NLP领域近期有哪些值得读的开源论文?(附下载)

来源:PaperWeekly
本文约3300字,建议阅读8分钟。
本文为你分享10篇值得读的NLP论文,带源代码的那种~


@paperweekly 推荐
#Relation Extraction
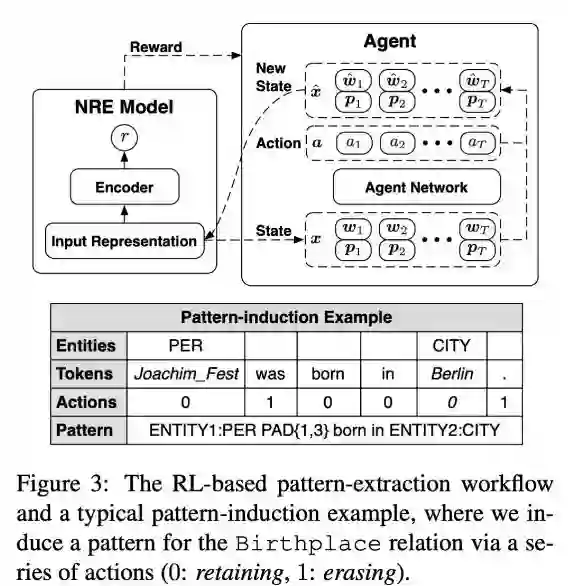
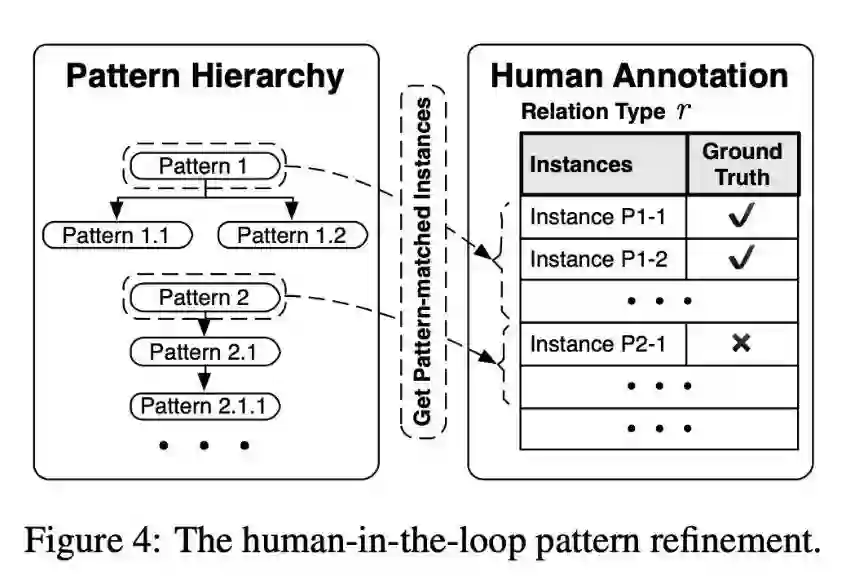
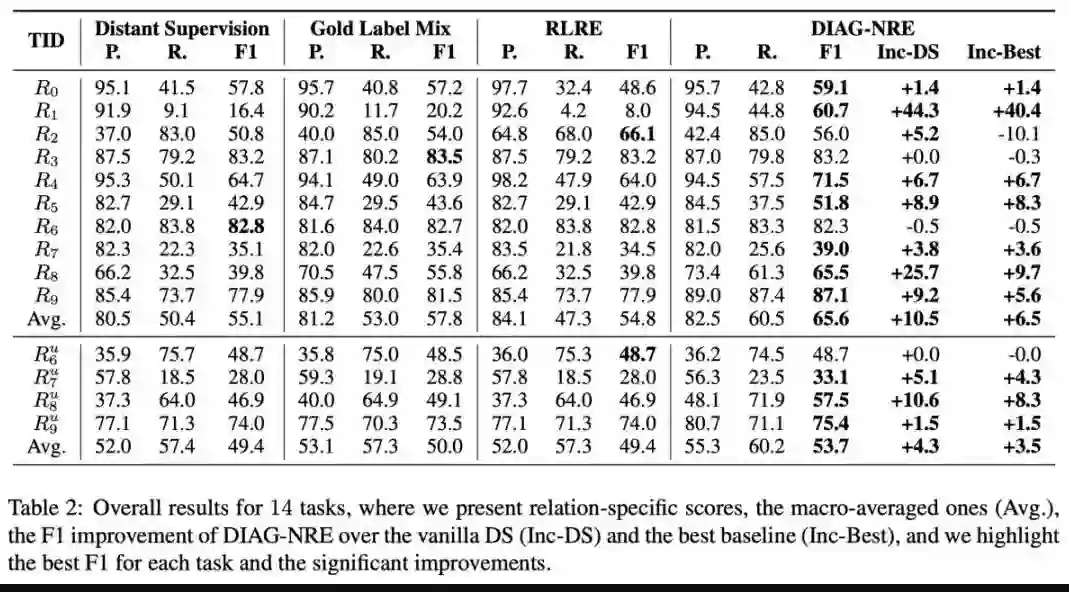
本文是清华大学徐葳老师组和刘知远老师组发表于 ACL 2019 的工作,论文在远程监督与弱监督融合两种技术之间搭建起了一座桥梁,既通过自动生成模式减轻了对领域专家在技能和工作量上的要求,又通过主动式的少量人工标注自动精炼高质量模式,从而赋能在新关系领域上的快速泛化。
此外,DIAG-NRE 不仅能有效抑制标签噪声,同时可以诊断不同关系类型上噪声类型、严重程度等方面,进而直观解释了噪声标签因何而起,又是如何得到抑制。
论文详细解读:ACL 2019 | 面向远程监督关系抽取的模式诊断技术


论文链接:
https://www.paperweekly.site/papers/3109
源码链接:
https://github.com/thunlp/DIAG-NRE


