ICLR 2018最佳论文出炉:Adam收敛、球形CNN、元学习备受瞩目

2018年的深度学习顶级会议ICLR将于4月30日—5月3日在加拿大温哥华正式举办。自去年11月27日论文评选结束后,ICLR 2018收到了981篇有效论文,较上一届的491篇增长了99.8%。会议收录了23篇(2.3%)oral paper、314篇(32%)post paper和90篇workshop paper。而就在今天凌晨,ICLR 2018官网正式公布了今年的Best Papers,它们分别是:

关于更多会议亮点,请看ICLR 2018亮点关注:23篇口头报告。
能力所限,本文无法对论文做更深入的挖掘,如发现错误,欢迎指正!

摘要:近年来,学界提出了不少已经成功用于训练深度神经网络的随机优化算法,如RMSProp、Adam、Adadelta和Nadam等。它们都基于迄今为止所有梯度值的平方和(二阶动量)进行梯度更新。但在许多场合下,如输出上限很高的情况下,这些算法往往无法收敛到全局最优解(非凸问题的临界点)。我们的研究证实,导致这一现象的出现的原因之一是算法用的是指数移动平均值。为此我们设置了一个简单的凸优化问题,发现Adam在上面无法收敛到最优解,我们还探讨了以前关于Adam算法论文中的精确性问题。分析表明,这个收敛问题可以通过对之前所有梯度设置一个渐变的“长期记忆”来解决。我们在这基础上提出了一个Adam算法的新变体,它不仅可以修正收敛问题,还可以提高经验积累性能。
1. Adam的指数移动平均值如何导致无法收敛
我们通过提供一个简单的一维凸优化问题说明了使用指数移动平均值的RMSProp和Adam为什么无法收敛到全局最优解。它们的缺陷在于这个公式:
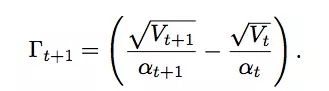
它基本表现了“自适应学习率”优化算法的学习率的倒数相对于时间的变化。 对于SGD和ADAGRAD而言,当t ∈ [T]时,Γt始终大于等于0。这是它们的基本梯度更新规则,所以它们的学习率始终是单调递减的。但是基于指数移动平均值的RMSProp和Adam却没法保证这一点,当t ∈ [T]时,它们的Γt可能大于等于0,也可能小于0。这种现象会导致学习率反复震荡,继而使模型无法收敛。我们可以来看看以下这个F = [−1, 1]的简单分段线性函数:

C > 2。在这个函数中,我们很轻松就能看出它应收敛于x = −1。但如果用Adam,它的二阶动量超参数分别是β1 = 0,β2 = 1/(1 + C2),算法会收敛在x = +1这个点。我们直观推理下:该算法每3步计算一次梯度和,如果其中两步得出的结论是x = -1,而一次得出的结论是C,那么计算指数移动平均值后,算法就会偏离正确收敛方向。因为对于给定的超参数β2,大梯度C没法控制自己带来的不良影响。
2. Adam的变体AMSGrad
我们的目标是设计一个能保证梯度收敛的新算法, 同时保留RMSProp和Adam的优势。根据上文我们可知,RMSProp和Adam算法下的Γt可能是负的,所以我们探讨了一种替代方法,通过把超参数β1、β2设置为随着t变化而变化,从而保证Γt始终是个非负数。

与Adam相比,AMSGrad的学习率更小,但只要限制Γt始终是个非负数,算法就能保证学习率是不断下降的。它们的主要区别在于后者记录的是迄今为止所有梯度值vt中的最大值,并用它来更新学习率,而Adam用的是平均值。因此当t ∈ [T]时,AMSGrad的Γt也能做到始终大于等于0。
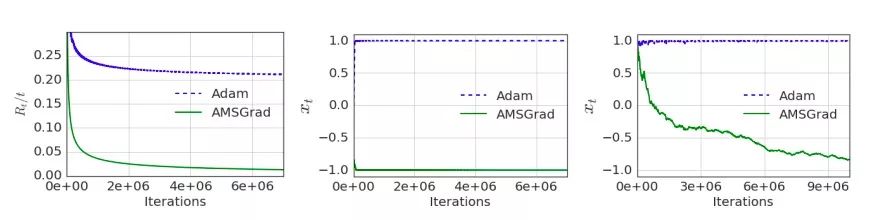
Adam和AMSGrad在一维凸优化问题上的收敛表现
更多精彩内容,请看原文:openreview.net/pdf?id=ryQu7f-RZ

