【综述翻译】Deep Learning for Video Game Playing
深度强化学习实验室

在本文中,我们将回顾最近的Deep Learning在不同类型的视频游戏中的应用情况 如第一人称射击游戏,街机游戏和即时战略游戏等方面取得的进展。我们分析了不同游戏类型对深度学习系统的独特要求, 并突出介绍了如何将机器学算法应用在即时视频游戏下所面临的挑战,例如1.处理超大的决策空间和稀疏奖励问题。
1.引言
将AI技术应用于视频游戏已经成为多个期刊和会议的专项研究领域。在本文中,我们回顾了视频游戏深度学习和应用游戏研究平台的最新进展,同时强调了重要的开放性挑战。撰写本文的动机是从不同类型的游戏角度审视该领域,以及他们为深度学习带来的挑战,和如何使用深度学习来玩这些游戏。关于深度学习的各种评论文章[39],[81],[126],以及强化学习[142]和深度强化学习[87]的调查,这里我们关注这些应用于视频游戏的技术。特别是,在本文中,我们专注于广泛用于基于DL的游戏AI的游戏问题和环境,例如Atari/ALE,Doom,Minecraft,星际争霸和赛车。此外,我们审查现有工作并指出仍有待解决的重要挑战。我们感兴趣的是那些旨在很好地发挥特定视频游戏的方法(与诸如Go之类的棋盘游戏相反),来自像素或特征向量,而没有现有的推理模型。分析了几种游戏类型,指出它们给人类和机器玩家带来的诸多挑战。值得注意的是,本文未涉及的AI和游戏中有很多用途;游戏AI是一个庞大而多样化的领域[171],[170],[93],[38],[99]。本文主要关注用于玩视频游戏的深度学习方法,同时有大量关于以可信,娱乐或类似人的方式玩游戏的研究[59]。AI还用于模拟玩家的行为,经验或偏好[169],或生成游戏内容,如关卡,纹理或规则[130深度学习远不是游戏中唯一使用的AI方法。其他突出的方法包括蒙特卡罗树搜索[18]和进化计算[115],[90]。在下文中,重要的是要意识到本文范围的局限性。本文的结构如下:第一节概述了应用于游戏的不同深度学习方法,第二,第三节是目前正在使用的不同研究平台。第四节回顾了不同视频游戏类型中DL方法的使用,第五节给出了领域的历史回顾。第六节中讲述重要开放性挑战,第七节中的结论。
2.深入学习游戏概述
本节简要概述了游戏环境中的神经网络和机器学习。首先,我们描述常见的神经网络架构,然后概述了机器学习任务的三个主要类别:监督学习,无监督学习和强化学习。这些类别中的方法通常基于梯度下降优化。我们还强调了遗传算法以及结合了多种优化技术的混合方法的一些示例。A.神经网络模型 人工神经网络(ANN)是通用功能,由其网络结构和每个图形边缘的权重定义。由于它们具有通用性和近似任何连续实值函数的能力(给定足够的参数),它们已经应用于各种任务,包括视频游戏。这些人工神经网络的架构大致可分为两大类:前馈和递归神经网络(RNN)。前馈网络采用单个输入,例如,游戏状态的表示,并输出每个可能动作的概率或值。卷积神经网络(CNN)由可训练的滤波器组成,适用于处理图像数据,例如来自视频游戏屏幕的像素。RNN通常应用于时间序列数据,其中网络的输出取决于先前时间步长[165],[82]中网络的激活。训练过程与前馈网络相似,除了网络的先前隐藏状态与下一个输入一起反馈到网络中。这样可以通过记住先前的激活来使网络变得上下文相关,当从游戏中获得的单个观察结果不能代表完整的游戏状态时,这将非常有用。对于视频游戏,通常使用一堆卷积层,然后是递归层和完全连接的前馈层。
以下各节将简要概述不同的优化方法,这些方法通常用于通过深度神经网络学习游戏行为。这些方法搜索最佳参数集以解决某些问题。优化还可以用于查找超参数,例如网络体系结构和学习参数,并且在深度学习中得到了很好的研究[13],[12]。
1)监督学习
在监督学习中,模型是从示例中训练出来的。在训练期间,要求模型做出正确答案已知的决定。该错误,即所提供的答案与地面实况之间的差异,被用作更新模型的损失。目标是实现一个可以超越训练数据的模型,从而在以前从未见过的例子上表现良好。大数据集通常可以提高模型的推广能力。在游戏中,这些数据可以来自游戏痕迹[16](即人类在被记录时通过游戏进行游戏),允许agent根据人类在给定状态下执行的操作来学习从输入状态到输出动作的映射。如果游戏已经被另一种算法解决,它可以用于生成训练数据,如果第一种算法太慢而无法实时运行,这将非常有用。虽然学习使用现有数据可以让agent快速学习最佳实践,但它往往很脆弱;可用的数据生产成本可能很高,并且可能缺少agent应该能够处理的关键方案。对于游戏玩法,算法仅限于数据中可用的策略,不能自行探索新算法。因此,在游戏中,监督算法通常通过强化学习算法与额外训练相结合[133]。监督学习在游戏中的另一个应用是学习游戏的状态转换。神经网络可以学习预测动作状态对的下一状态,而不是为给定状态提供动作。因此,网络本质上是学习游戏模型,然后可以用来更好地玩游戏或执行计划[45]。
2)无监督学习
无监督学习的目标不是学习数据与其标签之间的映射,而是发现数据中的模式。这些算法可以学习数据集的特征分布,可用于聚类类似数据,将数据压缩为其基本特征,或创建原始数据特征的新合成数据。对于奖励稀疏的游戏(例如Montezuma的Revenge),以无人监督的方式从数据中学习是一种潜在的解决方案,也是一项重要的开放式深度学习挑战。深度学习中一种突出的无监督学习技术是自动编码器,它是一种神经网络,试图学习身份函数,使得输出与输入相同[80],[117]。网络由两部分组成:将输入x映射到低维隐藏向量h的编码器,以及尝试从h重构x的解码器。主要思想是,通过保持小,网络必须学会压缩数据,从而学习良好的代表性。研究人员开始将这种无监督算法应用于游戏,以帮助将高维数据提取到更有意义的低维数据,但这一研究方向仍处于早期阶段[45]。有关监督和无监督学习的更详细概述,请参见[126],[39]。
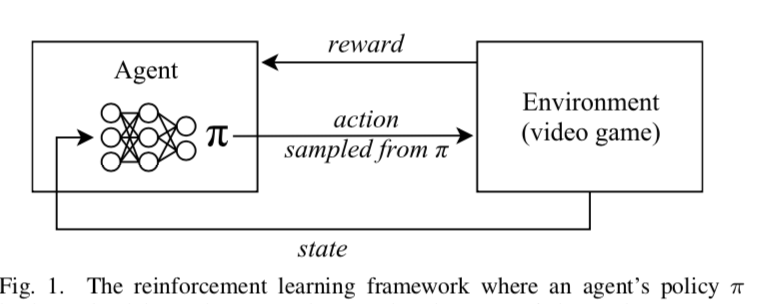
图1.强化学习框架,其中agent的策略π由深度神经网络确定。将环境状态或诸如屏幕像素的观察作为输入馈送到agent的策略网络。从策略网络的输出π中采样动作,其中在接收到奖励和随后的游戏状态之后。目标是最大化累积奖励。强化学习算法基于奖励更新策略(网络参数)。
3)强化学习方法
在强化学习(RL)中,agent通过与提供奖励信号给agent的环境交互来学习行为。在RL设置中,可以轻松地将视频游戏建模为环境,其中将玩家建模为agent,并在每个步骤中采取一组有限的动作,并根据游戏得分来确定奖励信号。在RL中,agent依赖于奖励信号。这些信号可能会频繁出现,例如游戏中得分的变化,也可能不经常发生,例如座席是赢还是输。电子游戏和RL配合得很好,因为大多数游戏都会为成功的策略提供奖励。开放世界游戏并不总是具有明确的奖励模型,因此对于RL算法具有挑战性。将RL应用到奖励稀疏的游戏时,面临的主要挑战是确定获得奖励信号时如何将信用分配给许多先前的行为。状态s的奖励R(s)需要传播回导致奖励的动作。从历史上看,有几种不同的方法可以解决此问题,下面将对此进行介绍。如果可以将环境描述为马尔可夫决策过程(MDP),则agent可以构建未来状态及其奖励的概率树。然后,可以使用概率树来计算当前状态的效用。对于RLagent,这意味着学习模型P(s'|s,a),其中P是状态s'给定状态s和动作a的概率。对于模型P,可以通过以下公式计算效用:
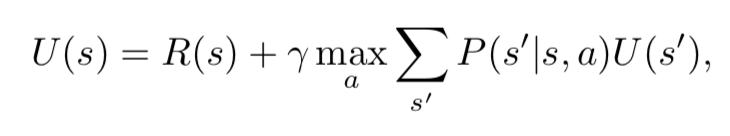
图1.强化学习框架,其中agent的政策π由深度神经网络确定。环境状态或观察结果(例如屏幕像素)将作为输入输入到agent的策略网络中。从策略网络的输出π中采样一个操作,然后在该操作中获得奖励和随后的游戏状态。目标是最大化累积的奖励。强化学习算法根据奖励更新策略(网络参数)。其中,γ是未来状态效用的折扣因子。这种称为自适应动态规划的算法,由于可以直接处理信用分配问题,因此可以相当快速地收敛[142]。问题在于,它必须在整个问题空间上建立概率树,因此对于大空间问题来说是棘手的。由于本文中涉及的游戏被认为是“大问题”,因此我们将不进一步详细介绍该算法。解决此问题的另一种方法是时间差异(TD)学习。在TD学习中,agent基于当前效用等于当前奖励加上下一状态的效用值的观察值直接学习效用U [142]。它不是学习状态转换模型P,而是学习为每个状态建模效用U。更新2,U的等式为:
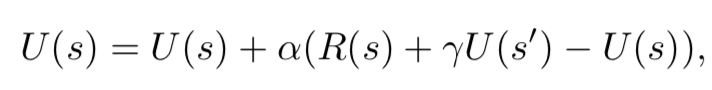
其中α是算法的学习率。上面的方程式没有考虑s'的选择方式。如果在st找到奖励,它将仅影响U(st)。agent下次在st-1时,U(st-1)将知道将来的奖励。随着时间的流逝,这将向后传播。同样,较少见的过渡对效用价值的影响也较小。因此,U将收敛到与从ADP获得的值相同的值,尽管速度较慢。TD的替代实现可以学习对状态-行为对的奖励。这允许agent在给定状态的情况下选择动作,而没有如何过渡到未来状态的模型。因此,这些方法被称为无模型方法。流行的无模型RL方法是Q学习[162],其中状态的效用等于状态的最大Q值。Q学习的更新公式为:
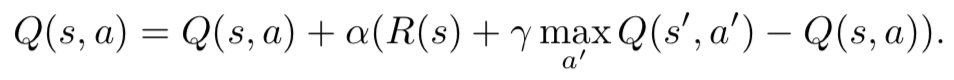
在Q学习中,通过选择最著名的未来状态-动作对来考虑未来奖励。在称为SARSA(状态行动-奖励状态行动)的类似算法中,仅当选择了下一个a且已知下一个s时才更新Q(s,a)[118]。使用该操作对代替最大Q值。与非策略性Q学习相反,这使SARSA成为一种基于策略的方法,因为SARSA的Q值说明了agent自己的策略。Q学习和SARSA可以使用神经网络作为Q函数的函数逼近器。给定的Q更新方程式可用于为状态-动作对提供新的“预期”Q值。然后可以在监督学习中更新网络。agent的政策π(s)确定在给定状态s时应采取的行动。对于Q学习,一个简单的策略是始终采取具有最高Q值的动作。但是,在训练的初期,Q值不是很准确,agent总是会因为获得少量奖励而陷入困境。学习者应该优先研究新动作以及对所学知识的利用。这个问题被称为多武装匪徒问题,并且已经得到了很好的研究。ε贪心策略是一种简单的方法,它以ε概率选择(估计的)最佳动作,否则选择随机动作。RL的一种方法是在策略的参数空间中执行梯度下降。设πθ(s,a)是在给定参数θ的情况下在状态s采取动作a的概率。来自REINFORCE算法家族的基本策略梯度算法[164]使用梯度∇θaπθ(s,a)R(s)更新θ,其中R(s)是从s向前获得的折现累积奖励。。实际上,从策略中抽取了可能采取的措施的样本,并对其进行了更新以增加将来返回更成功的措施的可能性。这很适合神经网络,因为π可以是神经网络,而θ可以是网络权重。