@tobiaslee 推荐
#Extractive Summarization
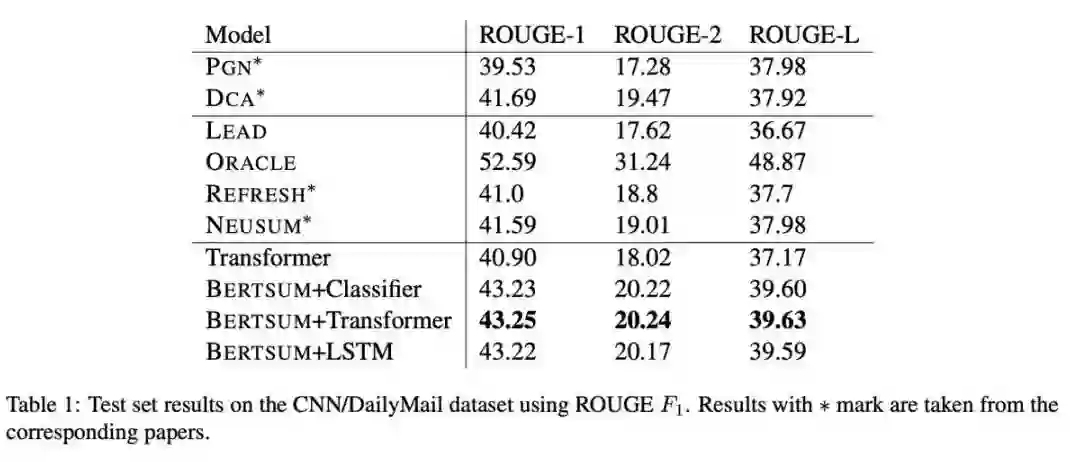
本文是 BERT 在摘要任务上的一次尝试,主要关注抽取式的摘要。对于每个文档中的句子,在句子之前设置一个 CLS,利用 BERT 的设置得到句子的表示,在此基础之上判断是否选取这个句子。进一步地,为了整合 Document-Level 的信息,再得到句子表示之后(即 CLS token),可以再做一次 self-attention 或者是过一层 RNN。此外,除了 BERT 原有的 Positional Encoding,文章为了区别句子(某些词属于某个句子),额外增加了一个 Segment Encoding,对句子进行交错编码。

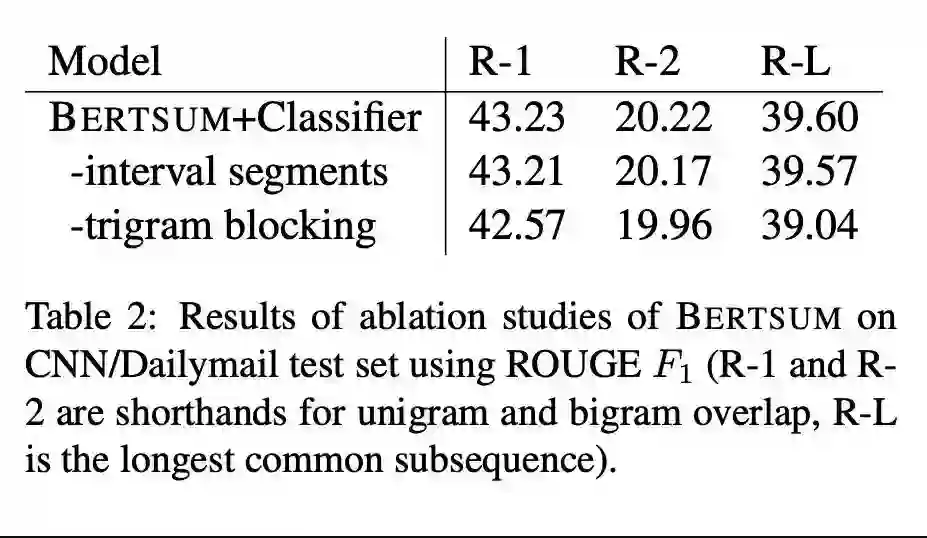
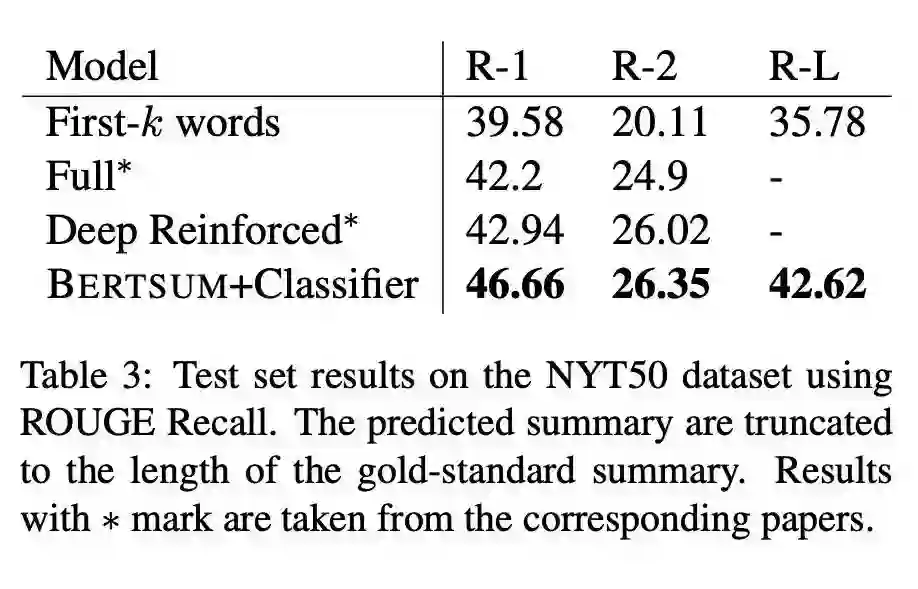

论文链接:
https://www.paperweekly.site/papers/3110
源码链接:
https://github.com/nlpyang/BertSum


@zhoujie 推荐
#Sentiment Classification
本文是一篇综述,对目前基于深度学习的 Aspect-level Sentiment Classification 进行了概括总结,对当前各种方法进行了分类。该论文整理了关于 Aspect-level Sentiment Classification 的目前比较常用的数据集,并提供了统一下载的地方。该论文对比了目前比较经典的 state-of-the-art 的模型,并在 5 个数据集上进行实验看模型效果。

