思维的碰撞|稀疏表达偶遇深度学习
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~

paper: https://arxiv.org/abs/2006.04357
code: https://github.com/ychfan/nsr
Abstract
受启发于稀疏表达在基于稀疏编码的图像复原方法中的鲁棒性与有效性,作者尝试将稀疏的思想引入到深度学习中。所提方法在隐层神经元上强加稀疏约束,这种稀疏约束可以与梯度学习方法相结合,同时可以与卷积相结合。神经元中稀疏性有助于降低计算量且不会影响精度,同时所提方法可以放大表达维度与模型容量,而额外代价则是微小的计算消耗。作者通过实验验证了所提方法在多个图像复原任务(包含图像超分、图像降噪、压缩伪影移除等)上的重要作用。
Background
稀疏表达兴起于2003年前后,兴盛于09年前后,被广泛应用到计算机视觉的各个领域,比如图像降噪、图像超分、图像去模糊等等。笔者读研时恰逢稀疏表达的尾声,也做了一丢丢的稀疏表达方面的工作,对稀疏表达也算是有那么一点点的了解。
类似于图像块的自相似性是图像中一种非常强有力的先验信息,稀疏表达是自然界的一种非常强有力的先验信息,它同时具有极强的鲁棒性,是一种比自相似性更广义的先验信息。
稀疏编码中的稀疏表达一般指的是高维但只有有限的非零成分,从某种程度上来讲,正交表达式稀疏表达的一种特例。2010年投于TIP的《Image Super-Resolution Via Sparse Representation》代表了稀疏表达在图像超分领域的里程碑,它将图像超分的性能推到了巅峰,截止目前,该方法仍是图像超分领域中非常有效的方法之一,感兴趣的小伙伴可以去了解一下,作者有开源,只不过代码是matlab版的。
在深度学习领域中,与稀疏表达比较类似的当属模型剪枝了。然而模型剪枝会导致隐层神经元的维度降低,进而影响模型的精度。
在这篇论文中,作者在深度网络的隐层神经元添加结构稀疏约束同时保持维度不变。在高维神经元方面,作者将其沿通道维度划分为组,每次只有一组非零。非稀疏组的选择可以通过上下文特征建模,然而“选择”操作并非可微分的,故而难以进行联合训练。鉴于此,作者将稀疏约束进行relax为soft形式而非hard形式。与此同时,作者还因如了额外的cardinal维分解稀疏预测为子问题:splitting each sparse group and concatenating after cardinal independent combination of parameters.
Method
Sparse coding
首先,简单介绍一下图像复原中的稀疏应用以及它与卷及网络的关联性。假设输入图像X可以表示为字典 上的稀疏线性组合,公式描述如下:
与此同时,还需要一个额外的对偶字典 用于信号复原Y,此时可以描述为:
在SRCNN一文中,作者曾分析了稀疏表达与卷积网络之间的关联性(感兴趣的可以去看一下SRCNN中的介绍)。这里,仅做简单的关联性分析,以包含两个卷积的网络为例:
上式中的 等价于输入图像X在字典 上的投影,而 则等价于在字典 的信号重建。隐层神经元的维度/通道数决定了字典的大小与模型容量,但同时也直接影响深度模型的推理速度与内存占用。
Sparsity in hidden neurons
