深入机器学习系列之:快速迭代聚类



来源:星环科技
数据猿官网 | www.datayuan.cn

今日头条丨一点资讯丨腾讯丨搜狐丨网易丨凤凰丨阿里UC大鱼丨新浪微博丨新浪看点丨百度百家丨博客中国丨趣头条丨腾讯云·云+社区

谱聚类算法的原理
在分析快速迭代聚类之前,我们先来了解一下谱聚类算法。谱聚类算法是建立在谱图理论的基础上的算法,与传统的聚类算法相比,它能在任意形状的样本空间上聚类且能够收敛到全局最优解。 谱聚类算法的主要思想是将聚类问题转换为无向图的划分问题。

谱聚类算法的一般过程如下:
1、输入待聚类的数据点集以及聚类数k;
2、根据相似性度量构造数据点集的拉普拉斯矩阵L;
3、选取L的前k个(默认从小到大,这里的k和聚类数可以不一样)特征值和特征向量,构造特征向量空间(这实际上是一个降维的过程);
4、使用传统方法对特征向量聚类,并对应于原始数据的聚类。
谱聚类算法和传统的聚类方法(例如K-means)比起来有不少优点:
·和K-medoids类似,谱聚类只需要数据之间的相似度矩阵就可以了,而不必像K-means那样要求数据必须是N维欧氏空间中的向量。
·由于抓住了主要矛盾,忽略了次要的东西,因此比传统的聚类算法更加健壮一些,对于不规则的误差数据不是那么敏感,而且性能也要好一些。
·计算复杂度比K-means要小,特别是在像文本数据或者平凡的图像数据这样维度非常高的数据上运行的时候。
快速迭代算法和谱聚类算法都是将数据点嵌入到由相似矩阵推导出来的低维子空间中,然后直接或者通过k-means算法产生聚类结果,但是快速迭代算法有不同的地方。下面重点了解快速迭代算法的原理。
2
快速迭代算法的原理

在大多数情况下,我们只关心第k(k不为1)大的特征向量,而不关注最大的特征向量。 这是因为最大的特征向量是一个常向量:因为W每一行的和都为1。
快速迭代的收敛性在文献【1】中有详细的证明,这里不再推导。
快速迭代算法的一般步骤如下:

3
快速迭代算法的源码实现
在spark中,文件org.apache.spark.mllib.clustering.PowerIterationClustering实现了快速迭代算法。我们从官方给出的例子出发来分析快速迭代算法的实现。
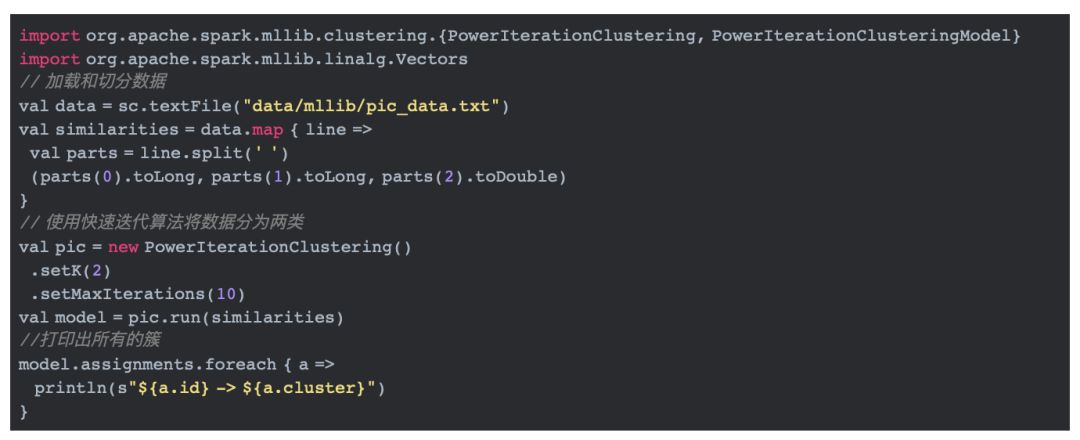
在上面的例子中,我们知道数据分为三列,分别是起始id,目标id,以及两者的相似度,这里的similarities代表前面章节提到的矩阵A。有了数据之后,我们通过PowerIterationClustering的run方法来训练模型。PowerIterationClustering类有三个参数:
·k:聚类数
·maxIterations:最大迭代数
·initMode:初始化模式。初始化模式分为Random和Degree两种,针对不同的模式对数据做不同的初始化操作