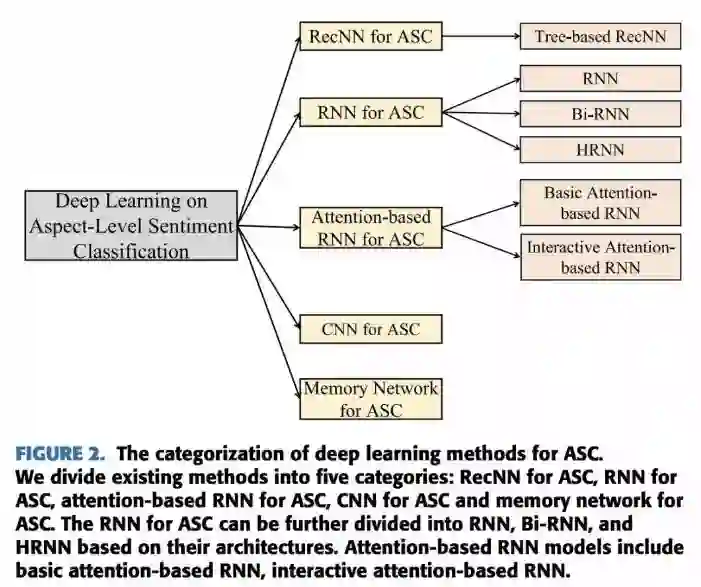
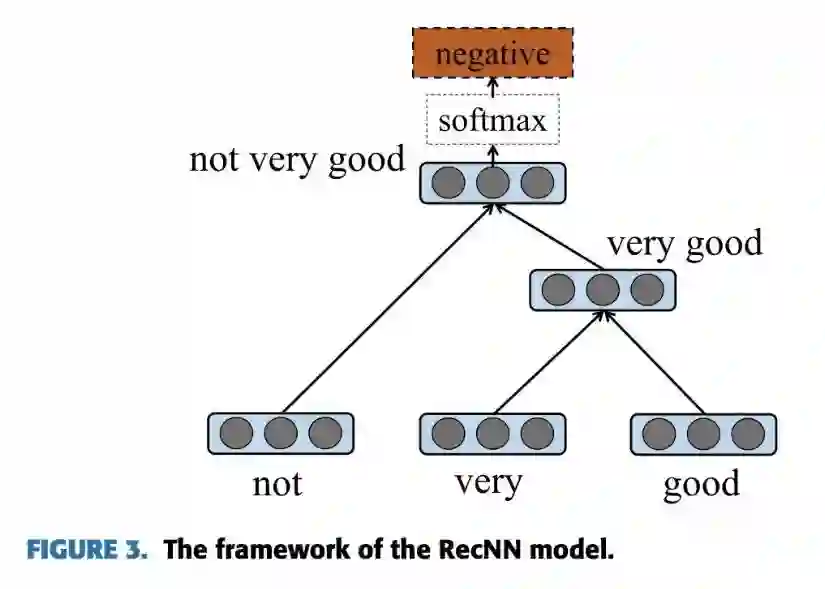

论文链接:
https://www.paperweekly.site/papers/3081
源码链接:
https://github.com/12190143/Deep-Learning-for-Aspect-Level-Sentiment-Classification-Baselines


@IndexFziQ 推荐
#Commonsense Reasoning
本文是 Allen 实验室发表在 ACL2019 的一篇关于自动常识知识库构建的文章。作者提出了Commonsense Transformers (COMET) 生成模型,主体框架是 Transformer 语言模型,在 ATOMIC 和 ConceptNet 知识种子训练集上训练,自动构建常识知识库。COMET与许多使用规范模板存储知识的传统知识库相反,常识知识库仅存储松散结构的开放式知识描述。
实证结果表明,COMET 能够产生新的人类评价为高质量的知识,高达 77.5%(ATOMIC)和 91.7%(ConceptNet)精度。使用常识生成模型 COMET 进行自动构建常识知识库也许就会成为知识抽取的合理替代方案。

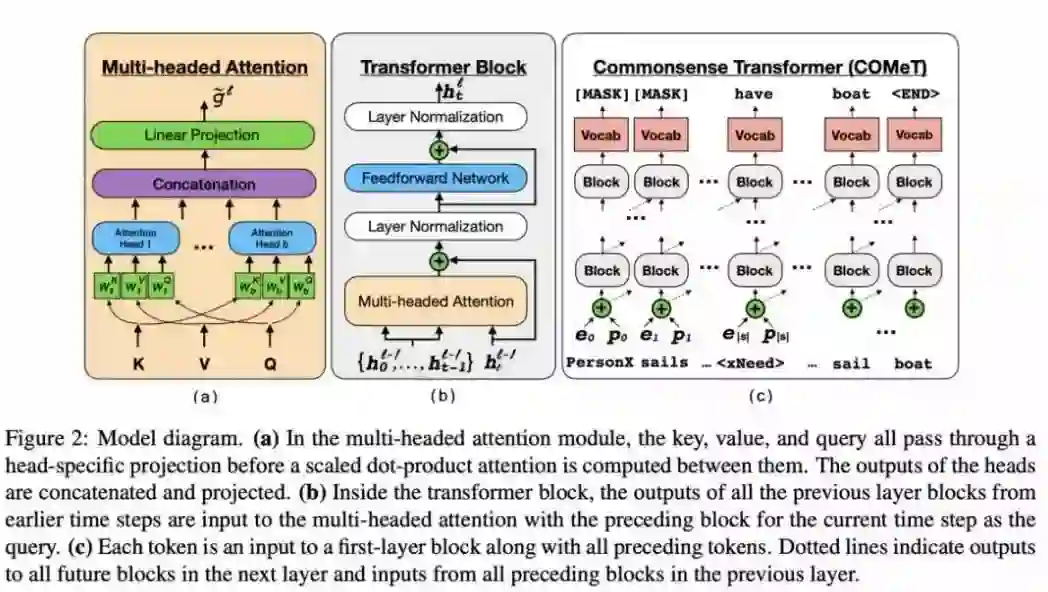

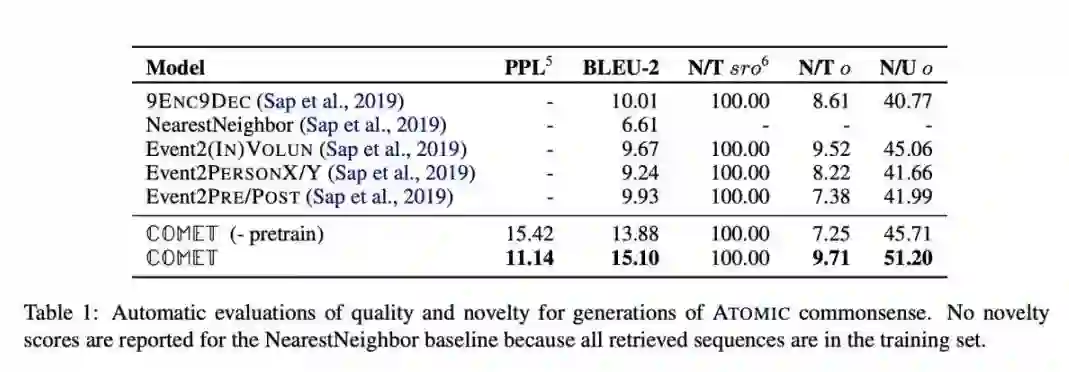

论文链接:
https://www.paperweekly.site/papers/3100
源码链接:
https://github.com/atcbosselut/comet-commonsense


