机器学习真实案例研究:基于文本描述的交易聚类

翻译:方星轩
校对:欧阳锦
本文约2200字,建议阅读5分钟。
本文为大家介绍了在日常的电子交易中对用户的交易信息进行聚类分析和建模,提供了用户分析的思路和建议。
标签:聚类 机器学习


在本文中,我们将讨论一个金融机构的实际使用案例,该案例使用-聚类clustering(一种流行的机器学习算法)来为其客户群定制其产品。

“A partial solution to the above problem can be addressed by using in-house transaction data available with the institution”
确定主题数量
Topic Modelling
https://www.analyticsvidhya.com/blog/2018/10/stepwise-guide-topic-modeling-latent-semantic-analysis/

主题连贯
Topic Coherence
https://rare-technologies.com/what-is-topic-coherence/
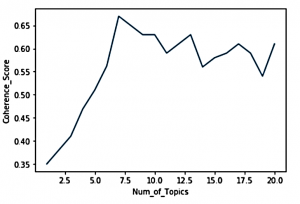
我们已经确定了主题/群集的总数(在我们的案例中为7个主题)。我们应该开始将每个交易描述消息分配给主题。在将文档分配给主题时,仅依靠主题建模可能无法产生准确的结果。
在这里,我们使用主题建模的输出以及其他一些功能,使用 K-Means clustering对交易描述消息进行聚类,我们将主要为K-Means集群构建功能集。
K-Means clustering
https://www.analyticsvidhya.com/blog/2019/08/comprehensive-guide-k-means-clustering/
基本特征
- 字数,位数,特殊符号数
- 最长数字序列长度,数字-字符比
- 平均,最长字长等
- 交易的周,日和月,当前日期,周末交易等
- 每月最后5天或每月前5天执行的交易
- 公众假期和节日交易等
查找功能–使用行业中的顶级品牌和常用名词作为查找名称。计算与特定行业相关的交易描述中的单词数。
- 食品:蔬菜,多米诺骨牌Dominos(披萨品牌),FreshDirect(美国的在线食品杂货商),赛百味等
- 体育:棒球,阿迪达斯,足球,防滑钉等
- 卫生:药房,医院,体育馆等
- Bill&EMI:政策,能源,声明,时间表,取款,电话等。
- 娱乐:Netflix,Prime节目,Spotify,Soundcloud,酒吧
- 电子商务:亚马逊,沃尔玛,eBay,Ticketmaster等
其他:Uber,Airbus,打包机等
对使用TF-IDF方法生成的DTM矩阵的一元模型和二元模型执行主题建模。对于每个主题的交易描述的unigram一元模型和bigram 二元模型DTM矩阵,我们使其获得2组7种的不同概率。
每个交易描述大约有30个功能,我们执行K-Means聚类将每个交易描述分配给7个集群之一。
结果表明,聚类中心附近的观测结果大多标有正确的主题。少量错误的主题标签被分配在距离聚类中心较远的观察点。在手动查看的350个交易描述中,大约240个(准确率为69%)交易描述已正确标记了适当的主题。
现在,我们至少可以对内部客户的偏好和兴趣进行基本估算。我们可以通过发送定制的要约和选项使内部客户参与并改善业务。
尽管使用主题建模的方法相对新颖,实际上,大多数的信用卡的发行商都会使用对客户交易的兴趣进行分类。例如,美国运通公司一直在使用这种方法为其客户创建兴趣图。这样的兴趣图不仅将交易分为食物,旅行等主要类别,而且还创建了诸如泰国美食迷,野生动物爱好者等的细分。所有这些分类都仅仅基于交易数据的丰富性!

Ravindra Reddy Tamma –数据科学家(Actify数据实验室)
Ravindra是Actify Data Labs的机器学习专家。他的专长包括信用风险分析,应用程序欺诈建模,OCR,文本挖掘以及将模型部署为API。他与贷方广泛合作,以开发应用程序,行为和收款记分卡。
Ravindra还使用非结构化征信机构标头信息为印度的无抵押贷款开发了国家级应用程序欺诈模型。除信用风险外,Ravindra在OCR,图像分析和文本挖掘方面拥有深厚的专业知识。Ravindra还在自动化生产数据管道和将机器学习模型部署为可扩展的API方面具有丰富的专业知识。








