IJCAI2020论文:上下文在神经机器翻译中的充分利用
来自:南大NLP

01
—
研究动机
目前,主流的神经机器翻译模型(Neural Machine Translation, NMT)通常是句子级别的,往往以单个句子为单位进行翻译。但是在实际情况下,我们往往希望机器翻译能连贯地翻译整个篇章文本,而句子级别的模型显然没办法去考虑篇章中句子之间的依赖关系和贯穿全局的上下文信息。例如,一篇文章的主题往往不能被句子级别的模型所建模,从而导致不连贯的篇章翻译结果。所以,我们希望能有这样一个模型,它不仅能做好单个句子的翻译,也能直接搞定整个篇章。
于是,context-aware NMT模型应运而生。
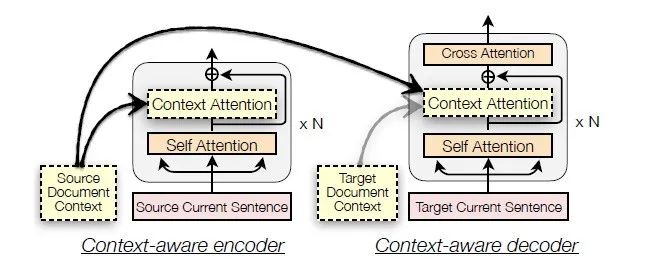
如上图所示, context-aware 模型的 Encoder 会将源端的全局上下文信息(global context)深度融合进入当前句子的局部上下文(local context)的每一层编码;同样地,它的 Decoder 的每一层也会类似的融合全局上下文和当前句子局部上下文信息的模块。因此,context-aware 模型在翻译某一个句子时所使用的当前句子表示,深度融合了全局和局部上下文信息,从而可以生成上下文连贯的译文。
我们知道篇章中肯定有不少有用的信息,这也是为什么要做篇章翻译的原因。然而,其中和当前句子不太相关的信息占比更大,这就带来了噪声。并且,输入的上下文越多,信噪比也就越小。因此,context-aware 模型这种将上下文信息深度融合进当前句子的表示的建模方式会使得模型对篇章上下文中的噪声非常敏感,这就导致了这类模型不能有效地避免上下文中噪音的影响,减小了对有用的篇章信息的有效利用。这可以解释在之前的工作中发现的现象,即对于 context-aware 模型,只有当前句子周围 2 到 3 句上下文对翻译比较有用,而更多上下文乃至整篇文档会使译文质量下降。
同时,我们发现,这类模型的输入除了当前源端句子外,还必须包括上下文句子,这就导致这类模型反而不能直接翻译单个句子,因为只输入单个句子和它们的输入要求不符合,强行翻译会导致比较差的效果。一方面,这导致实际部署模型的时候可能需要分别部署一个句子级别和一个篇章级别的模型,代价太大;另一方面,一个能翻译篇章的模型不能够很好地翻译单个句子也与直觉相违背。
自然而然地,本文的研究动机是:我们想要一个统一的模型,它能够尽可能地利用篇章上下文信息,也能够处理任意长的文本,不管该文本是一个句子还是由多个句子组成。
02
—
解决方案
为了解决上述问题,本文提出了一个通用目的的神经机器翻译模型。
我们核心想法是,我们应该尽量避免直接让上下文信息与当前句子进行深度融合,而应该让模型更好地以一种层次化的方式来平衡对篇章中每个句子局部上下文和全局上下文信息的利用。
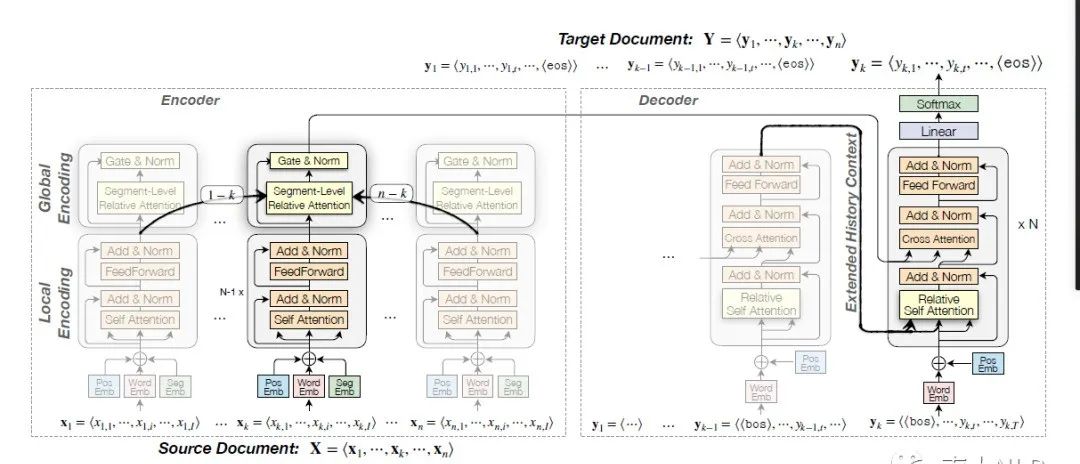