@vertigo 推荐
#Sentence Representation
本文是杜克大学发表于 ACL 2019 的工作。文章动机在于学习更加 compact 的 general-purpose sentence representations,以便于将其运用到移动设备上(内存较小,运算能力有限)。作者提出了学习 binary 的 sentence embeddings,即句子向量的每一维是 0 或者 1,这样降低了储存 sentence embeddings 的内存,也加快了比较句子相似度的计算量(只需要计算 hamming distance)。
作者试验了一系列从 continous(real-valued)的句子向量 infer 出 binary 句子向量的办法。其中,autoencoder 加上一种 semantic-preserving loss 得到了很好的结果——在 10 个 downstream tasks 上,binary representations 达到了和 continous representations 很接近的结果。

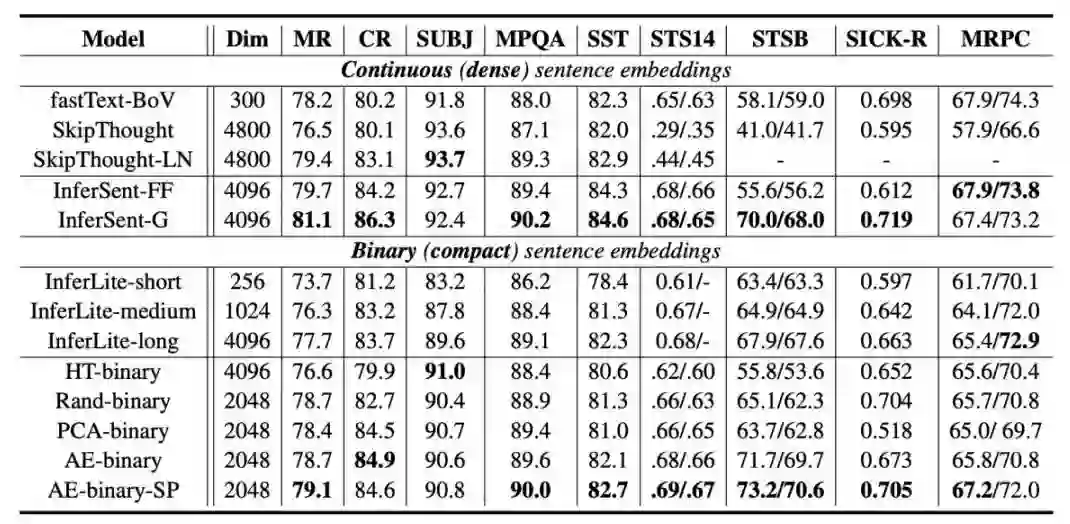
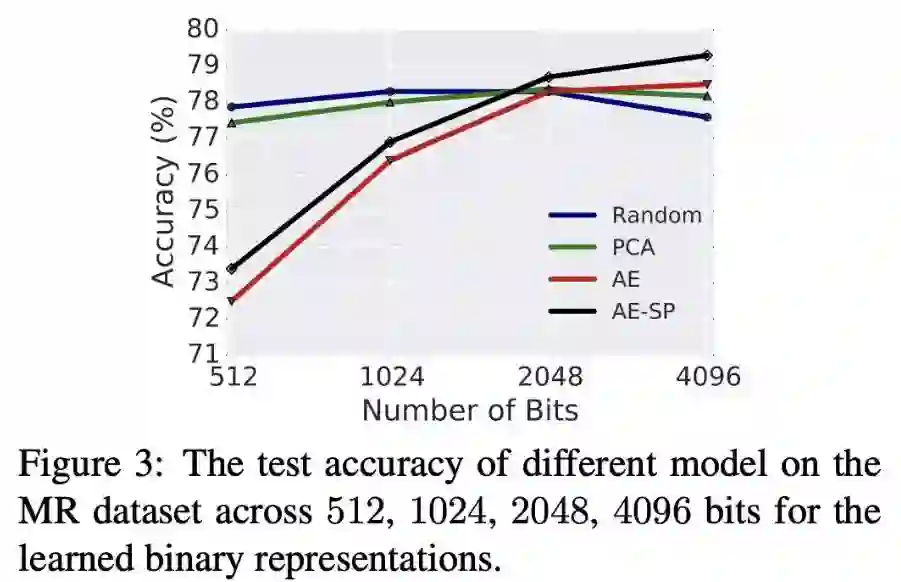
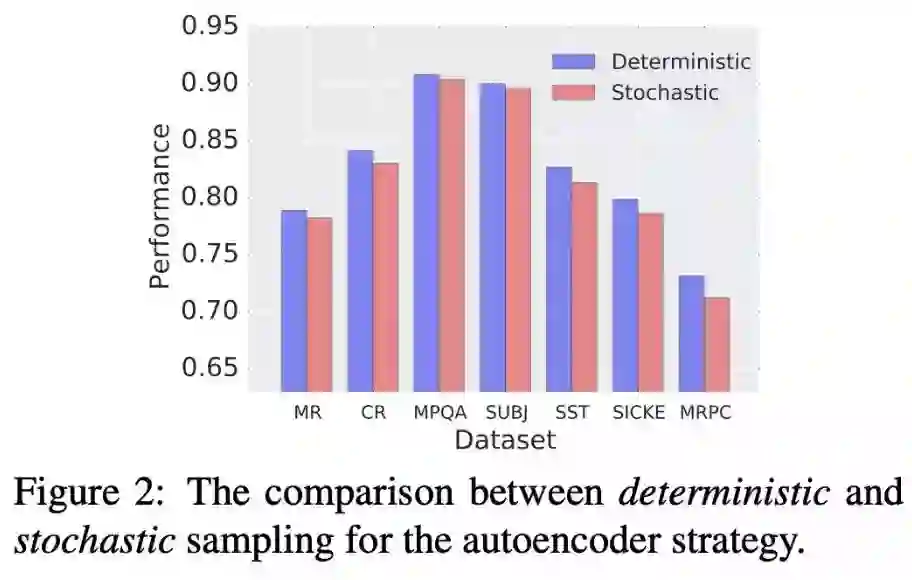
▲ 论文模型:点击查看大图

