![]()
本文由西湖大学李子青教授完整修订
10 月 17 日至 19 日,由 CCF 主办、苏州工业园区管委会、苏州大学承办的 CNCC 2019 在苏州成功举办。
西湖大学讲席教授、IEEE Fellow 李子青作为该技术论坛的开场演讲嘉宾,带来了主题为《
人脸识别挑战问题和解决技术
》的演讲,他主要从人脸识别当前所存在的大数量类别的模式识别问题、人脸防伪问题以及复杂光照问题三个未来需要重点关注的挑战出发,阐述了应对这三个问题的解决方案。
![]()
李子青(Stan Z. Li),IEEE Fellow,曾任微软亚洲研究院Research Lead,中科院自动化所模式识别国家重点实验室资深研究员。2019年加盟西湖大学工学院,开展人工智能创新研究,研究方向包括:机器学习/深度学习、数据科学、AI+交叉学科(如计算机视觉、生物医学、材料科学、环境科学、传感器技术等)。
以下为李子青演讲全文,AI 科技评论进行了不改变原意的编辑,李子青教授进行整体修改和确认。
计算机视觉是人工智能技术中应用最成功的一个方向,其中人脸识别和视频分析在落地上又是最成功的。
我首次参加的人脸识别会议是 1997 年的第二届 FG(IEEE International Conference on Automatic Face and Gesture Recognition),这个会议由 Thomas Huang(黄煦涛)发起,一直存在至今。当时我在新加坡南洋理工,是我的学生把我带上了人脸识别的研究之路,而现在我的学生不做了,而我一做,就是 20 多年。
过去人脸识别采用非深度学习的传统方法。昨天在 CNCC 的晚宴上,有一个来自 Oulu 大学的博士毕业生说起 LBP,当时我审了这篇投稿,并大力推荐到了 CVPR。另外我也审到那个著名的 AdaBoost 人脸检测的投稿并做了推荐,它是第一个能把人脸检测在 PC 上做到实时的算法。我觉得这种方法非常好,并基于这个算法在 MSRA 开发了世界上第一个实时的人脸识别系统。那个系统采用的是传统的人脸识别算法。
2013、2014 年开始,深度学习开始在人脸识别得到应用,受人工智能技术的产业驱动,人脸识别技术也取得了突飞猛进的发展。现在的人脸识别技术指标比当年提高了好几个数量级,在中国已经广泛应用。虽然如此,现在人脸识别仍然存在一些技术挑战问题,这也是我今天要分享的主题。
本次分享,我可能无法将所有的挑战和问题都涵盖到,而主要讲三个无论从算法层面还是应用层面都需要进一步解决的挑战问题:
第一,巨量类别的模式识别问题。
人脸识别、辨别现在的应用可能达到成百万、千万级别了,涉及到对这么多数量的类别的模式识别,必然存在一些问题。例如中国一个省或者一个中等城市,人口就几百万甚至几千万,其中就涉及到多数量的类别的模式识别问题,那这该如何解决呢?