作者提出将隐层神经元分为k组,每组有c个节点,并约束只有一组具有非零值。类似的,卷积核可以根据隐层神经元的连接方式进行分组。以前述包含两个卷积的网络为例进行说明,此时卷积核被划分为
此时前述公式可以重写为:
当稀疏约束使得仅第i组神经元网络非零元时,上述可以进一步简化为:
作者提出采用MLP方式根据输入X选择非零元组。而MLP的设计则参考SELayer方式进行设计,描述为:
注:这里的Pool与特定块大小相关,而非整个图像。有没有小伙伴在这里看到GENet的影子,笔者认为作者在这里采用的是类似GENet的思想,而非SENet的思想。有对此感兴趣的小伙伴可以后台留言联系笔者进行讨论。
Relaxed soft sparsity
类似于稀疏编码中的 范数非可微,上式中的自适应稀疏组选择同样是不可微的。这就导致了它难以与其他模块联合训练。作者提出对稀疏约束采用softmax进行relax变为soft形式。即MLP将采用softmax预测每组的概率 :
此时,前述公式将转变为:
很明显,公式8与公式5是等价的。更幸运的是,在softmax输出上添加稀疏假设 ,可以证实上述公式可以进一步通过参数 的加权近似,此时可以描述为如下公式,可参考下面的示意图。
注:上述公式中 为共享模式,它可以设置成独立模式(独立模式效果更佳)。
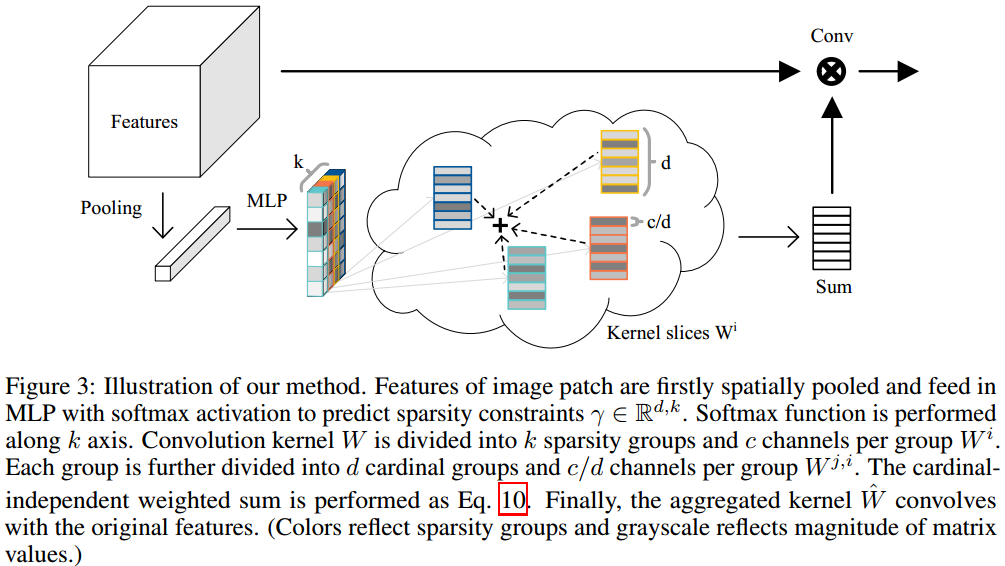
Relation Method
前面作者将hard稀疏约束转为了soft稀疏约束,额外代价则是卷积核的加权组合。看到这里,大家有没有觉得这种处理方法与DyNet,CondConv、DynamicConv的思想非常相似(不了解这三种动态滤波器卷积的小伙伴可以去看一下笔者之前分享的文章:高性能长点的动态卷积DyNet与CondConv、DynamicConv有什么区别联系。
这篇论文与CondCov的区别在于:
-
CondConv采用的是sigmoid函数进行权值归一化,而这篇论文采用的是softmax函数进行归一化。 -
CondConv中并未明确的添加稀疏约束,而该文实验表明稀疏约束对于模型精度非常重要。
Cardinality over sparsity groups
作者提到:采用简单的MLP进行模型组间稀疏约束是一种极具挑战的行为,尤其当每组的维度提升后,而且预定义组的通道的粘合也会限制稀疏模式的灵活性。受启发与ResNeXt,作者将c阶段分组为d个cardinal group,每个cardinal group包含
个节点。此时,卷积权值变为:
其中
表示第j个cardinal group中的第i个稀疏组。看到这里,有没有觉得它又与ResNeSt中的思想非常相似了呢?对ResNeSt实现感兴趣的可以去看一下笔者之间的解析关于ResNeSt的点滴疑惑与解读。
Experiments
Training Settings
图像超分训练数据:DIV2K
图像超分测试数据:Set5、Set14、BSD100、Urban100
图像降噪训练数据:BSD200-train
图像降噪测试数据:Set12、BSD64、Urban100
压缩伪影训练数据:T291
压缩伪影测试数据:LIVE1、Classic5
评价度量准则:PSNR、SSIM、FLOPs@pixel。
其他训练超参:数据增广包含随机镜像、旋转;每个图像采样100块,总计训练epoch为30;损失函数为L1;优化器为Adam;初始学习率为0.001,在20与25epoch时乘0.2.
