CVPR 2020论文开源项目一页看尽,附代码论文
十三 发自 凹非寺
量子位 报道 | 公众号 QbitAI
CVPR 2020中选论文放榜后,最新开源项目合集也来了。
本届CPVR共接收6656篇论文,中选1470篇,“中标率”只有22%,堪称十年来最难的一届。

刨去接受率低这件事,从论文本身出发,在中选论文中还是有很多值得我们去借鉴和学习的精品。
今日GitHub上便出现了一个项目,将本届CVPR论文开源项目做了个集合。
本文便基于此GitHub项目,对中选CVPR 2020论文的开源项目做了整理,主要内容如下:

目标检测
论文题目:
Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
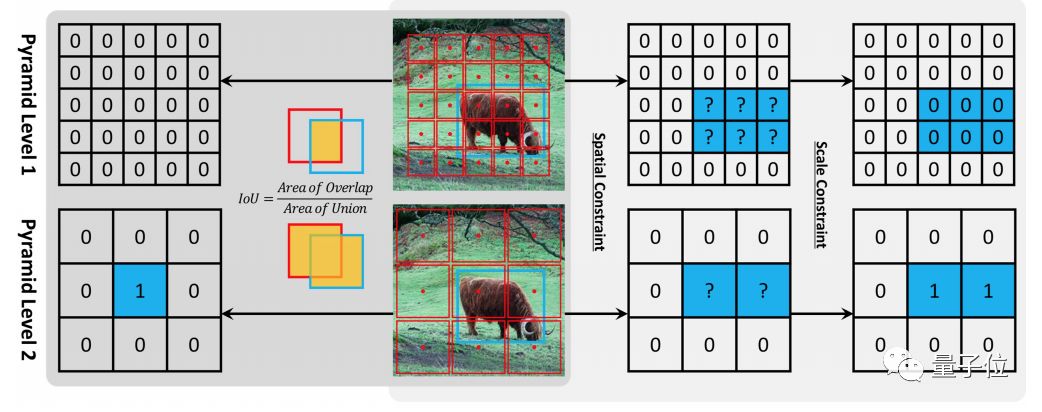
本文首先指出了基于锚点检测与无锚点检测的本质区别,在于如何定义正、负训练样本,从而导致两者之间的性能差距。
研究人员提出了一种自适应训练样本选择 (ATSS),根据对象的统计特征自动选择正样本和负样本。它显著地提高了基于锚点和无锚点探测器的性能,并弥补了两者之间的差距。
最后,还讨论了在图像上每个位置平铺多个锚点来检测目标的必要性。
论文地址:
https://arxiv.org/abs/1912.02424
代码:
https://github.com/sfzhang15/ATSS
目标跟踪
论文题目:
MAST: A Memory-Augmented Self-supervised Tracker
(注:不确定是否中选)