第二,人脸防伪问题。
现在在人脸识别如刷脸支付等场景中常面临照片攻击问题,包括支付宝等应用当年也曾被破解过,因而他们也对此做了很多的努力。
第三,复杂光照问题。
2005 年前后我一直在寻求光照问题解决方案,这是由于当年基于可见光图像的识别算法水平比较低,基本上无法达到应用要求。我尝试使用前端近红外成像光电硬件+算法软件一体化的方法,比较好地实现了配合和半配合(比如刷脸认证、闸机通道的身份识别)条件下的人脸识别技术要求并实现了产品化。
![]()
1、巨量类别的模式识别:夹角分类器和 Margin
常用的欧式距离分类,可以用一个魔方的小方格块来描述,把每个人脸特征装进魔方中的一个小块中,这样的分布下,欧式距离基本上无法对这些类别进行有效的分类,更不用说密密麻麻地排列几万甚至几十万个类别。而从数据分析的角度来看,高维空间的数据分布跟这种魔方中小方块的分布是不一样的。在高维空间的均匀随机分布,大部分数据样本都在魔方的角上,也就是说不同类别的数据之间是正交的关系,并且可以证明随机样本间相对欧式距离趋于零。所以在高维空间,在类别数量非常多的情况下,如果采用欧式距离度量方法,识别性能必然得不到保障。
![]()
在高维空间采用样本间的夹角作为距离度量能够取得比较好的结果,所以现在用的方法大都基于 Angular Similarity。
我们把样本映射到一个高维球面的分布,不同类的样本是角度可分而距离不可分的。几十万个类,每个都在在球面上占据一小块,利用夹角进行分类。在深度学习以前就已经有研究者研究和应用 Angular Similarity,而在 2016 年、2017 年,尤其是 2018 年和今年,这种按角度进行分类的人脸识别研究论文发表比较多,例如今年 CVPR 2019 大概就有六七篇论文就是研究这个问题的。
第一个特点是 Angular Loss,即在训练神经网络的时候,采用按角度划分类的方法。