形式化上来讲,我们的模型的输入是一个文本 X,它包含 n 个句子。在编码阶段,1)模型的 Encoder 部分会先独立地对各个句子做局部编码(local encoding),得到每个句子的局部上下文信息(local context)。这一步骤和原本的句子级别 Transformer 模型一样,用来保证每个句子的编码不提前被上下文信息中的噪声影响。2)当我们得到每一个句子的局部上下文编码后,我们的模型会对篇章中这些句子进行全局编码(global encoding),建模句子与句子之间的相对关系,得到当前句子有用的全局上下文信息(global context)。3)最后Encoder通过一个门控机制把当前句子的局部上下文表示和 全局上下文表示动态地、有的放矢地结合起来
在解码阶段,我们的模型逐句进行解码。1)在解码到第 k 个句子的时候,我们将之前已经解码出来的历史句子缓存下来作为目标端的全局上下文信息。2)其次,我们允许Decoder 的 self-attention 模块除了能访问当前句子外,还能够额外访问到这些历史信息,获得有用的目标端上下文信息。3)在接下来的 cross-attention 模块中,只对源端中对应的第 k 个句子的编码结果表示做 cross-attention,获得与当前句子相关的源端上下文信息。4)最后基于上述这些信息做出预测。
可以看到,我们通过一种层次化的方式,剥离对局部上下文和全局上下文的处理,延后了它们的融合,从而减少上下文中噪声对建模的影响,最终让模型能得到更好的的句子表示和篇章表示;另外,当输入只有一个句子时,Encoder 的全局编码部分相当于自动退化成了局部编码,使得我们的模型能够不依赖额外的上下文也能完成对单个句子的翻译。
模型细节上,Encoder 主要是顺序地进行着几个功能:词和位置编码、句子局部上下文信息编码(local encoding)、篇章全局上下文信息编码(global encoding)。其中,对于篇章全部上下文信息编码部分,我们提出了基于块级别的相对注意力机制(Segment-level Relative Attention)。Decoder 则是借鉴了Transformer-XL 的缓存机制,可以存储前一个句子的隐层表示作为历史信息,并允许 Decoder 的 self-attention 模块可以同时访问当前句子和缓存中的表示信息。
03
—
实验
我们在中英和英德两个语言对上的四个常用的篇章翻译评测数据集上做了实验。其中,我们在中英上使用了容量较小的模型,而在英德上使用了 Transformer-base。在训练的时候,为了提高效率,我们将篇章以 20 个句子为单位进行切分,将得到的20 句为一组的段落作为处理的单位。另外,我们没有使用大规模句子级别的双语数据进行预训练。
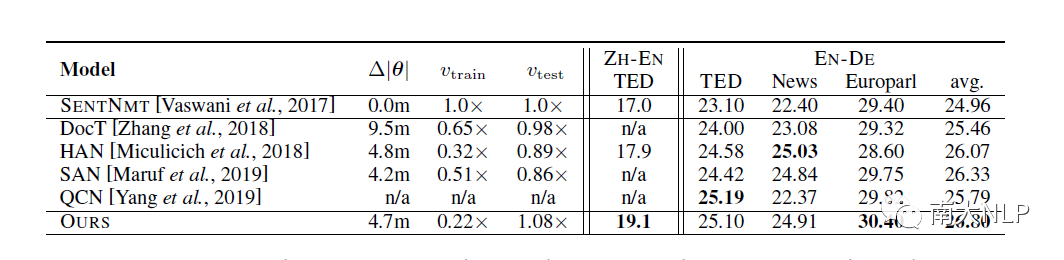
从下表中,我们可以看到,在篇章翻译上,我们在两个数据集上得到了当前最好的性能,在另外两个没有取得最好性能的数据集上,我们的模型也与当前最好的模型有非常接近的性能。