Actor-Critic方法将策略梯度方法与TD学习相结合,其中actor学习策略πθ(s,a)使用策略梯度算法,评论者使用TD学习[R]学习近似R。总之,它们是迭代学习策略的有效方法。在演员批评家方法中,可以有一个单独的网络来预测π和R,也可以有两个单独的网络。对于应用于深度神经网络的强化学习的概述,我们建议使用Arulkumaran等人的文章。[2]。
4)进化方法
迄今为止,基于定义的误差的区分,到目前为止讨论的优化技术依赖于梯度下降。但是,诸如进化算法之类的无导数优化方法也已广泛用于训练神经网络,包括但不限于强化学习任务。这种通常称为神经进化(NE)的方法可以优化网络的权重及其拓扑结构/体系结构。由于其通用性,NE方法已广泛应用于不同类型的视频游戏。有关此领域的完整概述,请参考感兴趣的读者阅读我们的NE调查论文[115]。与基于梯度下降的训练方法相比,NE方法具有不需要网络具有差异性的优势,并且可以应用于有监督,无监督和强化学习问题。演化拓扑的能力以及权重潜在地提供了一种自动化神经网络体系结构开发的方法,目前需要大量的领域知识。这些技术的前景是,进化可以找到一种神经网络拓扑,这种神经网络拓扑比现有的人类设计架构更擅长玩某种游戏。传统上,NE已被用于解决输入维数比典型深度学习方法低的问题,最近Salimans等人提出。[121]表明,依靠足够的计算资源,依赖于通过随机噪声进行参数探索而不是计算梯度的演化策略可以达到与当前深层RL方法在Atari视频游戏中具有竞争力的结果。
5)混合学习方法
最近,研究人员开始研究用于视频游戏的混合方法,该方法将深度学习方法与其他机器学习方法结合在一起。Alvernaz和Togelius[1]和Poulsen等人。[113]进行了实验,将通过梯度下降训练的深度网络与通过人工进化训练的网络合并,将浓缩的特征表示馈入网络。这些混合方法旨在将两种方法中的最佳方法结合起来,因为深度学习方法能够直接从高维输入中学习,而进化方法则不依赖于可区分的体系结构,并且在奖励稀疏的游戏中表现良好。一些结果表明,无梯度方法在训练的初期似乎更好,以避免过早收敛,而基于梯度的方法则在需要较少探索的情况下最终会更好[139]。另一种用于棋盘游戏的混合方法是AlphaGo [133],它依靠深度神经网络和树搜索方法来击败Go的世界冠军,[36]则将计划应用到预测模型之上。通常,本体遗传学RL(例如Q学习)与系统发育方法(例如进化算法)具有很大的影响力,因为它可以在不同的时间尺度上进行并发学习[153]。
3,游戏类型和研究平台
毫无疑问,由于在公开数据集上比较结果的惯例,深度学习方法的快速发展无疑。游戏AI中的一个类似惯例是使用游戏环境来比较游戏算法,其中,基于得分或获胜的能力对方法进行排名。IEEE计算智能与游戏大会之类的会议在各种游戏环境中都开展流行的比赛。本节介绍与深度学习相关的文献中流行的游戏类型和研究平台;图2中显示了一些示例。对于每种类型,我们简要概述该类型的特征,并描述玩该类型游戏的算法所面临的挑战。本文讨论的视频游戏已在很大程度上取代了较早的较简单控制问题,这些问题长期以来一直是主要的强化学习基准,但对于现代RL方法而言通常过于简单。在这样的经典控制问题中,输入是一个简单的特征向量,描述了位置,速度和角度等。此类问题的流行平台是rllab [29],其中包括经典问题,例如杆平衡和山地车问题,以及MuJoCo(带接触的多关节动力学),一种物理引擎,用于复杂的控制任务,例如人形步行任务[152]。
三,游戏类型和研究平台
毫无疑问,由于在公开数据集上比较结果的惯例,深度学习方法的快速发展无疑。游戏AI中的一个类似惯例是使用游戏环境来比较游戏算法,其中,基于得分或获胜的能力对方法进行排名。IEEE计算智能与游戏大会之类的会议在各种游戏环境中都开展流行的比赛。本节介绍与深度学习相关的文献中流行的游戏类型和研究平台;图2中显示了一些示例。对于每种类型,我们简要概述该类型的特征,并描述玩该类型游戏的算法所面临的挑战。本文讨论的视频游戏已在很大程度上取代了较早的较简单控制问题,这些问题长期以来一直是主要的强化学习基准,但对于现代RL方法而言通常过于简单。在这样的经典控制问题中,输入是一个简单的特征向量,描述了位置,速度和角度等。此类问题的流行平台是rllab [29],其中包括经典问题,例如杆平衡和山地车问题,以及MuJoCo(带接触的多关节动力学),一种物理引擎,用于复杂的控制任务,例如人形步行任务[152]。
B 赛车游戏
赛车游戏是指玩家被要求控制某种车辆或角色,以便在尽可能短的时间内达到目标,或在给定时间内沿轨道尽可能远地穿越的游戏。通常,游戏从玩家控制的车辆后面采用第一人称视角或有利位置。绝大多数赛车游戏都将连续输入信号作为方向盘输入,类似于方向盘。某些游戏,例如《极限竞速》(Microsoft Studios,2005–2016)或《真实赛车》(Firemint和EA Games,2009–2013)系列中的游戏,允许输入复杂的内容,包括变速杆,离合器和手刹,而侧重于街机诸如“极品飞车”(电子艺术,1994–2015)系列中的游戏通常具有较简单的输入集,因此分支系数较低。在所有赛车游戏中普遍存在的挑战是,agent需要使用微调的连续输入来控制车辆的位置并调整加速度或制动,以便尽可能快地穿越轨道。最佳地执行此操作至少需要短期计划,即向前或向前转一两圈。如果游戏中需要管理一些资源,例如燃料,损坏或提速,则需要进行长期规划。当其他车辆出现在赛道上时,在试图管理或阻止超车时会增加一个对抗性计划方面。通常在存在隐藏信息(轨道上不同部分上其他车辆的位置和资源)的情况下进行此计划。开放式赛车模拟器TORCS[168]是使用逼真的3D图形进行视觉强化学习的一种流行环境。

Fig. 2. Screenshots of selected games and frameworks used as research platforms for research in deep learning.
C.第一人称射击游戏(FPS)
最近出现了更高级的游戏环境,用于第一人称射击游戏(FPS)中的视觉强化学习agent。与ALE基准中的经典街机游戏相比,FPS具有3D图形和部分可观察的状态,因此是学习时更现实的环境。通常,观点是由玩家控制的角色,尽管某些FPS类别中的游戏大多采用过肩的观点。第一人称射击游戏的设计使得挑战的一部分就是简单的快速感知和反应,尤其是发现敌人并迅速瞄准他们。但是,还存在其他认知挑战,包括在复杂的三维环境中的定向和移动,预测多个对手的动作和位置以及在某些游戏模式下还进行基于团队的协作。如果使用视觉输入,则存在从像素提取相关信息的挑战。在FPS平台中有ViZDoom,该框架允许agent使用屏幕缓冲区作为输入来播放经典的第一人称射击游戏《毁灭战士》(id Software,1993–2017)[73]。DeepMind Lab是一个基于Quake III Arena(id Software,1999)引擎[3]的3D导航和解谜任务的平台。
D.开放世界游戏
Minecraft(Mojang,2011)或Grand Theft Auto(Rockstar-Games,1997–2013)系列等开放世界游戏的特点是非常非线性的游戏玩法,需要探索的游戏世界很多,既没有设定目标,也有很多目标 内部秩序不明确,在任何给定时间都有很大的行动自由。agent面临的主要挑战是探索世界并设定切合实际和有意义的目标。由于这是一个非常复杂的挑战,因此大多数研究都使用这些开放环境来探索强化学习方法,这些方法可以重用已知学识并将其转移到新任务中。马尔默计划(Project Malmo)是建立在开放世界游戏《我的世界》(Minecraft)之上的平台,可用于定义许多不同和复杂的问题[65]。
E.实时策略游戏
策略游戏是玩家控制多个角色或单位的游戏,其目的是在某种征服或冲突中占上风。通常但并非总是如此叙述和图形反映了军事冲突,其中单位可能是骑士,坦克或战舰。策略游戏的主要挑战是制定并执行涉及多个单位的复杂计划。通常,此挑战比诸如Chess之类的经典棋盘游戏中的计划挑战要困难得多,主要是因为必须随时移动多个单元,并且有效的分支因子通常很大。规划期可能会非常长,游戏开始时采取的行动会影响整体策略。此外,要预测一个或多个自身具有多个单位的对手的行动也存在挑战。实时策略游戏(RTS)是一种策略游戏,它不会分阶段进行,而是可以在任何时间点采取行动。RTS游戏将时间优先级的挑战添加到了玩策略游戏已经很艰巨的挑战中。《星际争霸》(暴雪娱乐公司,1998–2017年)系列无疑是实时战略(RTS)类别中研究最多的游戏。Brood War API(BWAPI)1使软件可以在游戏运行时与StarCraft通信,例如提取状态特征并执行操作。BWAPI已在游戏AI研究中广泛使用,但目前只有少数几个应用了深度学习的示例。TorchCraft是建立在BWAPI之上的库,该库将科学计算框架Torch与StarCraft连接起来,从而可以对该游戏进行机器学习研究[145]。此外,DeepMind和Blizzard(StarCraft的开发者)开发了一种机器学习API,以支持StarCraft II中的研究,其功能包括为卷积网络设计的简化视觉效果[157]。该API包含多个迷你挑战,同时还支持完整的1v1游戏设置。μRTS[104]和ELF[151]是两个简约的RTS游戏引擎,实现了RTS游戏中存在的某些功能。
F.团体运动会
流行的体育游戏通常基于基于团队的体育活动,例如足球,篮球和足球。这些游戏旨在通过逼真的动画和3D图形来尽可能逼真。在一年一度的机器人世界杯足球赛(RoboCup)中,几种类似于足球的环境已被广泛用作研究平台,包括物理机器人和2D / 3D模拟[3]。Keepaway-Soccer是一种简单的类似于足球的环境,其中一个团队的探员试图保持对球的控制权,而另一团队则试图获得对球的控制权[138]。类似的多agent环境学习方法是RoboCup 2D半场进攻(HFO),由2-3名球员组成的团队在足球场的一半上扮演进攻或防守的角色[50]。