摘要:卷积神经网络(CNN)是学习二维平面图像问题的首选方法。然而近期随着无人机、机器人和自动驾驶汽车全方位导航,分子回归以及全球天气、气候建模等需求的出现,构建能分析球形图像的模型正在成为一个热点课题。如果我们简单地把卷积神经网络直接用于球面信号的平面投影,它注定会失败,因为由这种投影引入的空间变化失真会使矩阵的平移分量失效。
本文介绍了一些用于球形卷积神经网络的构件块。我们提出了一个既具表达性,又符合内置的球形旋转不变性等相关定义的球形CNN,它满足广义傅立叶变换,这就允许我们用快速傅里叶变换(FFT)算法实现快速群卷积。在实验中,我们演示了将球形CNN用于三维模型识别和雾化能量回归中的计算效率、数值准确度和有效性。
什么是球形CNN
在一张普通的二维平面图像上,无论检测目标怎么移动,卷积神经网络总能轻松获得它所在的位置。但球面图像不同,虽然看起来检测目标也是在平面上移动,但它做的不是平移,而是三维旋转,这就为CNN模型检测带来了不小的困难。如下图所示,我们无法用平移卷积或群卷积处理球面信号,为了把二维做法推广到三维,我们需要用旋转来代替原来的filter变换。
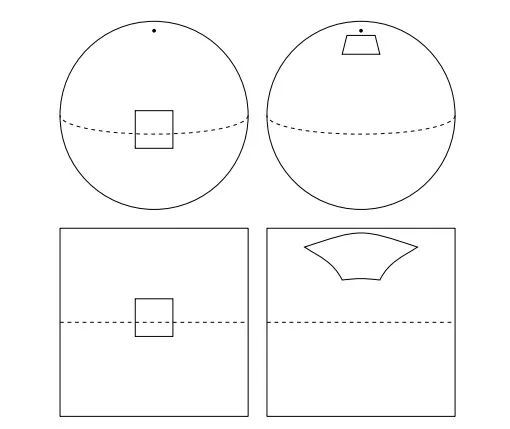
这就带来了一个非常微妙但又很重要的问题:平面的运动空间(二维平移)是和它同构的平面,但球面的运动空间(三维旋转)是三维流形SO(3)。球形CNN(S2-CNN)的难点主要有两方面。一是尽管像素的正方形网格具有离散的平移对称性,但它并不存在完全对称的网格。二是计算效率,因为SO(3)是三维流形,所以它的算法时间复杂度有O(n6)。
为了简单说明这个概念,我们通过类比经典平面Z2的相关性来解释S2和SO(3)的相关性。平面的相关性可以理解如下:
在平移x ∈ Z2时,输出特征图的值是由输入特征图与filter(变量x)的内积计算得来的。
同理,球面的相关性也可以这么理解:
在旋转R ∈ SO(3)时,输出特征图的值是由输入特征图与旋转filter(变量R)的内积计算得来的。
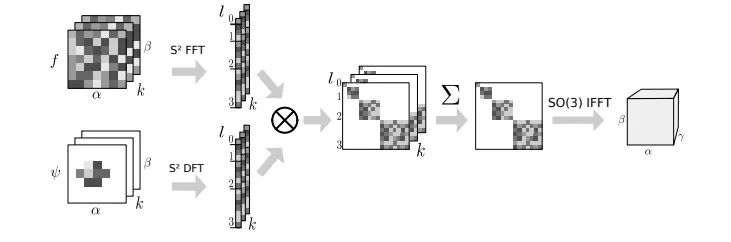
其中S2为:
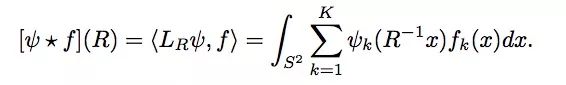
R ∈ SO(3)为:
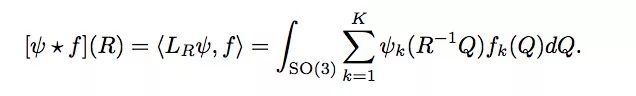
更多精彩内容,请看原文:arxiv.org/pdf/1801.10130.pdf