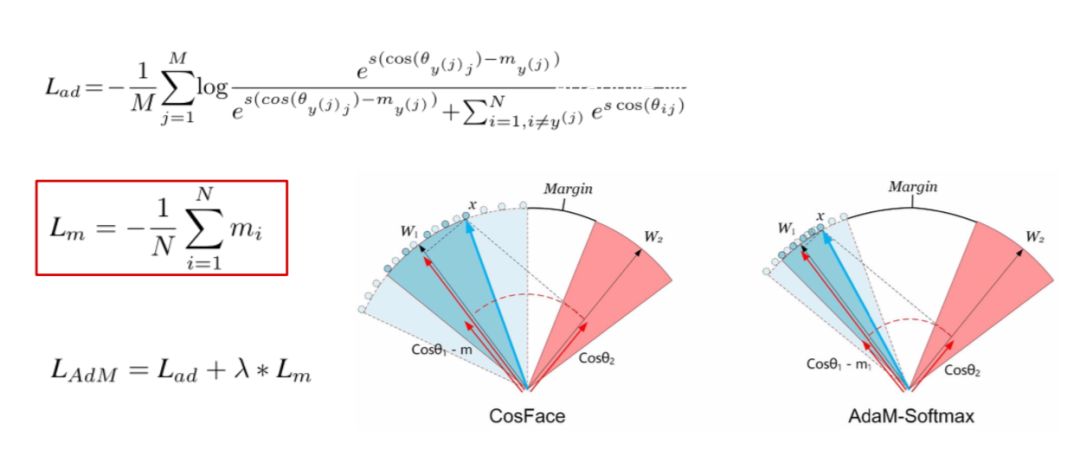
第二个特点是在夹角损失函数中引入了 Margin,即相邻两类的分界面并不是一个简单的夹角分界面,而是两个夹角分界面,其间留有一定的裕量,这样在测试或使用阶段才能更好地分类。
第三个特点是 Imbalanced Data,比如说在下图中,一个人最多有几千张图,最少的只有三、五张图,并且大部分的类别数量都非常少,针对这样的长尾分布问题,我的学生提出了一个方法——AdaM-Softmax,即边际随着每类的样本数量进行自适应变化,相关的论文《AdaptiveFace: Adaptive Margin and Sampling for Face Recognition》也在今年 CVPR2019 上发表。
![]()
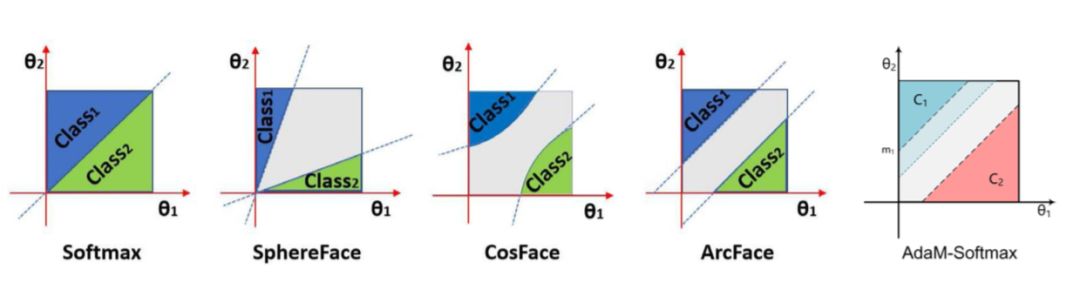
下面这个图比较几种方法的 Angular Loss 方案:Softmax 方法 中的第一类和第二类之间就是一根直线;SphereFace 按角度来分类;CosFace 是球面的,并且各类之间有一个cosine 裕量;ArcFace 则留有夹角裕量,该方法的应用效果在论文上看似乎是最好的,比前面几个好一丁点。ArcFace 开源了代码,现在很多公司和院校都在使用。
![]()
AdaM-Softmax 与前述引入 Margin 裕量方式不同,AdaM-Softmax 中每类都有不同的边界值,而非采用固定值。实现的方法是引入了一个 Margin 相关的 Loss,乘以权重 Symbol 后加入到总体 Loss。这样训练出来的网络,在处理数据不平衡条件下,表现更好。
![]()
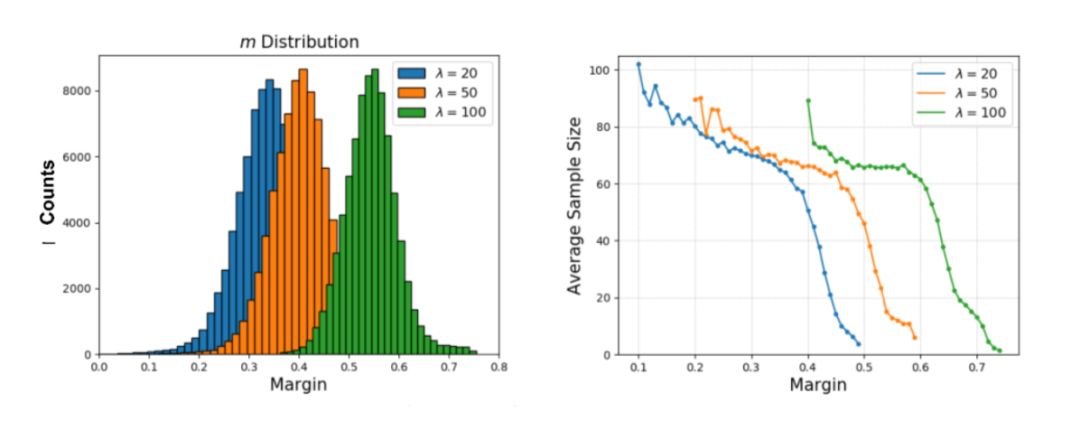
在上图(右侧)中,纵轴表示类别分别有 20、40、60、80 以及 100 个样本,横轴表示相应的 Margin。我们可以看出,每类的样本数量越 多,它的边际值就越小,我认为这个趋势是合理的,实际上达到了预期的效果。
