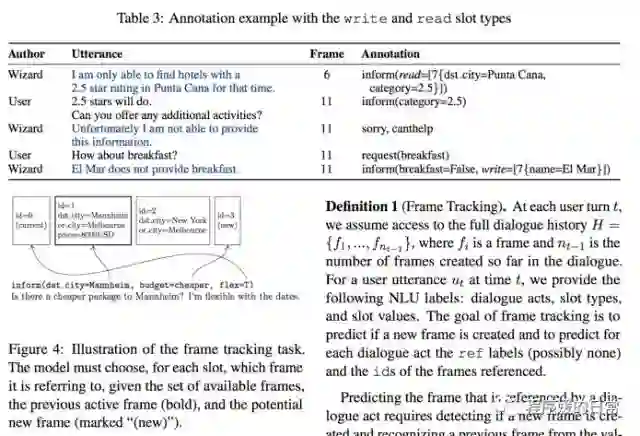
六
下面要分享的这个语料有一点特别,虽然也是对话语料,但是是针对对话中的讽刺语现象的[6]。
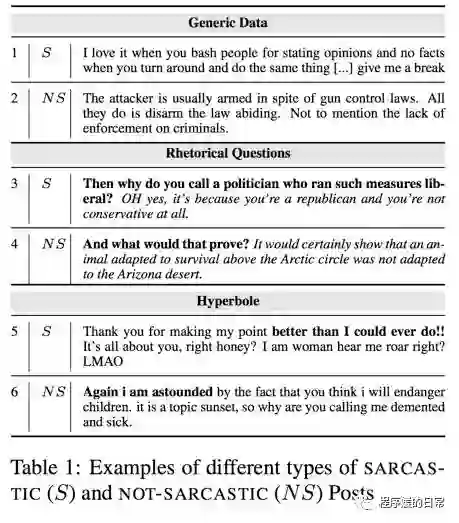
在这份语料中,作者给出了主要四种数据:一般形式的讽刺语(general)、比喻型的讽刺(rhetorical questions)、夸张型的讽刺(hyperbole),和非讽刺语(负样本)。
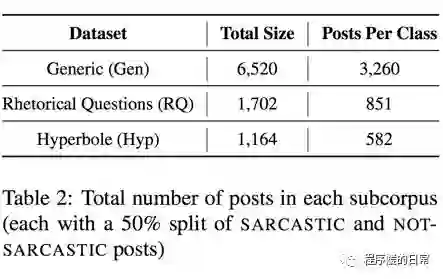
为了表示自己的标注质量很高,作者也给出了一些特征和有监督的训练模型来检验。并根据这些特征给出了一些讽刺语的语言现象分析。对于这方面感兴趣的同学还是很值得看一下这份语料的。比如说,以下这些词就是很强烈的讽刺语提示词:

七
最后要分享的数据集也给出了一个新任务,叫做 Reader-Aware Multi-Document Summarization(RA-MDS)[7]。文章指出,在做新闻摘要的时候,读者在新闻评论中的一些关注点,对摘要系统也有很大帮助。比如说,有些原始新闻报道都持有对 AI 技术非常乐观的态度,而有些读者则可能在新闻下方的评论里表达对于 AI 技术可能带来的社会问题的忧虑等等。这些信息也会为摘要系统增加新的视角。于是便有了这样第一份 RA-MDS 的数据集。
这个数据集里的一些信息主要是延续了 TAC 的数据规范:topic、document、category、aspect、aspect facet 和 comment。其中 aspect facet 和 comment 是 RA-MDS 独有的。Aspect facet 是 aspect 的具体内容,comment 就不用说了。比如,以“Malaysia Airlines Disappearance”为例, 针对“WHAT”这个方面(aspect),其 aspect facet 就包含了“missing Malaysia Airlines Flight 370”, “two passengers used passports stolen in Thailand from an Austrian and an Italian.”等等。
同时,论文也给出了自己的一个模型来解决这样一个任务。可以看看最后生成出的一些摘要:

以上就是今天的分享内容啦。希望这些新数据集、新任务对大家有一点点启发~
编辑:文婧