G.文字冒险游戏
经典的文字冒险游戏是一种互动小说形式,在游戏中,玩家会获得文字而非文字的描述和说明,并通过基于文字的命令与故事情节互动[144]。这些命令通常用于查询系统的状态,与故事中的角色进行交互,收集和使用物品或在虚构的世界中导航。这些游戏通常实现三种基于文本的界面之一:基于解析器,基于选择和基于超链接[54]。基于选择的界面和基于超链接的界面以列表,上下文或状态描述中的链接的形式,在给定状态下向播放器提供可能的操作。另一方面,基于解析器的界面可以接受任何输入,并且玩家必须学习游戏可以理解的单词。这对计算机很有趣,因为它更类似于自然语言,在自然语言中,您必须根据对语言和给定状态的理解,知道应该采取什么行动。与街机游戏等其他游戏类型不同,文本冒险游戏还没有人人都能比较的标准游戏基准。这使得很多结果难以直接比较。许多研究都针对可在Infocom的Z-Machine游戏引擎上运行的游戏,该引擎可播放许多早期的经典游戏。最近,Microsoft引入了TextWorld环境,以帮助创建标准化的文本冒险环境[25]。
H.OpenAI体育馆和宇宙
相比于单一学习界面的智能学习算法,OpenAI Gym是一个大型的强化学习平台,可以连接到一组不同的环境,包括ALE,GVG-AI,MuJoCo,Malmo,ViZDoom等[17]。OpenAI Universe是OpenAI Gym的扩展,目前可与上千种Flash游戏接口,并计划在将来添加许多现代视频游戏
4 深度游戏学习方法
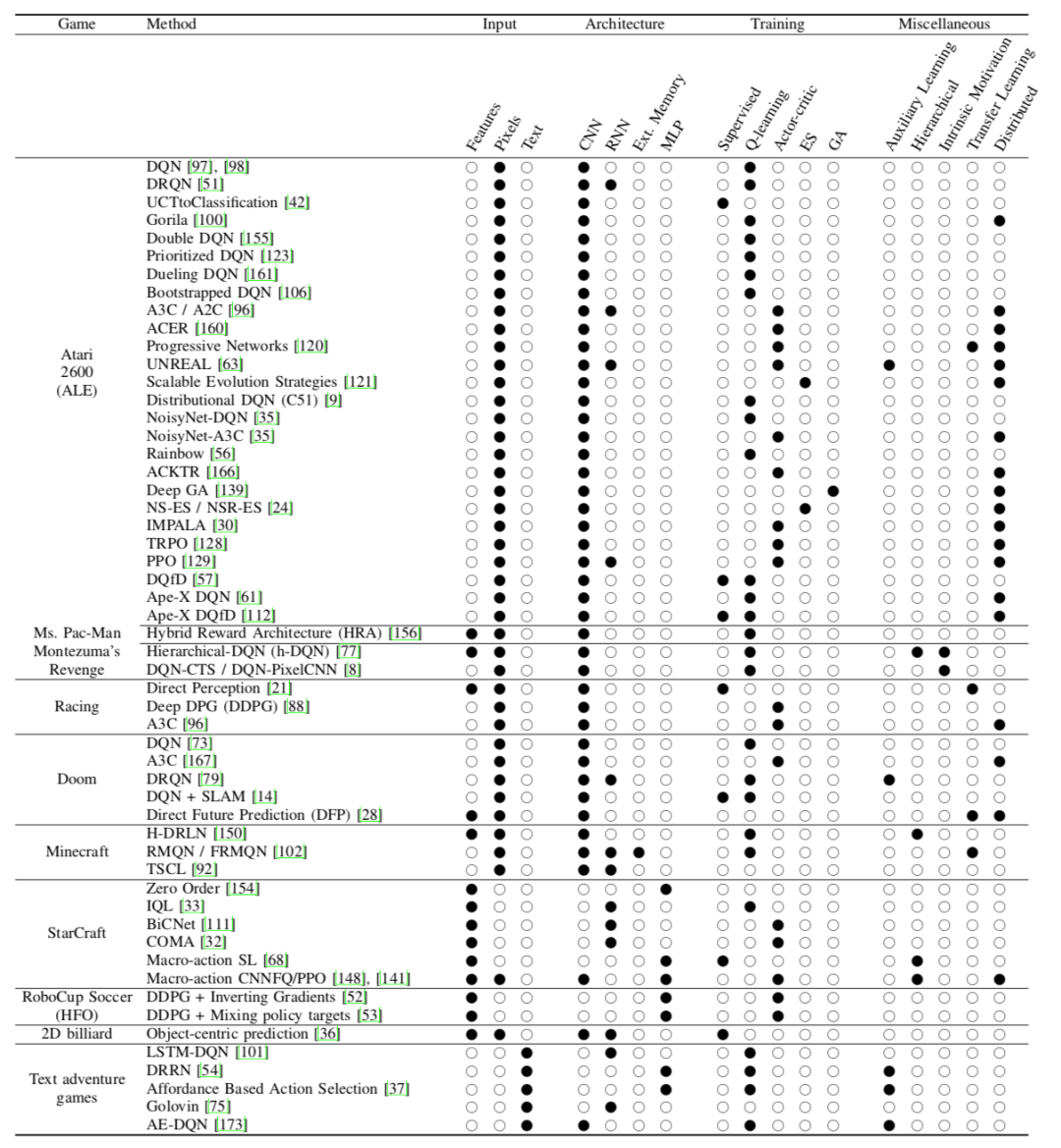
本节概述了用于玩视频游戏的深度学习技术,按游戏类型划分。表II列出了每种游戏类型和亮点的深度学习方法,它们输入了功能,网络架构以及他们所依赖的训练方法。深度RL中使用的典型神经网络架构如图3所示。
A.街机游戏
街机学习环境(ALE)包含50多种Atari游戏,并已成为深度强化学习算法的主要测试平台,该算法直接从原始像素学习控制策略。本节回顾了ALE中已演示的主要改进。表IV-A显示了这些进展的概述。
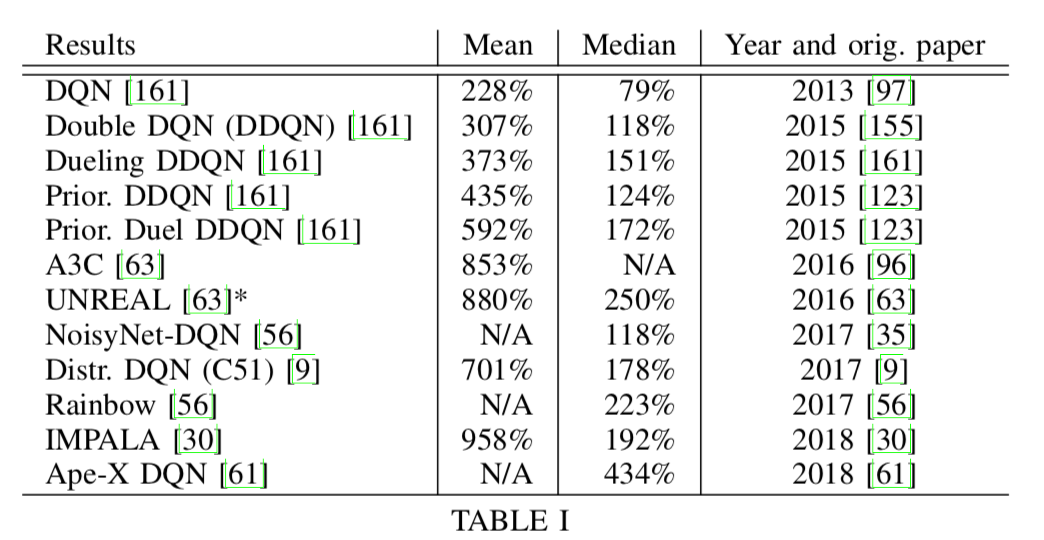
深度Q网络(DQN)是第一个在ALE中显示人类专家级控制的学习算法[97]。DQN已在7款Atari 2600游戏中进行了测试,其性能优于以前的方法,例如具有特征构建功能的SARSA [7]和神经进化[49],以及三款游戏的人类专家。DQN基于Q学习,其中神经网络模型学习近似Qπ(s,a),该Qπ(s,a)估计在遵循行为策略μ的情况下在状态s下采取行动a的预期回报。一个简单的网络体系结构由两个卷积层和一个单独的全连接层组成,用作函数逼近器。DQN中的关键机制是体验重播[89],其中{st,at,rt + 1,st +1}形式的体验存储在重播内存中,并在网络更新时分批随机采样。这使算法能够重用并从过去和不相关的经验中学习,从而减少了更新的差异。DQN后来通过一个单独的目标Q网络进行了扩展,该参数在各个更新之间保持固定,并在49个经过测试的游戏中有29个显示出超过人类专家的分数[98]。深度循环Q学习(DRQN)在输出之前在循环层上扩展了DQN体系结构,并且对于具有部分可观察状态的游戏非常有效[51]。在使用Gorila架构(通用强化学习架构)的情况下,DQN的分布式版本在49款游戏中有41项优于非分布式版本[100]。Gorila将收集经验的演员并行化到分布式重放存储器中,并并行化训练来自相同重放存储器的样本的学习者。
Q学习算法的一个问题是它经常高估动作值,因为它使用相同的值函数进行动作选择和动作评估。基于Double-DQN[46]的双DQN减少了通过学习两个价值网络观察到高估参数θ和θ'都使用另一个网络进行价值估算,以使目标Yt = Rt + 1 +γQ(St + 1,maxQ(St +1,a;θt);θ't)[155]。另一个改进是优先播放来自根据TD错误,哪些重要经验被更频繁地采样,这被证明可以显着改善DQN和Double-DQN [123]。决斗DQN使用在卷积层之后分为两个流的网络分别估计状态值Vπ(s)和动作优势Aπ(s,a),以使Qπ(s,a)= Vπ( s)+Aπ(s,a)[161]。Dueling-DQN可改善Double DQN,也可与优先体验重播结合使用。Double-DQN和Dueling-DQN在RLE的五种更为复杂的游戏中也进行了测试,平均得分约为人类专家的50%[15]。在这些实验中,最好的结果是在游戏Mortal Kombat(Midway,1992)中以Dueling-DQN进行,占128%。自举DQN通过训练多个Q网络来改善探索。在每个训练阶段都使用随机采样的网络,并且自举掩码会调制梯度以不同方式训练网络[106]。通过训练一个网络以进行竞争性或合作性多人游戏,可以使用DQN来学习强大的策略每个玩家,并在训练过程中互相对抗[146]。经过多人游戏模式训练的特工在对抗新型对手时表现出色,而经过固定算法训练的特工无法将其策略推广到新型对手。DQN,SARSA和Actor-Critic方法的多线程异步变体可以在一台机器上利用多个CPU线程,从而减少了与并行线程数量大致成线性关系的训练[96]。这些变体不依赖于重播内存,因为网络会根据并行参与者的不相关经验进行更新,这也有助于稳定基于策略的方法。异步优势Actor-Critic(A3C)算法是一种actor-critic方法,它使用多个并行agent来收集所有异步更新全局actor-critic网络的体验。A3C的性能优于优先决斗DQN,后者在GPU上进行了8天的培训,而在CPU上仅进行了一半的培训时间[96]。具有经验重演的行为者批判方法(ACER)实现了一种有效的信任区域策略方法,该方法强制更新与过去策略的运行平均值之间的偏差不大[160]。ALE中的ACER的性能与具有优先级经验回放的Dueling DQN匹配,而没有经验回放则与A3C相匹配,而数据效率更高。具有渐进神经网络的A3C [120]可以有效地将学习从一种游戏转移到另一种游戏。通过为每个新任务实例化一个网络来完成培训,并连接到所有先前学习的网络。这使新网络可以访问已经学习的知识。
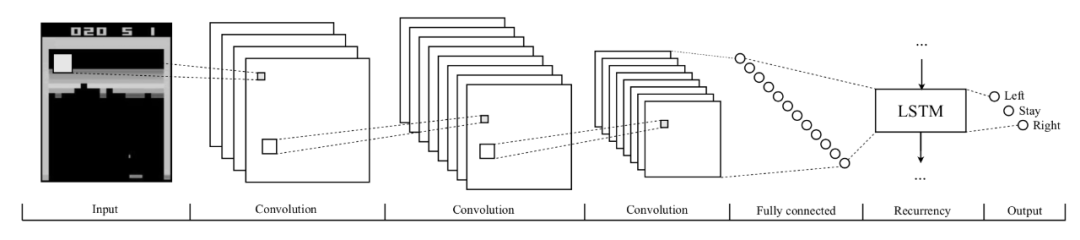
图3.在深度强化学习中使用像素输入进行游戏的典型网络架构示例。输入通常由预处理的屏幕图像或几个堆叠或串联的图像组成,其后是几个卷积层(通常不合并)和几个完全连接的层。循环网络在完全连接的层之后具有一个循环层,例如LSTM或GRU。对于游戏中每种独特的动作组合,输出通常包含一个单元,而行为评论家方法也具有一个用于状态值V(s)的单元。这种体系结构的示例,没有递归层并且有一些变化,是[97],[98],[100],[155],[123],[106],[96],[160],[120],[121],[9],[35],[161],[56],[166],[139],[24],[30],以及带有循环层的示例为[51],[96 ],[63]。
参与者和评论者Actor-Critic(A2C)是A3C的一种同步变体[96],A3C出现在AC之前。可以分批同步更新参数,并且在仅维护一个神经网络的情况下具有可比的性能[166]。使用Kronecker要素信任区域(ACKTR)的Actor-Critic通过对参与者和评论者的自然政策梯度更新进行近似来扩展A2C[166]。在Atari中,与A2C相比,ACKTR的更新速度较慢(每个时间步长最多25%),但采样效率更高(例如,在Atlantis中是10倍)[166]。信任区域策略优化(TRPO)使用替代目标,并为单调策略的改进提供了理论上的保证,而实际上实现了一种称为信任区域的近似方法[128]。这是通过限制网络更新并限制当前和当前的KL差异来完成的。更新的政策。TRPO在Atari游戏中具有强大且数据高效的性能,同时它对内存的要求很高,并且有一些限制。近端策略优化(PPO)是对TRPO的改进,它使用类似的替代目标[129],但通过添加KL-散度作为惩罚,使用了软约束(最初在[128]中建议)。它使用固定的替代目标代替固定的惩罚系数,该目标在某些指定时间间隔之外对策略更新进行惩罚。PPO被证明比A2C具有更高的采样效率,与Atari中的ACER相当,而PPO不依赖于重播内存。在连续控制任务中,PPO还具有与TRPO相当或更好的性能,同时更简单,更易于并行化。IMPALA(重要加权演员学习者体系结构)是一种A2C,其中具有GPU访问权限的多个学习者彼此之间共享梯度,同时从一组参与者中同步更新[30]。这种方法可以扩展到大量机器,并且性能优于A3C。此外,IMPALA经过训练,具有一组参数,可以玩ALE中的全部57个Atari游戏,其人类标准化平均得分为176.9%(中位数为59.7%)[30]。参与者在IMPALA设置中收集的经验可能缺乏学习者的政策,从而导致脱离政策的学习。通过V-trace算法可以减轻这种差异,该算法根据参与者和学习者的政策之间的差异来权衡体验的重要性[30]。UNREAL(无监督的强化和辅助学习)算法基于A3C,但使用重播内存,可同时从中学习辅助任务和伪奖励功能[63]。相对于ALE中的香草A3C,UNREAL仅显示了很小的改进,但在其他领域则显示出较大的改进(请参阅第IV-D节)。分布DQN通过将Q(s,a)视为收益的近似分布,而不是将每个动作的单个近似期望视为对强化学习的分布观点[9]。分布分为所谓的原子集,它决定了分布的粒度。他们的结果表明,分布越细,结果越好,并且具有51个原子(此变体称为C51),其ALE的平均得分几乎与UNREAL相当。