Main Results
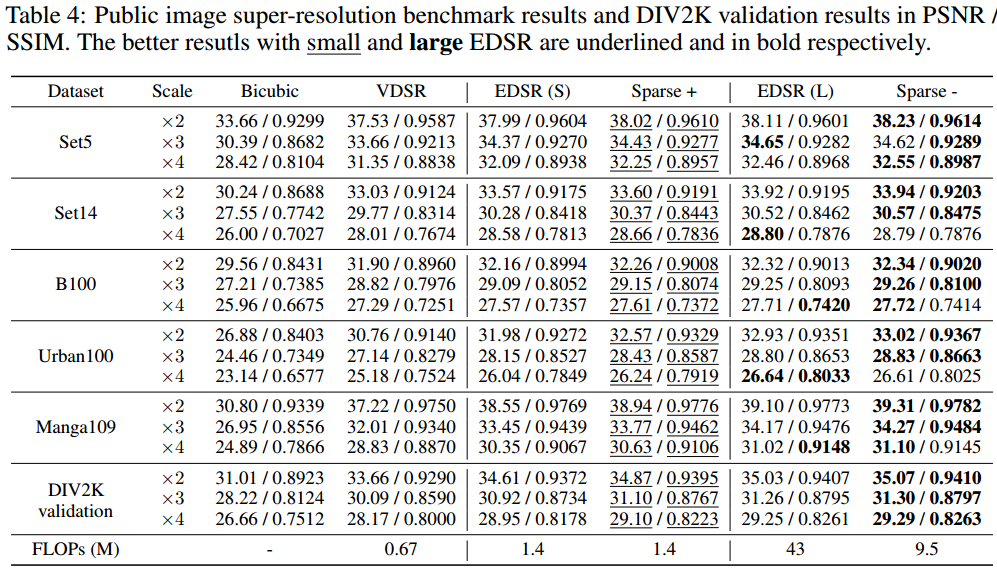
下图给出了所提方法在图像超分任务上的性能对比。作者主要与VDSR、EDSR两种超分方法进行了对比(注:对标EDSR-S的模型中间特征通道数为64,包含4个稀疏组,每个组包含16个cardinal;对标EDSR-L的模型中间特征通道数为128,包含4个稀疏组,每个组包含16个cardinal),从表中数据可以看到:(1)所提方法具有更优的性能指标;(2)所提方法具有更少的计算量,大约为EDSR的四分之一。
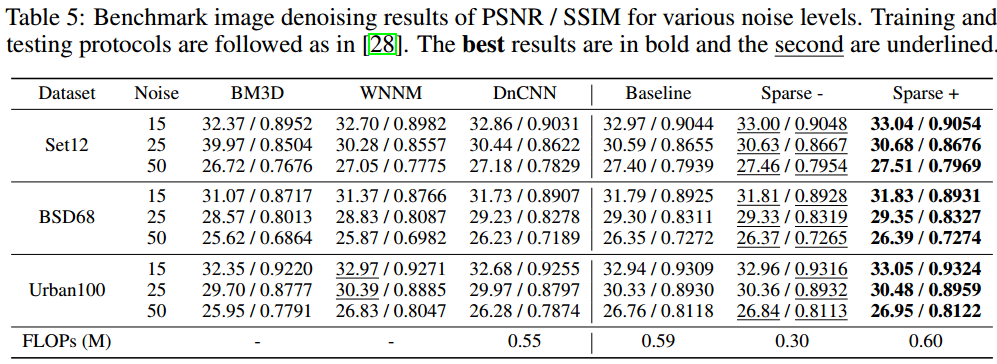
下图给出了所提方法在图像降噪任务上的性能对比。它主要与BM3D、WNNM、DnCNN方法进行了对比。从表中数据可以看到:所提方法具有更好的性能指标。
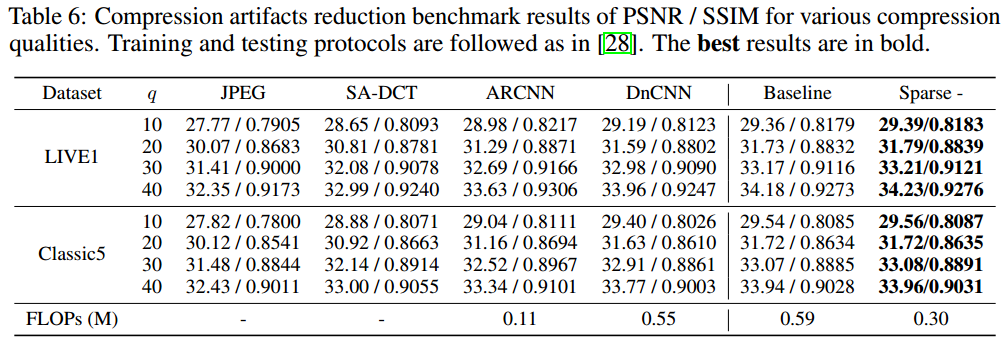
下图给出了所提方法图像去压缩伪影任务上的性能对比。对标方法为JPEG、SA-DCT、ARCNN、DnCNN等,从表中数据可以看到:所提方法具有更高的性能指标。
Ablation study
为更好的说明所提方法,作者设计了一系列的消融实验。主要是在DIV2K验证集上进行评估,选用WDSR模型作为baseline,它包含16个残差模块,32个神经元,4x放大因子,k=4。
-
Sparsity:作者尝试了几种不同的稀疏约束方式,比如Sigmoid、硬约束Gumbel-softmax、软约束Softmax等。具体指标见下表,可以看到:所提方法确实提升了性能。
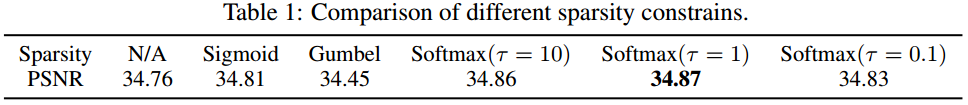
-
Cardinality: 它有助于降低稀疏组内通道的维度与互依赖型同时提升卷积核的灵活性。下图给出了不同cardinal时的性能对比,同时对比了它与SE模式的性能。
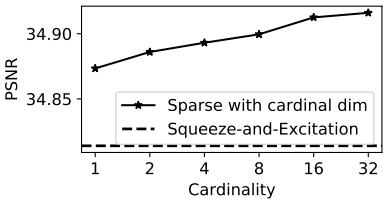
-
Efficiency:理论上该方法可以节省k倍计算消耗同时保持模型参数量不变。下表给出了模型大小与不同组数的性能关系:至少可以节省一半计算量且不会影响模型性能。
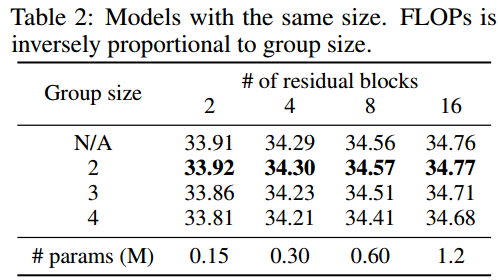
-
Capacity:作者认为可以通过扩展参数量达到扩增模型容量的目的,下表给出了实验结果。