下面分步骤介绍run方法的实现。
(1)标准化相似度矩阵A到矩阵W
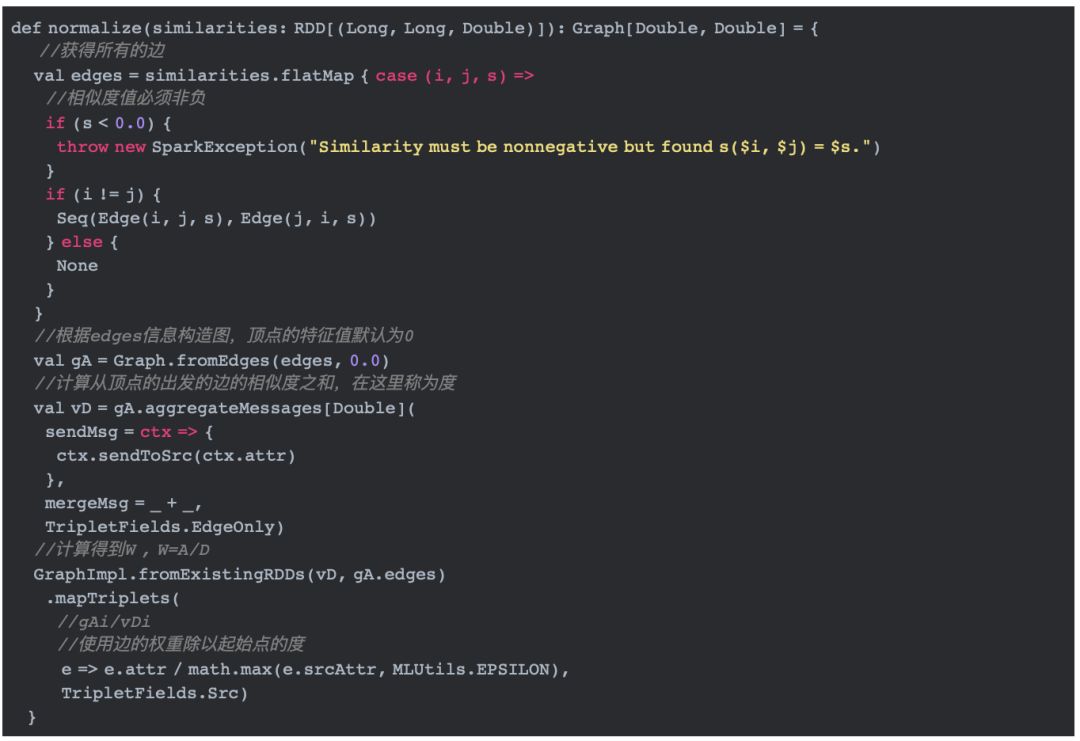
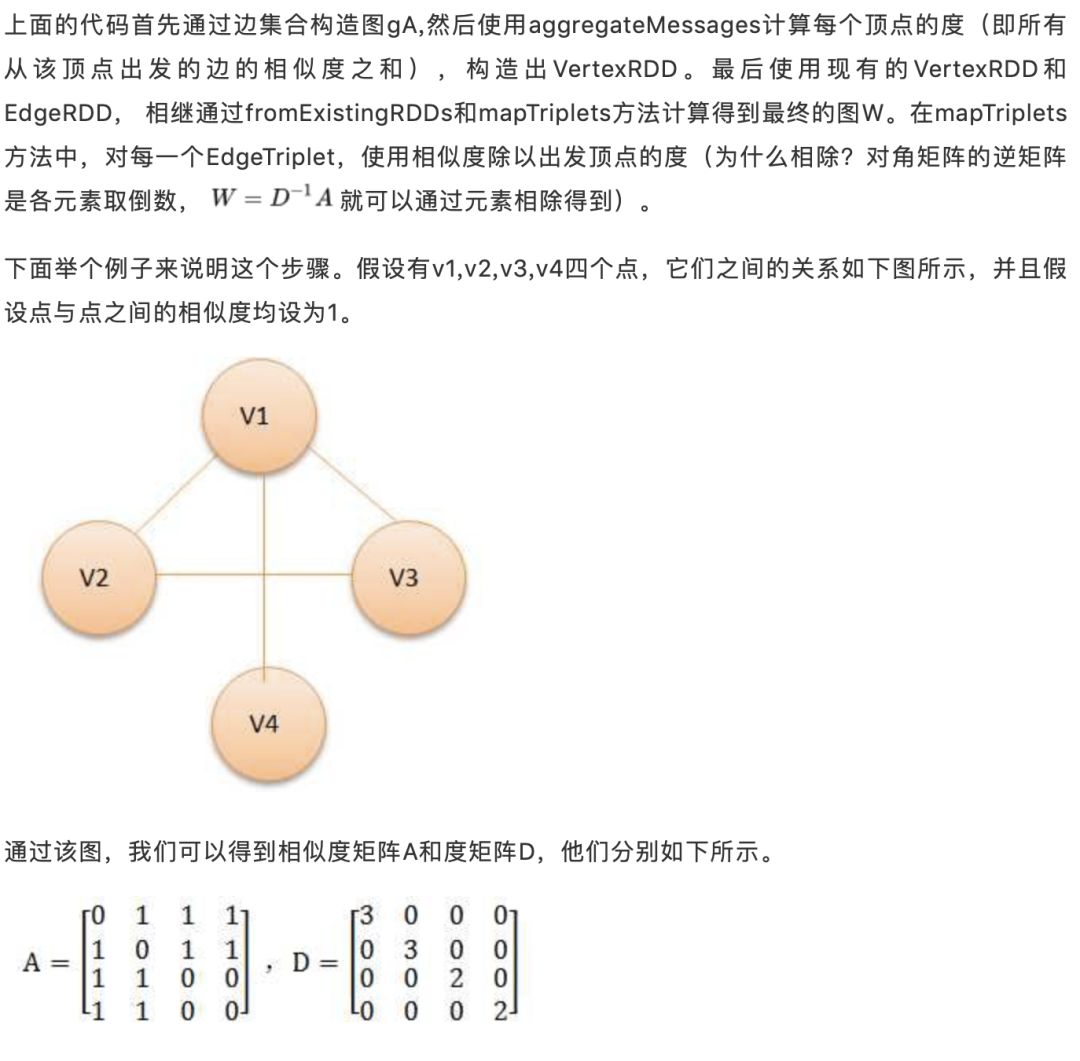
通过mapTriplets的计算,我们可以得到从点v1到v2,v3,v4的边的权重分别为1/3,1/3,1/3;从点v2到v1,v3,v4的权重分别为1/3,1/3,1/3;从点v3到v1,v2的权重分别为1/2,1/2;从点v4到v1,v2的权重分别为1/2,1/2。 将这个图转换为矩阵的形式,可以得到如下矩阵W。

·随机初始化

·度初始化

在这里,度初始化的向量我们称为“度向量”。度向量会给图中度大的节点分配更多的初始化权重,使其值可以更平均和快速的分布,从而更快的局部收敛。详细情况请参考文献【1】。
(3)快速迭代求最终的v

(4)使用k-means算法对v进行聚类