在NoisyNets中,将噪声添加到网络参数中,并使用梯度下降来学习每个参数的唯一噪声级别[35]。与ε贪婪探索相反,agent人从策略或从统一随机分布中采样操作,NoisyNets使用该策略的嘈杂版本来确保探索,这被证明可以改善DQN(NoisyNet-DQN)和A3C(NoisyNet-A3C)。Rainbow结合了DQN的多项增强功能:双DQN,优先重播,决斗DQN,分布式DQN和NoisyNets,其平均得分高于任何一项增强[56]。进化策略(ES)是一种黑盒优化算法,它依靠通过随机噪声进行参数探索而不是计算梯度,并且在使用更多CPU时可以在训练时间上线性加速,从而高度并行化[121]。720个CPU使用了1个小时,此后ES在51款游戏中有23款的性能优于A3C(运行了4天),而ES则由于其高度并行化而使用了3至10倍的数据。ES仅运行了一天,因此目前尚不清楚它们的全部潜力。新颖性搜索是一种流行的算法,可以通过指导新颖性行为来克服具有欺骗性和/或稀疏奖励的环境[84]。ES已被扩展为使用新颖性搜索(NS-ES),它通过基于RAM状态定义新颖的行为,在一些具有挑战性的Atari游戏中胜过ES[24]。使用新颖性和奖励信号的称为NSR-ES的质量多样性变体可以达到更高的性能[24]。在少数游戏中,NS-ES和NSR-ES的效果较差,可能是奖励功能不稀疏或具有欺骗性。一种具有高斯噪声突变算子的简单遗传算法可改进深层神经网络(Deep-GA)的参数,并且可以在多个Atari游戏中获得令人惊讶的好成绩[139]。在使用多达数千个CPU的13种Atari游戏中,Deep-GA显示出与DQN,A3C和ES相当的结果。此外,在计算量大致相同的情况下,随机搜索在13场比赛中有4场表现优于DQN,在5场比赛中表现优于A3C [139]。尽管人们一直担心进化方法不能像基于梯度下降的方法那样可扩展,但一种可能性是将特征构造与策略网络分开。然后,进化算法可以创建仍然发挥良好作用的极小的网络[26]。一些监督学习方法已应用于街机游戏。在郭等。[42]使用蒙特卡洛树搜索,离线部署慢速计划agent,以通过多项式分类生成用于训练CNN的数据。这种方法被称为UCTtoClassification,表现优于DQN。策略提炼[119]或模仿角色[108]的方法可用于训练一个网络来模仿一组策略(例如,针对不同的游戏)。这些方法可以减小网络的大小,有时还可以提高性能。可以使用DQNagent使用编码,转换,解码网络体系结构从数据集中学习帧预测模型。然后可以在再训练阶段使用该模型来改进勘探[103]。自我监督的任务,例如奖励预测,状态后继对的验证以及将状态和后继状态映射到行动可以定义用于政策网络预训练的辅助损失,最终可以改善学习[132]。培训目标向agent提供反馈,而绩效目标则指定目标行为。通常,单个奖励功能会同时扮演这两个角色,但是对于某些游戏,性能目标无法充分指导训练。混合奖励架构(HRA)将奖励功能分为n个不同的奖励功能,其中每个功能都被分配了一个单独的学习agent[156]。HRA通过在网络中具有n个输出流以及n个Q值来做到这一点,这些Q值在选择动作时进行组合。HRA能够以更少的成本获得最大可能的分数超过3,000集。
B.蒙特祖玛的复仇
反馈稀疏的环境仍然是加强学习的挑战。蒙特祖玛的复仇游戏就是ALE中这种环境的一个很好的例子,因此已经进行了更详细的研究,并用于基于内在动机和好奇心的基准学习方法。应用内在动机的主要思想是基于某种自我奖励系统来改善对环境的探索,这最终将帮助主体获得外部奖励。DQN在此游戏中未获得任何奖励(得分为0),而Gorila的平均得分仅为4.2。人类专家可以达到4,367点,很显然,到目前为止介绍的方法无法应对如此稀疏的奖励环境。一些有希望的方法旨在克服这些挑战。分层DQN(h-DQN)[77]在两个时间尺度上运行,其中一个Q值函数Q1(s,a; g)(控制器)学习有关满足上级Q选择的目标的操作的策略值函数Q2(s,g),元控制器,它学习有关内在目标(即选择哪些目标)的策略。这种方法在蒙特祖玛的复仇中平均得分约为400,目标定义为特工达到(碰撞)某种类型的对象。因此,此方法必须依赖某种对象检测机制。当观察到意外的像素配置时,伪计数已被用于以探索性奖金的形式提供内在动机,并且可以从CTS密度模型[8]或神经密度模型[107]中得出。密度模型为图像分配概率,与在同一幅图像上再训练一次相比,模型对观测图像的伪计数是模型的预测变化。通过将DQN与CTS密度模型(DQN-CTS)或PixelCNN密度模型(DQN-PixelCNN)相结合,在蒙特祖玛的复仇和其他困难的Atari游戏中取得了令人印象深刻的结果[8]。有趣的是,当CTS密度模型与A3C(A3C-CTS)结合使用时,结果效果不佳[8]。Ape-X DQN是类似于Gorila的分布式DQN体系结构,因为演员与学习者是分开的。Ape-X DQN使用376核和1个GPU(在50K FPS上运行),在57款Atari游戏中都可以达到最先进的效果[61]。从演示中进行的深度Q学习(DQfD)从经验重播缓冲区中抽取样本,该缓冲区由人类专家的演示数据初始化,并且优于11种稀疏奖励的Atari游戏中的先前方法[57]。Ape-X DQfD结合了Ape-X的分布式架构和DQfD的使用专家数据的学习算法,并被证明优于ALE中的所有先前方法,并优于Montezuma的Revenge [112]中的1级。为了提高性能,Kaplan等。等通过文字说明增强了agent培训。一种基于指令的强化学习方法,该方法同时使用CNN进行视觉输入,同时使用RNN进行基于文本的教学,输入的管理得分为3500分。指令与房间中的位置相关联,当agent到达那些位置时会得到奖励[71],这说明了人类和学习算法之间的卓有成效的合作。在蒙特祖玛的《复仇》中进行的实验也表明,该网络学会了推广到与以前的指令相似的看不见的指令。类似的工作演示了agent如何在学习了教师的语言之后,在称为XWORLD的类似于2D迷宫的2D迷宫环境中执行基于文本的命令,例如步行和捡起物体[172]。基于RNN的语言模块连接到基于CNN的感知模块。然后,将这两个模块连接到一个动作选择模块和一个识别模块,该模块在问答过程中学习教师的语言。
C.赛车游戏
Chen等人通常强调两种基于视觉的自动驾驶范例。[21];(1)学会直接将图像映射到动作(行为反射)的端到端系统,以及(2)解析传感器数据以做出明智决策(介导的感知)的系统。介于这些范式之间的一种方法是直接感知,其中CNN学会从图像映射到有意义的负担能力指示符,例如汽车角度和到车道标记的距离,简单的控制器就可以根据这些指示符做出决策[21]。在TORCS中记录了12个小时的人类驾驶情况,对直接感知进行了训练,并且训练后的系统能够在非常不同的环境中驾驶。令人惊讶的是,网络还能够将其推广到真实图像。端到端强化学习算法(例如DQN)不能直接应用于连续环境(例如赛车游戏),因为动作空间必须是离散的并且具有相对较低的维度。取而代之的是,诸如参与者行为准则[27]和确定性策略梯度(DPG)[134]之类的策略梯度方法可以在高维连续行动空间中学习策略。深度DPG(DDPG)是一种策略梯度方法,可同时实现体验重播和单独的目标网络,并用于从图像中训练TORCS中的CNN端到端[88]。前面提到的A3C方法也已经应用于仅使用像素作为输入的赛车游戏TORCS[96]。在那些实验中,奖励的形成取决于坐席在赛道上的速度,经过12小时的训练,A3C在有和没有对手机器人的赛道上,分别达到了人类测试人员的大约75%和90%的得分。虽然大多数从视频游戏中的高维度输入训练深度网络的方法都是基于梯度下降,但值得注意的例外是Koutńik等人的方法。[76],其中发展了傅立叶型系数,该系数编码了具有一百万以上权重的递归网络。在这里,evolution能够找到仅依赖于高维视觉输入的TORCS高性能控制器。
D.第一人称射击游戏
Kempka等。[73]证明了使用最大池化法和DQN训练的全连接层的CNN在基本情况下可以实现类似人的行为。在Visual Doom-AI竞赛20163中,许多参与者提交了经过预训练的基于神经网络的agent,这些agent在多人死亡竞赛中竞争。既举行了有限的竞赛(其中机器人以已知的水平竞争),也进行了全面的竞赛,其中包括了以看不见的水平竞争的机器人。有限赛道的获胜者使用了经过奖励塑造和课程学习的A3C训练的CNN[167]。奖励塑形解决了奖励稀疏和延误的问题,对捡起物品给予人为的积极奖励,对使用弹药和失去健康的人给予负面奖励。课程学习试图通过在一组逐渐困难的环境中进行训练来加快学习速度[11]。受限赛道上的第二名参赛者使用了经过改进的DRQN网络体系结构以及附加的全连接层流,以学习有监督的辅助任务,例如敌人侦察,目的是加快对卷积层的训练[79]。使用同时定位和映射(SLAM)从像素和深度缓冲区进行位置推断和对象映射也可以改善Doom中的DQN[14]。完整的比赛竞赛获胜者采用了直接未来预测(DFP)方法,该方法被证明优于DQN和A3C[28]。DFP广告管理系统中使用的体系结构包含三个流:一个流用于屏幕像素,一个流用于描述agent的当前状态的低维测量,还有一个用于描述业务代表的目标的指标,它是优先衡量指标的线性组合。DFP会在内存中收集经验,并接受有监督的学习技术的培训,以根据当前状态,目标和所选操作来预测未来的测量结果。在训练期间,根据以下情况选择能够产生最佳预测结果的动作:当前的目标。可以针对各种目标训练该方法,并在测试时将其推广到看不见的目标。在3D环境中导航是FPS游戏所需的重要技能之一,并且已经得到了广泛的研究。使用扩展的A3C对CNN +LSTM网络进行了训练,并提供了额外的输出,可预测像素深度和环路闭合,显示出显着的改进[95]。基于A3C的UNREAL算法实现了辅助任务,它训练网络以预测从一系列连续观察中得出的即时后续未来收益。UNREAL在OpenArena的水果采集和勘探任务上进行了测试,并获得了87%的人类标准化平均得分,而A3C仅达到53%[63]。将知识转移到新环境中的能力可以减少学习时间,并且在某些情况下对于某些具有挑战性的任务至关重要。可以通过在类似环境中用更简单的任务对网络进行预训练或在训练过程中使用随机纹理来实现转移学习[20]。Distill and Transfer Learning(Distral)方法同时训练了几个工人策略(每个任务一个),并共享一个蒸馏策略[149]。对工作人员策略进行了规范化处理,以使其紧贴共享策略,而共享策略将成为工作人员策略的重心。Distral已应用于DeepMind-Lab。内在好奇心模块(ICM)由多个神经网络组成,它根据agent无法预测采取行动的结果而在每个步骤中计算内在奖励。它被证明可以学习仅依靠内在的奖励就可以在复杂的《毁灭战士》和《超级马里奥》中导航[110]。
E.开放世界游戏
