最新开源无监督单目深度估计方法,解决复杂室内场景难训练问题,效果性能远超SOTA
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
一、摘要
无监督单目深度估计算法已经被证明能够在驾驶场景(如KITTI数据集)中得到精确的结果,然而最近 [5] (ICCV 2019) 指出这类算法在更复杂的场景(如室内NYUv2数据集)中难以训练。比如,GeoNet [8] (CVPR 2018) 甚至无法得出合理的结果。即使 [5] 和最新的 [6] (CVPR 2020) 针对这一问题提出了更鲁棒的训练框架,结果精度也非常有限。本文从理论和统计结果上分析了这一问题。得出结论:1、在无监督单目深度估计训练过程中,相机运动中的旋转部分是噪音而平移部分是信号。2、在NYUv2等手持相机拍摄的视频中旋转是相机运动的主要成份,而在KITTI等驾驶视频中平移是主要成份。这个结论解释了为什么无监督算法在驾驶场景表现良好而在室内场景难以训练这一现象。根据结论,本文提出了一种数据预处理的方法来解决问题。结果证明在处理后的数据上进行训练,算法性能得到大幅提升。文章以现有的无监督算法SC-SfMLearner [4] (NeurIPS 2019) 作为训练框架,得出远超SOTA [6] (CVPR 2020) 的深度估计结果。比如,在AbsRel error 上 0.147 vs. 0.189,在Acc (delta<1.25) 上 0.804 vs. 0.701。可视化对比结果如图3。
论文:Unsupervised Depth Learning in Challenging Indoor Video: Weak Rectification to Rescue, Jia-Wang Bian, Huangying Zhan, Naiyan Wang, Tat-Jun Chin, Chunhua Shen, Ian Reid, arXiv:2006.02708, 2020.
论文地址:https://arxiv.org/abs/2006.02708
代码地址:https://github.com/JiawangBian/Unsupervised-Indoor-Depth
中文主页:https://jwbian.net/unsupervised-indoor-depth-cn
二、算法回顾