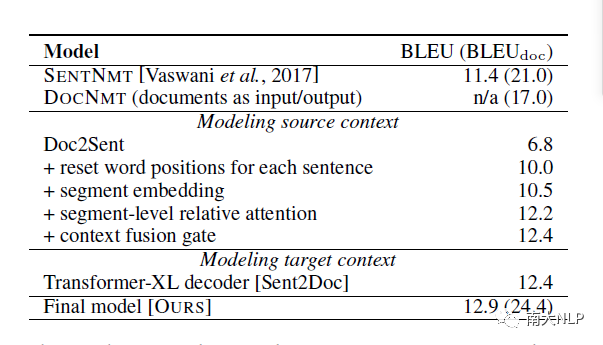
从下表中,我们还可以看到,我们的模型同样可以高质量地处理单个句子文本的翻译,而之前的方法在这种场景中表现不够令人满意。

我们在下表中列举了ablation study。我们发现,源端和目标端的上下文信息都对篇章翻译有所帮助,与此同时,我们添加的模块都对性能的提高有相应的贡献。
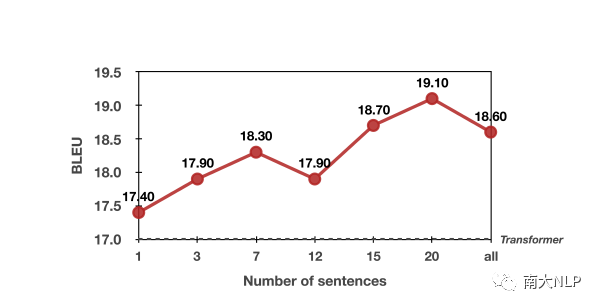
我们在下图中展示了翻译效果与输入篇章长度的关系。我们首次发现,整体上,使用的上下文越多,我们的模型翻译效果就越好。该发现与之前的相关工作中认为上下文越多会对性能产生负面影响的结论有一定冲突。我们认为,上下文越多,翻译效果越好显然是更符合我们直觉的。我们认为这样的效果与我们在建模时避免局部和全局上下文信息的深度融合,转而使用层次化的建模有关,我们的方案有效地避免了无关噪声对机器翻译建模的影响。
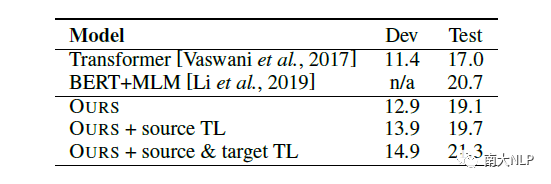
在下表中,我们尝试使用大规模的句子级别双语语料进行预训练,然后在篇章级别语料上进行迁移学习。我们发现,大规模句子级别语料预训练对翻译效果有很大的提升,使我们的模型再这个数据集上得到了当前最好的性能。我们认为,句子级别预训练有很大帮助,这同时也说明了篇章级别翻译仍然缺少足够的语料。
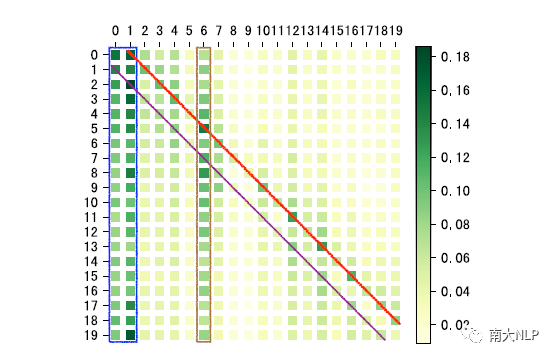
为了研究我们的模型学习到了怎样的建模上下文的能力,在下图中,我们利用 Encoder 中全局上下文编码部分的 attention 权重,可视化得到了句子对句子之间的依赖关系。我们有如下有趣的发现:
左边的蓝色框说明,所有句子都“认为”该篇章的前两句很重要,我们认为这是因为文档中开头的句子往往奠定了该文章的主题信息
两条对角线权重较高,说明当前句子周围相邻前一个和后一个句子很重要
主对角线权重很低低,说明全局编码自动学到了每个句子应该更加关注其他句子而不是自己
第 6 个句子看起来很重要,这是因为这个句子中包含了该文本中的关键内容
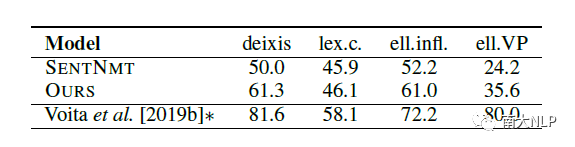
在下表中,我们还考察了我们模型对篇章一致性及连贯性的建模。我们发现,我们的模型确实在一定程度上提高了译文的篇章一致性。
04
—
总结
在本文中,我们提出了一个统一的模型,可以处理任意长的文本,同时也尽可能地利用好篇章上下文信息。我们发现,提供给我们的模型的上下文越多,翻译效果越好。我们认为,要达到高质量的篇章翻译效果,我们需要特别注意长篇章中的无用噪声,避免无用信息影响到神经机器翻译模型表示的建模。
作者:郑在翔
编辑:刘莉,何亮

由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记