论文链接:
https://www.paperweekly.site/papers/3115
源码链接:
https://github.com/Linear95/BinarySentEmb

@tobiaslee 推荐
#Text Style Transfer
本文是腾讯微信 AI 和北大计算语言所发表在 ACL 2019 上的论文,关注的是无监督的文本风格转换任务。已有工作往往基于分步走的策略:先从文本中分离出内容,再通过一个风格融合模块来进行目标风格文本的生成,而这种策略无法捕获内容和风格之间的隐式关联,容易造成内容缺失等问题。
为了解决这个问题,作者基于 Dual RL 框架,分别学习了两个 seq2seq 模型,一个负责将源输入转换为目标风格输出,另一个恰好相反,这样就能直接完成输入到输出的转换而不需要分步走。reward 是调和平均风格奖赏(分类器判定为目标风格的概率)和内容奖赏(通过生成的文本重构原文本的概率),训练的时候交替更新两个 seq2seq 直到收敛。
另外,为了解决强化学习在生成过程中容易遇到的两个问题:需要预训练和在 RL 过程中语言模型容易崩坏,作者通过基于模板的方法来构建伪并行语料集来完成预训练,并且提出了 Annealing Pseudo Teacher-Forcing 来缓解后一问题。
实验部分,文章提出的模型在 YELP (情感极性转换)和 GYAFC (formality transfer)都取得了最佳的性能,并且发现 RL 方法对于风格迁移的准确度有所提升,但是在流畅程度上相比 MLE 有所欠缺。

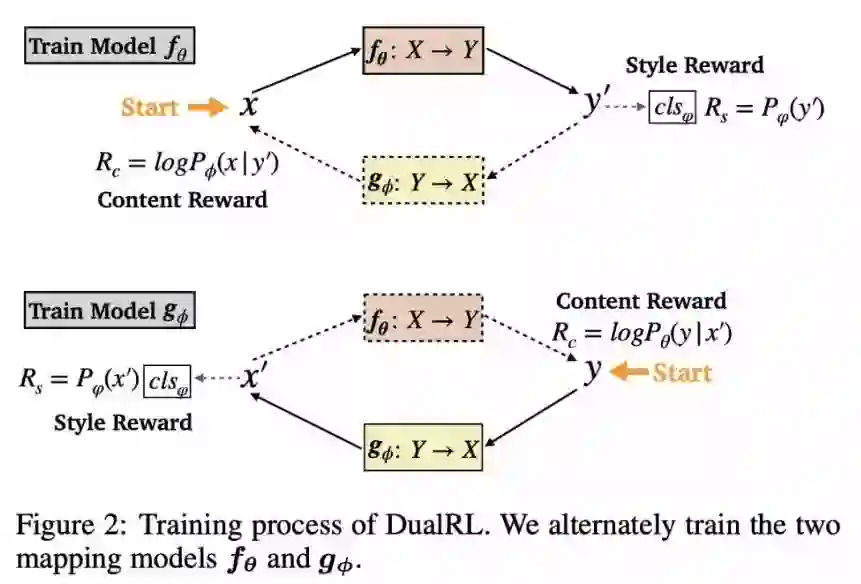


▲ 论文模型:点击查看大图

论文链接:
https://www.paperweekly.site/papers/3060
源码链接:
https://github.com/luofuli/DualLanST

@paperweekly 推荐
#Sentence Representation
本文是清华大学和华为诺亚方舟实验室发表于 ACL 2019 的工作,论文提出将知识图谱的信息加入到模型的训练中,这样模型就可以从大规模的文本语料和先验知识丰富的知识图谱中学习到字、词、句以及知识表示等内容,从而有助于其解决更加复杂、更加抽象的自然语言处理问题。实验表明,本文模型在多项 NLP 任务上的表现超越 BERT。
论文详细解读:ACL 2019 | 基于知识增强的语言表示模型,多项NLP任务表现超越BERT