分层深度强化学习网络(H-DRLN)架构实现了终身学习框架,该框架被证明能够在Minecraft中的简单任务(例如导航,项目收集和放置任务)之间传递知识[150]。H-DRLN使用各种策略提炼[119]来将学习到的知识保留并封装到单个网络中。神经图灵机(NTM)是完全可区分的神经网络,再加上外部存储资源,可以学习解决简单的算法问题,例如复制和排序[40]。在NTM的启发下,两种基于记忆的变体称为循环记忆Q网络(RMQN)和反馈循环记忆Q网络(FR-MQN)能够解决需要记忆和主动感知的复杂导航任务[102]。师生课程学习(TSCL)框架结合了一位老师,该老师对任务进行优先排序,其中学生的表现是增加(学习)或减少(忘记)[92]。TSCL启用了策略梯度学习方法来解决迷宫问题,而这些迷宫问题在子任务的统一采样下是不可能的。
F.实时策略游戏
前面的部分描述了学会端到端玩游戏的方法,即训练了神经网络将状态直接映射到动作。但是,实时策略(RTS)游戏提供了更为复杂的环境,在这种环境中,玩家必须同时在部分可观察的地图上实时控制多个agent。另外,RTS游戏没有游戏内计分,因此奖励由谁赢得游戏来确定。由于这些原因,在可预见的将来学习端到端玩RTS游戏可能是不可行的,到目前为止,已经研究了子问题。对于简单的RTS平台μRTS,在生成的数据集上使用监督学习将CNN训练为状态评估器,并与Monte Carlo Tree Search(蒙特卡洛树搜索) [136],[4]结合使用。该方法的性能明显优于以前的评估方法。《星际争霸》一直是人工智能研究的流行游戏平台,但到目前为止仅提供了几种深度学习方法。《星际争霸》的深度学习方法侧重于微管理(单元控制)或构建顺序计划,而忽略了游戏的其他方面。在战斗场景中可以避免《星际争霸》中奖励延迟的问题。在这里,奖励的形式可以是所造成的损害与所遭受的损害之间的差额[154],[33],[111],[32]。状态和动作通常是相对于单位进行本地描述的,单位是从游戏引擎中提取的。如果对agent进行单独培训,则很难知道是哪个agent对全球报酬做出了贡献[19],这一问题被称为多agent信用分配问题。一种方法是训练通用网络,该网络可分别控制每个单元,并根据每个情节中产生的奖励使用零级优化在策略空间中进行搜索[154]。该策略能够为多达15个单位的军队学习成功的政策。独立Q学习(IQL)通过单独控制单元,同时将其他agent视为环境的一部分来简化多agent-RL问题[147]。这使得Q学习可以很好地扩展到大量agent。但是,当将IQL与最新技术(例如体验重播)结合使用时,agent倾向于根据过时策略的经验来优化其策略。通过在经验上应用记忆和应用重要性加权损失函数可以自然克服陈旧的数据,从而克服了这一问题,这对于某些小型战斗场景已显示出改进[33]。多主体双向协调网络(BiC-Net)实现了基于双向RNN的矢量化行为者批评框架,每个主体具有一个维度,并输出一系列操作[111]。这种网络体系结构是其他方法所独有的,因为它可以处理任意数量的不同类型的单元。反事实多主体(COMA)策略梯度是一种行为者批评方法,具有集中的批评者和分散的行动者,通过批评者网络计算出的反事实基线来解决多主体信用分配问题[32]。COMA在分散作战的情况下,在每边最多10个单位的小型战斗场景中,可以达到最新成果。深度学习也已应用于星际争霸中的构建顺序计划中,它使用基于宏的监督学习方法来模仿人类策略[68]。训练有素的网络被集成为现有bot中使用的模块,该bot能够以其他方式手工制作的行为玩完整游戏。卷积神经网络拟合Q学习(CNNFQ)是另一种基于宏的方法,这里使用RL而不是SL,已经在DoubleCQt II中接受Double DQN的训练,以用于构建订单计划,并且能够与中级脚本机器人竞争小地图[148]。
G.团体运动会
深度确定性策略梯度(DDPG)已应用于RoboCup-2D半场进攻(HFO)[51]。角色网络使用了两个输出流,一个用于选择离散的动作类型(破折号,转弯,铲球和脚踢),一个用于每种动作类型的1-2个连续值参数(功率和方向)。当输出接近其边界时,反梯度边界方法会缩小梯度,如果参数超过边界,则将其反转。在2012年的RoboCup比赛中,这种方法的表现优于SARSA和最佳agent。DDPG还通过将策略更新与第一步Q-Learning更新[53]相结合而应用于HFO,并且在每个团队中只有一名球员的情况下胜过了具有专业知识的手工编码agent。
H.物理游戏
由于视频游戏通常是对现实世界的反映或简化,因此了解有关环境中物理定律的直觉可能会富有成果。使用以对象为中心的方法(也称为注视)的预测性神经网络在接受随机交互训练后学会了运行台球游戏[36]。然后,可以将这种预测模型用于计划游戏中的动作。使用虚幻引擎在类似3D游戏的环境中测试了类似的预测方法,其中对ResNet-34[55](用于图像分类的深层残差网络)进行了扩展和训练,以预测堆叠的块的视觉效果这样它们通常会掉下来[86]。残留网络实现跳过层的快捷连接,这可以改善非常深入的网络中的学习。
I.文字冒险游戏
文本冒险游戏是一种特殊的视频游戏类型,其中状态和动作都仅以文本形式呈现。一种称为LSTM-DQN [101]的网络体系结构是专门为玩这些游戏而设计的,并使用LSTM网络实现,该网络将文本从世界状态转换为矢量表示,该矢量表示估计所有可能的状态-动作对的Q值。在两种不同的文字冒险游戏中,LSTM-DQN能够平均完成96%至100%的任务。为了改善这些结果,研究人员已转向学习语言模型和单词嵌入以增强神经网络。结合了一种方法具有明确的语言理解能力的强化学习是深度强化相关网络(DRRN)[54]。这种方法有两个学习单词嵌入的网络。一个嵌入状态描述,另一个嵌入动作描述。使用诸如向量的内积或双线性运算之类的相互作用函数来计算两个嵌入向量之间的相关性。然后将相关性用作Q值,并通过深度Q学习对整个过程进行端到端培训。这种方法允许网络将训练期间未看到的短语概括化,这对于大型文本游戏是一种改进。该方法已经在文字游戏《拯救约翰》和《死亡机器》这两个基于选择的游戏中进行了测试。进一步进行语言建模,Fulda等。等明确建模的语言能力来帮助选择行动[37]。首先通过无监督学习从维基百科语料库中学习单词嵌入[94],然后使用该嵌入来计算类比,例如将歌曲作为自行车与x一起唱歌,然后可以在嵌入空间中计算x [94]。。作者建立了一个动词,名词对和另一个对象操纵对的字典。使用所学的能力,该模型可以为状态描述建议一小组动作。通过Q-Learning学习了策略,并在50个Z-Machine游戏上进行了测试。戈洛温特工专门研究语言模型[75],这些语言模型是从幻想类型的书籍中预训练的。使用单词嵌入,agent可以用已知单词替换同义词。戈洛文由五个命令生成器构成:常规,运动,战斗,战斗,收集和库存。这些是通过分析状态描述而生成的,使用语言模型为每个命令从许多功能中计算和采样。戈洛文(Golovin)不使用强化学习,其得分与可负担性方法相当。最近,Zahavy等。等提出了另一种DQN方法[173]。此方法使用一种称为“行动消除网络”(AEN)的注意力机制。在基于解析器的游戏中,动作空间非常大。AEN在玩游戏时会学会预测哪些动作对于给定的状态描述将无效。然后,使用AEN消除给定状态下的大多数可用操作,然后使用Q网络评估剩余的操作。整个过程经过端到端的培训,并通过手动约束的操作空间实现了与DQN相似的性能。尽管文本冒险游戏取得了进步,但当前的技术仍远不能与人类的表现相提并论。除文字冒险游戏外,还使用了自然语言处理这些方法如何相互影响方面的发展,对深度学习方法进行了历史回顾,在上一节中进行了回顾。这些方法中的许多方法是从以前的方法中汲取灵感或直接建立在以前的方法上的,而某些方法则应用于不同的游戏类型,而另一些方法则针对特定类型的游戏进行了量身定制。图4显示了一个影响图,其中包含已审查的方法及其与早期方法的关系(当前部分可以看成是该图的长标题)。图中的每种方法都带有颜色,以显示游戏基准。DQN[97]作为一种使用基于梯度的深度学习进行基于像素的视频游戏的算法非常有影响力,最初被应用于Atari基准测试。注意,存在较早的方法,但成功率较低,例如[109]和成功的无梯度方法[115]。Double DQN [155]和Dueling DQN [161]是使用多个网络来改进估计的早期扩展。DRQN [51]使用递归神经网络作为Q网络。优先DQN [123]是另一个早期扩展,它增加了改进的体验重播采样。自举式DQN [106]是Double DQN的基础,它采用了不同的改进采样策略。用于Atari的其他DQN增强功能包括:C51算法[9],该算法基于DQN但更改了Q函数;噪声网使网络随机,以协助探索[35];DQfD也从例子中学习[57];和Rainbow,将许多这些最先进的技术结合在一起[56]。Gorila是第一个基于DQN的异步方法[100],随后是A3C [96],该方法将多个异步agent用于参与者批评方法。2016年底,UNREAL [63]进一步扩展了该方法,该方法结合了辅助学习完成的工作以处理稀疏的反馈环境。从那时起,A3C有了很多其他扩展[166],[160],[120],[35]。IMPALA通过专注于可以玩所有Atari游戏[30]的受过训练的经纪人来进一步发展。在2018年,通过Ape-X [61],[112]继续向大规模分布式学习迈进。进化技术也正在使视频游戏复兴。第一Salimans等。等结果表明,进化策略可以与深度RL竞争[121]。然后,Uber AI又发表了两篇论文:一篇表明无导数进化算法可以与深度RL竞争[139],以及对ES的扩展[24]。它们得益于易于并行化,并且可能在勘探中具有一定优势。引入DQN时在Atari上使用的另一种方法是信任区域策略优化[77]。这将更新从环境更新的替代目标。2017年下半年,引入了近端策略优化作为一种更健壮,更简单的agent优化方案,该方案也借鉴了A3C的创新[129]。一些扩展专门针对Montezuma的复仇,这是ALE基准内的游戏,但是由于稀疏的奖励和隐藏的信息而特别困难。在Montezuma上表现最佳的算法是通过使用内在动机[8]和分层学习[77]扩展DQN来实现的。Packman女士还从Atari选拔出来,在那里,奖励功能是在单独的部分中学习的,以使agent对新环境更健壮[156]。《毁灭战士》是2016年的新基准。该游戏的大部分工作都在扩展为Atari设计的方法,以处理更丰富的数据。A3C+课程学习[167]建议在A3C中使用课程学习。