1.最早是 [1] (ECCV 2016) 提出利用颜色不变性在已知相机内外参数的双目图像上训练单目深度估计网络。原理是通过网络估计出左图的深度,然后根据深度与相机参数来建立左右图的像素映射关系,接下来使用右图和映射关系来生成虚拟的左图,最后将生成的图像与真实的图像比较(即photometric loss)来训练网络。训练框架如下:
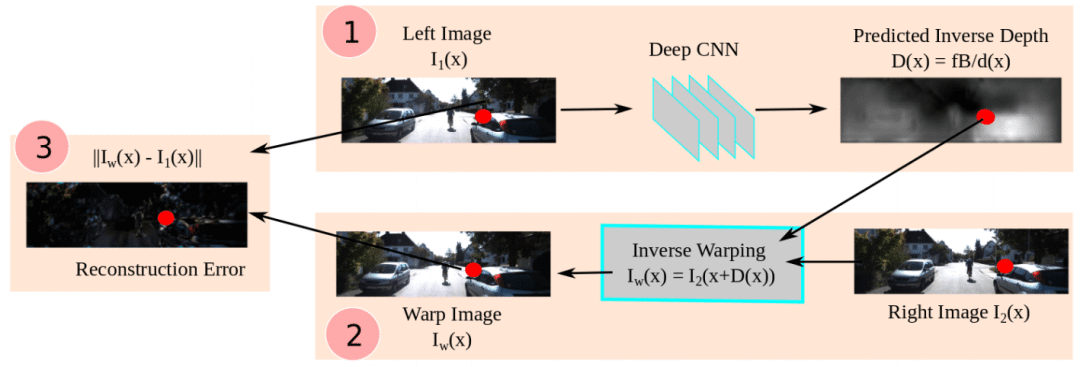
2.根据 [1],SfMLearner [2] (CVPR 2017) 提出在已知相机内参的单目视频上训练单目深度估计网络。原理是在视频前后帧上除了训练depth CNN外,再额外引入一个Pose CNN来估计相机外参(也就是相机运动),然后在训练过程中使用photometric loss来同时监督这两个网络。框架如下:
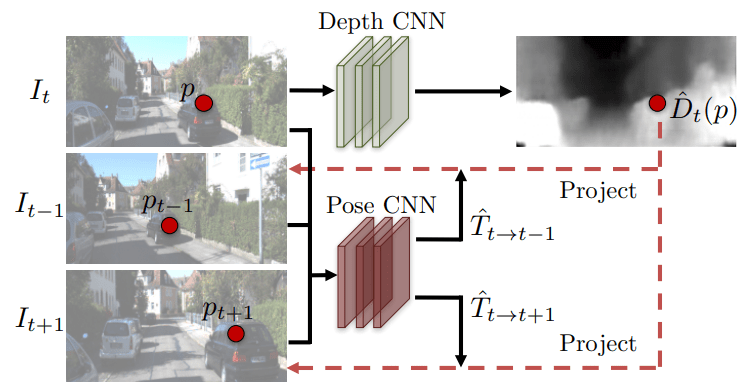
3.基于[2], SC-SfMLearner [4] 提出geometry consistency loss来约束在视频前后帧上所估计出深度的一致性,然后利用这个几何一致性来检测运动物体和遮挡区域。在计算photometric loss时移除这些病态区域,可以提升算法性能。而且用这种训练方式得到的深度估计结果具有在长视频上的尺度一致性,可以用来做SLAM / VO等任务。框架如下:
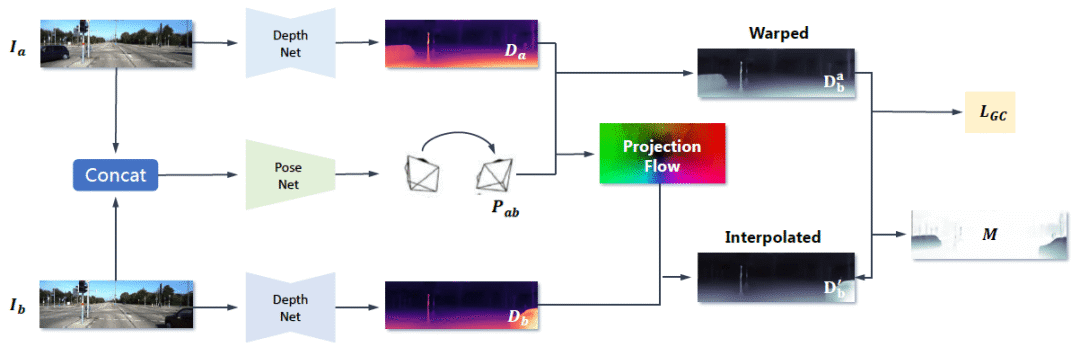
4.评论:这一类无监督算法都是利用图像深度与相机内外参数共同计算3D投影,从而生成新图像并计算photometric loss来训练网络。正是由于图像深度与投影的密切关系,使得梯度可以从图像生成误差,到投影误差,再到深度估计误差来训练网络。因此,我们接下来从投影、相机参数、与图像深度相互关系的角度来分析问题。
三、问题分析
无监督算法在KITTI上运行良好,然而在NYUv2难以训练。对比这两个数据集,除了图像纹理光线问题之外,前者相机运动简单(相机固定在车上,主要是向前开车),而后者运动轨迹复杂(手持相机,任意运动)。由于基于视频训练的无监督算法依赖对相机运动轨迹的估计(如第二部分所述),本文认为是复杂的相机运动给训练造成了障碍。因此,文章接下来首先从理论上分析相机运动对深度估计的影响,然后再统计在不同数据集上的相机运动的情况。
-
相机运动对深度估计的影响