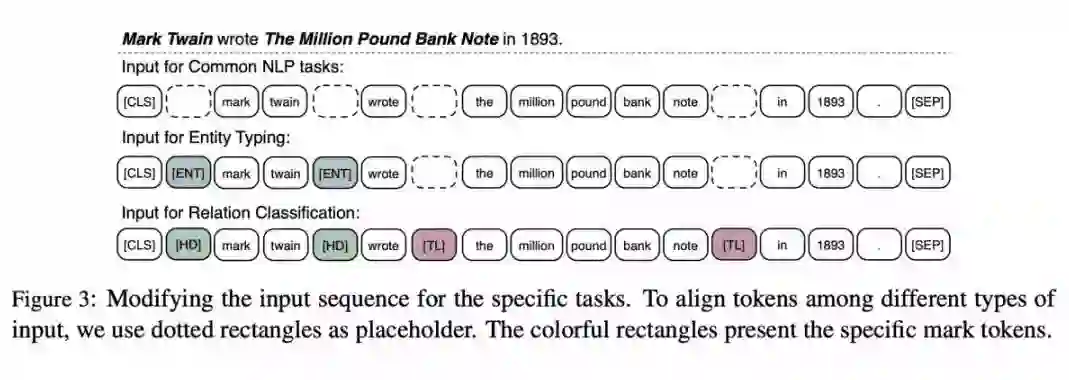
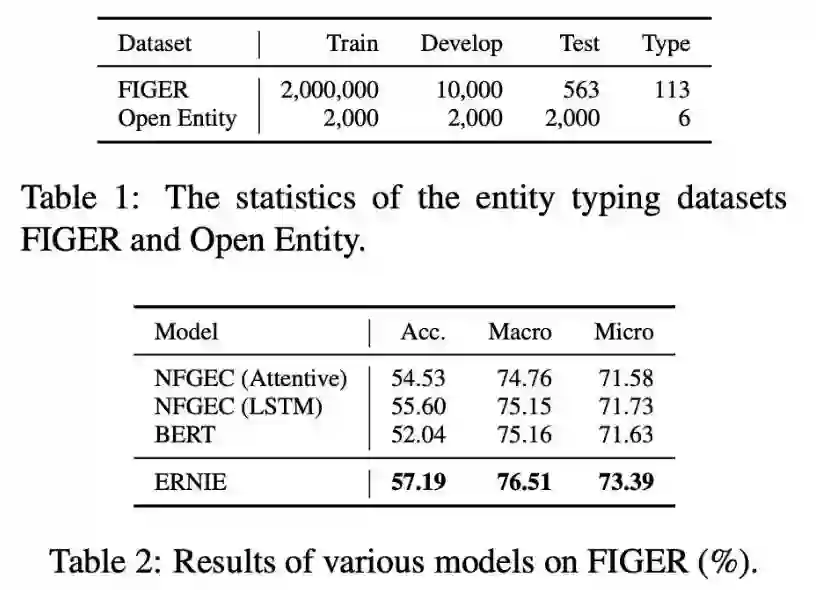
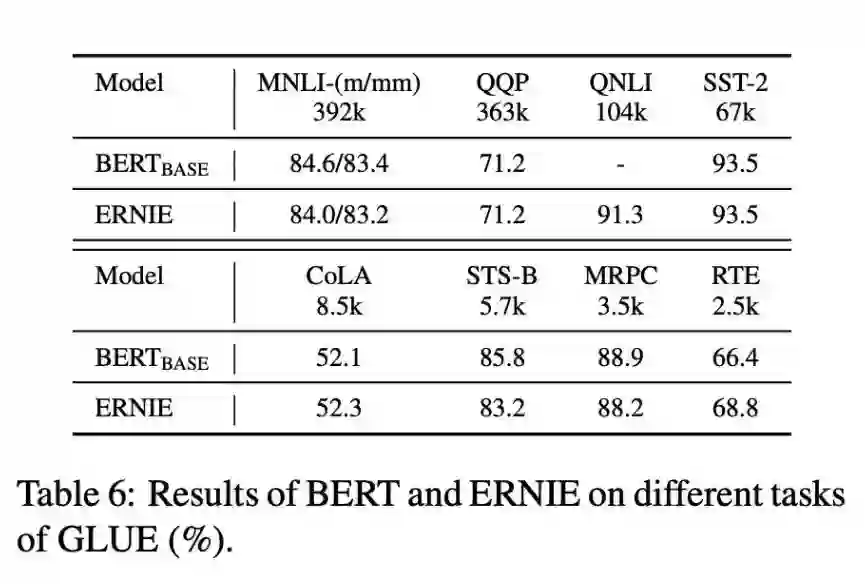
▲ 论文模型:点击查看大图

论文链接:
https://www.paperweekly.site/papers/3057
源码链接:
https://github.com/thunlp/ERNIE

@O3oBigFace 推荐
#Multimodal Sentiment Analysis
本文是清华大学和 CMU 发表于 AAAI 2019 的工作。论文研究的内容是非文本的多模态数据对文本的情感极性的影响。在日常生活中,除了说话内容,说话时的语调、面部表情、手势等等音频-视觉信息也是影响情感表达的重要部分。单纯利用文本词嵌入进行情感识别,会忽略掉重要的多模态信息。
本文提出了一个多模态情感分析模型,能够根据音频-视觉的多模态信息来动态地调整词嵌入的情感极性。首先,模型根据文本中的每一个单词切分出对应的音频和视频片段,并利用 LSTM 分别对音频-视觉信息进行特征提取。然后,上一步抽取出的特征流入门控模态混合网络,该网络利用原始单词的词向量,以跨模态注意力的方式,来计算非文本特征的调整值。最后,加权合并原始词向量和对应的调整值,得到最终的多模态调整的词向量。
该模型使用了多模态融合机制(门控注意力)来融合不同模态之间的相关特征(视频-文本、音频-文本),最后用加权和的方式对文本特征进行调整;使用了多模态表示实现了文本与非文本特征的联合表示。结果比得上现有的情感分析模型,可能存在的问题:时间成本有点高、多模态注意力的实现方式有待商榷。