DRQN +辅助学习[79]通过在训练过程中增加额外的奖励来扩展DRQN。DQN + SLAM [14]结合了使用DQN映射未知环境的技术。DFP [28]是唯一没有扩展Atari技术的方法。与Atari的UCT分类[42],台球的以对象为中心的预测[36]和Racing的直接感知[21]一样,DFP广告管理系统使用监督学习来学习游戏。所有这些,除了《 UCT分类》外,都学会了直接预测游戏的某些未来状态并根据此信息进行预测。这些作品都来自不同的年份,彼此之间没有相互参照。除了直接感知,赛车上唯一独特的作品是Deep-DPG [88],它将DQN扩展为连续控制。该技术已扩展到RoboCup Soccer [52][53]。《星际争霸》微管理(单元控制)的工作基于2016年底开始的Q学习。IQL[33]通过将所有其他agent视为环境的一部分来扩展DQN优先DQN。COMA[32]通过计算反事实报酬(每个agent人增加的边际贡献)来扩展IQL。biCNet[111]和零阶优化[154]是基于强化学习的,但并非源自DQN。另一种流行的方法是分层学习。在2017年,它使用重播数据进行了尝试[68],并在2018年通过将其与两种不同的RL方法一起使用而获得了最先进的结果[141],[148]。2016年发表的一些作品将DQN扩展到Minecraft[150]。大约在同一时间,开发了使DQN上下文感知和模块化以处理大型状态空间的技术[102]。最近,课程学习也已应用于Minecraft [92]。DQN于2015年应用于文字冒险游戏[101]。不久之后,它被修改为具有特定于语言的体系结构,并使用状态-动作对相关性作为Q值[54]。这些游戏的大部分工作都集中在显式语言建模上。戈洛文特工和基于负担的行动选择都使用神经网络来学习语言模型,这些语言模型为特工提供了扮演的行动[37],[75]。最近,在2018年,DQN再次与“行动消除网络”配对使用[173]。事实证明,结合以前算法的扩展是应用于视频游戏的深度学习的一个有希望的方向,其中Atari是RL最受欢迎的基准。从表II中可以明显看出,另一个明显的趋势是对并行化的关注:在多个CPU和GPU之间分配工作。并行化最常见于行动者批评方法,例如A2C和A3C,以及进化论方法,例如Deep GA [139]和Evolution Strategies [121],[24]。分层强化学习,内在动机和迁移学习是探索掌握视频游戏中当前尚未解决的问题的有希望的新方向。
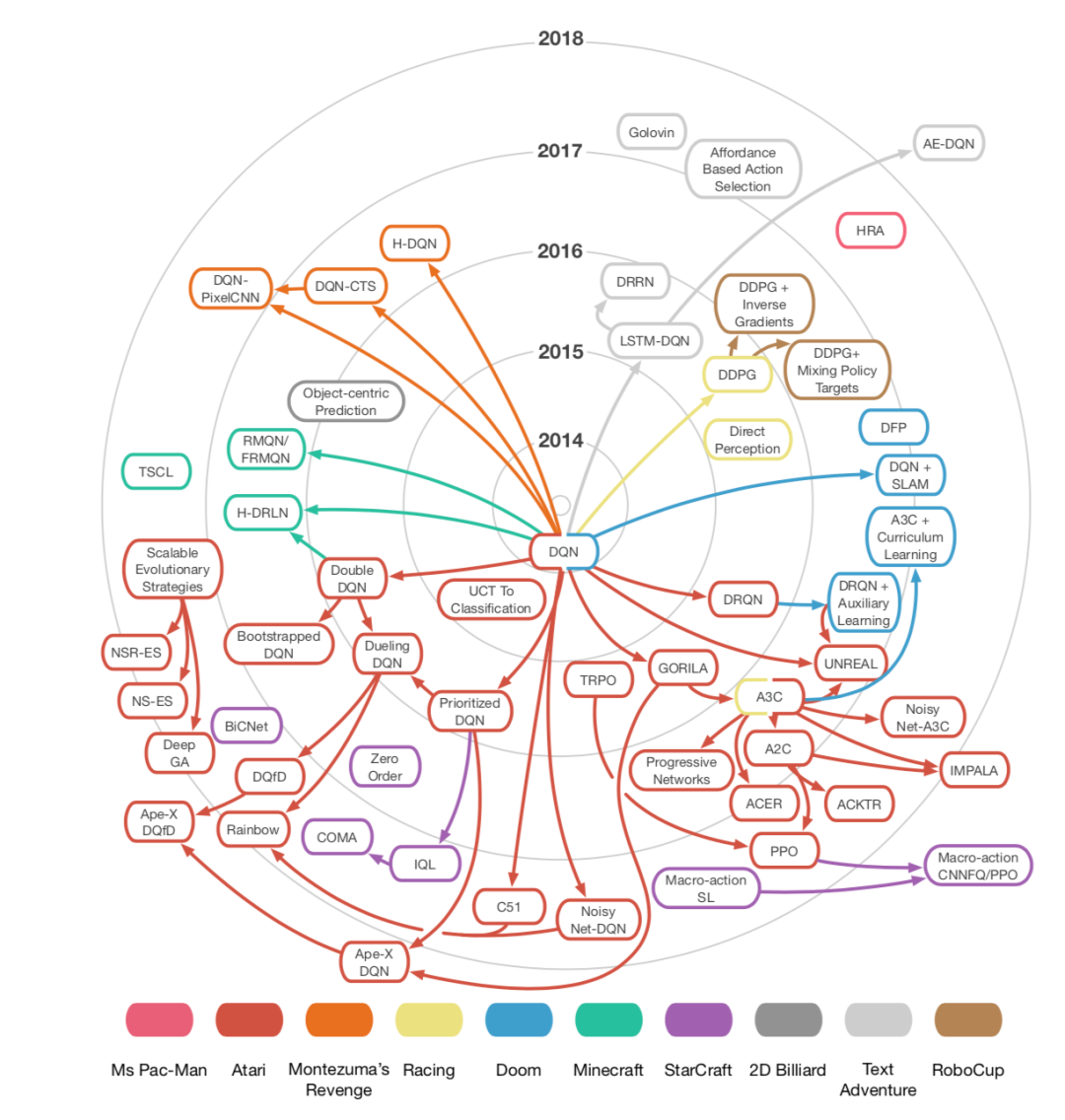
图4.本文讨论的深度学习技术的影响图 每个节点都是一种算法,而颜色代表游戏基准。距中心的距离表示原始论文在arXiv上发表的日期。箭头表示技术之间的关系。每个节点都指向使用或修改了该技术的所有其他节点。指向特定算法的箭头表示哪些算法影响了其设计。影响不是传递性的:如果算法a影响b,而b影响c,则a不一定影响c。
6. 公开挑战
尽管深度学习已在视频游戏中取得了显著成果,但仍然存在许多重要的开放挑战,我们将在这里进行回顾。确实,回顾未来一两年的研究现状,我们很可能会将当前的研究视为广泛而重要的研究领域中的早期步骤。本节分为四大类(agent模型属性,游戏行业,游戏学习模型和计算资源),它们具有不同的游戏玩法挑战,但仍对深度学习技术开放。我们提到了一些应对某些挑战的潜在方法,而目前尚不清楚针对其他挑战的最佳方法。
A.agent模型属性
1)普通电子游戏
能够解决一个问题并不能使您变得聪明。没有人会说深蓝色或AlphaGo[133]具有一般的智力,因为他们甚至不能玩跳棋(未经重新训练),更不用说煮咖啡或系鞋带了。要学习一般的智能行为,您不仅需要训练单个任务,还需要训练许多不同的任务[83]。视频游戏已被建议作为学习一般智力的理想环境,部分原因是因为有太多共享共同接口和奖励惯例的视频游戏[124]。但是,视频游戏深度学习的绝大多数工作都集中于学习玩单个游戏,甚至在单个游戏中执行单个任务。虽然基于RL的深入方法可以学习玩各种不同的Atari游戏,但开发可学习玩任何类型的游戏(例如Atari游戏,DOOM和StarCraft)的算法仍然是一项重大挑战。当前的方法仍然需要大量的努力来设计网络体系结构并奖励特定类型游戏的功能。在玩多个游戏问题上的进步包括渐进神经网络[120],它允许新游戏(不会忘记以前学习的功能)并通过横向连接利用以前学习的功能更快地解决问题。但是,它们为每个任务都需要一个单独的网络。弹性重量合并[74]可以顺序学习多个Atari游戏,并通过保护权重不被修改而避免灾难性的遗忘,这对于以前学习的游戏很重要。在PathNet中,使用进化算法来选择将神经网络的哪些部分用于学习新任务,从而证明ALE游戏具有一些转移学习的性能[31]。将来,即使这些游戏非常不同,也要扩展这些方法以学习玩多个游戏,这一点很重要-大多数当前的方法侧重于ALE框架中的不同(已知)游戏。这种研究的合适途径是GVGAI竞赛的新学习轨迹[78],[116]。与ALE不同,GVGAI有可能无限的游戏。GVGAI的最新工作表明,无模型的深度RL不仅适合于个人游戏,甚至适合个人水平。在训练过程中不断产生新的水平可以抵消这种情况[69]。多种游戏问题的重大进步可能来自外部深度学习。特别是,最近的缠结图表示法(一种遗传程序设计)已在这项任务中显示出希望[72]。最近的IMPALA算法试图通过大规模扩展解决多游戏学习问题,并取得了令人鼓舞的结果[30]。
2)克服稀疏,延迟或欺骗性的奖励
以稀疏奖励为特征的蒙特祖玛的复仇之类的游戏,对于大多数Deep RL方法仍然构成挑战。尽管将DQN与内在动机[8]或专家演示[57],[112]相结合的最新进展可以提供帮助,但稀疏奖励的游戏仍然是当前深度RL方法的挑战。关于内在动机的强化学习[22],[125]和分层强化学习的研究已有很长的历史,在这里可能有用[5],[163]。基于Minecraft的Project Malmo环境提供了一个极好的场所,可用于创建具有稀疏奖励的任务,而agent需要设定自己的目标。无导数和无梯度的方法,例如进化策略和遗传算法,通过局部采样来探索参数空间,并且对于这些游戏是有前途的,尤其是与[24],[139]中的新颖性搜索结合使用时。
3)与多个agent一起学习
当前的深度RL方法主要与培训单个agent有关。存在多个例外,多个agent必须合作[85],[33],[154],[111],[32],但是如何在各种情况下扩展到更多agent仍然是一个公开的挑战。在许多当前的视频游戏中,例如《星际争霸》或《侠盗猎车手5》,许多特工相互之间以及与玩家互动。为了将视频游戏中的多agent学习扩展到与当前单agent方法相同的性能水平,可能需要能够同时有效培训多个agent的新方法。
4)终身适应
虽然可以训练NPC很好地玩各种游戏(请参阅第IV节),但是当涉及到应该能够agent的agent时,当前的机器学习技术仍然很困难 在他们的一生中(即在玩游戏时)适应。例如,当人类玩家意识到自己总是被伏击在FPS地图中的相同位置时,可以迅速改变其行为。但是,大多数当前的DL技术将需要昂贵的重新培训才能适应这些情况以及在培训过程中未遇到的其他不可预见的情况。一个人的实时行为所提供的数据量远不及普通深度学习方法所需的数据量。这一挑战与少拍学习,迁移学习和普通视频游戏的广泛问题有关。解决这一问题对创建更具可信性和人性化的NPC至关重要。
5)类人游戏
终身学习只是当前NPC与人类玩家相比缺乏的差异之一。大多数方法都与创建尽可能玩特定游戏的agent有关,通常只考虑达到的分数。但是,如果期望人类在视频游戏中与基于AI的机器人对战或与其合作,则其他因素也会发挥作用。在这种情况下,与其创建一个能完美玩转的机器人,不如让机器人变得可信且有趣,并且具有与人类玩家相似的特质,这一点变得更为重要。类人游戏是一个活跃的研究领域,有两个针对类人行为的竞赛,分别是2k BotPrize[58],[59]和马里奥AI冠军赛的Turing测试赛道[131]。这些比赛中的大多数参赛作品都是基于各种非神经网络技术,而有些则使用了深度神经网络的进化训练来产生类似人的行为[127],[105]。
6)可调节的性能水平
几乎所有有关DL的游戏研究都旨在创建能够尽可能玩游戏,甚至“击败”游戏的agent。但是,出于游戏测试,创建教程和演示游戏的目的-在所有具有类似于人的游戏玩法的地方-能创建具有特定技能水平的特工很重要。如果您的经纪人比任何人类玩家都玩得更好,那么这不是人类在游戏中会做什么的好模型。从最基本的意义上讲,这可能需要训练一个玩得很好的agent,然后找到降低该agent性能的方法。但是,能够以更细粒度的方式调整性能水平,以便例如分别控制agent的反应速度或长期计划能力,将更为有用。甚至更有用的是能够禁止训练有素的特工的游戏风格的某些能力,从而测试例如是否可以在不采取某些行动或战术的情况下解决给定水平。实现这一点的一条途径是程序角色的概念,其中将agent的偏好编码为一组效用权重[60]。但是,尚未使用深度学习来实现此概念,并且仍不清楚如何在这种情况下实现计划深度控制。
7)处理非常大的决策空间
国际象棋的平均分支因子徘徊在30左右,围棋的平均分支因子徘徊在300左右,而《星际争霸》之类的游戏的分支因子要大几个数量级。而进化规划的最新进展已使分支因子较大的游戏的实时和长期规划达到[66],[159],[67],如何将Deep-RL扩展到如此复杂的水平是一个重要的开放挑战。在这些游戏中通过深度学习来学习启发式方法以增强搜索算法也是一个有前途的方向。
B.游戏产业
1)在游戏行业中的采用
由于DL,Facebook,Google / Alphabet,Microsoft和Amazon等各种公司对DL的开发投入了大量资金,因此DL的许多最新进展得到了加速。但是,游戏行业尚未完全接受这些进步。有时,这被游戏界以外的评论员感到惊讶,因为游戏被视为大量使用AI技术。但是,在游戏行业中最常使用的AI的类型更多地集中在具有表现力的非玩家角色(NPC)行为的手工创作上,而不是机器学习上。在该行业中缺少神经网络(和类似方法)的一个经常被引用的原因是,这种方法天生就难以控制,这可能导致不良的NPC行为(例如,NPC可能会决定杀死一个与故事有关)。另外,训练深度网络模型需要一定水平的专业知识,并且该领域的专家库仍然有限。应对这些挑战很重要,以鼓励在游戏行业中的广泛采用。另外,尽管大多数DL方法尽可能地只专注于玩游戏,但这个目标对于游戏行业而言可能并不是最重要的[171]。在此,玩家在玩耍时所经历的乐趣或参与度是至关重要的。DL在游戏生产过程中用于游戏的一种用途是游戏测试,其中人工agent测试级别是否可解决或难度是否合适。DL可能会在游戏行业中看到其最显着的用途,而不是用于玩游戏,而是基于对现有内容[140],[158]的训练或为玩家体验建模[169]来生成游戏内容[130]。在游戏行业中,包括Electronic Arts,Ubisoft和Unity在内的数家大型开发和技术公司最近已开始内部研究部门,其研究重点是深度学习。这些公司或其客户的开发部门是否也将接受这些技术,还有待观察。