在无监督深度估计框架中,图像深度与相机运动共同作用于3D投影,从而生成新图像并计算photometric loss来训练网络。接下来我们分别分析完整的3D投影、纯旋转投影、和纯平移投影。我们发现在完整投影和纯平移投影中,图像深度与相机运动密切相关,它们共同影响了投影结果。而在纯旋转投影过程中,图像深度与投影不相关。从控制变量法的角度,这个现象就证明了:旋转是噪音,平移是信号。具体分析如下:
(a) 完整投影:如果一个点(u1, v1)从一张图像投影到另一张图像的(u2, v2),那么它将满足:
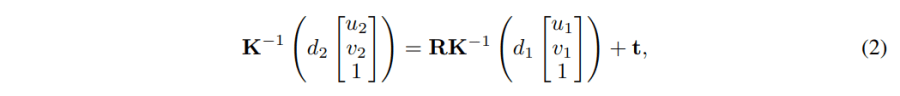
这里,K是一个3×3的相机参数矩阵,R是3×3的旋转旋转,t是3×1的平移向量,d1, d2分别代表这个点在两张图像上的深度。也就是说当我们知道(u1,v2, d1), K, R, t,就可以计算出(u2, v2, d2)。这说明了在完整投影过程中,图像深度与相机运动共同影响了投影结果。
(b)纯旋转投影:当相机运动只包含旋转而没有平移的时候,那公式(2)就变成了:
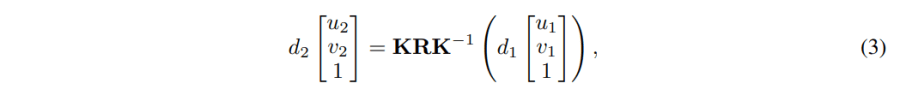
其实这里[KRK^-1]就是homography matrix (H)。重写公式(3)就得到:
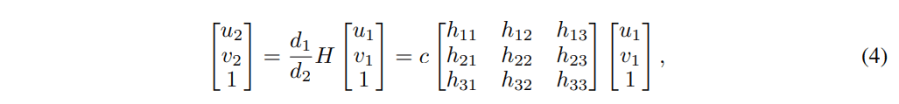
这里的c=d1/d2是可以从等式最后一行解出来的,也即 c = 1/(h31u1 + h32v1 + h33)。然后可以得到:
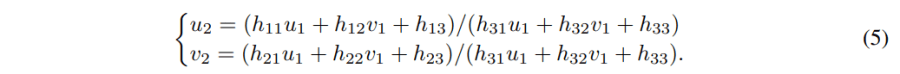
也就是说,我们可以从(u1,v1),K, R 来直接计算出 (u2, v2)。这个过程与d1无关。而无监督算法正是通过这种投影关系来约束和训练深度估计网络的,所以这种纯旋转的图像不能提供有效的梯度。而且尤其是当旋转估计不准确时,会造成错误的梯度影响训练。因此,本文认为相机运动中的旋转部分是噪音。
(c)纯平移投影:当相机运动只包含平移而没有旋转时,公式(2)就变成了:
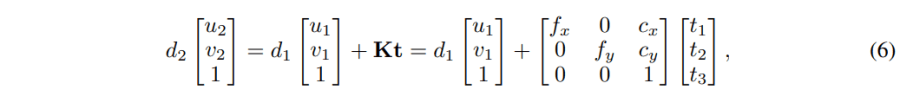
解方程,可以得到:
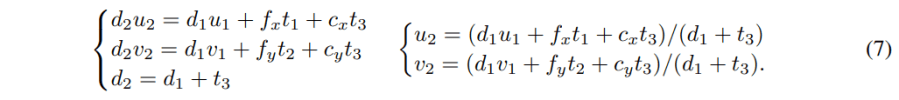
也就是说,在从(u1,v2) 到 (u2,v2) 的投影中,d1是与t相关联的。必须知道d1,才能完成投影。正是这种关系使得深度与投影有了联系,从而可以利用这种联系来训练深度估计网络。所以得到结论,平移是信号。