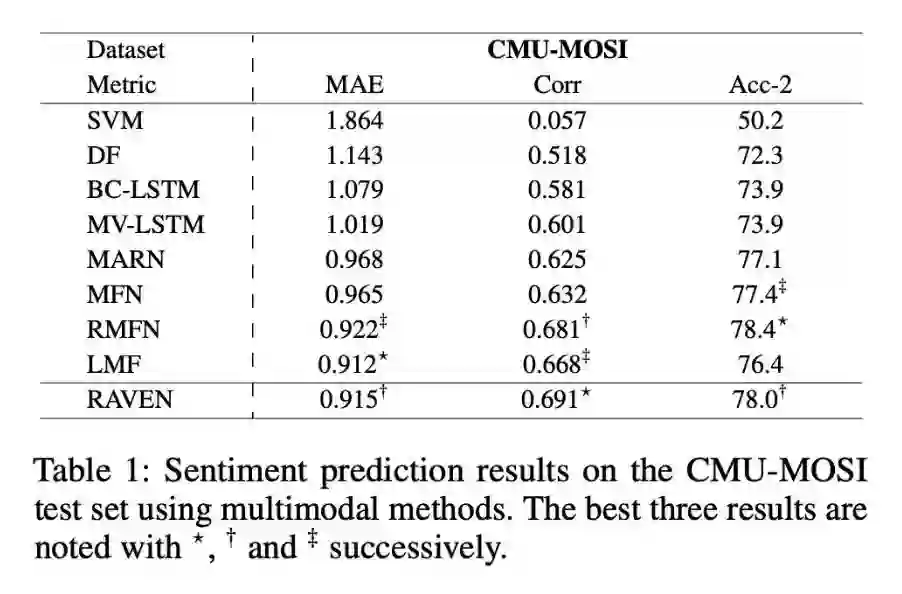
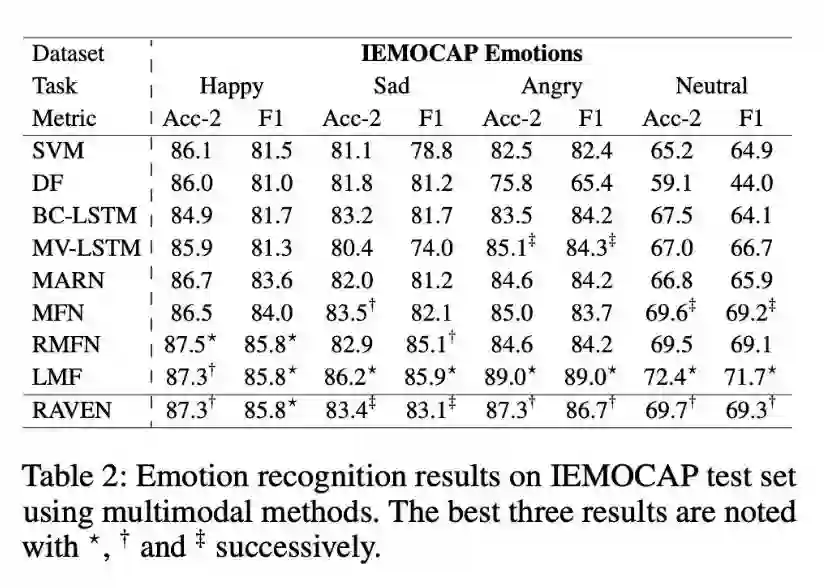
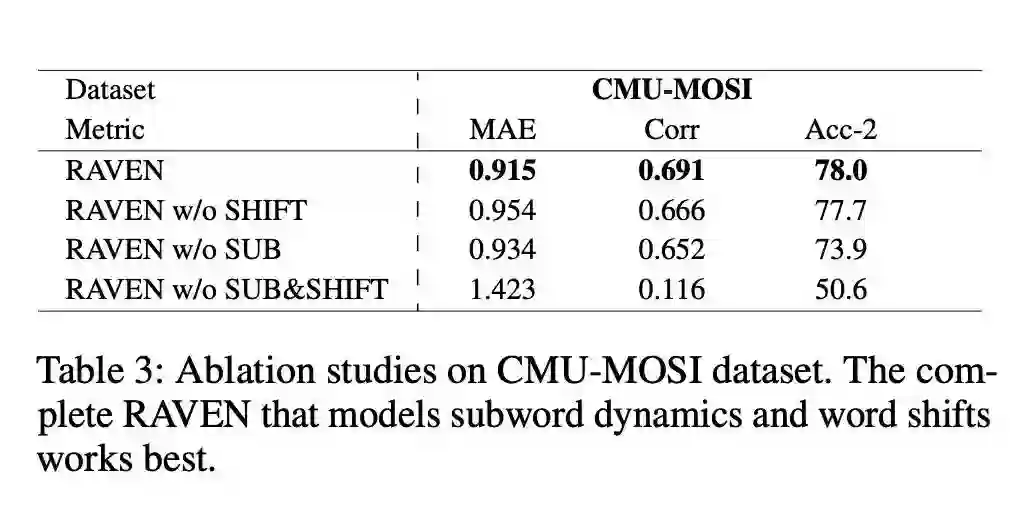
▲ 论文模型:点击查看大图

论文链接:
https://www.paperweekly.site/papers/2980
源码链接:
https://github.com/victorywys/RAVEN

@paperweekly 推荐
#Natural Language Sentence Matching
本文是腾讯、哈工大和 IBM 发表于 ACL 2019 的工作。在本文中,作者调研了六个 NLSM 数据集,发现这些数据集中广泛地存在一种样本选择偏差,以致于只使用三种和语义完全无关的特征,就可以在一些数据集上达到和 LSTM 差不多的准确率,针对这种偏差,作者提出了一种不需要任何额外资源的去偏训练、评估方法,实验证明本文方法能提升模型的真实泛化能力并提供更可靠的评估结果。
论文详细解读:ACL 2019开源论文 | 句对匹配任务中的样本选择偏差与去偏方法


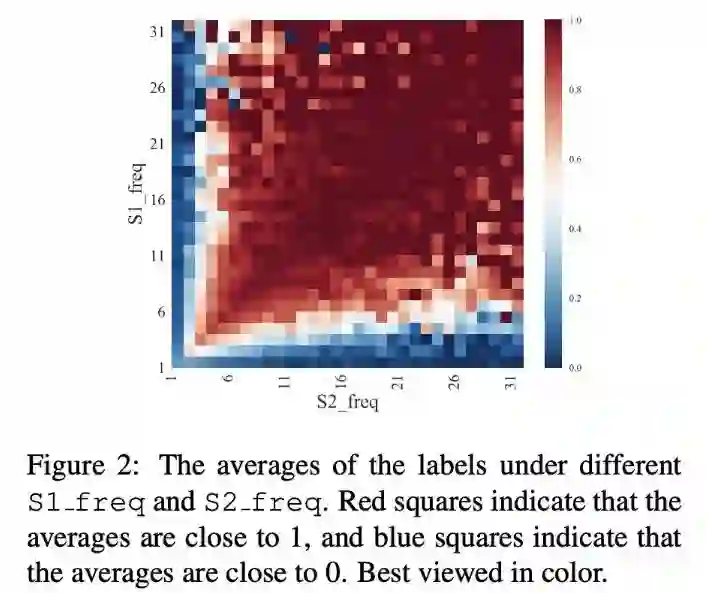
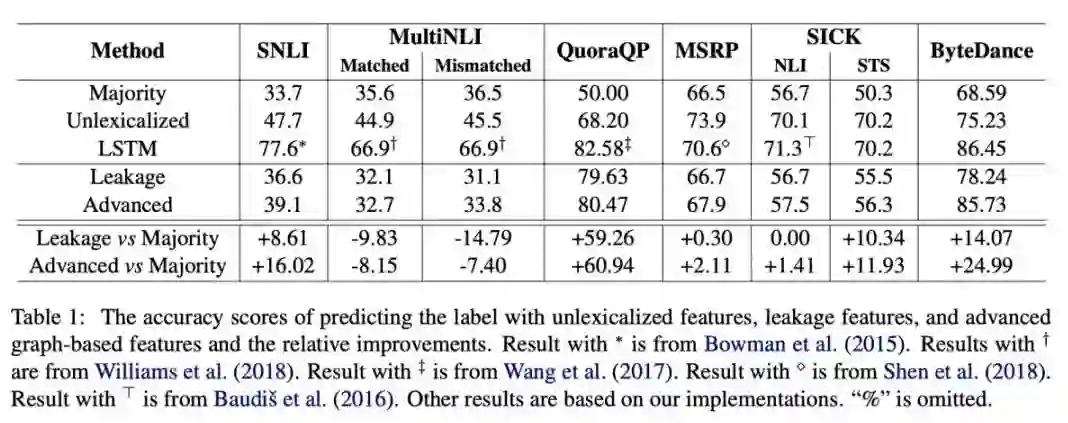
▲ 论文模型:点击查看大图