2)游戏开发的互动工具
与先前的挑战相关,目前缺少设计人员用来轻松训练NPC行为的工具。尽管现在有许多用于培训深度网络的开源工具,但其中大多数都需要相当专业的知识。一种工具,可使设计人员轻松地指定所需的NPC行为(和不希望的NPC行为),同时确保对最终训练结果的一定程度的控制,将大大加快游戏行业对这些新方法的采用。从人类的喜好中学习是该领域一个有希望的方向。在神经进化的背景下[115],也对这种方法进行了广泛的研究。视频游戏,允许非专业用户为超级马里奥[135]滋生行为。最近,类似的基于偏好的方法被应用于深度RL方法[23],允许agent基于人类偏好学习和深度RL的组合来学习Atari游戏。最近,游戏公司King发布了使用模仿学习的结果,以学习对Candy Crush级别进行游戏测试的策略,为新的设计工具指明了一个有希望的方向[41]。
3)创建新型的视频游戏
DL可能会提供一种创建全新游戏的方法。当今大多数游戏设计源于没有先进的AI方法可用或硬件过于受限而无法利用它们的时代,这意味着游戏被设计为不需要AI。围绕AI设计新游戏可以帮助突破这些限制。特别是进化算法和神经进化[115]允许创建全新的游戏类型,但在这种情况下尚未探索基于梯度下降的DL。神经进化是NERO [137],银河军备竞赛[48],Petalz [114]和EvoCommander [64]等游戏的核心机制。基于梯度的优化的一个挑战是结构通常仅限于具有数学上的平滑度(即可微性),这使得创建有趣且出乎意料的输出具有挑战性。
C.游戏学习模型
关于游戏深度学习的许多工作都采用了无模型的端到端学习方法,其中训练了神经网络,以状态观察为输入来产生动作。但是,众所周知,良好且快速的模型使玩游戏变得容易得多,因为可以使用基于树搜索或进化的计划方法[171]。因此,该领域面临的一个重要的开放挑战是开发可以学习游戏正向模型的方法,从而有可能对游戏的动力学进行推理。希望学习游戏规则的方法可以更好地推广到不同的游戏变体,并表现出更强大的学习效果。在这方面有希望的工作包括Guzdial等人的方法。[44]从游戏数据中学习了超级马里奥兄弟的简单游戏引擎。Kansky等。[70]介绍了模式网络的思想,该网络遵循面向对象的方法,并经过培训可以根据当前的属性和动作来预测未来的对象属性和奖励。因此,受过训练的模式网络提供了一种概率模型,该概率模型可用于计划,并且能够执行零散地转移到Breakout的变体,类似于在训练中使用的变体。
D.计算资源
随着开放世界中更高级的计算模型和大量智能体的出现,计算速度成为一个问题。旨在通过在训练后压缩网络[62]或修剪网络[47],[43]来使网络计算效率更高的方法可能会有用。当然,一般而言或神经网络的处理能力的提高也很重要。目前,将网络实时训练为适应游戏中的变化或适应玩家的玩法,这在设计过程中可能会很有用。
7. 结论
本文回顾了应用于各种类型视频游戏中的深度学习方法。街机,赛车,第一人称射击游戏,开放世界,实时策略,团队运动,物理和文字冒险游戏。大部分经过调研的工作都在端到端的无模型深度强化学习中进行,其中卷积神经网络通过与游戏互动来学习直接从原始像素进行游戏。最近的工作表明,无梯度的进化策略和遗传算法是有竞争力的选择。某些经过调研的工作应用监督学习来模仿游戏日志中的行为,而另一些则基于学习环境模型的方法。对于简单的游戏(例如大多数街机游戏),经过审查的方法可以达到高于人类水平的性能,而在更复杂的游戏中则存在许多开放性挑战。
-
[1] S. Alvernaz and J. Togelius. Autoencoder-augmented neuroevolution for visual doom playing. In Computational Intelligence and Games (CIG), 2017 IEEE Conference on. IEEE, 2017. -
[2] K. Arulkumaran, M. P. Deisenroth, M. Brundage, and A. A. Bharath. Deep reinforcement learning: A brief survey. IEEE Signal Processing Magazine, 34(6):26–38, 2017. -
[3] M. Asada, M. M. Veloso, M. Tambe, I. Noda, H. Kitano, and G. K. Kraetzschmar. Overview of robocup-98. AI magazine, 21(1):9, 2000. -
[4] N.A.Barriga,M.Stanescu,andM.Buro.Combiningstrategiclearning and tactical search in real-time strategy games. 2017. -
[5] A. G. Barto and S. Mahadevan. Recent advances in hierarchical reinforcement learning. Discrete Event Dynamic Systems, 13(4):341– 379, 2003. -
[6] C. Beattie, J. Z. Leibo, D. Teplyashin, T. Ward, M. Wainwright, H. Ku ̈ttler, A. Lefrancq, S. Green, V. Valde ́s, A. Sadik, et al. Deepmind lab. arXiv preprint arXiv:1612.03801, 2016. -
[7] M. Bellemare, Y. Naddaf, J. Veness, and M. Bowling. The arcade learning environment: An evaluation platform for general agents. In Twenty-Fourth International Joint Conference on Artificial Intelligence, 2015. -
[8] M. Bellemare, S. Srinivasan, G. Ostrovski, T. Schaul, D. Saxton, and R. Munos. Unifying count-based exploration and intrinsic motivation. In Advances in Neural Information Processing Systems, pages 1471– 1479, 2016. -
[9] M. G. Bellemare, W. Dabney, and R. Munos. A distributional perspec- tive on reinforcement learning. In Proceedings of the International Conference on Machine Learning (ICML), 2017. -
[10] M. G. Bellemare, Y. Naddaf, J. Veness, and M. Bowling. The arcade learning environment: An evaluation platform for general agents. J. Artif. Intell. Res.(JAIR), 47:253–279, 2013. -
[11] Y. Bengio, J. Louradour, R. Collobert, and J. Weston. Curriculum learning. In Proceedings of the 26th annual international conference on machine learning, pages 41–48. ACM, 2009. -
[12] J. Bergstra, D. Yamins, and D. D. Cox. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. 2013. -
[13] J. S. Bergstra, R. Bardenet, Y. Bengio, and B. Ke ́gl. Algorithms for hyper-parameter optimization. In Advances in neural information processing systems, pages 2546–2554, 2011. -
[14] S. Bhatti, A. Desmaison, O. Miksik, N. Nardelli, N. Siddharth, and P. H. Torr. Playing doom with SLAM-augmented deep reinforcement learning. arXiv preprint arXiv:1612.00380, 2016. -
[15] N. Bhonker, S. Rozenberg, and I. Hubara. Playing SNES in the retro learning environment. 2017. -