-
在不同数据集上相机运动的分布
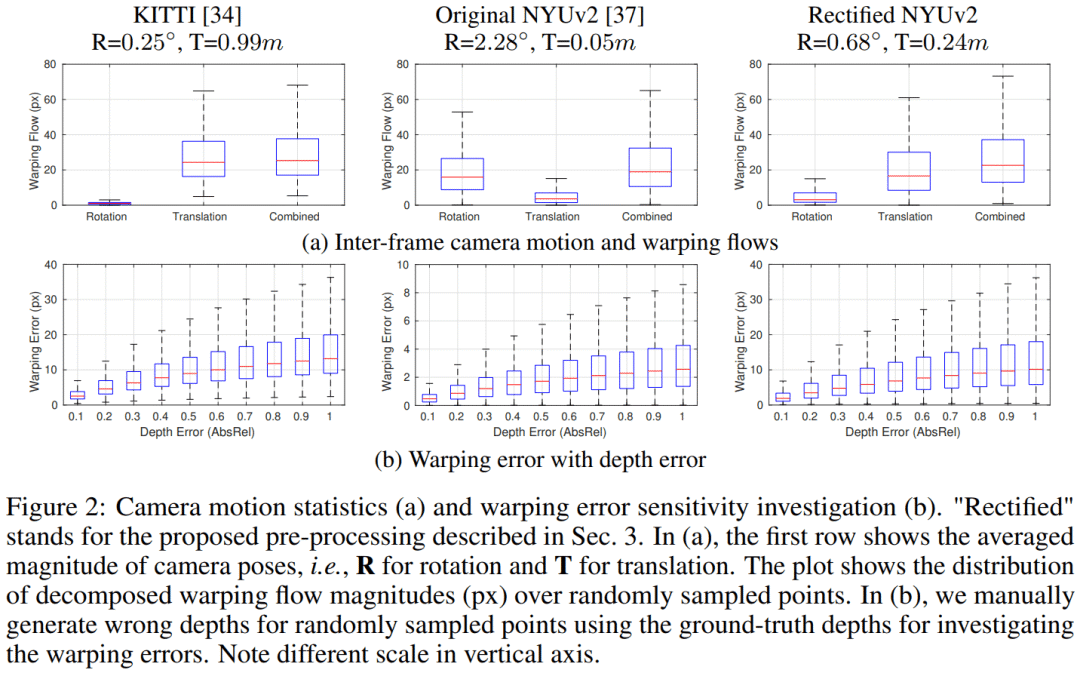
(a)对比视频前后帧相机运动的绝对大小(图2a),我们发现在NYUv2上相机的平均旋转 (R=2.28度) 远大于在KITTI上 (R=0.25度)。而在NYUv2上平均平移(T=0.05米) 远小于在KITTI上 (T=0.99米)。根据之间的结论:旋转是噪音,平移是信号。这就说明了为什么无监督算法在KITTI上运行良好,而在NYUv2上难以训练。另外,旋转和平移分别在图像平面上造成的warping flow的大小 (图2a) 也证明了相同的结论。
(b)由于投影是训练过程中的关键,我们希望投影误差 (warping error) 能够对深度误差 (depth error) 比较敏感。因此我们根据GT手动生成一些错误的depths然后分析这些错误的depths所造成的warping errors。图2b的结果反应了在NYUv2 上当AbsRel=1.0 (错了1倍,严重错误) 时, warping error ~= 3px。而在KITTI上,warping error ~= 15px。这就导致了在NYUv2上投影误差很难有效区分精确与不精确的深度估计。这是由于在NYUv2上的相机平移过小,从而深度变化只能引起较小的投影位置变化。
(c)图2中Rectified NYUv2是经过我们处理后的数据集。以上问题都得到了有效解决。接下来的章节介绍我们的数据处理方法。
四、解决方案
由上述分析可知,理想数据的特征是“无旋转+适量的平移”。因为平移太大了会导致图像差异过大,平移太小了会出现图2b所示的问题(warping error 对 depth error不敏感)。然而在NYUv2这种手持相机拍摄的视频中,相机运动主要成份是旋转。为了解决这个问题,我们提出:1、首先选择平移在合理范围内的图像对;2、通过旋转图像到同一平面来消除相对旋转。具体如下:
1.选择平移在合理范围内的图像对:首先因为NYUv2的帧率很高(30fps),我们首先下采样视频(每10帧抽一张)。接下来对每张图像我们都将其与后面的10张图像进行特征匹配来计算相对旋转和平移,这里使用的SIFT+GMS [7] + RANSAC + 5-point 算法。然后,我们可以根据得到的匹配和相机参数来计算平均的translation flow(和图2b一样,只是我们不需要GT来算,而是在得到的匹配上计算)。以KITTI上显示的结果为经验,我们保留满足“10px < translation flow <50px” 的图像对。