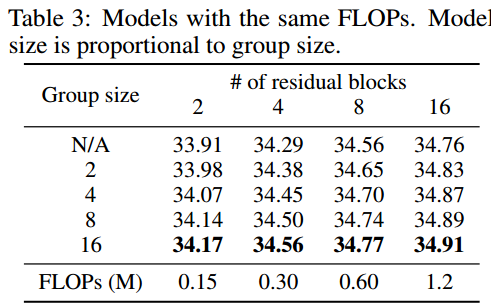
-
Kernel selection: 作者对所选择的kernel进行了可视化,见下图。越往后的kenel越关注于高频区域,即纹理复杂的区域。

Conclusion
该文提出一种在隐层神经元添加结构化稀疏的方法以使深度网络具有稀疏表达能力,它在稀疏性与可微分性方面寻求了均衡以进行联合训练学习。所提方法是一种“即插即用”方法,它可以嵌入到其他不同模型中。最后作者在多个图像复原任务中验证了所提方案的有效性。
题外话:之前在跟该文的三作(也就是PANet《非局部均值偶遇深度学习》的一作)偶聊中曾提到Yuchen大佬近期会有一篇结合稀疏表达与深度学习的图像复原方法近期会发表。今天早上刷arxiv时看到了这篇文章,花了点时间对该文的思路进行了梳理。总体而言,这篇文章这几点并未介绍清楚,
-
Relaxed soft sparsity中如何引入 ?这点作者原文中并未有较好的说明,同时实验中也缺乏相关对比; -
MLP进行稀疏约束部分介绍也是并不详细,Pool与输入块大小有关,而非全图均值池化。这里介绍也并不是很详细,笔者去研究了一下作者开源的代码才算大概了解怎么去执行;笔者认为:这里可以参考GENet的思路去设计,也许会有不错的效果。 -
它只介绍了与CondConv的区别,并未介绍其与DynamicConv的区别;不过这两篇属于同一时期的产物,不做对比完全可以理解; -
实验对比稍显不足,在超分方面,该文仅与EDSR进行了对比。实验对比方面更多更详细的对比会不会更好一些,期待作者完善一下; -
稀疏表达到动态卷积的过渡稍显生硬,权值层面的稀疏性如何体现也是有些突兀,可以参考DynamicConv中的方式引入渐变 ,这样会不会更好一些呢? -
稀疏表达由hard模式转soft部分好像与Face++提出的DRConv有些类似,可惜DRConv并未开源,无从对比。
以上仅为笔者个人一点理解,非喜勿喷。对该文有兴趣的小伙伴可以后台留言(或知乎搜索Happy)联系笔者一起讨论。
推荐阅读

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:超分辨率-小极-北大-深圳),即可申请加入极市超分辨率技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~