[16] M. Bogdanovic, D. Markovikj, M. Denil, and N. De Freitas. Deep apprenticeship learning for playing video games. In Workshops at the Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015. -
[17] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schul- man, J. Tang, and W. Zaremba. Openai gym. arXiv preprint arXiv:1606.01540, 2016. -
[18] C. B. Browne, E. Powley, D. Whitehouse, S. M. Lucas, P. I. Cowling, P. Rohlfshagen, S. Tavener, D. Perez, S. Samothrakis, and S. Colton. A survey of monte carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in games, 4(1):1–43, 2012. -
[19] Y.-H. Chang, T. Ho, and L. P. Kaelbling. All learning is local: Multi- agent learning in global reward games. In NIPS, pages 807–814, 2003. [20] D. S. Chaplot, G. Lample, K. M. Sathyendra, and R. Salakhutdinov. Transfer deep reinforcement learning in 3D environments: An empirical study. NIPS, 2016. -
[21] C. Chen, A. Seff, A. Kornhauser, and J. Xiao. Deepdriving: Learning affordance for direct perception in autonomous driving. In Proceedings of the IEEE International Conference on Computer Vision, pages 2722– 2730, 2015. -
[22] N. Chentanez, A. G. Barto, and S. P. Singh. Intrinsically motivated reinforcement learning. In Advances in neural information processing systems, pages 1281–1288, 2005. -
[23] P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems, pages 4302– 4310, 2017. -
[24] E.Conti,V.Madhavan,F.P.Such,J.Lehman,K.Stanley,andJ.Clune. Improving exploration in evolution strategies for deep reinforcement learning via a population of novelty-seeking agents. In Advances in Neural Information Processing Systems, pages 5032–5043, 2018. -
[25] M.-A. Coˆte ́, A. Ka ́da ́r, X. Yuan, B. Kybartas, T. Barnes, E. Fine, J. Moore, M. Hausknecht, L. E. Asri, M. Adada, W. Tay, and A. Trischler. Textworld: A learning environment for text-based games. arXiv preprint arXiv:1806.11532, 2018. -
[26] G. Cuccu, J. Togelius, and P. Cudre-Mauroux. Playing atari with six neurons. arXiv preprint arXiv:1806.01363, 2018. -
[27] T. Degris, P. M. Pilarski, and R. S. Sutton. Model-free reinforcement learning with continuous action in practice. In American Control Conference (ACC), 2012, pages 2177–2182. IEEE, 2012. -
[28] A. Dosovitskiy and V. Koltun. Learning to act by predicting the future. In Proceedings of the International Conference on Learning Representations, 2017. -
[29] Y. Duan, X. Chen, R. Houthooft, J. Schulman, and P. Abbeel. Benchmarking deep reinforcement learning for continuous control. In Proceedings of the 33rd International Conference on Machine Learning (ICML), 2016. -
[30] L. Espeholt, H. Soyer, R. Munos, K. Simonyan, V. Mnih, T. Ward, Y. Doron, V. Firoiu, T. Harley, I. Dunning, S. Legg, and K. Kavukcuoglu. IMPALA: Scalable distributed deep-RL with im- portance weighted actor-learner architectures. In J. Dy and A. Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 1407–1416, Stockholmsmssan, Stockholm Sweden, 10–15 Jul 2018. PMLR. -
[31] C. Fernando, D. Banarse, C. Blundell, Y. Zwols, D. Ha, A. A. Rusu, A. Pritzel, and D. Wierstra. Pathnet: Evolution channels gradient descent in super neural networks. In Proceedings of the Genetic and Evolutionary Computation Conference, 2017. -
[32] J. Foerster, G. Farquhar, T. Afouras, N. Nardelli, and S. Whiteson. Counterfactual multi-agent policy gradients. In Proceedings of AAAI, 2018. -
[33] J. Foerster, N. Nardelli, G. Farquhar, P. Torr, P. Kohli, S. Whiteson, et al. Stabilising experience replay for deep multi-agent reinforcement learning. In Proceedings of the International Conference on Machine Learning, 2017.
完
总结3: 《强化学习导论》代码/习题答案大全
总结5: 万字总结 || 强化学习之路
总结9:分层强化学习(HRL)全面总结
完
第88篇:2019年-57篇深度强化学习文章汇总
第85篇:279页总结"基于模型的强化学习方法"
第84篇:阿里强化学习领域研究助理/实习生招聘
第83篇:180篇NIPS2020顶会强化学习论文
第81篇:《综述》多智能体强化学习算法理论研究
第80篇:强化学习《奖励函数设计》详细解读
第79篇: 诺亚方舟开源高性能强化学习库“刑天”
第77篇:深度强化学习工程师/研究员面试指南
第75篇:Distributional Soft Actor-Critic算法
第74篇:【中文公益公开课】RLChina2020
第73篇:Tensorflow2.0实现29种深度强化学习算法
第72篇:【万字长文】解决强化学习"稀疏奖励"
第71篇:【公开课】高级强化学习专题
第70篇:DeepMind发布"离线强化学习基准“
第66篇:分布式强化学习框架Acme,并行性加强
第65篇:DQN系列(3): 优先级经验回放(PER)
第64篇:UC Berkeley开源RAD来改进强化学习算法
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第14期论文: 2020-02-10(8篇)
第13期论文:2020-1-21(共7篇)
第12期论文:2020-1-10(Pieter Abbeel一篇,共6篇)
第11期论文:2019-12-19(3篇,一篇OpennAI)
第10期论文:2019-12-13(8篇)
第9期论文:2019-12-3(3篇)
第8期论文:2019-11-18(5篇)
第7期论文:2019-11-15(6篇)
第6期论文:2019-11-08(2篇)
第5期论文:2019-11-07(5篇,一篇DeepMind发表)
第4期论文:2019-11-05(4篇)
第3期论文:2019-11-04(6篇)
第2期论文:2019-11-03(3篇)
第1期论文:2019-11-02(5篇)