2.在得到的图像对上,我们已经计算出了图像之间的相对旋转R,也就是说我们只要将其旋转到同一个平面就可以得到无相对旋转的图像对。这一点和stereo rectification特别像。但区别是我们只旋转图像而不要求两张图像行对齐。这是因为双目rectification是用在左右两个相机采集的照片上,而我们的算法作用在视频上(注意:对前-后运动的图像进行行对齐会得到特别奇怪的结果)。所以这个方法命名为 weak rectification。综上,就得到了符合“小旋转+适量平移”的图像对(见图2b)。我们发现仍有残存的旋转,这是由于不够精确的匹配造成的。为了解决这一问题,在训练Pose CNN时,仍然使其输了6-D参数(3-D for rotation, 3-D for translation)。这里的旋转估计用来弥补数据预处理中的不足。在NYUv2上,原始的training sequences总共包括268K图像。我们在下采样10倍后的26.8K图像上进行上述的图像处理,总共得到67K图像对用于训练。
五、实验结果
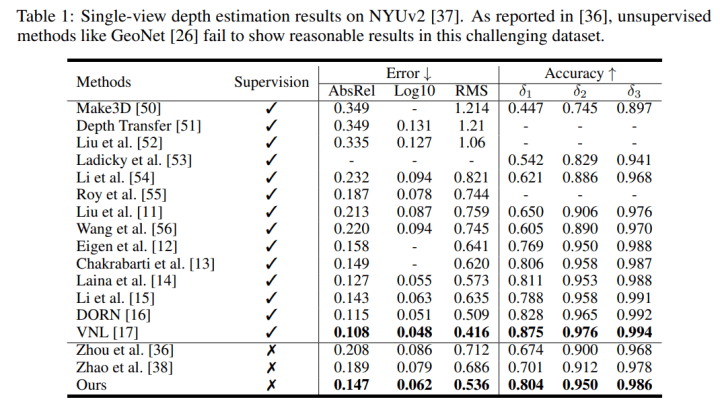
1.本文用SC-SfMLearner [4] 作为训练框架,其中Depth CNN和Pose CNN都使用ResNet18 作为encoder。在NYUv2上的结果如下, 其中 [36] 和[38] 分别是本文提到的 [5] [6]。
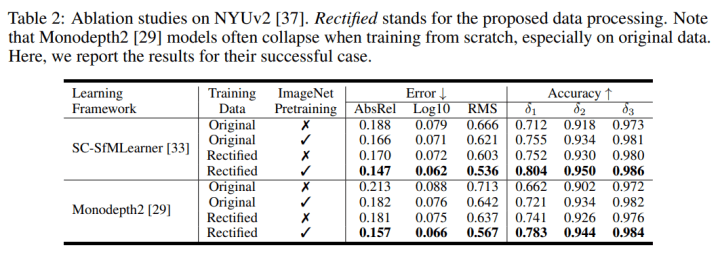
2.Ablation study 结果如下。可以看到 monodepth2 [3] 在处理后的数据上也能取得不错的结果,虽然SC-SfMLearner [4] 更好一点:
3.SC-SfMLearner在NYUv2上的训练曲线如下图所示,基中 “pt”指 ImageNet上的预训练。
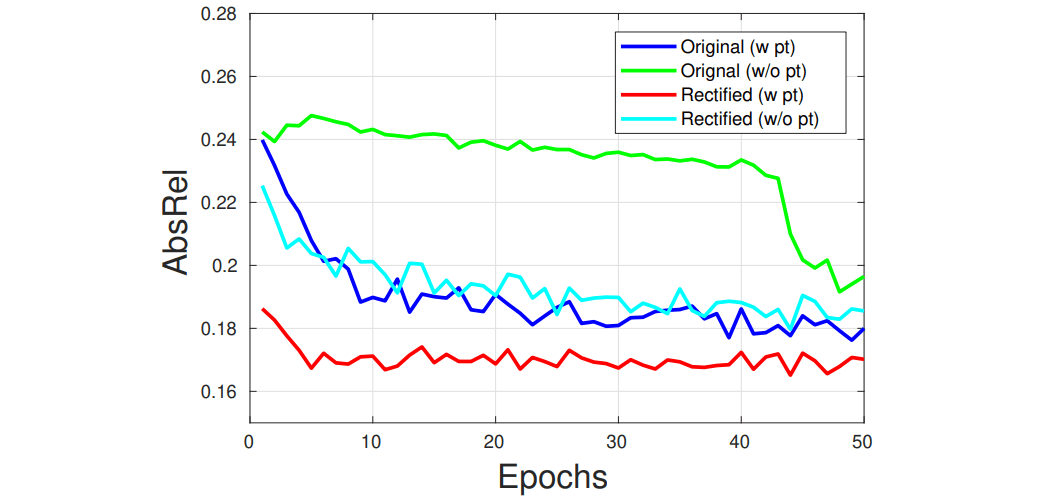
4.效率分析:在单张 V100 GPU上训练网络50 epochs总共耗时25小时(其实上图红线在5个epochs时已经收敛了)。在单张RTX 2080 GPU上进行inference,可以达到约210fps。
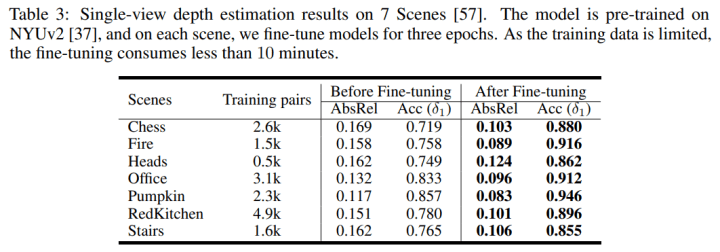