![]()
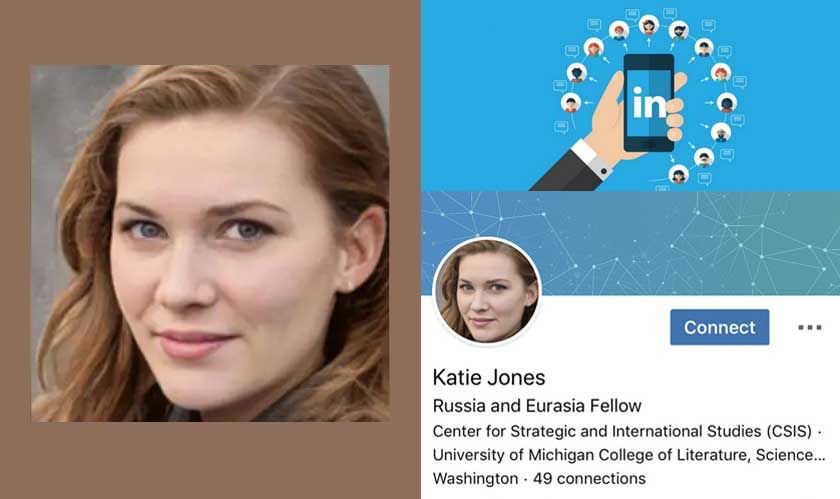
人脸防伪的需求主要存在于身份认证等场景,举两个实际发生的例子,第一个案例:几年前有一名中国福建籍的男子化妆成一位老人通过了加拿大的海关,但是之后有人发现他脸上皱纹巴巴的,而手却细皮嫩的,后来被查出。第二个案例:今年 6 月份的时候,下图右侧这个人被曝出身份造假,并且与美国政府高官勾搭上了,最后被查出来这张脸是生成的。但是我们用肉眼来看,她的脸非常逼真。
与机器人脸识别相关的采用伪造人脸攻击成功的案例当属当年支付宝被人用照片打印和手机屏幕显示攻击破解,其后支付宝做了很多技术防范措施,现在攻击比较难了,但目前仍然未能达到预期的技术防范强度。
人脸防伪主要有打印、屏幕显示/视频重放以及人脸面具三个类别,防伪的方法则是对不同类型提取不同的特征。而传统方法主要对纹理、三维形状等提取特征从而区分真人和假体,其中硅胶是最难 以辨别出来的类别。这是因为本质上,我们需要判别的是「人脸」的皮肤是肉体还是假体,然而硅胶材质从成像上来看与人脸的皮肤很相近,因此在一般情况下很难区分出来。
现在基本上采用深度学习算法模型解决人脸防伪。2014 年,我们将深度学习引入到了人脸防伪中,采用一个简单粗暴的方法——采用正样本 和负样本训练真假人脸分类器。还有一种方法是利用人机应答的方式,看看「人脸」是否能做眨眼、摇头等动作。此外还有利用三维结构来判断人脸图像是平面还是立体。我们在 2011 年提出了多光谱(可见光、近红外)成像和鉴别的防伪方案,这也是当前最普遍采用的方案。
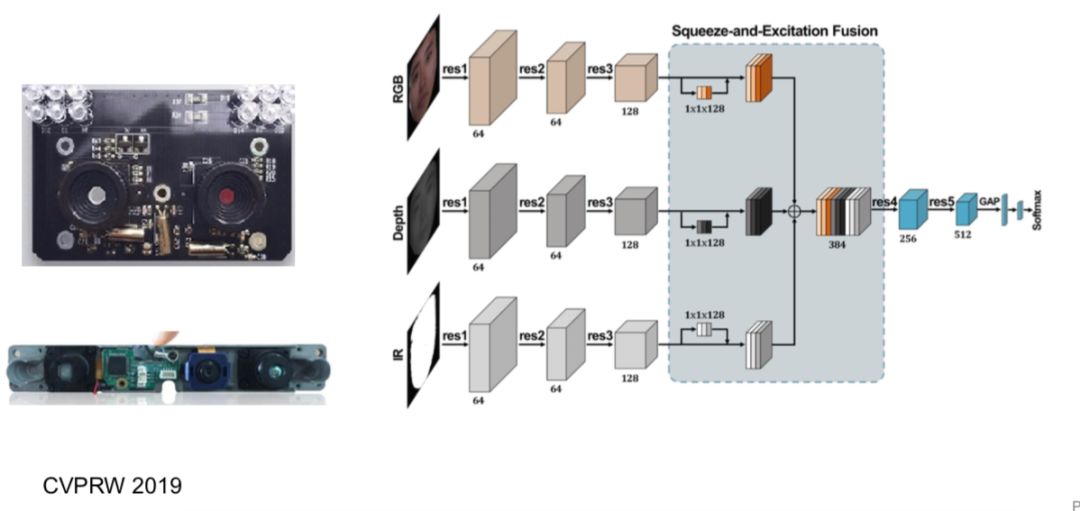
下图是我们在 CVPR 2019 的人脸防伪竞赛上给出的一个 Baseline 方案,将 RGB 、NIR和3D深度图像信息进行了融合:
![]()