这篇论文提出了一种密集的视频跟踪模型 (无任何注释),在现有的基准上大大超过了之前的自监督方法(+15%),并实现了与监督方法相当的性能。
首先通过深入的实验,重新评估用于自监督训练和重建损失的传统选择。其次,通过使用一个重要的内存组件来扩展架构,从而进一步改进现有的方法。而后,对大规模半监督视频对象分割进行了基准测试,提出了一种新的度量方法:可泛化 (generalizability)。
论文地址:
https://arxiv.org/abs/2002.07793
代码:
https://github.com/zlai0/MAST
实例分割
论文题目:
PolarMask: Single Shot Instance Segmentation with Polar Representation
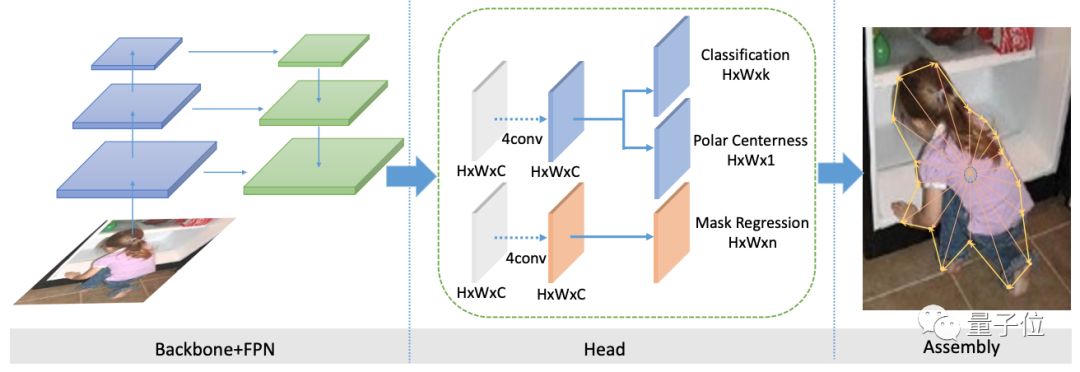
本文提出了PolarMask方法,是一种single shot的实例分割框架。PolarMask基于FCOS,把实例分割统一到了FCN的框架下。
FCOS本质上是一种FCN的dense prediction的检测框架,可以在性能上不输anchor based的目标检测方法。
贡献在于,把更复杂的实例分割问题,转化成在网络设计和计算量复杂度上和物体检测一样复杂的任务,把对实例分割的建模变得简单和高效。
论文地址:
https://arxiv.org/abs/1909.13226
代码:
https://github.com/xieenze/PolarMask
其他论文:
CenterMask : Real-Time Anchor-Free Instance Segmentation
论文地址:
https://arxiv.org/abs/1911.06667
代码:
https://github.com/youngwanLEE/CenterMask
Deep Snake for Real-Time Instance Segmentation
论文地址:
https://arxiv.org/abs/2001.01629
代码:
https://github.com/zju3dv/snake
NAS
论文题目:
CARS: Continuous Evolution for Efficient Neural Architecture Search
在本文中,研究人员开发了一种高效的连续演化方法来搜索神经网络。
在最近的迭代中,在一个超网中共享参数的种群中的架构,将在具有几个epoch的训练数据集上进行调优。下一个演化迭代中的搜索将直接继承超网和种群,加速了最优网络的生成。进一步采用非支配排序策略,仅保留Pareto前沿的结果,以精确更新超网。
经过0.4天的GPU连续搜索,可以生成多个模型大小和性能不同的神经网络。这些网络超过了基准ImageNet数据集上最先进方法产生的网络。
论文地址:
https://arxiv.org/abs/1909.04977
代码(即将开源):
https://github.com/huawei-noah/CARS
人脸表情识别
论文题目:
Suppressing Uncertainties for Large-Scale Facial Expression Recognition