5.为了证明算法的通用性,也在7Scenes数据集上做了通用性测试和finetune (对7scenes数据集也进行了本文的预处理)。结果如下:
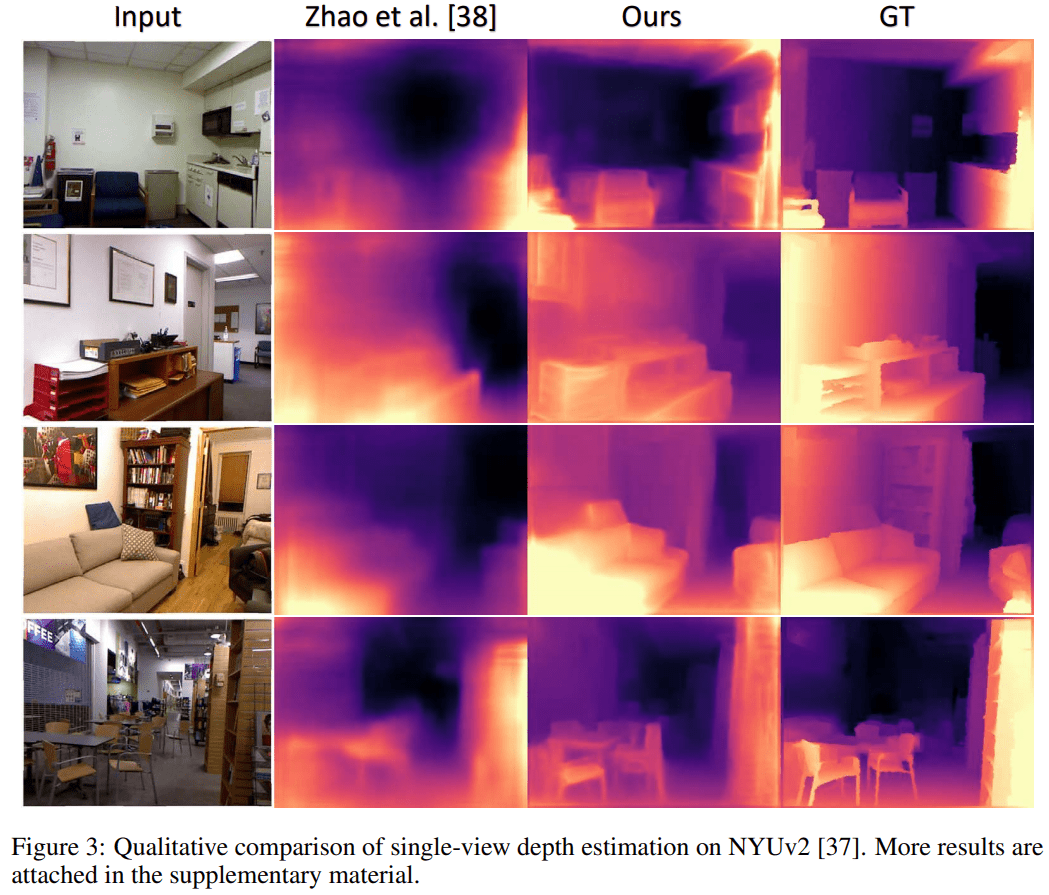
6.深度估计可视化对比结果如下 ([38]是本文中的[6]):
7.3D点云可视化结果如下:

六、 参考文献
[1] Garg et al., Unsupervised cnn for single view depth estimation: Geometry to the rescue. ECCV 2016
[2] Zhou et al., Unsupervised learning of depth and ego-motion from video. CVPR 2017
[3] Godard et al., Digging into self-supervised monocular depth prediction. ICCV 2019
[4] Bian et al., Unsupervised scale-consistent depth and ego-motion learning from monocular video. NeurIPS 2019
[5] Zhou et al., Moving indoor: Unsupervised video depth learning in challenging environments. ICCV 2019
[6] Zhao et al., Towards better generalization: Joint depth-pose learning without posenet. CVPR 2020.
[7] Bian et al., GMS: Grid-based motion statistics for fast, ultra-robust feature correspondence. IJCV 2020
[8] Yin et al., GeoNet: Unsupervised learning of dense depth, optical flow and camera pose. CVPR 2018.
推荐阅读

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~