CVPR 2019 人脸防伪竞赛相关内容可参考:http://openaccess.thecvf.com/content_CVPRW_2019/html/CFS/Liu_Multi-Modal_Face_Anti-Spoofing_Attack_Detection_Challenge_at_CVPR2019_CVPRW_2019_paper.html
另外,多年前我在一个会议上也看到了一个非常有意思的工作,这项工作用到了一位 MIT 的硕士提出来的方法:用可见光对着人脸拍摄,会检测到人脸皮下的毛细血管按照心率节奏在跳动。
我当时就想到这个方法可以用到人脸防伪上,但是我尝试后发现实际是不可行的——就算你对着一张白纸拍摄,也能检测到心率节奏的跳动,这是因为该方法采用的是傅立叶变换,总能检测到周期性的,比如灯光下的 50Hz,总会有一些微小的东西将幅度最大的频率分量提取出来。后来看到有一些相关的论文发表,我估计实验结果应该离实用还有段距离,但我觉得这个思路不错,如果要把它做成实用,只从算法上解决是不够的,必须在前端光电硬件上有所创新,才能解决其中的关键问题。
![]()
现在的人脸识别算法在受控良好光线环境中的识别效果已经很好了,但在工地、地铁入口等光线不受控的场景中仍然无法正常使用,包括计算机视觉领域的独角兽公司提出的算法都还无法解决这个问题,这是因为采集的图像就已经难以恢复成正常光照被正常识别了。在这种情况下,还需要从前端的光电硬件上想办法,从图像获取阶段去解决这个挑战问题。而采用近红外主动光源照射成像,是一个解决方案。
采用近红外成像的方案,就需要解决异质图像人脸识别问题。该方案能够比较好地解决光照问题,2005年开始就在深圳罗湖海关得到实际使用了。不过,当时相关单位也给我提出了一个问题:虽然效果不错,但是存在限制,就是必须要使用近红外人脸图像进行注册,那如果只有身份证照片注册呢,该怎么解决这个问题?为此我提出了异质人脸识别的方法。有两个方案:
第一个思路是将近红外的图像转化为可见光的图像,然后用可见光人脸算法做匹配;
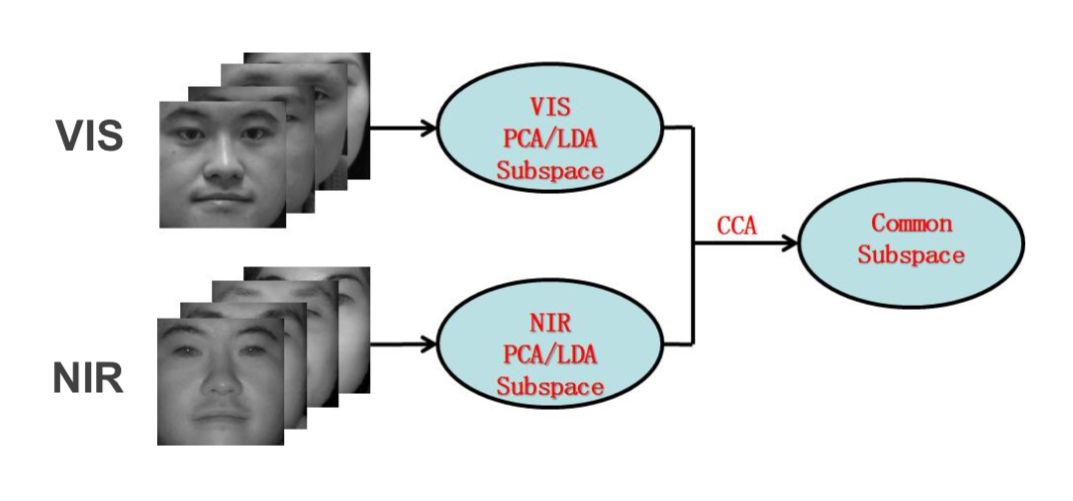
另一个思路是,从近红外和可见光两种不同的图像中学习共同特征。例如在2007年,我们的团队也提出了一种采用 CCA 提取共同特征的的方法。
![]()
参考:Dong Yi,Rong Liu,RuFeng Chu,Zhen Lei,Stan Z. Li, "Face Matching Between Near Infrared and Visible Light Images" ICB-2007
论文地址:
https://link.springer.com/content/pdf/10.1007%2F978-3-540-74549-5_55.pdf
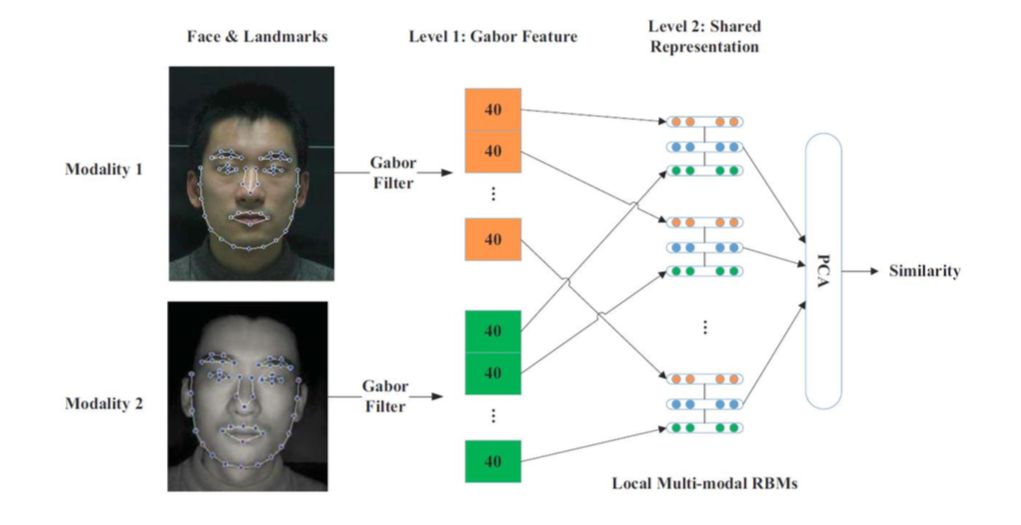
除此之外,提取不同图像共同特征的方法还有:对两类图像的各个局部特征进行处理、滤波,从而提取出一些共同特征;用传统的方法提取特征后,再用深度网络进行不同图像的特征变化(如下图)。这种方法很容易实现端到端的训练。
![]()
Dong Yi, Zhen Lei, Stan Z. Li. Shared Representation Learning for Heterogeneous Face Recognition, In FG 2015.
现在最新的方法是采用深度学习技术,通过深度网络的非线性映射,提取出可见光、近红外图像的人脸隐空间表示,以隐变量的均值来表示每一个人脸的内在 ID ,以分布方差表示外部影响如光照、姿态等。近红外、可见光人脸的两个隐空间中隐变量分布之间的差异,可以通过概率和拓扑映射的方法来弥补,最终实现全光照条件下可靠的人脸识别。
![]()
![]() 点击“阅读原文”查看更多顶会报道
点击“阅读原文”查看更多顶会报道