本文提出了一种简单而有效的自修复网络(SCN),它能有效地抑制不确定性,防止深度网络对不确定的人脸图像进行过拟合。
具体来说,SCN从两个不同的方面抑制了不确定性:⑴在小批量上的自关注机制,通过排名规则化对每个训练样本进行加权;⑵重新贴标签机制,在排名最低的组中修改这些样本的标签。
论文地址:
https://arxiv.org/abs/2002.10392
代码(即将开源):
https://github.com/kaiwang960112/Self-Cure-Network
人体姿态估计
2D人体姿态估计
论文题目:
The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation
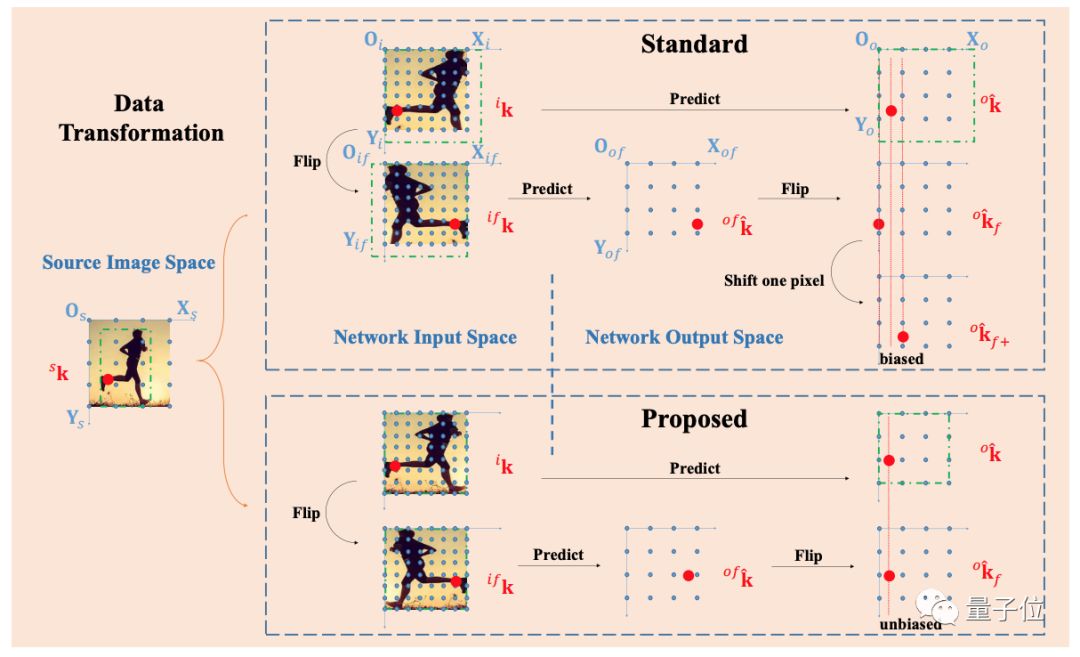
所有计算机视觉的任务都需要和数据处理打交道,但在关键点检测问题上,数据处理显得尤为重要。在关键点检测任务上,数据处理尚未被系统的学习,因此这篇文章关注了人体关键点检测问题的数据处理,认为它是算法的一个极其重要的组成部分。
在系统地分析这个问题的时候,发现现有的所有的state-of-the-art在这个环节上都会存在两个方面的问题:一个是在测试过程中,如果使用flip ensemble时,由翻转图像得到的结果和原图得到的结果并不对齐。另外一个是使用的编码解码(encoding-decoding)方法存在较大的统计误差。
这两个问题耦合在一起,产生的影响包括:估计的结果不准确、复现指标困难、有较大可能使得实验的结果结论不可靠。
论文地址:
https://arxiv.org/abs/1911.07524
代码:
https://github.com/HuangJunJie2017/UDP-Pose
其他论文:
Distribution-Aware Coordinate Representation for Human Pose Estimation
论文地址:
https://arxiv.org/abs/1910.06278
代码:
https://github.com/ilovepose/DarkPose
3D人体姿态估计
论文题目:
VIBE: Video Inference for Human Body Pose and Shape Estimation

由于缺乏用于训练的ground-truth三维运动数据,现有的基于视频的最先进的方法无法生成准确和自然的运动序列。
为了解决这个问题,本文提出了身体姿态和形状估计的视频推理(VIBE),它利用了现有的大型动作捕捉数据集(AMASS)和未配对的、in-the-wild 2D关键点注释。
关键创新是一个对抗性学习框架,它利用AMASS来区分真实的人类动作和由时间姿态、形状回归网络产生的动作。
论文地址:
https://arxiv.org/abs/1912.05656
代码:
https://github.com/mkocabas/VIBE
其他论文:
Compressed Volumetric Heatmaps for Multi-Person 3D Pose Estimation
论文地址:
暂无
代码:
https://github.com/anonymous-goat/CVPR-2020
点云
点云分类
论文题目:
PointAugment: an Auto-Augmentation Framework for Point Cloud Classification

本文提出了一种新的自动增强框架PointAugment,该框架在训练分类网络时自动优化和增强点云样本,以丰富数据多样性。
还建立了一个可学习的点增强函数,该函数具有形状上的变换和点上的位移,并根据分类器的学习过程,精心设计了损失函数来采用增广后的样本。
论文地址:
https://arxiv.org/abs/2002.10876
代码(即将开源):
https://github.com/liruihui/PointAugment/
场景文本检测/识别
论文题目:
ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network

本文提出了自适应Bezier曲线网络(ABCNet),主要贡献包括:⑴第一次通过参数化的Bezier曲线自适应地拟合任意形状的文本;⑵设计了一种新颖的BezierAlign层,用于提取具有任意形状的文本实例的精确卷积特征;⑶方法在效率和准确性上都具有优势。
论文地址:
https://arxiv.org/abs/2002.10200
代码(即将开源):
https://github.com/Yuliang-Liu/bezier_curve_text_spotting
https://github.com/aim-uofa/adet
超分辨率
视频超分辨率
论文题目:
Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time Video Super-Resolution