论文链接:
https://www.paperweekly.site/papers/3113
源码链接:
https://github.com/arthua196/Leakage-Neutral-Learning-for-QuoraQP

@tobiaslee 推荐
#Story Ending Generation
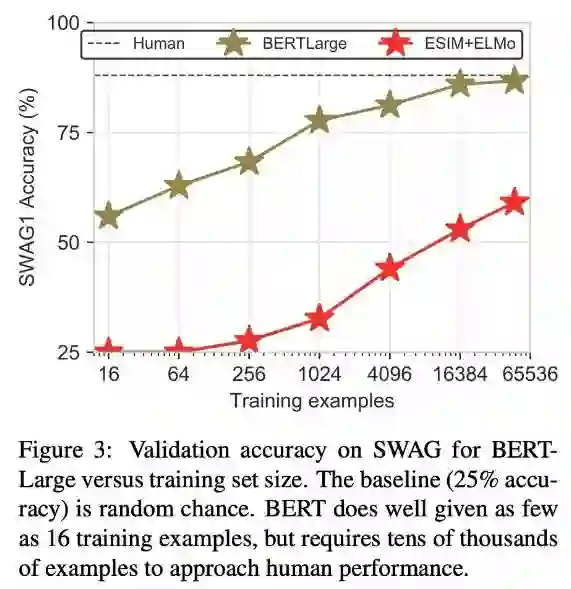
本文是 UW 的 Yejin Choi 组的工作,核心的一个想法是数据集应该和模型一起进化。SWAG 是 18 年提出的一个推理数据集(给定上文,判断一个句子是否是对应的结尾),人类能够达到 88% 的准确率,BERT之前的 state-of-the-art 是 60% 不到,而 BERT 则能达到 86% 的准确率。
那么为什么 BERT 效果这么好?实验证明,BERT 并不具备很强的常识推理能力,而是通过 fine-tune 阶段习得的数据分布的归纳偏好(dataset-specific distribution biases),实现了接近人类的性能。
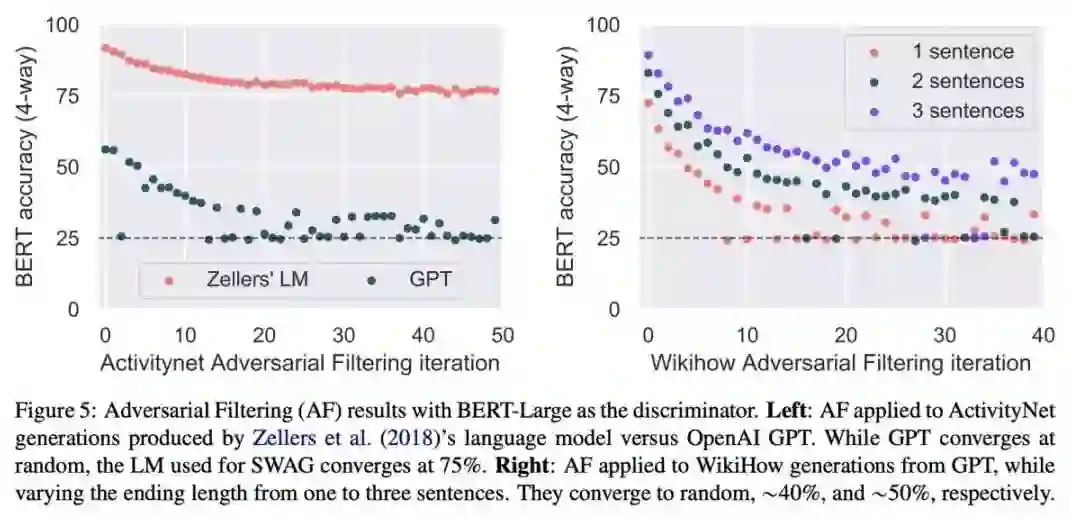
下一个问题就是,如何难倒 BERT 呢?解铃还须系铃人,文章使用 adversarial filtering 技术,随机将数据集分成训练集和测试集,然后在训练集上训练分类器,利用 Pre-train Language Model 来生成假的 candidate,并且不断替换能够被分类器轻松识别的候选句子,直到在这些具有对抗性的候选答案上的准确率收敛为止,从而构建出一个即使是 BERT 也无法轻松正确判断的数据集。
文章一个有意思的是对 BERT 在 SWAG 取得较好性能的探究,首先是对 fine-tune 数据集的 size 做了探究,发现只要十几个样本 BERT 就能达到 76% 的准确率,当然这并不能得出是来对 data set 的 fit 所致。
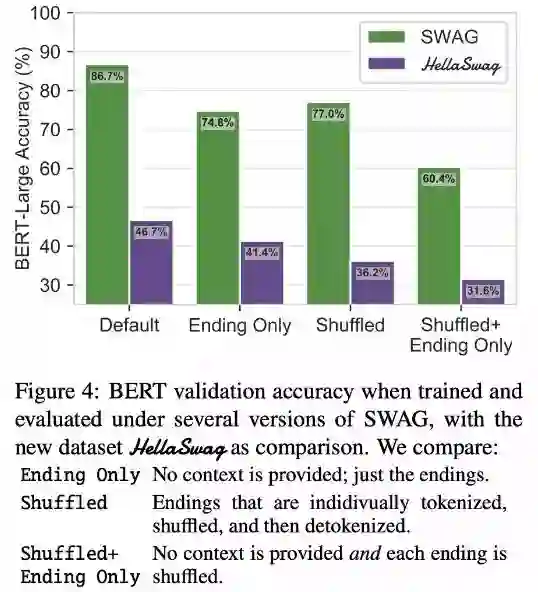
为此,文章还做了一个实验,发现即使是不给上文,也能达到 75% 的准确率,说明 fit 故事结尾就能够学习到很多的 bias,此外,即使是打乱结尾的句子词序,带来的性能降低也不足 10%,因此得出了 BERT 在 SWAG 上的出色表现来自于对于 surface 的学习,学习到合理结尾的某些 realization pattern 的结论。

▲ 论文模型:点击查看大图

论文链接:
https://www.paperweekly.site/papers/3112
源码链接:
https://github.com/rowanz/hellaswag
编辑:于腾凯