摘要:在非稳定和竞争环境中不断学习、不断适应是通往通用人工智慧道路上的一个重要里程碑。本文将持续适应问题转化成“学习到学习”框架,提出了一种基于梯度的元学习方法,能用于动态和竞争环境下的连续适应。此外,我们还设计了一个新的多智能体竞争环境RoboSumo。并定义了测试适应性迭代效果的游戏机制。实验证明,元学习比策略基线效果更好,用了元学习的智能体在竞争迭代中性能更佳。
1. 基于梯度的元学习方法
近来强化学习(RL)已经在多方面取得了令人印象深刻的成果,例如游戏和对话系统。但这些成果的一个共同局限是算法处理的还是稳定的环境。现实世界通常是不稳定的,由于复杂的生命周期变化、环境演进或其他竞争者的存在,这种非平衡的因素往往能打破目前已经建立的标准假设,并迫使智能体在训练和运行期间不断调整自我已取得成功。
在我们看来,一个非稳定环境可以被看作是一系列固定的任务,因此我们可以把它作为一个多任务学习问题来解决。我们需要在这些问题中纳入few-shot regime:智能体必须能依赖少数经验进行学习,并在环境变化前完成学习。这时,“学习到学习”(或元学习)的方法是最值得期待的,而我们借鉴的方法是伯克利大学的提出的基于梯度的未知模型元学习法(MAML)。
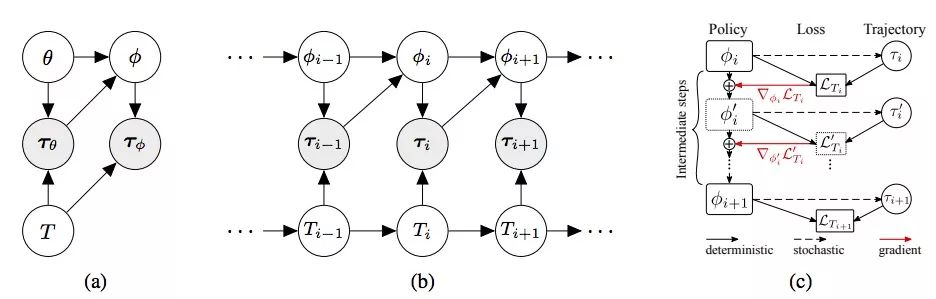
上图(a)是一个常规的多任务强化学习MAML概率模型,其中任务T、策略π和轨迹τ都是以图中依赖关系联系起来的随机变量。图(b)是我们为适应动态环境对该模型所做的扩展,可以发现,智能体上一步的策略和轨迹被用于为当前步骤构建新策略。图(c)则是从 φi到φi+1时meta-update的计算图,其中方框表示具有指定参数的策略图的副本,从LTi+1开始,模型通过截断反向传播进行优化。

(计算略)。简而言之,基于梯度的元学习方法的主要思路是通过调整任务Ti的策略πt,使任务Ti+1获得一个优秀的新策略πt+1。它把Ti和任务Ti+1的关系建模成马尔可夫链,然后改变MAML模型中loss的定义用Ti调出策略πφ,已获得更好的效果。
2. 多智能体竞争环境RoboSumo
我们的多智能体环境RoboSumo允许参与者按照标准相扑规则以1对1的方式进行竞争。智能体有三种类型:Ant、Bug和Spider。它们具有不同的物理结构。在比赛期间,每个智能体都会观察自己和对手的位置、自己关节的角度、相应的速度以及施加在自己身体上的力(相当于触觉)。它们的动作是连续的。
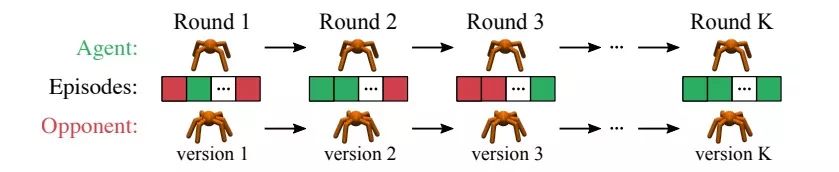
如上图所示,RoboSumo的一轮游戏包含多个episode,智能体在游戏中和竞争对手比赛,如果它在大多数episode中获胜了,则判定为胜一轮(以颜色标记)。随着episode更迭,智能体和其对手都能通过改进策略来提高表现。
更多精彩内容,请看原文:arxiv.org/pdf/1710.03641.pdf
参考文献
[1] On the convergence of Adam and Beyond By Sashank J. Reddi, Satyen Kale, Sanjiv Kumar
[2] Adam那么棒,为什么还对SGD念念不忘 By Juliuszh
[3] 深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam) By ycszen
[4] Spherical CNNs By Taco S. Cohen, Mario Geiger, Jonas Köhler, Max Welling
[5] Continuous Adaptation via Meta-Learning in Nonstationary and Competitive Environments By Maruan Al-Shedivat, Trapit Bansal, Yura Burda, Ilya Sutskever, Igor Mordatch, Pieter Abbeel
[6] 论文笔记 Continuous Adaptation via Meta-Learning in Nonstationary and Competitive Environments By 王小惟