本文探讨了时空视频的超分辨率任务,该任务旨在从低帧率(LFR)、低分辨率(LR)视频中生成高分辨率(HR)慢动作视频。
研究人员提出了一种基于LFR、LR视频直接合成HR慢动作视频的,单级空时视频超分辨率框架。
除此之外,还提出了一种可变形凸STM来同时对齐和聚合时态信息,以更好地利用全局时态上下文。最后,利用深度重构网络对HR慢动作视频帧进行预测。
论文地址:
https://arxiv.org/abs/2002.11616
代码:
https://github.com/Mukosame/Zooming-Slow-Mo-CVPR-2020
视觉语言导航
论文题目:
Towards Learning a Generic Agent for Vision-and-Language Navigation via Pre-training
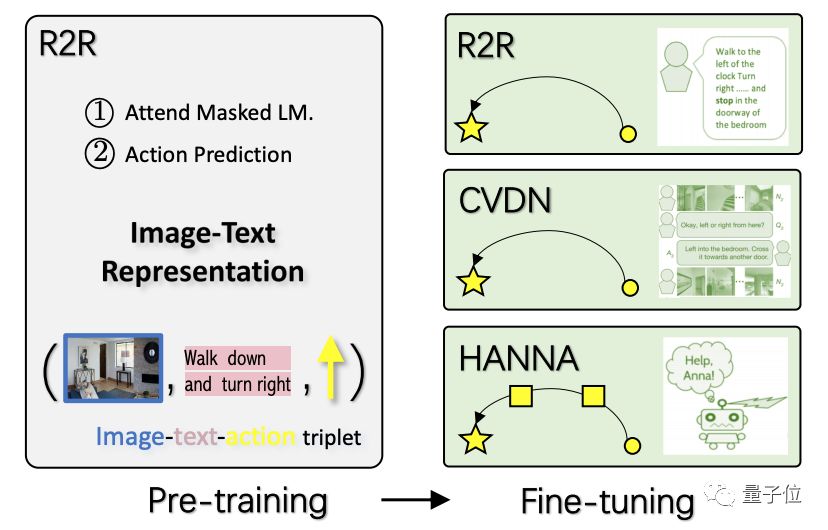
本文提出了视觉和语言导航(VLN)任务的第一个预训练和微调范例。
通过以自监督的学习方式训练大量的图像-文本-动作三元组,预训练模型提供了视觉环境和语言指令的通用表示。
论文地址:
https://arxiv.org/abs/2002.10638
代码(即将开源):
https://github.com/weituo12321/PREVALENT
其他
GhostNet: More Features from Cheap Operations
论文地址:
https://arxiv.org/abs/1911.11907
代码:
https://github.com/iamhankai/ghostnet
AdderNet: Do We Really Need Multiplications in Deep Learning?
论文地址:
https://arxiv.org/abs/1912.13200
代码:
https://github.com/huawei-noah/AdderNet
Deep Image Harmonization via Domain Verification
论文地址:
https://arxiv.org/abs/1911.13239
代码:
https://github.com/bcmi/Image_Harmonization_Datasets
其他GitHub论文项目地址:
https://github.com/charlesCXK/3D-SketchAware-SSC
https://github.com/Anonymous20192020/Anonymous_CVPR5767
https://github.com/avirambh/ScopeFlow
https://github.com/csbhr/CDVD-TSP
https://github.com/ymcidence/TBH
https://github.com/yaoyao-liu/mnemonics
https://github.com/meder411/Tangent-Images
https://github.com/KaihuaTang/Scene-Graph-Benchmark.pytorch
https://github.com/sjmoran/deep_local_parametric_filters
https://github.com/charlesCXK/3D-SketchAware-SSC
https://github.com/bermanmaxim/AOWS
最后,本项目是由公众号CVer编辑Amusi整理,同时欢迎各位大佬提交issue,分享CVPR 2020开源项目。
传送门
GitHub项目地址:
https://github.com/amusi/CVPR2020-Code
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
3月10-24日,浪潮携手一览群智、睿沿科技、海天瑞声大咖带来科技战“疫”系列直播,2周时间、5大主题,分享AI、HPC在战“疫”中的应用与实践,感受科技的力量。
满满都是干货,欢迎扫码预约观看。
AI专场系列直播 | 科技战“疫”直播进行时

直播报名 | 图像与视频处理系列
<NVIDIA图像处理公开课·第二期> 开始报名啦,下周四晚8点,英伟达专家将分享如何利用TensorRT 7.0部署高速目标检测引擎。


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !




